【加载数据自定义自己的Dataset类】
- 1 加载数据
- 2 数据转换
- 3 自定义Dataset类
- 4 划分训练集和测试集
- 5 提取一批次数据并绘制样例图
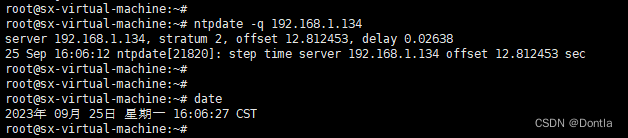
假设有四种天气图片数据全部存放与一个文件夹中,如下图所示:
├─dataset2
│ cloudy1.jpg
│ cloudy10.jpg
│ cloudy100.jpg
│ cloudy101.jpg
│ cloudy102.jpg
│ cloudy103.jpg
│ cloudy104.jpg
│ cloudy105.jpg
......
1 加载数据
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import torchvision
import glob
from torchvision import transforms
from torch.utils.data import Dataset
from PIL import Image
import glob
img_dir = r'./dataset2/*.jpg'
imgs = glob.glob(img_dir) # 读取所有图片路径
print(imgs[:3]) # 打印前3张图片
species = ['cloudy', 'rain', 'shine', 'sunrise']
species_to_idx = dict((c, i) for i, c in enumerate(species)) # 建立类别和序号字典
print(species_to_idx)
idx_to_species = dict((v, k) for k, v in species_to_idx.items()) # 反转类别和序号
print(idx_to_species)
输出如下:
['./dataset2\\cloudy1.jpg',
'./dataset2\\cloudy10.jpg',
'./dataset2\\cloudy100.jpg']
{'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
{0: 'cloudy', 1: 'rain', 2: 'shine', 3: 'sunrise'}
读取路径加载序号作为标签
labels = []
for img in imgs:
for i, c in enumerate(species):
if c in img:
labels.append(i)
print(labels[:3])
输出如下:
[0, 0, 0]
方法1:提前划分训练集和测试集,使用乱序后的index进行划分
np.random.seed(2022)
index = np.random.permutation(count)
imgs = np.array(imgs)[index]
labels = np.array(labels, dtype=np.int64)[index]
sep = int(count*0.8)
train_imgs = imgs[ :sep]
train_labels = labels[ :sep]
test_imgs = imgs[sep: ]
test_labels = labels[sep: ]
2 数据转换
transforms = transforms.Compose([
transforms.Resize((96, 96)),
transforms.ToTensor(),
transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5])
])
3 自定义Dataset类
class WT_dataset(Dataset):
def __init__(self, imgs_path, lables):
self.imgs_path = imgs_path
self.lables = lables
def __getitem__(self, index):
img_path = self.imgs_path[index]
lable = self.lables[index]
pil_img = Image.open(img_path)
pil_img = pil_img.convert("RGB")
pil_img = transforms(pil_img)
return pil_img, lable
def __len__(self):
return len(self.imgs_path)
# 加载数据
dataset = WT_dataset(imgs, labels)
4 划分训练集和测试集
count = len(dataset)
print(count)
# 方法2:划分训练集和测试集
train_count = int(0.8*count)
test_count = count - train_count
train_dataset, test_dataset = data.random_split(dataset, [train_count, test_count])
print(len(train_dataset), len(test_dataset))
# 批量加载数据
BTACH_SIZE = 16
train_dl = torch.utils.data.DataLoader(
train_dataset,
batch_size=BTACH_SIZE,
shuffle=True
)
test_dl = torch.utils.data.DataLoader(
test_dataset,
batch_size=BTACH_SIZE,
)
5 提取一批次数据并绘制样例图
imgs, labels = next(iter(train_dl)) #提取一批次数据
print(imgs.shape)
im = imgs[0].permute(1, 2, 0) # 将通道所在列放在后
print(im.shape)
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs[:6], labels[:6])):
img = (img.permute(1, 2, 0).numpy() + 1)/2
plt.subplot(2, 3, i+1)
plt.title(idx_to_species.get(label.item()))
plt.imshow(img)
plt.savefig('pics/example1.jpg', dpi=400)
输出如下:
torch.Size([16, 3, 96, 96])
torch.Size([3, 96, 96])
torch.Size([96, 96, 3])