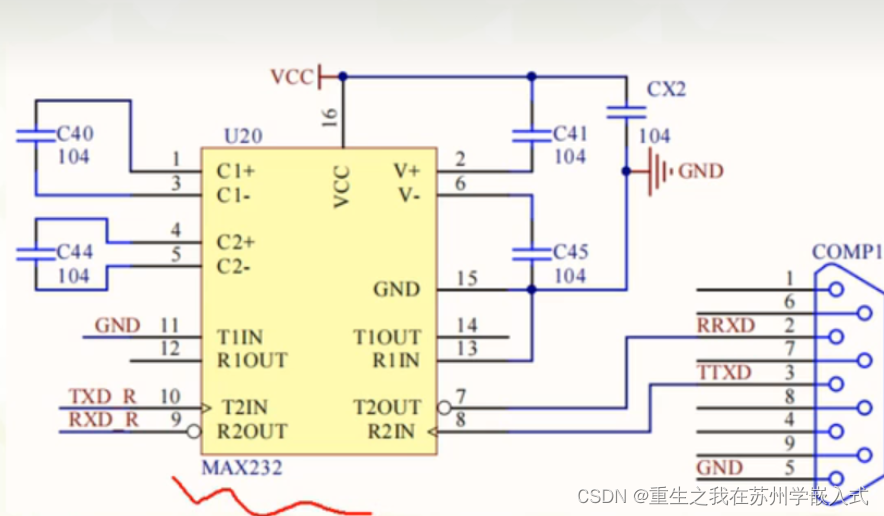
文章目录
- 泛化(Generalization):
- 过拟合(Overfitting):
- 例子

泛化(Generalization):
泛化是指机器学习模型在未见过的新数据上表现良好的能力。换句话说,一个好的机器学习模型应该不仅仅在训练数据上表现良好,还应该能够对来自相同数据分布的新数据进行准确预测。泛化是机器学习的关键目标,因为我们通常不是为了拟合训练数据而构建模型,而是为了解决真实世界中的问题。
良好的泛化能力取决于以下因素:
-
数据质量:高质量的训练数据通常能够帮助模型更好地泛化,因此数据预处理和清洗非常重要。
-
模型复杂性:模型应该足够简单,以避免过拟合(Overfitting)。过于复杂的模型可能会在训练数据上表现得非常好,但在新数据上泛化能力差。
-
正则化:使用正则化技术如 L1 正则化和 L2 正则化来控制模型的复杂性,以改善泛化性能。
-
特征工程:选择和创建合适的特征可以提高模型的泛化能力。
过拟合(Overfitting):
过拟合是指机器学习模型在训练数据上表现得过于好,以至于在未见过的新数据上表现不佳的情况。过拟合通常发生在模型过于复杂或训练数据量不足的情况下。
以下是导致过拟合的一些常见原因和特征:
-
模型复杂性:过于复杂的模型,如高阶多项式模型或深度神经网络,容易过拟合训练数据。
-
训练数据不足:如果训练数据量太小,模型可能会记住训练样本,而不是学习通用规律。
-
特征噪音:包含错误或不相关信息的特征可能导致模型过拟合。
-
训练时间过长:训练时间过长可能导致模型在训练数据上过多地调整权重,以适应数据的噪音。
防止过拟合的方法包括:
- 正则化:使用 L1 正则化和 L2 正则化来控制模型的复杂性,防止过多的权重分配给特征。
- 交叉验证:使用交叉验证来评估模型在不同数据子集上的性能,以检测过拟合。
- 增加训练数据:增加更多的训练数据可以帮助模型更好地泛化。
- 特征选择:选择最重要的特征,以减少不相关特征的影响。
- 提前停止训练:在验证集性能不再提高时停止训练,以防止过拟合。
在实际机器学习任务中,平衡模型的复杂性和泛化能力是一个重要的挑战。好的泛化模型通常能够在新数据上表现良好,而不会被训练数据的噪音所影响。
例子
当我们想要实现下面的图像的一个分类时:
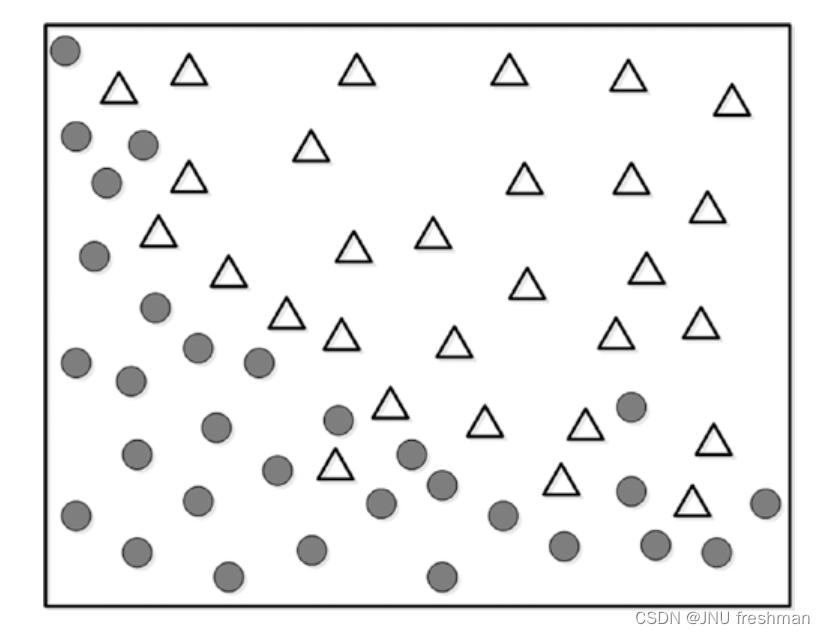
我们可以选取两种方式:
方式1:
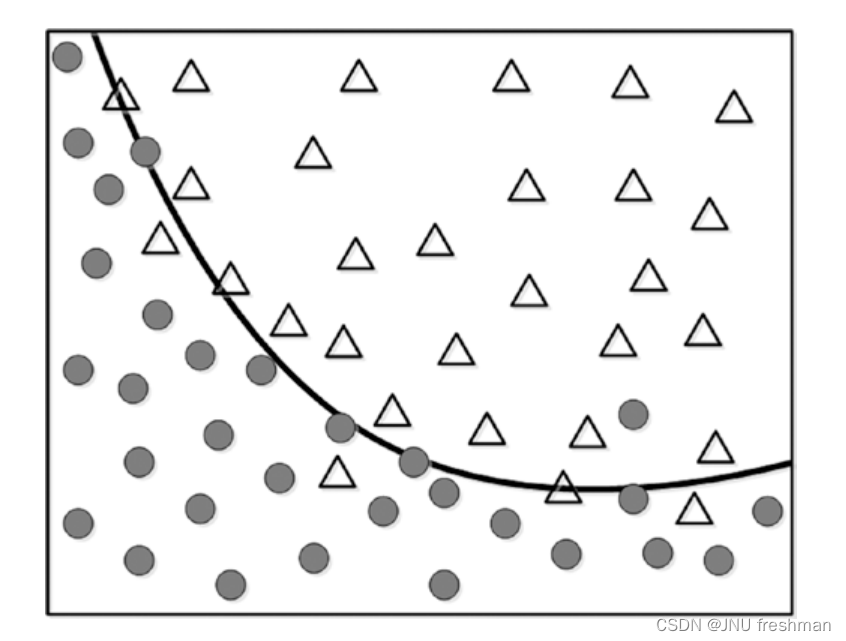
方式2:
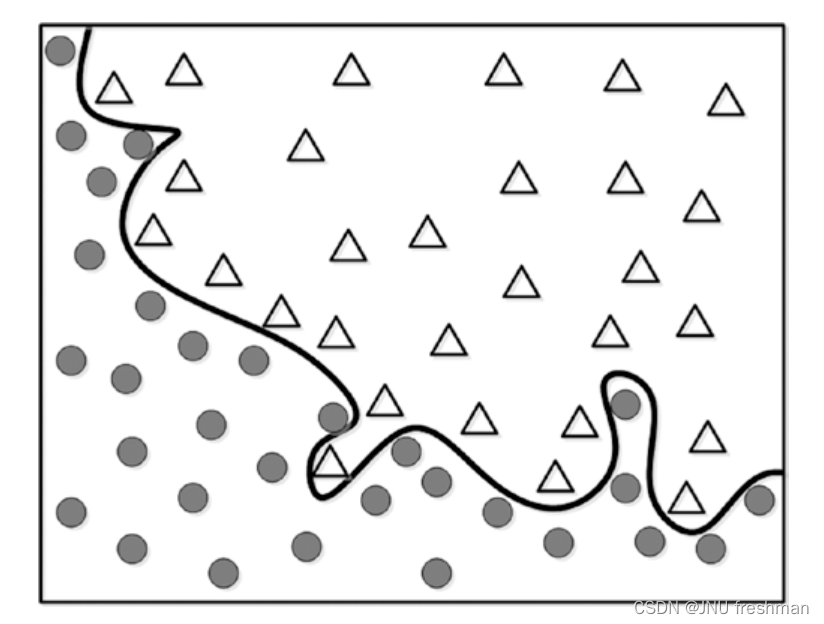
当然啦,方式二对于这个数据拟合得很好,似乎方式而更好,但是我要是换一个例子呢?
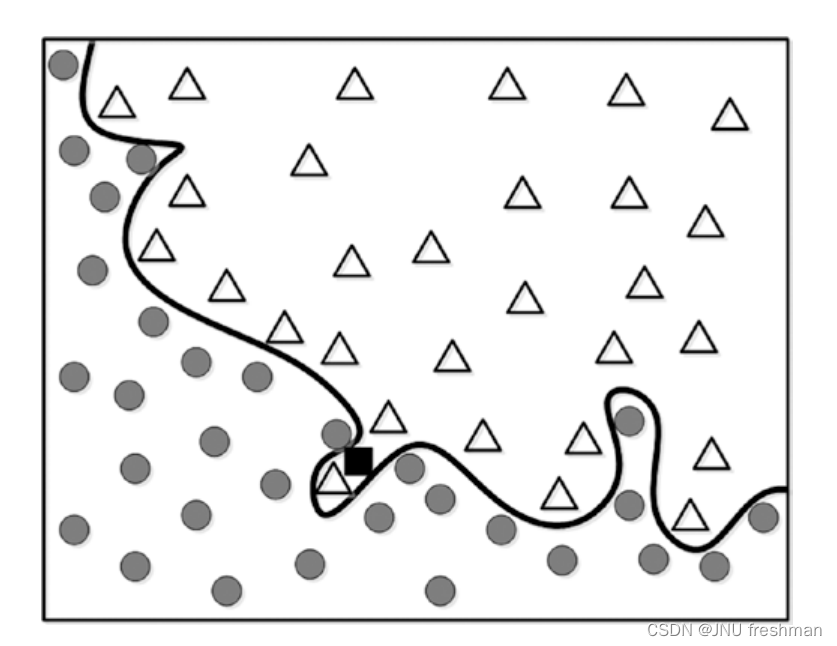
这样的话,就会显得没有那么完美了,当然啦,回到我们的概念,泛化就是要模型简单,对于各种数据都能表现较好,而过拟合只是对于某些数据表现良好,由此观之,方式1更为简单,能够体现泛化,而方式2就显得过拟合啦。