Towards Generative Modeling of Urban Flow through Knowledge-enhanced Denoising Diffusion
摘要:尽管生成式人工智能在许多领域取得了成功,但在建模地理空间数据方面的潜力仍尚未充分发掘。城市流动,是一种典型的地理空间数据,对各种城市应用至关重要。现有的研究主要集中在基于历史流动数据预测城市流动的预测建模,而在数据稀疏地区或新规划区域可能无法获得这些数据。还有一些其他研究旨在预测区域之间的 OD 流动,但它们无法模拟城市流动随时间的动态变化。在本文中,我们研究了一个新的城市流动生成问题,为没有历史流动数据的地区生成动态城市流动。为了捕捉影响城市流动的多因素,如地区特征和城市环境,我们采用扩散模型为不同条件下的地区生成城市流动。首先,我们构建了一个城市知识图(UKG)来模拟城市环境和地区之间的关系,基于此,我们设计了一个知识增强的时空扩散模型(KSTDiff)来为每个地区生成城市流动。具体来说,为了准确地为具有不同流动量的地区生成城市流动,我们设计了一个由体积估计器引导的新颖扩散过程,该过程可学习并针对每个地区进行定制。此外,我们提出了一种知识增强的去噪网络,以捕捉城市流动的时空依赖关系以及城市环境在去噪过程中的影响。在四个真实世界数据集上的大量实验验证了我们的模型在城市流动生成方面的优越性。进一步的深入研究证明了生成城市流动数据的有效性,以及我们的模型在长期流动生成和城市流动预测方面的能力。我们的代码发布在:https://github.com/tsinghua-fib-lab/KSTDiff-Urban-flow-generation.
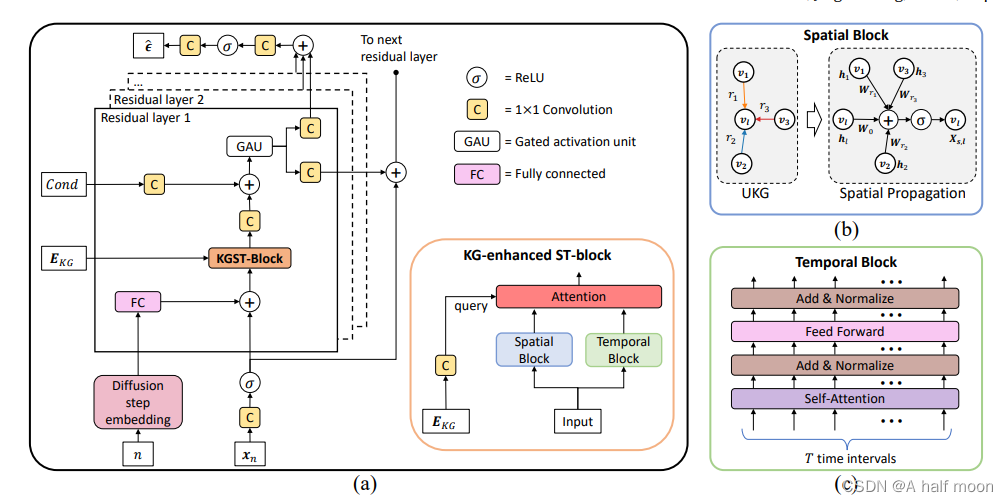
核心:知识增强的时空扩散模型(KSTDiff)
Beyond Accuracy: Measuring Representation Capacity of Embeddings to Preserve Structural and Contextual Information

评价:感觉是个很有用的研究角度,衡量嵌入式方法在捕捉结构和上下文信息方面的有效性的方法,里面大概简单选了一些指标来评估吧,但理论性一般,没有太数学的支撑。
Multi-view Fuzzy Representation Learning with Rules based Model
摘要:无监督多视角表示学习已经在挖掘多视角数据方面得到了广泛的研究。然而,一些关键的挑战仍然存在。一方面,现有方法无法全面探索多视角数据,因为它们通常学习视图之间的共同表示,而多视角数据既包含视图之间的共同信息,也包含每个视图内的特定信息。另一方面,为了挖掘数据之间的非线性关系,核方法或神经网络方法通常用于多视角表示学习。然而,这些方法缺乏可解释性。因此,本文提出了一种新的基于可解释的 Takagi-Sugeno-Kang(TSK)模糊系统(MVRL_FS)的多视角模糊表示学习方法。该方法从两个方面实现了多视角表示学习。首先,将多视角数据转换为高维模糊特征空间,同时探索视图之间的共同信息和每个视图的特定信息。其次,提出了一种基于 L_(2,1)-范数回归的新正则化方法来挖掘视图之间的一致性信息,同时通过 Laplacian 图保留数据的几何结构。最后,在许多基准多视角数据集上进行大量实验,验证了所提出方法的优势。
评价:多视图,多角度学习,更多更全面的信息
Automatic Personalized Impression Generation for PET Reports Using Large Language Models
目的:确定是否可以通过微调大型语言模型(LLM)为全身 PET 报告生成准确、个性化的印象。材料和方法:在教师推动算法下,用 PET 报告语料库训练了 12 个语言模型,将报告发现作为输入,临床印象作为参考。额外的输入标记编码阅读医生的身份,使模型学习医生特定的报告风格。我们的语料库包括了我们机构在 2010 年至 2022 年期间收集的 37,370 份回顾性 PET 报告。为了确定最佳 LLM,将 30 个评估指标与两名核医学(NM)医生的质量评分进行了基准测试,最相关的指标选择进行专家评估。在数据子集中,根据 6 个质量维度和一个总体效用评分(5 分制),模型生成的印象和原始临床印象由 3 名 NM 医生评估。每位医生审查了他们自己的 12 份报告和其他医生的 12 份报告。使用 bootstrap 重采样进行统计分析。结果:在所有评估指标中,领域自适应的 BARTScore 和 PEGASUSScore 与医生偏好的 Spearman 相关系数最高(分别为 0.568 和 0.563)。
资源:里面有很多摘要的模型,可以学习: