线程互斥 与 锁
- 前言
- 正式开始
- 黄牛抢票demo
- 问题解释
- if判断。
- tickets-\-
- 数据不一致
- 临界资源与临界区
- 互斥锁
- 全局锁
- 局部锁
- 几个问题
- 互斥锁的原理
- 单个线程时
- 多线程申请锁
- 总结申请锁流程
- 可重入和线程安全
- 常见的线程不安全的情况
- 常见的线程安全的情况
- 常见不可重入的情况
- 常见可重入的情况
- 可重入与线程安全联系
- 可重入与线程安全区别
- 死锁
- 死锁的四个必要条件

前言
屏幕前的你若对线程概念还不是很了解的话,可以看看我前一篇:
- 详解线程第一篇:从单线程到多线程的转变
本篇全程会通过一个例子(抢票)来讲解线程互斥。
正式开始
说一个现实生活中的例子:多个黄牛抢票。不管抢啥票,就说抢陈奕迅演唱会的票吧😁。
我现在搞一个多线程,主线程只进行创建新线程,并对新线程进行等待。新线程就是黄牛,来抢陈奕迅演唱会的票,而演唱会的票在整个程序中是一个全局变量。
黄牛抢票demo
代码如下:
【注】下面代码中涉及到的函数均已在上篇中介绍,本篇不会再讲解,若有不懂的函数接口可查看我刚刚给的那篇博客
#include <iostream>
using namespace std;
#include <pthread.h>
#include <unistd.h>
#include <string>
// 黄牛人数
#define THREAD_NUM 5
// 陈奕迅演唱会的票数tickets
int tickets = 1000;
// 黄牛抢票执行的方法
void* getTicket(void* arg)
{
// 每个黄牛疯狂抢票
while(1)
{
if(tickets > 0)
{
// 每次都抢一张
tickets--;
// 抢到票时就打印一下
printf("%s抢到票了, 此时ticket num ::%d\n", (char*)arg, tickets);
}
else
{
printf("%s没抢到票, 票抢空了\n", (char*)arg);
break;
}
}
// 记得要释放掉黄牛的名字,不然内存泄漏了
delete (char*)arg;
return nullptr;
}
int main()
{
// 假设此时有三个黄牛进行抢票
pthread_t tid[THREAD_NUM];
for(int i = 0; i < THREAD_NUM; ++i)
{
// 给黄牛起个名
char* name = new char[20];
snprintf(name, 20, "%d号黄牛", i + 1);
// 每个黄牛去抢票
pthread_create(tid + i, nullptr, getTicket, (void*)name);
}
// 等待每个黄牛抢完票后退出
for(int i = 0; i < THREAD_NUM; ++i)
{
pthread_join(tid[i], nullptr);
}
return 0;
}
此时如果我直接运行:
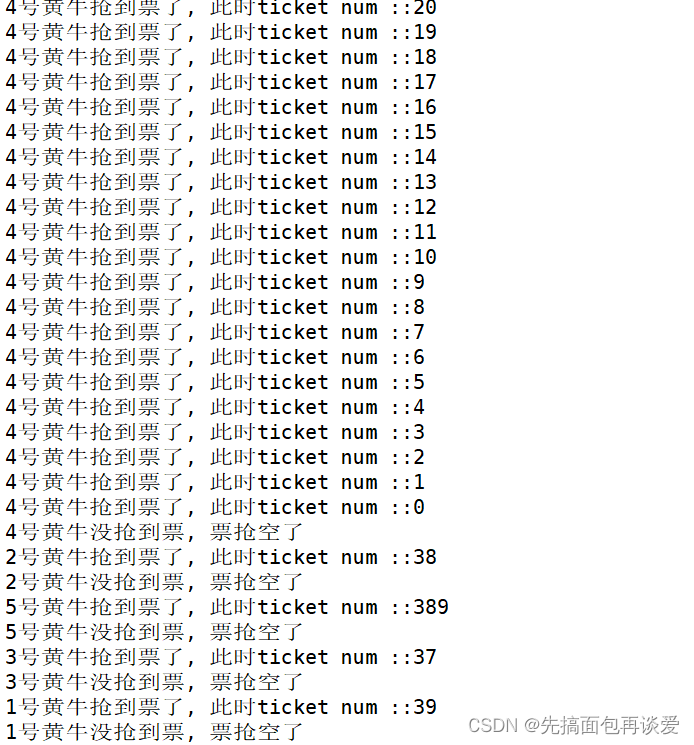
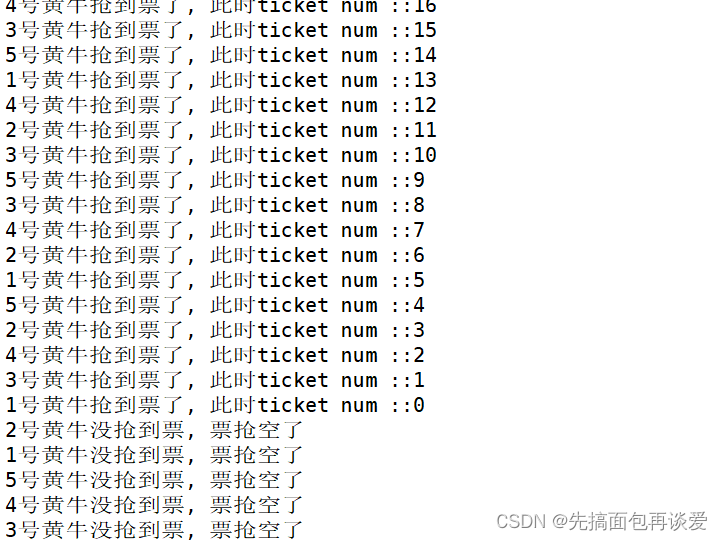
出问题了,上面的运行结果比较长,我没法截全,大概说一下没截上得的,ticket是从1000开始减的,而且每个黄牛都有抢到票了(1000张票抢的时候是5个黄牛穿插着抢的),4号黄牛抢到了最后一张,但是此时其他黄牛打印的信息却是一个大于0的数,然后又打印了票空了。这是为啥呢?
如果我在抢票的函数中加上usleep(以微秒为单位暂停)控制一下呢:

运行:

此时竟然还出现了负数,你说奇怪不奇怪?
我来把4、3、2、1号的最后两次出现截出来:
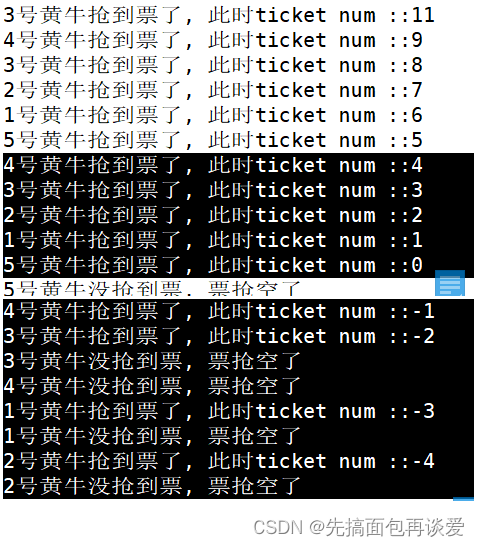
各位有啥想法?
问题解释
出现上方问题的原因有两个:
-
一个是if判断
-
一个是ticket--
也就是这:

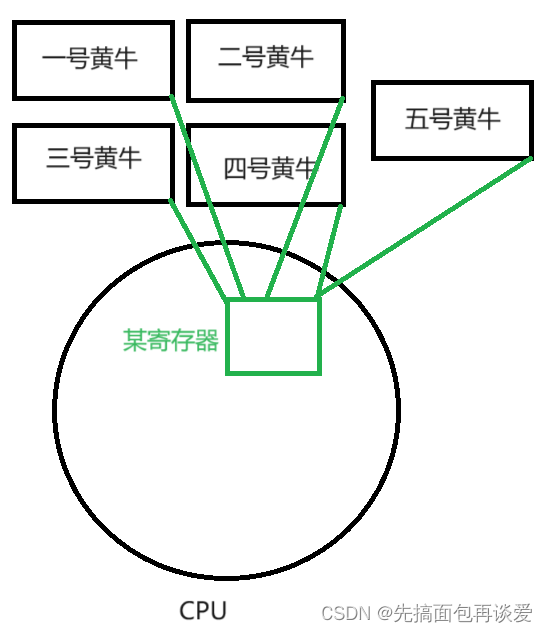
首先最重要的一点是CPU的寄存器存放了每个线程的上下文数据。当某一线程在其时间片跑完后,会将其在CPU的寄存器中的某些重要数据保存到其上下文当中。
在每个线程眼里,CPU内的寄存器本质上就是其上下文数据。尽管所有的寄存器空间是被所有的执行流所共享的,但是寄存器中的内容对某一特定执行流来说是私有的,也就是执行流的上下文。
.
举个例子,比如你现在要造一把铁锤子,需要用到工作台,这个工作台是共享的,所有人都能用,你在造锤子前需要木头、铁、钉子等材料,你将这些材料带过去,然后在工作台上进行加工,期间你可能会休息一会,休息的时候你就要把那些加工过的材料拿走方便别人使用你刚刚用过的工作台,休息好并且工作台空闲时你再带着你的材料再去进行加工,你中间可能休息了不止一回,重复该过程,直到造完之后就将锤子拿走。这里的你就好比线程,材料就是线程的数据,时间片跑完就相当于是你要休息了,此时CPU寄存器中的重要数据就是你加工过的材料,休息的时候要将加工过的材料拿走,对应的,线程时间片跑完后需要将其重要的数据拿走。这里寄存器中的重要数据就是上下文。
也就是下图:
还有一点,线程在被调度的时候,其执行到哪一步代码我们人为是无法确定的(除了人为干预的部分代码可以确定),这取决于优先级等线程自身属性。再把代码拿出来:

这里代码中的usleep会导致线程阻塞等待,此时就会切换掉当前线程,然后让下一个线程继续运行。但是阻塞的时间非常短,就5ms,也就是说非常短的时间内线程就又准备好在CPU上跑了。所以同一时刻内可能有多个线程都准备好了,此时谁先运行就取决于优先级了,优先级相同就看运气了(后面这句是应该吧,我也不太确定🤔)。
tickets是存放在内存中的。我们每次对tickets的运算操作,要先从内存中加载到CPU的寄存器中,然后再进行运算。
那么这里就好说了。
if判断。
if判断对tickets进行了逻辑运算,这也是运算,那么就会把tickets先加载到CPU的寄存器中然后再运算。重点来了,此时if走完后又执行了usleep,然后此时当前线程阻塞,也就是说当前线程恢复阻塞完毕,再到CPU上跑到的时候,就会恢复上下文,那么此时上下文中有一个存放当前线程执行进度的东西,而档期进度就是usleep之后,也就是要执行tickets--了。
如图:

恢复上下文后:

这里是重点,等会要考,各位拿小本本记住。当然if这里还不够,要结合着tickets--来看。
tickets--
tickets--,这也是个运算操作,其转为汇编的话,会有三步:
- 将tickets在内存中的数据加载到CPU的寄存器中
- CPU内部进行tickets减一的操作(因为只有CPU能运算)
- 将运算完的结果写回内存中
结合着前面的if和那个运行结果来说:
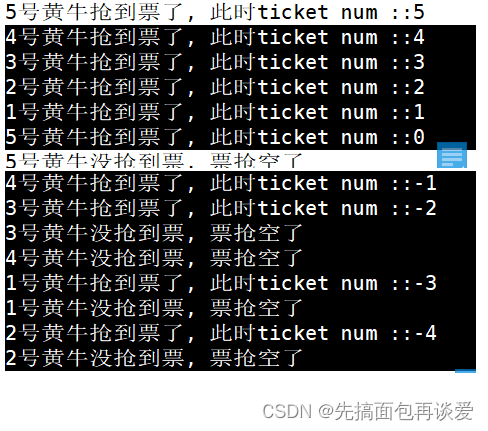
注意看,4号黄牛倒数第二次抢票后其认为还剩4张票,3号黄牛倒数第二次抢票后其认为还剩3张票…以此类推,当5号黄牛抢完票后票已经为0了,5号就退出了,但是此时注意4号抢完后,其时间片还没走完,所以又循环了一次:

轮到3号后:

然后2号线程循环上去后认为tickets是2,然后又进去了,阻塞后换1号。
然后1号线程循环上去后认为tickets是1,然后又进去了,阻塞后换5号。
然后5号线程循环上去后认为tickets是0,然后走的是else语句,5号结束了。
但是,4、3、2、1还没有走完,因为都到usleep那里阻塞了,阻塞完后恢复上下文,此时都要去执行tickets--的操作。
按照上面的运行结果来看,后续执行顺序是4、3、1、2,说明优先级都差不多的,4执行的时候内存中的tickets已经被5号改为0了,此时0加载到了CPU的寄存器中,进行--运算,那么tickets就变成了-1,而这个-1又被写回了内存,然后printf打印的时候,又将tickets从内存中找到tickets并进行打印,也就打印出了-1,然后又循环上去了,if判断tickets为-1,小于零,四号就退出了。同理,后面的三个我就不讲了吧。。。
那么这就是为啥会出现上述的运行结果,原因就是多执行流并发访问全局的数据tickets而导致的结果。
当然,看过我前面信号那篇博客的同学应该也知道--还会导致一种错误。就是数据不一致的错误。
数据不一致
还是刚刚那句话,我们无法确定当前线程是在何处阻塞的(除了人为干预的能够确定其一定会阻塞的位置),调度的时候会线程的下一条执行位置会停在某一条汇编代码处。而--操作有三条汇编代码,刚刚也说了,这里就不重复了。
来个例子:
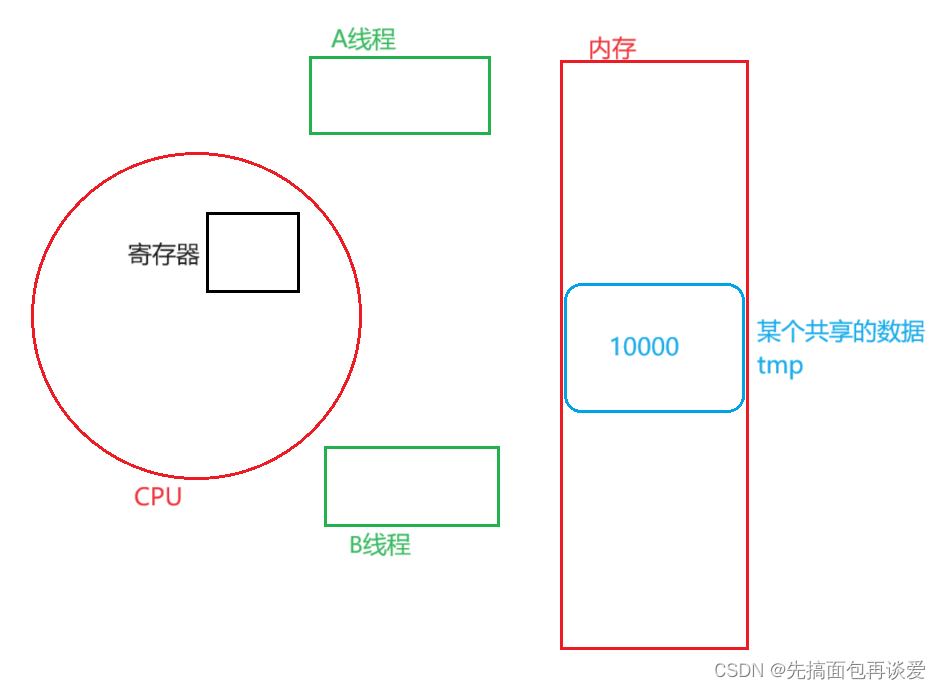
如图,线程A和线程B共享数据tmp,此时二者的执行代码中都是循环对tmp进行--操作,假如说tmp的起始数值为10000。
--操作汇编分三步:
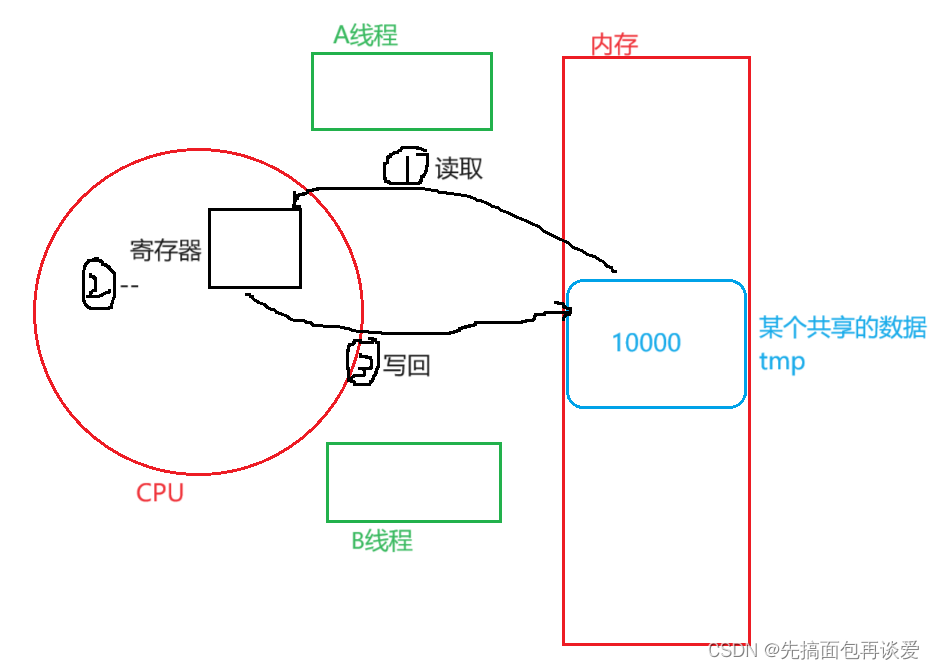
假如A线程先来减,减了30次时,被调度了,而且是要在进行数据重写的时候被调度了,也就是要重写回9970时被调度,A中会保存tmp为9970这个值,而且此时内存中tmp的值为9971:
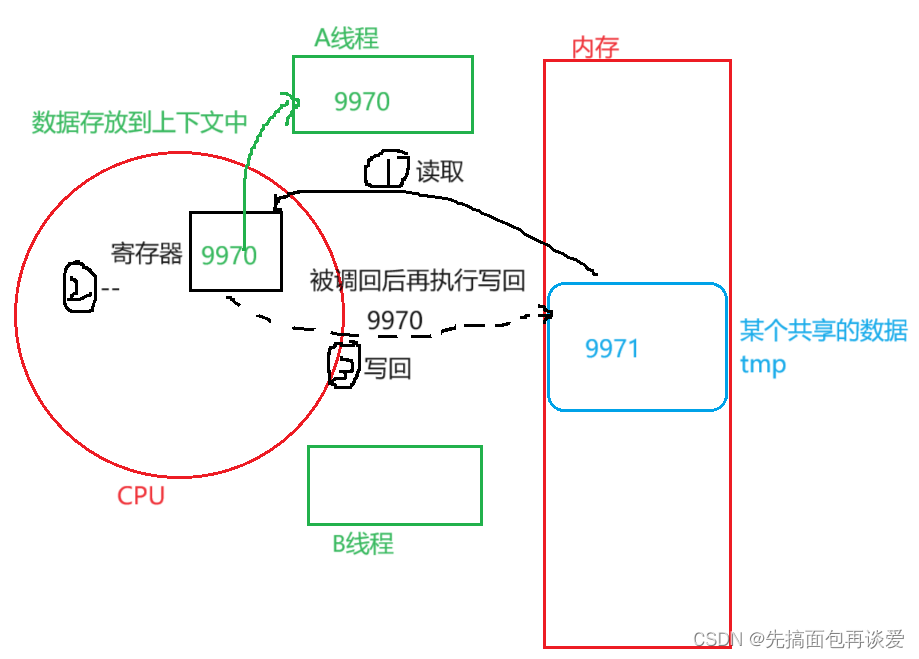
此时切换到线程B,假如线程B执行了5000次--操作后被调度了,也就是说从9971减5000次,那么最终会减到4971,此时B认为tmp减到了4971:

此时切换到A,回复上下文后,A中tmp的值为9970,执行写回操作,直接将9970覆盖到了内存的tmp中:
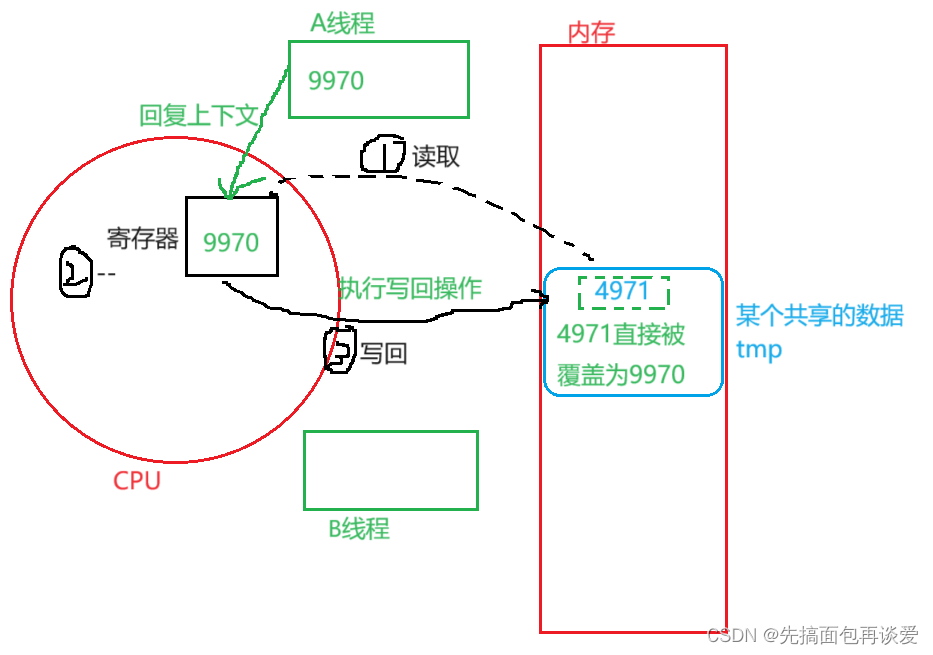
这下完了,B线程半天的努力成果白费了,直接干回了9970。
B认为还是4971,但是A已经将tmp改成9970了,这就是数据不一致问题。
我已经尽力讲了,不知屏幕前的你听懂没。
其实上面if执行完之后可能也会被调度,也就是在usleep之前就调度了,此时线程就已经进入if成功的语句块中了,如果此时被调度,也是上面if中讲解的一样,没啥变化,这种情况发生的概率极低(--操作中被调度也是概率极低),不过还是要说一说的。
临界资源与临界区
其实这俩概念在我前面进程间通信的那篇博客的最后也讲了,但是只是一带而过,毕竟进程间通信涉及到的并不多。
这里就再说说。
-
临界资源:多线程执行流共享的资源就叫做临界资源
就比如说上面代码中的陈奕迅演唱会的票,也就是那个tickets。 -
临界区:每个线程内部,访问临界资源的代码,就叫做临界区
直接来个图吧:

就是访问到tickets的代码,就是临界区。
这种访问临界资源的实际情况处理起来还是有点复杂的。我们得要保证临界数据被访问时的安全问题, 像上面的代码中就没有考虑到这一点,那么如何避免上述减到负数的情况呢?
要对tickets进行加锁保护,这里就要开始讲互斥锁了。
互斥锁
再来说两个概念:
- 互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用
- 原子性(后面讨论如何实现):不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成
我先不讲锁相关的东西,这里得先看看代码长啥样,不然不好讲。
全局锁
先看看锁长啥样:

pthread_mutex_t就是锁的类型,没错,定义一个锁就和定义一个变量一样简单。
可以看到我注释了一个全局锁,意思就是这个锁是放在全局作用域下的。当然也有static的锁、局部的锁等等,这里就先以全局锁为例来演示。
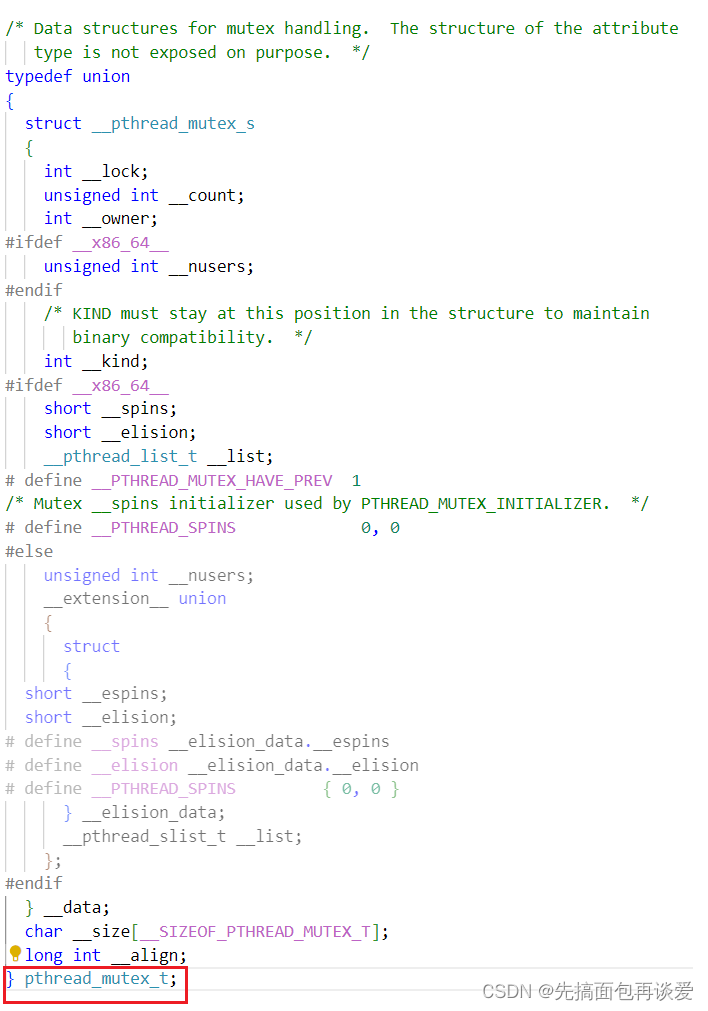
其实pthread_mutex_t就是一个联合体:
再来看看有关锁的接口:
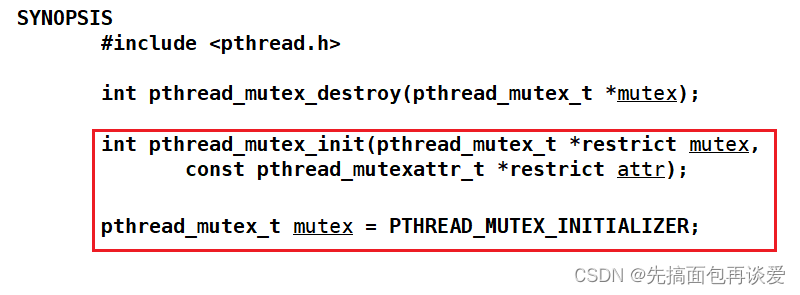
destroy就是销毁锁。没啥好讲的,就是传一个锁的指针就能把锁销毁了。
init就是对锁进行初始化,不过锁有两种初始化的方式,一种是对于局部锁的初始化,用的就是pthread_mutex_init,但先不讲局部的。另一种是对全局 / 静态的锁的初始化,用最下面的 = PTHREAD_MUTEX_INITIALIZER直接初始化。

其实就是个宏。
还有加锁和解锁:

lock就是上锁,unlock就是解锁,trylock后面会讲一个使用场景。
传个指针就行。
加锁是要对临界区进行加锁。
有什么用,等会详细说,各位先看代码:
#include <iostream>
using namespace std;
#include <pthread.h>
#include <unistd.h>
// 全局锁 直接用宏来初始化
pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
// 黄牛人数
#define THREAD_NUM 5
// 陈奕迅演唱会的票数tickets
int tickets = 1000;
// 黄牛抢票执行的方法
void* getTicket(void* arg)
{
// 每个黄牛疯狂抢tickets
while(1)
{
pthread_mutex_lock(&mtx);
if(tickets > 0)
{
usleep(2000);
tickets--;
printf("%s抢到票了, 此时ticket num ::%d\n", (char*)arg, tickets);
// 当对临界资源访问完后就解锁
pthread_mutex_unlock(&mtx);
}
else
{
// 当对临界资源访问完后就解锁,这里是当tickets == 0的情况,也要解锁
pthread_mutex_unlock(&mtx);
printf("%s没抢到票, 票抢空了\n", (char*)arg);
break;
}
}
// 记得要释放掉黄牛的名字,不然内存泄漏了
delete (char*)arg;
return nullptr;
}
int main()
{
// 假设此时有三个黄牛进行抢票
pthread_t tid[THREAD_NUM];
for(int i = 0; i < THREAD_NUM; ++i)
{
// 给黄牛起个名
char* name = new char[20];
snprintf(name, 20, "%d号黄牛", i + 1);
// 每个黄牛去抢票
pthread_create(tid + i, nullptr, getTicket, (void*)name);
}
// 等待每个黄牛抢完票后退出
for(int i = 0; i < THREAD_NUM; ++i)
{
pthread_join(tid[i], nullptr);
}
return 0;
}
对临界区加锁之后,某时刻只能有一个线程执行临界区中的语句,当有一个线程执行pthread_mutex_lock(&mtx)之后,这个线程就能拿到这把mtx锁,此时其他线程跑到pthread_mutex_lock(&mtx)时只能阻塞等待,拿到锁的线程执行完加锁区域中的代码并释放掉其所拿到的锁后才能让其他线程执行pthread_mutex_lock(&mtx)操作来继续拿锁,此即互斥。
运行:
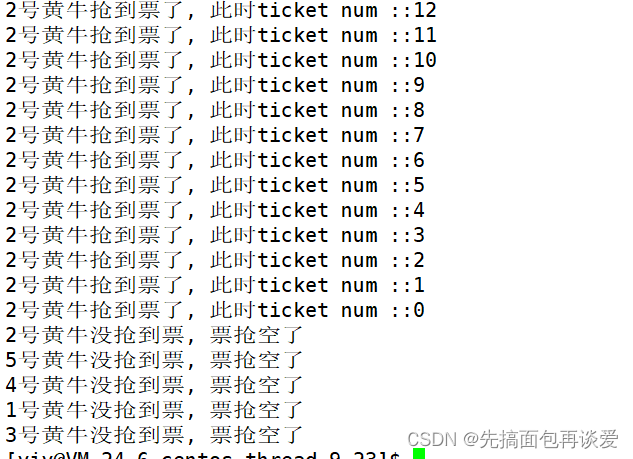
可以看到,不会出现负数的情况了,但是还有点小问题,这里票全被2号黄牛抢了,不太现实,我们应该加点抢完票的后续动作,不能全让一个黄牛拿走了,别的黄牛就没法活了😅。而且这里打印速度相比前面变慢了好多,可惜我只能搞静态的图,没法搞动图,各位如果有条件的话可以试着运行一下。
稍微修改一下:
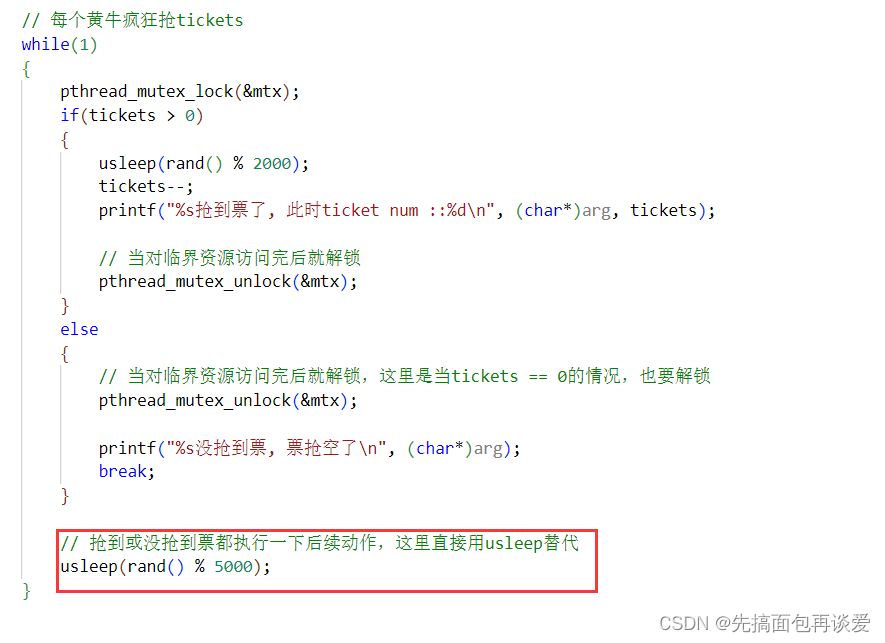
运行:

这里主要是可以对临界资源进行保护,这一点演示出来就行。
还有注意一点,我代码中也注释了,lock的是临界区的,也就是:
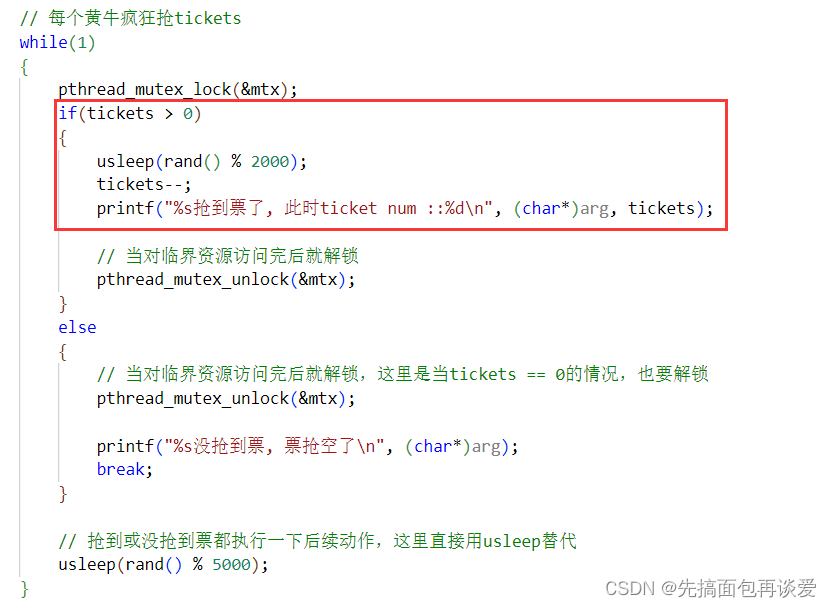
unlock要给两个,一个是为了当前tickets>0的时候解锁,一个是为了tickets = 0的时候解锁,不能在
else结束后面解锁,不然break跳出之后就解不了锁了。
还有一点,有的同学可能会说为啥不在函数的开始加锁,结束解锁呢?
注意,加锁的时候一定要保证加锁的粒度要细,越细越好,不要将无关紧要的代码也加上锁,没有意义,只会降低运行效率,因为加锁的代码某一时刻只能一个线程跑,别的线程会指向到加锁前的代码等待,所以尽量在只有访问到临界资源的时候才加锁。如果这里printf中没有访问tickets的话,也可以不对printf加锁。直接放到printf前面解锁就行。
这里再演示一下去掉锁:

运行:
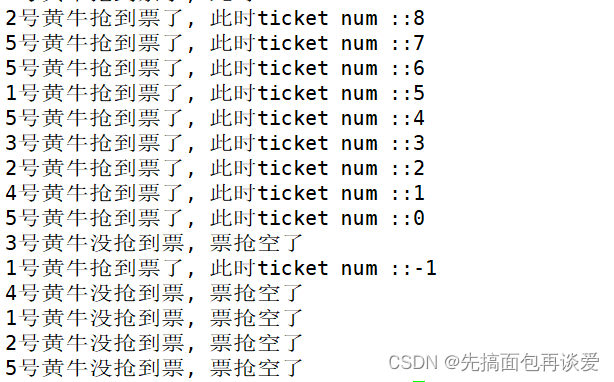
还是会出现负数的情况。所以要注意临界资源的安全性问题。
全局的讲的差不多了,再来说说局部锁。
局部锁
就是一个局部对象。
怎么用呢?
先初始化:

然后我上一讲了pthread_create接口,第三个参数是回调函数,第四个参数可以传给那个回调函数。
那么我们就可以通过第四个参数把锁传给那个回调的方法。这里来个例子:
#include <iostream>
using namespace std;
#include <pthread.h>
#include <unistd.h>
#include <ctime>
#include <string>
// 线程数据,包含线程名字,也就是黄牛名字,还有线程对应的互斥锁
class ThreadData
{
public:
ThreadData(const string& name, pthread_mutex_t* pmtx)
:_name(name),
_pmtx(pmtx)
{}
public:
string _name;
pthread_mutex_t* _pmtx;
};
// 黄牛人数
#define THREAD_NUM 5
// 陈奕迅演唱会的票数tickets
int tickets = 1000;
// 黄牛抢票执行的方法
void* getTicket(void* arg)
{
ThreadData* ptd = (ThreadData*)arg;
// 每个黄牛疯狂抢tickets
while(1)
{
pthread_mutex_lock(ptd->_pmtx);
if(tickets > 0)
{
usleep(rand() % 2000);
tickets--;
printf("%s抢到票了, 此时ticket num ::%d\n", ptd->_name.c_str(), tickets);
// 当对临界资源访问完后就解锁
pthread_mutex_unlock(ptd->_pmtx);
}
else
{
// 当对临界资源访问完后就解锁,这里是当tickets == 0的情况,也要解锁
pthread_mutex_unlock(ptd->_pmtx);
printf("%s没抢到票, 票抢空了\n", ptd->_name.c_str());
break;
}
// 抢到或没抢到票都执行一下后续动作,这里直接用usleep替代
usleep(rand() % 5000);
}
// 记得要释放掉线程数据,不然内存泄漏
delete ptd;
return nullptr;
}
int main()
{
// 局部锁
pthread_mutex_t mtx;
// 默认给空就行
pthread_mutex_init(&mtx, nullptr);
// 种一颗随机数种子
srand((unsigned int)time(nullptr) ^ getpid() ^ 0x24233342);
// 假设此时有三个黄牛进行抢票
pthread_t tid[THREAD_NUM];
for(int i = 0; i < THREAD_NUM; ++i)
{
string tmp;
tmp += to_string(i + 1) + "号黄牛";
ThreadData* ptd = new ThreadData(tmp, &mtx);
// 每个黄牛去抢票
pthread_create(tid + i, nullptr, getTicket, (void*)ptd);
}
// 等待每个黄牛抢完票后退出
for(int i = 0; i < THREAD_NUM; ++i)
{
pthread_join(tid[i], nullptr);
}
pthread_mutex_destroy(&mtx);
return 0;
}
上面的代码中用了一个类来表示线程相关的东西,就两个,一个线程名字,一个线程需要的锁的指针。这样就能把局部的锁传到线程的执行方法中。
运行:
完全ok。和上面的全局锁用法差不多。
几个问题
- 加锁的区间就是一定是串行(某时刻只能有一个执行流执行)执行了吗?
- 再临界区中的执行流是否会因为调度而被切换?如果切换了会有问题吗?
- 上面代码中的原子性体现在哪里?
先来说第二个问题,答案是会切换的,os可能在任意位置切换,此处临界区有多条语句,完全有可能在其中切换,但是不会发生问题。因为虽然被切换了,但当前执行流并没有释放锁,即便有其他线程想申请锁也无法申请成功,因为锁已经被当前执行流占有,故其他线程无法进入临界区,所以临界资源也不会被修改。
如果有人写出了一个同一份临界资源被不同的执行流所处理,而且不同执行流的处理方式中有的加了锁,有的没加锁,就完全可以说这种方式是一种错误的编码方式。上面加锁只是一种编码规范,不遵守该规范虽然可以写出代码,但是这种方式非常不推荐,否则锁也就没有了存在的价值。
再来说说原子性:
对没有持有锁的线程来说,对该线程最有意义的两件事是:
- 其他线程没有持有锁
- 某一线程刚释放锁
也就是说这里的锁只有两种状态:被持有和未被持有,未被持有锁的时候,该线程就能申请锁。
其他线程未持有锁,即对临界资源什么都没做。
某一线程刚释放完锁,即对临界资源的行为已经做完了。
要么什么都没做,要做就做完,此即原子性的体现(以当前的学习进度来看,并不是很全面)。
那么根据对上面后两个问题的解答,就能回答第一个问题了,加了锁之后,执行临界区的代码一定是串行的。
互斥锁的原理
多个线程想要访问临界资源都必须先申请锁,也就是说多个线程都必须先看到同一把锁并且能够访问锁,那么这样的话,锁本身也是一种共享资源,申请锁和释放锁必须是具有原子性的,那么谁来保证这两个操作的原子性的呢?
经过上面的例子,大家已经意识到单纯的 i++ 或者 ++i 都不是原子的,有可能会有数据不一致性问题。
若一句代码转为汇编后只有一条汇编语句,我们就认为该汇编语句的执行是原子的,即一条汇编语句要么被执行完,要么就没执行。
为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性。
现在我就通过画图来讲解一下锁发生互斥的整个流程。

上面一个上锁,一个解锁,都是伪代码。这里光讲一下解锁就够了。
单个线程时
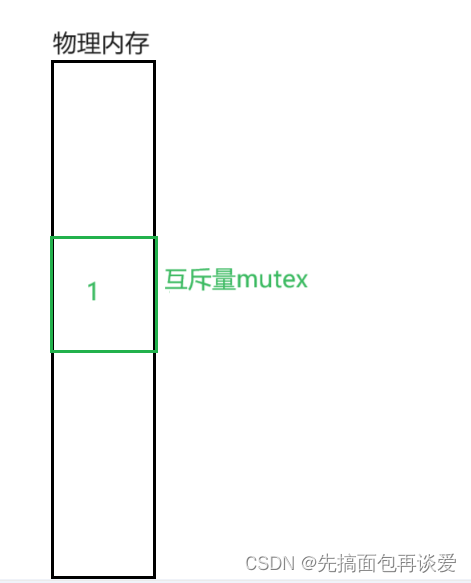
假如说现在有一个线程A,其要执行上锁操作。
锁在内存中会有一份,这里假如说其内容就是1:
然后A线程在申请锁前, 状态是这样的:
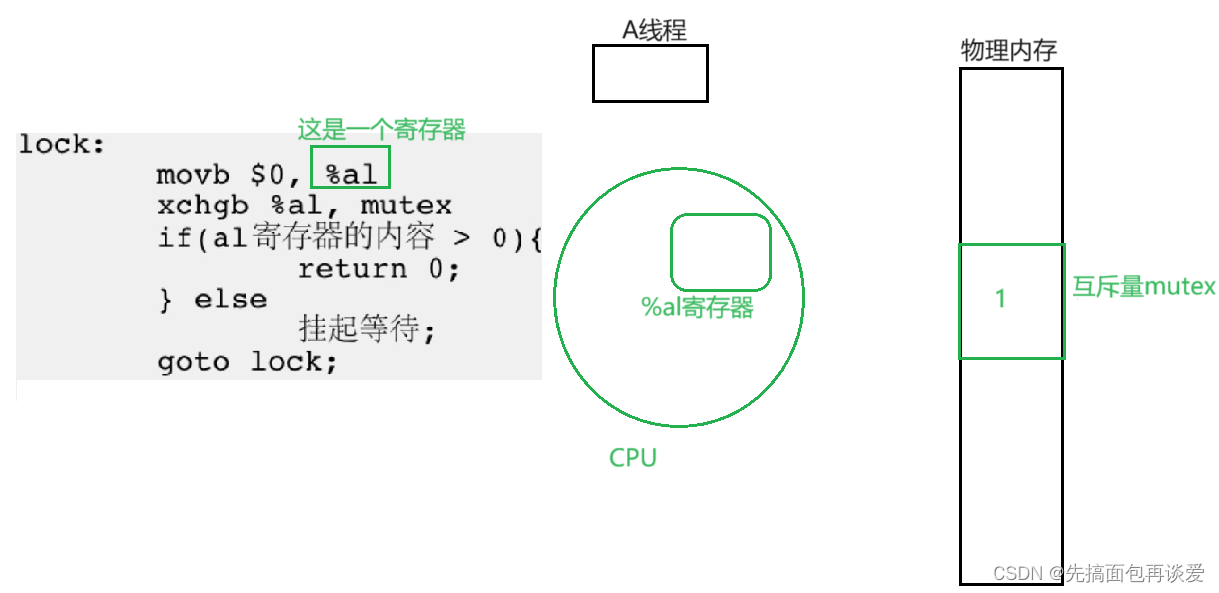
开始:
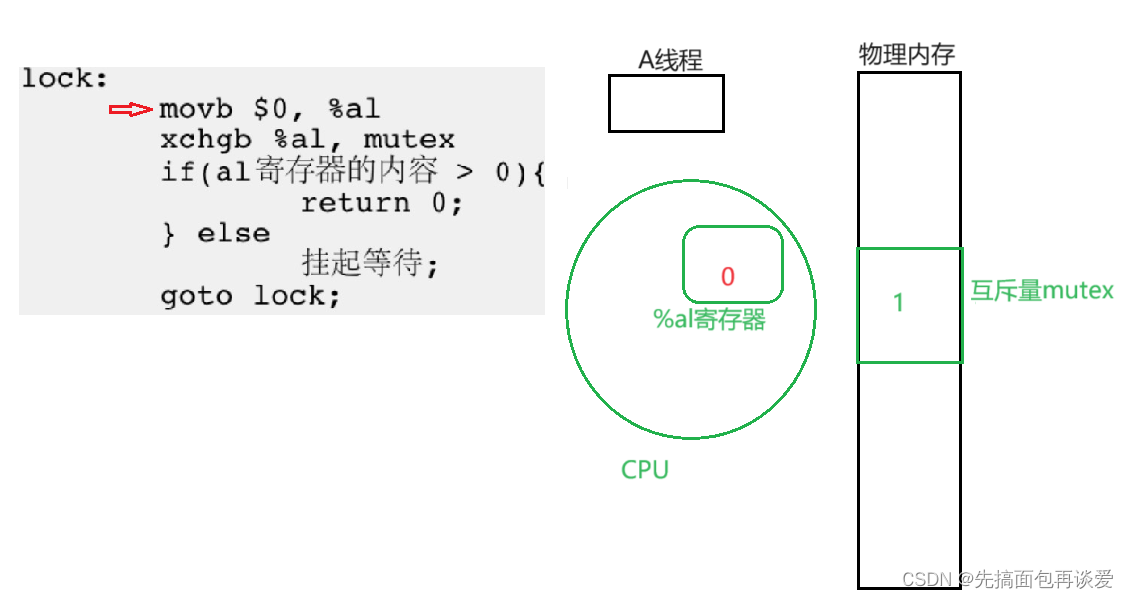
mov指令会将%al中的值改为0。
继续:
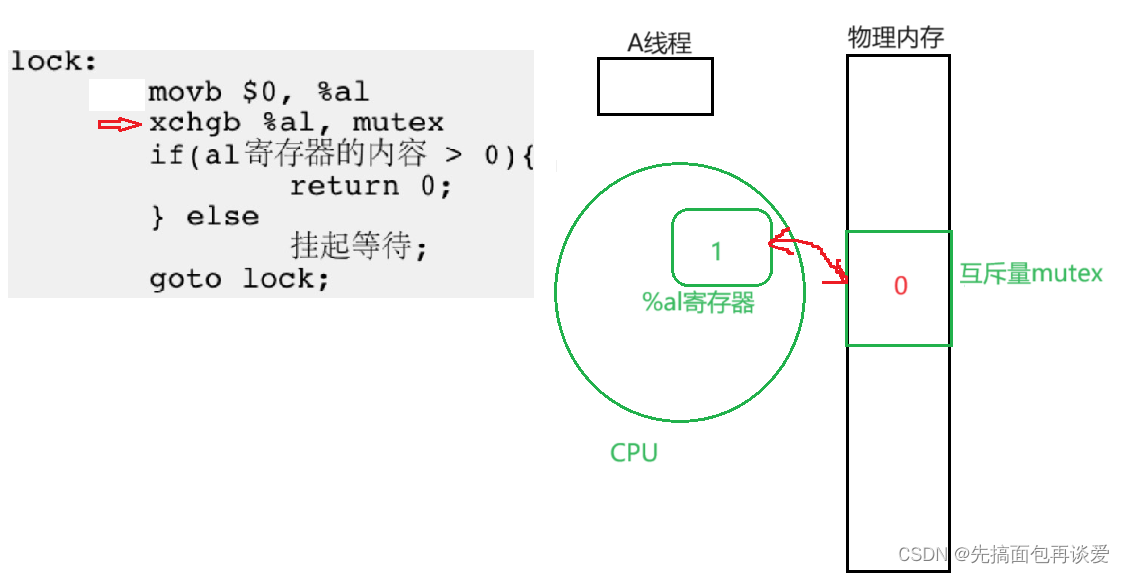
xchgb就是上面提到的exchange指令,将寄存器中的内容和物理内存中的mutex交换,而且是一步到位的。
继续:
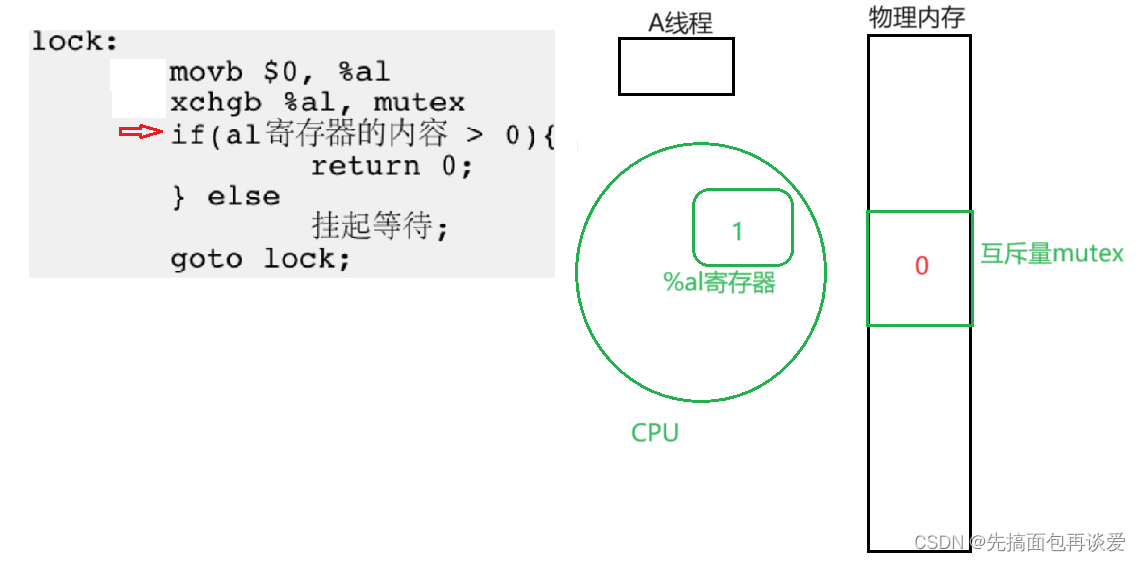
if判断正确,进入要执行的语句块:
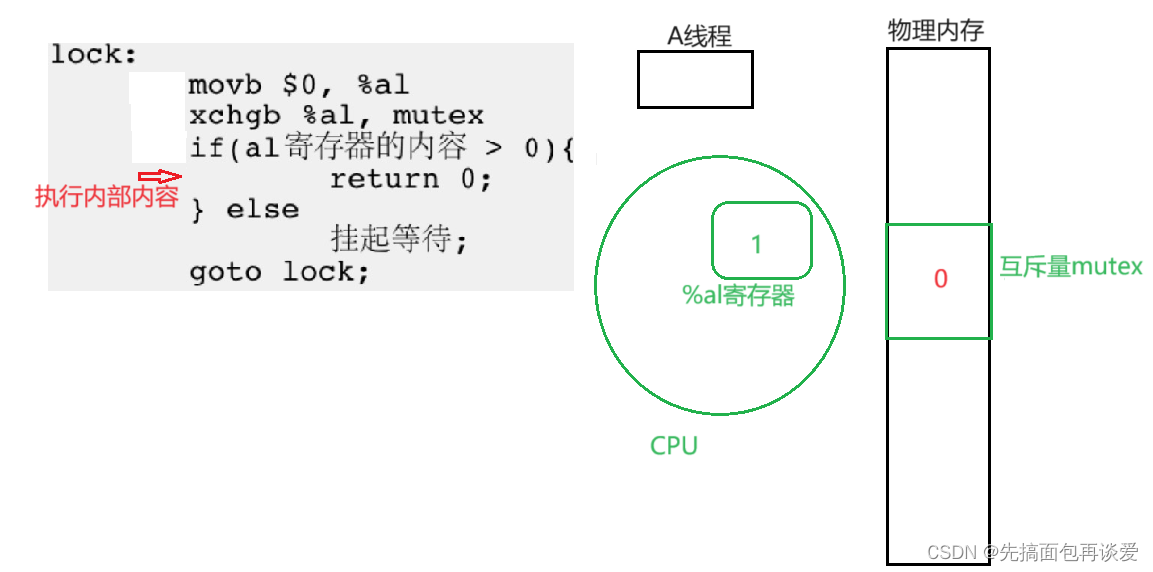
这里面写的是return0,实际上就是那些对临街资源的操作等。
用完后解锁:

ok这是一个线程申请锁的时候的大致流程,但是其中任意一条指令执行前,该线程都有可能被调度走。记住这句话,还有最重要的一个xchgb操作。
多线程申请锁
不要太多,太多了我不好讲,就两个,一个A进程,一个B进程。
初始状态下:
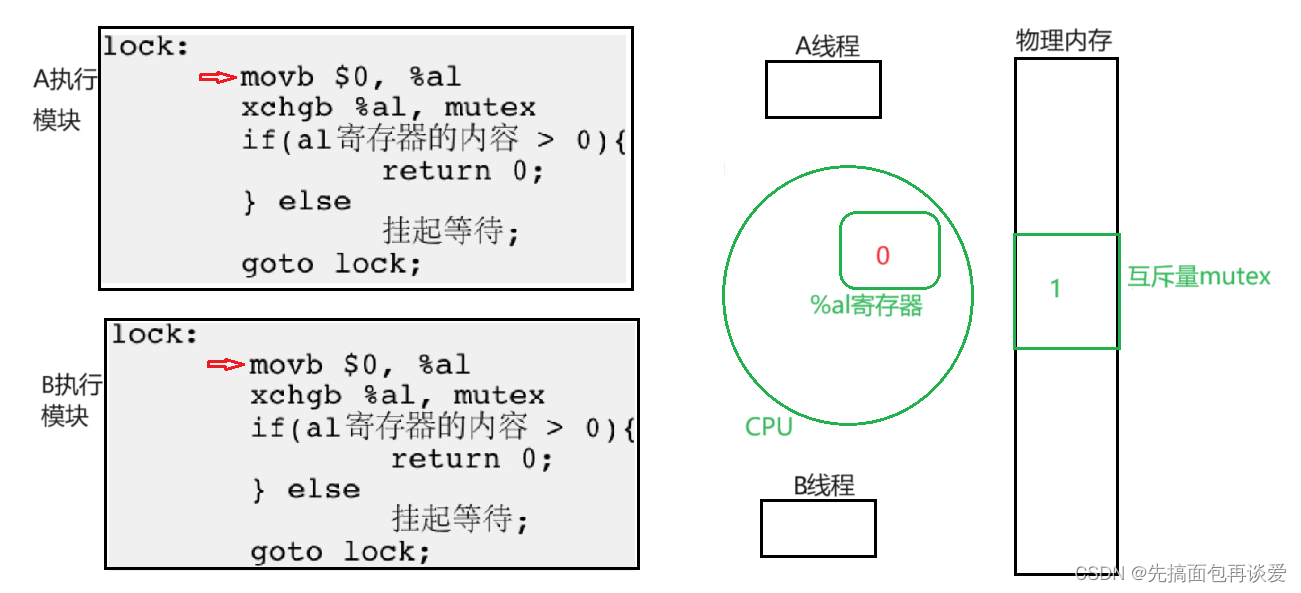
假如说A先执行:
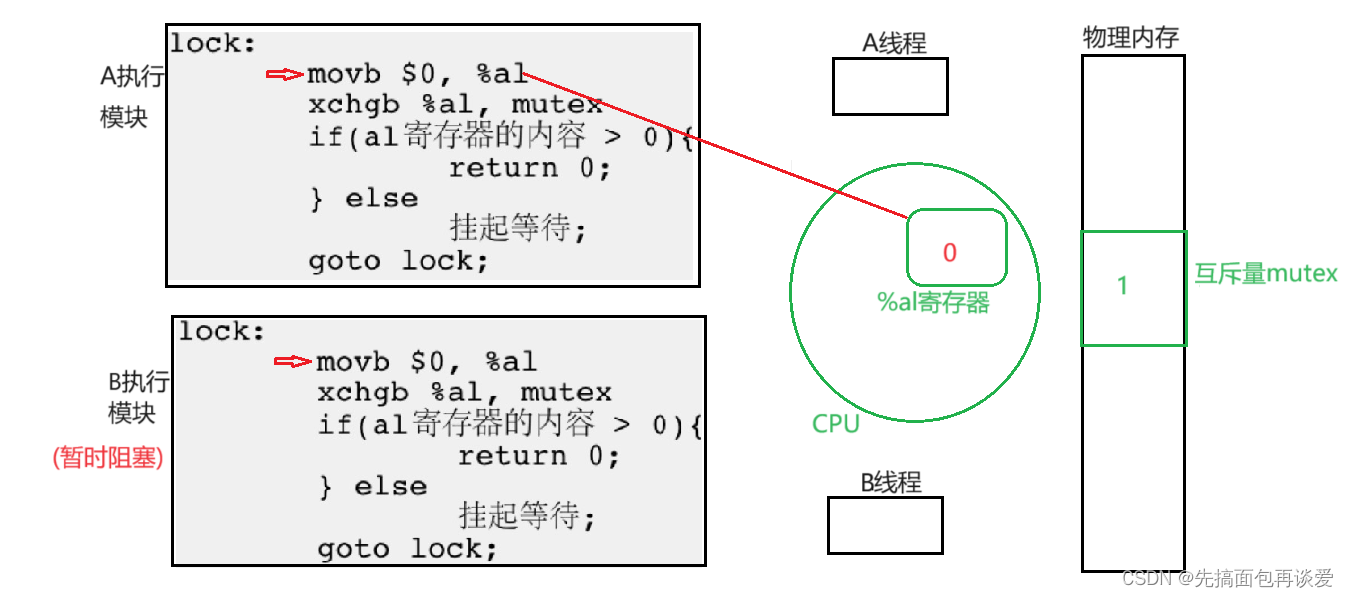
置零操作。
继续:
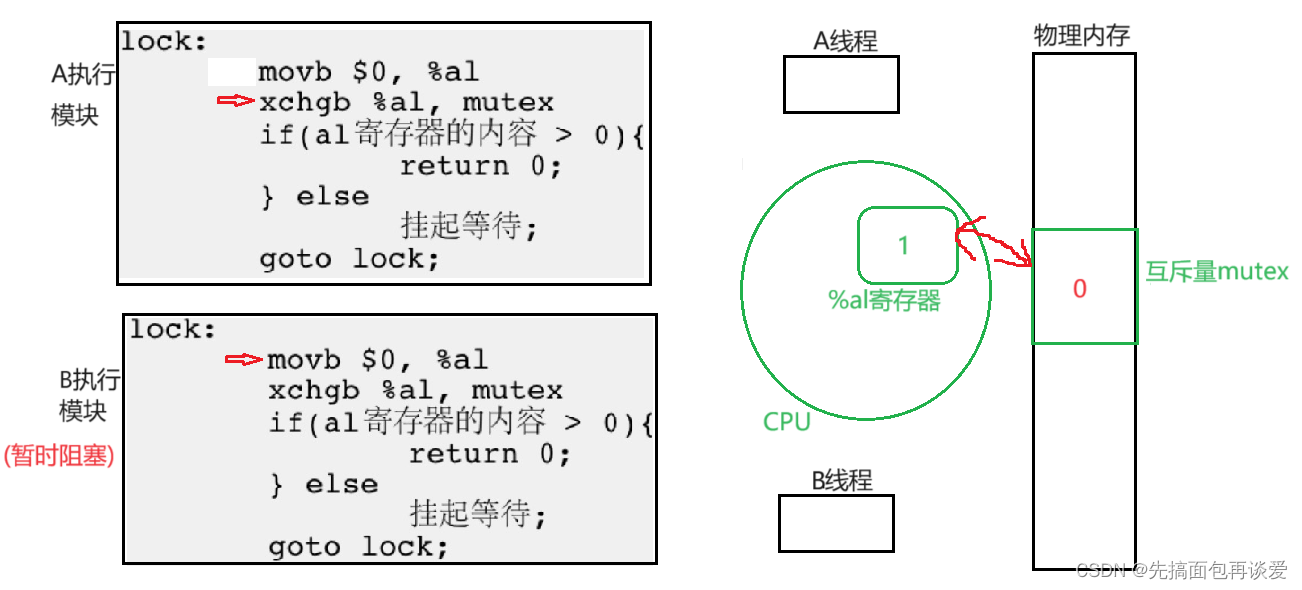
交换寄存器与mutex的值。
ok,假如说此时A被调度走了,也就是说A要开始阻塞,B要开始执行了,A走前要把其重要的数据带走,也就是互斥量也会被A带走:
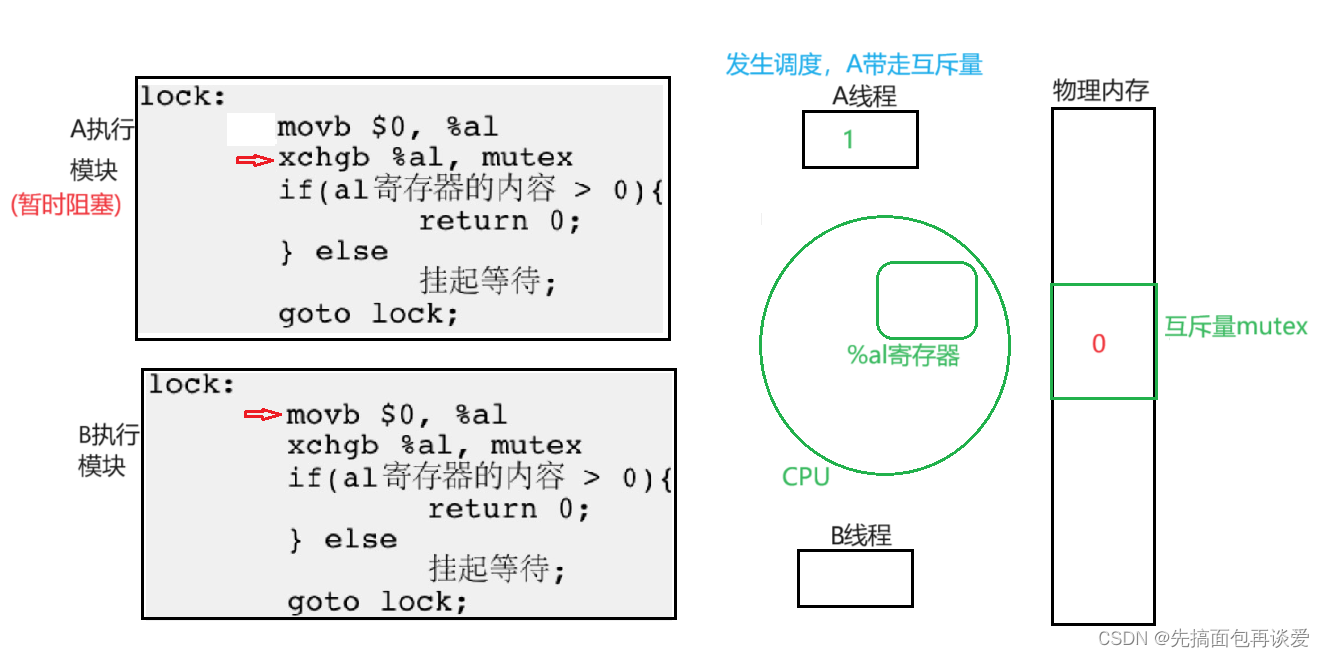
此时B开始执行:
置零。
继续:
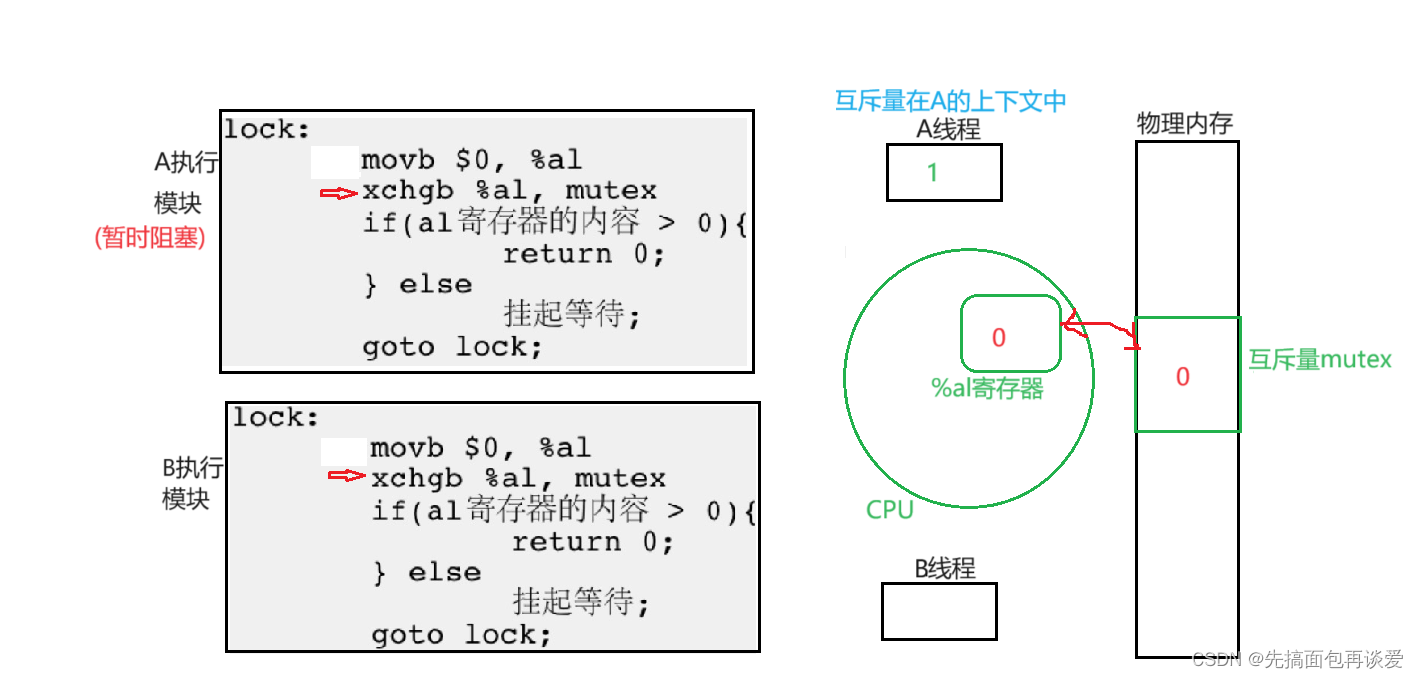
B执行交换操作,但是内存中互斥量值为0,所以交换了个寂寞,还是0。
继续:
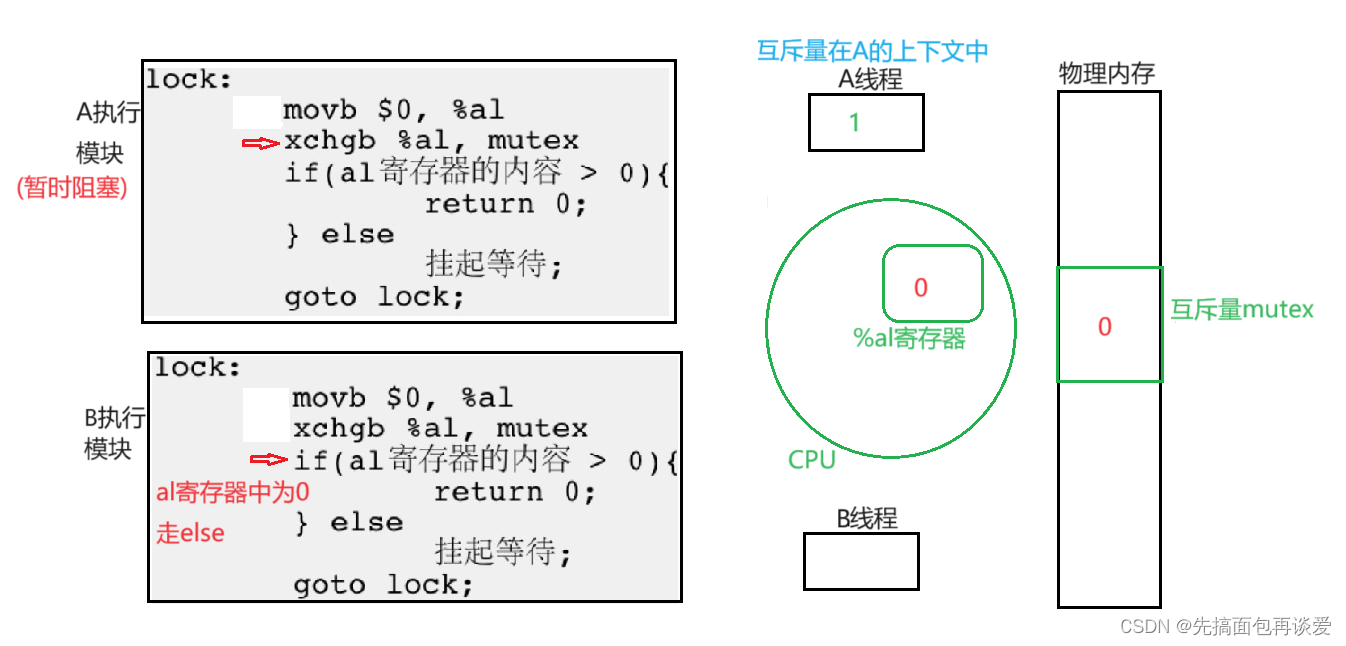
继续:

此时B就阻塞了,走之前也会带走%al中的内容,此时B得到0:
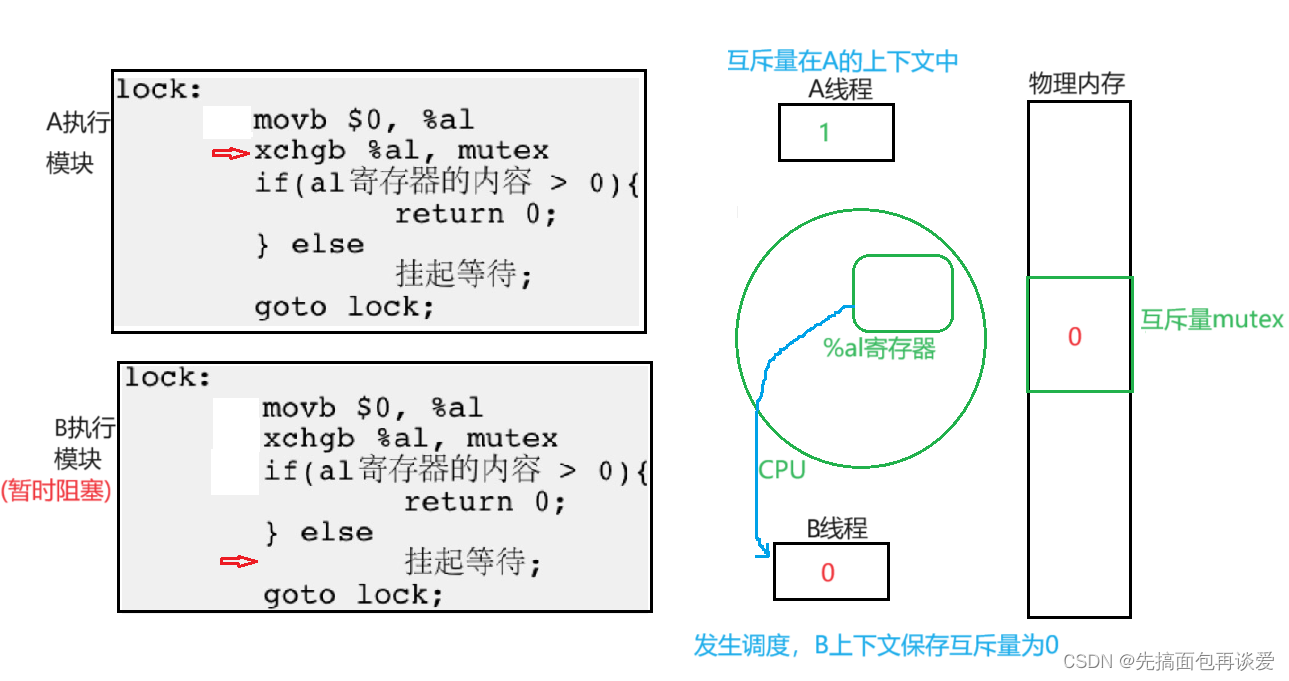
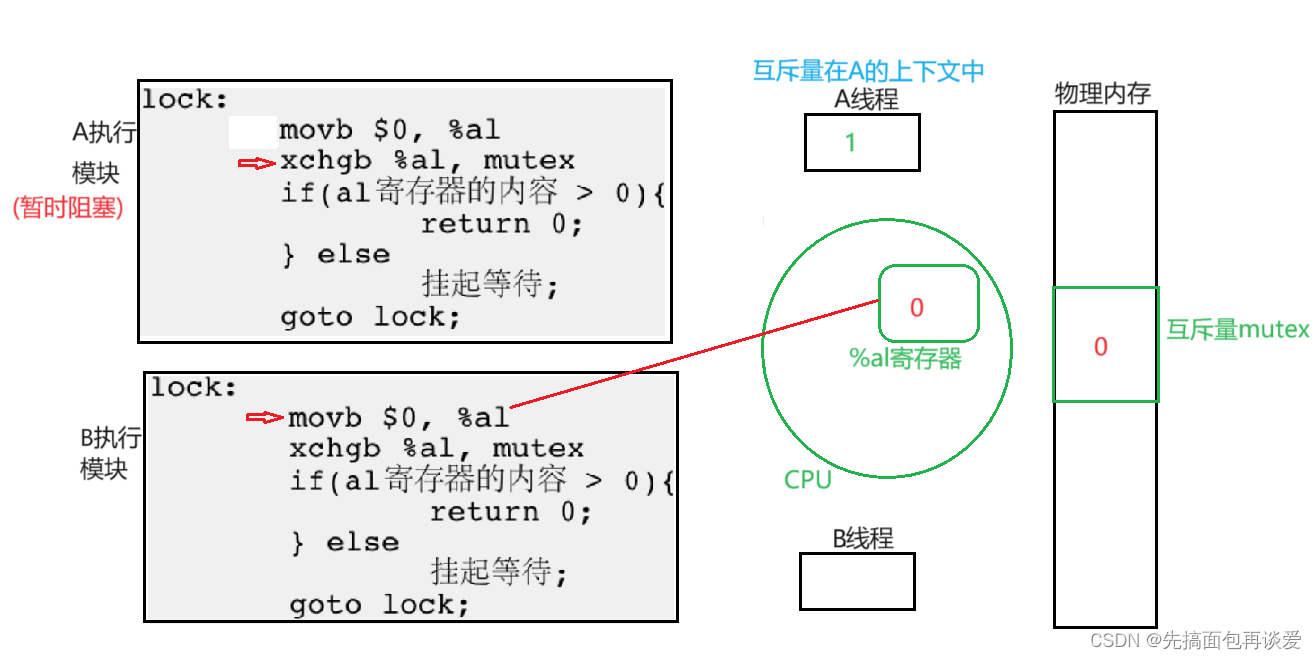
那么此时若还有其他线程想要申请锁,结果是和B一样的。那么这样肯定会轮到A,那么A继续回来:
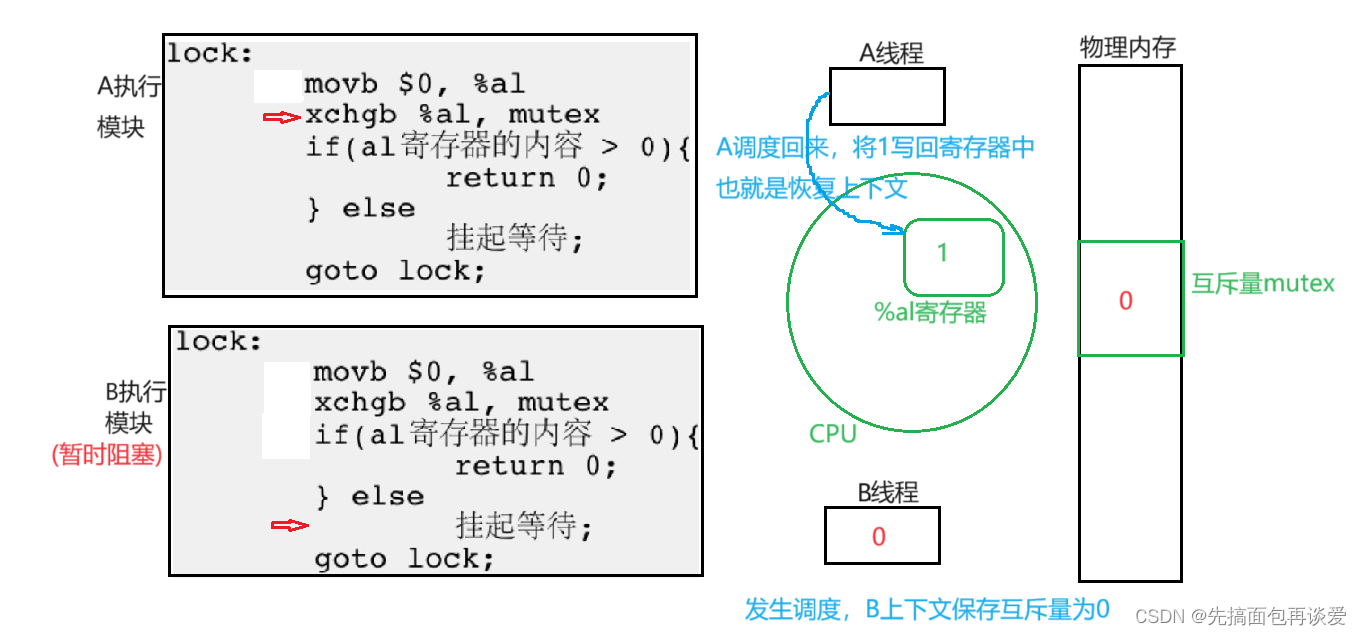
此时A继续执行:
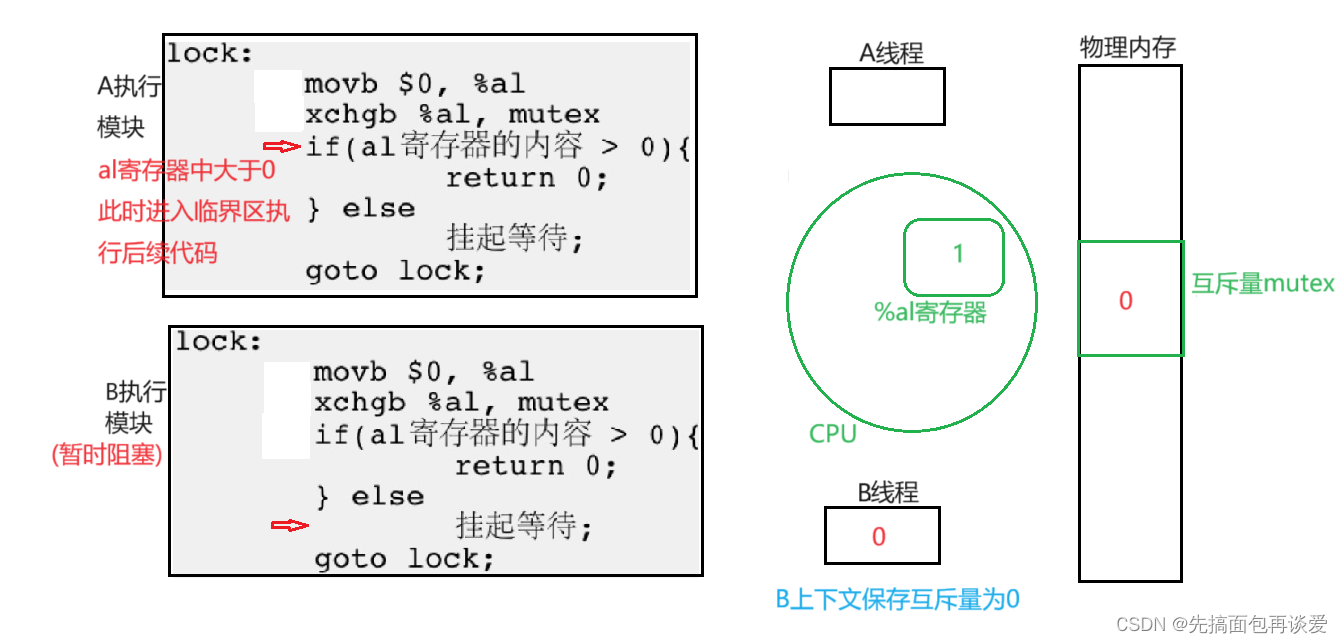
然后A若在执行过程中又被调走了,其他的线程挂起等待结束,又执行了后续的goto lock,这样就有和上面B的流程一样。还是会让A继续走。后续的流程就是A走完了,解锁,然后某一个线程申请锁成功,这样又是一个轮回。应该讲的很详细了吧😁。。。
总结申请锁流程
上面整个流程中最重要的就是xchgb这一步,相当于是线程获取锁,不像mov那样会直接进行拷贝,xchgb能够保证整个流程中只有一个1,也就是只有一个mutex,而mov会导致整个流程中的1个数增加,这样就没法判断锁在哪个线程手上了。也就是说全程仅凭一个1来判断锁的拥有者。
上面图中红色箭头指向某线程的执行位置,是一个理想化的模型,实际上CPU中有一个EIP寄存器,这个寄存器就存储了当前执行流执行到了那一条语句的信息,被调度的时候,这个也会被线程拿走。
所以说,锁的安全性是其本身的设计原理来实现的。
可重入和线程安全
我前面信号量那篇博客也讲过可重入,是跟前面的临界资源、临界值什么的一块讲的。这里就再说说吧。
-
重入:同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。
-
线程安全:多个线程并发同一段代码时,不会出现不同的结果。常见对全局变量或者静态变量进行
操作,并且没有锁保护的情况下,会出现该问题。
各位要记好,可重入描述的是函数,线程安全描述的是线程。虽然一个是函数,一个是线程,但是二者是有交集的。
其实这两个没啥好讲的地方,偏理论,稍微说说各位了解了解就行。
常见的线程不安全的情况
-
不保护共享变量的函数
就比如说我写的第一个黄牛抢票没加锁的例子 -
函数状态随着被调用,状态发生变化的函数
比如说函数中有一个static的变量,用来统计这个函数调用的次数,这里的函数就是一个状态会发送变化的函数 -
返回指向静态变量指针的函数
-
调用线程不安全函数的函数
我们见到的%95以上的函数都是线程不安全的
常见的线程安全的情况
- 每个线程对全局变量或者静态变量只有读取的权限,而没有写入的权限,一般来说这些线程是安全的
- 类或者接口对于线程来说都是原子操作
- 多个线程之间的切换不会导致该接口的执行结果存在二义性
常见不可重入的情况
-
调用了malloc/free函数,因为malloc函数是用全局链表来管理堆的
-
调用了标准I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构
-
可重入函数体内使用了静态的数据结构
常见可重入的情况
-
不使用全局变量或静态变量
-
不使用用malloc或者new开辟出的空间
-
不调用不可重入函数
-
不返回静态或全局数据,所有数据都有函数的调用者提供
-
使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据
可重入与线程安全联系
-
函数是可重入的,那就是线程安全的
-
函数是不可重入的,那就不能由多个线程使用,有可能引发线程安全问题
-
如果一个函数中有全局变量,那么这个函数既不是线程安全也不是可重入的。
可重入与线程安全区别
-
可重入函数是线程安全函数的一种
-
线程安全不一定是可重入的,而可重入函数则一定是线程安全的。
-
如果将对临界资源的访问加上锁,则这个函数是线程安全的,但如果这个重入函数若锁还未释放则会产生死锁,因此是不可重入的
这里讲一下死锁是啥。
死锁
这里说一下死锁是啥。
比如说两个线程,一个A,一个B。
二者都要申请两把锁,比如说一号锁和二号锁。
但是线程A会先申请一号锁,然后再申请二号锁。
但是线程B会先申请二号锁,然后再申请一号锁。

此时二者都会卡在第二步的申请上,此时整个程序进度也就会被卡死。
各位不要觉得你不会写出这样的代码,这取决于场景,比如说一写一个项目,第一行申请一把锁,第5000行申请第2把锁,此时可能你已经忘记了前面申请过第一把锁,此时不同的执行流其执行时,就可能出现死锁的情况。这就好比一个刚学指针的新手,malloc后总会忘记掉free,而且老手也可能会
犯。
来个生活中的例子讲一下,比如说你和你的小伙伴去买糖吃,你两个人身上都带了五毛钱,但是到了商店,老板说一根🍭要一块钱,此时你给你朋友说“把你五毛给我,我想吃糖”,你朋友也说出同样的话,这样就形成了“死锁”。
如果锁有两把以上就可能出现死锁。但是一把锁也可能,虽然很少见,比如说代码写错了,把释放锁写成了申请锁:
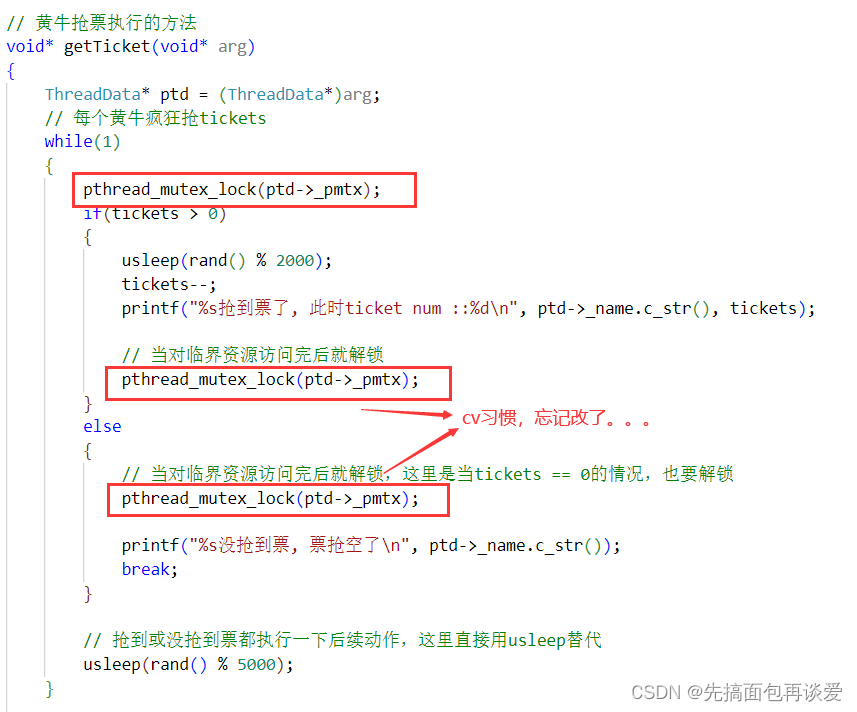
此时运行起来就卡住了:

就是因为出现了死锁,这里1号黄牛现申请了锁,然后又申请了一次其拥有的锁,不就是拿着手机找手机么。
总结一下死锁:
多线程场景中,多个线程在持有自身锁的同时还向对方线程申请对方线程持有的锁,而且还不释放自身所持有的锁,进而导致代码无法向下推进,此即死锁。
死锁的四个必要条件
只有同时满足以下四个条件时,死锁才会形成:
-
互斥条件:一个资源每次只能被一个执行流使用
-
请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放
-
不剥夺条件:一个执行流已获得的资源,在末使用完之前,不能强行剥夺
-
循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系
上面的每个条件中的资源,就是锁。
只要我们能更够使得一个条件不满足,就能避免死锁。
挨个说怎么避免:
- 当我们写代码时,如果有访问到临界资源,要先考虑要不要加锁,可能有不需要加锁的情况,这一点即是互斥条件是否满足,没有锁了,那么就不会出现执行流申请锁。肯定就不会有死锁发生。
- pthread_mutex_lock申请一个占有的锁时会导致线程挂起,但是pthread_mutex_trylock不会。
这里要介绍一下pthread_mutex_trylock,man手册中是这么描述的:
- The pthread_mutex_trylock() function shall be equivalent to pthread_mutex_lock(), except that if the mutex object referenced by mutex is currently locked (by any thread, including the current thread), the call shall return immediately. If the mutex type is PTHREAD_MUTEX_RECURSIVE and the mutex is currently owned by the calling thread, the mutex lock count shall be incremented by one and the pthread_mutex_trylock() function shall immediately return success.
- The pthread_mutex_trylock() function shall return zero if a lock on the mutex object referenced by mutex is acquired. Otherwise, an error number is returned to indicate the error.
其中最重要的一点就是:trylock申请锁失败的时候不会使得当前线程阻塞,而是返回一个错误码,我们在写代码的时候可以用trylock来申请,如果函数返回了就再用五次(其他次数也可以)trylock,若这五次都失败了,那么就先释放掉当前线程拥有的锁,然后过一段时间之后再申请锁,这样就能破坏掉请求与保持条件。相对于第一点更方便一些。
就比如说下图:
如果其中的一个线程不需要锁,比如说F线程,A线程想要B线程的锁,B线程想要C线程的锁,C线程想要D线程的锁…,如果说F线程不需要所,E线程需要F线程的锁的时候,F线程说我直接给你就行。那么就不会出现“死循环”的情况。
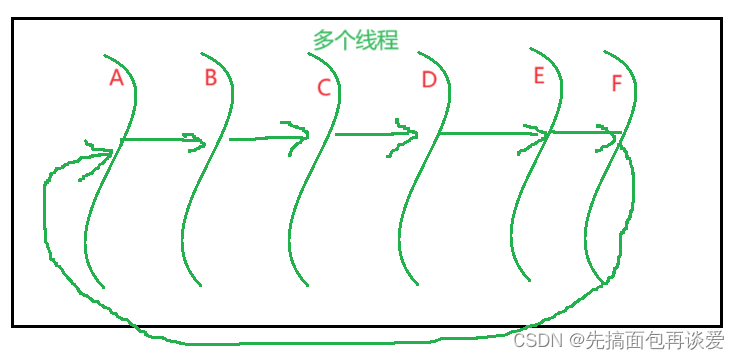
- 不剥夺条件我不知道如何破坏,一般情况下是不允许一个线程直接申请执行让占有锁的线程解锁的,如果有知道的同学可以在评论区中告诉我一下,谢谢。😊
- 其实就是第二点的那张图,不要出现循环的情况,如果用锁,就尽量用一个锁,如果用一个锁,就要让“锁住的区间”尽量短,锁用完后立刻解锁,这样串行区间越短,执行效率越高。尽量把临界资源的分配集中在一块,这样就能尽可能的减少锁的个数,不要频繁的加锁申请各种资源。
线程互斥和锁就讲的差不多了,不过还是遗留了点问题,只凭本篇中的知识无法解决,得通过线程同步来解决。下一篇就讲线程同步。
到此结束。。。