目录
一、RestClient操作索引库
1.1、RestClient是什么?
1.2、JavaRestClient 实现创建、删除索引库
1.2.1、前言
1.2.1、初始化 JavaRestClient
1.2.2、创建索引库
1.2.3、判断索引库是否存在
1.2.4、删除索引库
1.3、JavaRestClient 实现文档的 CRUD
1.3.1、初始化 JavaRestClient
1.3.2、添加文档(酒店数据)到索引库
1.3.3、根据 id 查询酒店数据
1.3.4、根据 id 修改酒店数据
1.3.5、根据 id 删除文档数据
1.3.6、批量导入文档
一、RestClient操作索引库
1.1、RestClient是什么?
前面我们已经了解了如何利用 DSL 语句去操作 es 的索引库和文档,但作为 java 程序员,将来肯定是要通过 java 代码去操作 es 的,那么想要实现这些,就需要通过 es 官方提供的 RestClient 实现.
RestClient 实际上就是 es 官方提供的各种语言的客户端,他的作用就是帮助我们组装 DSL 语句,然后发送 http 请求给 es 服务器,而我们只需要通过 java 代码将请求发送给客户端,然后客户端就会帮我们来处理剩下的这些事情.
官方文档地址:Elasticsearch Clients | Elastic
1.2、JavaRestClient 实现创建、删除索引库
1.2.1、前言
这里我将以一个 酒店 demo 工程来演示 JavaRestClient 的操作.
具体来讲,这是一个酒店的数据,创建的 sql 如下:
CREATE TABLE `tb_hotel` (
`id` bigint(20) NOT NULL COMMENT '酒店id',
`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',
`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',
`price` int(10) NOT NULL COMMENT '酒店价格;例:329',
`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',
`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',
`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',
`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',
`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',
`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',
`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',
`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
之后我们创建 索引库 的时候,就需要基于上述 sql 数据,来考虑 mapping 约束.
1.2.1、初始化 JavaRestClient
a)引入 es 的 RestHighLevelClient 依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
b)由于 SpringBoot 默认的 ES 版本是 7.6.2,因此这里我们需要覆盖默认的 ES 版本.
在 yml 配置文件中添加如下版本信息即可.
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
c)初始化 RestHighLevelClient.
这里我们创建一个测试类 HotelIndexTest ,用来演示 RestClient 操作的相关方法.
@SpringBootTest
class HotelIndexTest {
private RestHighLevelClient client;
@BeforeEach
public void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http//云服务器ip:9200")
//将来如果是集群,这里还可以通过 HttpHost.create 继续连接多个节点
));
}
@AfterEach
public void tearDown() throws IOException {
client.close();
}
}1.2.2、创建索引库
这里就需要根据前面提供的表结构来考虑 mapping 该如何建立.
具体的要考虑:字段名、数据类型、是否参与搜索、是否分词、如果分词,分词器是什么?
这里可以先使用 Kibana 来编写.
PUT /hotel
{
"mappings": {
"properties": {
"id": {
// id 按照数据库那边的定义,这里因该类型设置为 long
// 但是这里比较特殊,在索引库中 id 比较特殊,将来都是字符串类型.
// 又因为 id 将来不做分词处理,因此是 keyword 类型
// id 将来肯定要参与 crud ,因此 index 就默认为 true 即可.
"type": "keyword"
},
"name": {
// 酒店的名字需要搜索和分词.
"type": "text",
"analyzer": "ik_max_word", "copy_to": "all"
},
"address": {
// 有时候我们需要根据地址来查询附近的酒店,分词也是有必要的("例如 徐汇龙华西路315弄58号")
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"price": {
//将来要根据价格范围过滤酒店,所以需要搜索,分词就没必要了.
"type": "integer"
},
"score": {
//这里就和 price 一样了
"type": "integer"
},
"brand": {
//酒店的品牌肯定是不需要分词了,但一定需要参与搜索.
"type": "keyword",
"copy_to": "all"
},
"city": {
//城市名字不要分词,但需要参与搜索
"type": "keyword",
"copy_to": "all"
},
"star_name": {
//一星、二星、三星... 分词是没有意义的,组合起来才有意义.
//有的人就想住5星酒店,那肯定要参与搜索.
"type": "keyword"
},
"business": {
//商圈比如: 虹桥、外滩... 这些肯定不需要分词,但一定需要参与搜索.
"type": "keyword",
"copy_to": "all"
},
"pic": {
//图片这里就是一个 url 路径,不需要分词,也没有人会搜这个 url
//因此就这个 url 就可以当作关键字来处理.
"type": "keyword",
"index": false
},
"location": {
//在 es 中有两种特殊的方式,专门来表示地理坐标
//"geo_point": 表示地图上的点
//"geo_shape": 表示地图上的区域,也就是多个点组成.
//那么酒店肯定是属于一个点(毕竟从地球上看,再大的酒店也不过是点)
// geo_point 里面由 经度 和 纬度 组成,并且是这两拼在一起组成的字符串
"type": "geo_point"
},
"all": {
// 将来 name、address、brand... 这些字段大概率都需要参与搜索
// 也就意味着用户输入的的关键字,我们后端都需要根据多个字来搜.
// 并且我们可以想象以下 es 作搜索的时候, 根据多个字段去搜索的效率肯定是要比一个字段搜索效率要高
//这里对比以下数据库就清楚了.
//最重要的是, 我们也希望用户输入名称就能搜到相关的内容, 用户输入品牌也能搜到相关内容...
// es 就中有一个字段 "copy_to", 就是将当前字段的值拷贝到指定字段.
//这里我们就将需要搜索的字段都拷贝到 all 这个字段中就 ok
//这也就实现了在一个字段里, 搜索到多个字段的内容.
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}自定义 all 字段的解读:
将来 name、address、brand... 这些字段大概率都需要参与搜索,也就意味着用户输入的的关键字,我们后端都需要根据多个字来搜,并且我们可以想象以下 es 作搜索的时候, 根据多个字段去搜索的效率肯定是要比一个字段搜索效率要高这里对比以下数据库就清楚了~
最重要的是, 我们也希望用户输入名称就能搜到相关的内容, 用户输入品牌也能搜到相关内容... es 就中有一个字段 "copy_to", 就是将当前字段的值拷贝到指定字段。这里我们就将需要搜索的字段都拷贝到 all 这个字段中就 ok ,实现了在一个字段里, 搜索到多个字段的内容.
而且这里还做了优化,并不是真的吧文档拷贝进去,而是创建索引,将来你去查的时候,是看不到这些字段,但搜却能搜到(类似于根据指针找到数据所在位置).
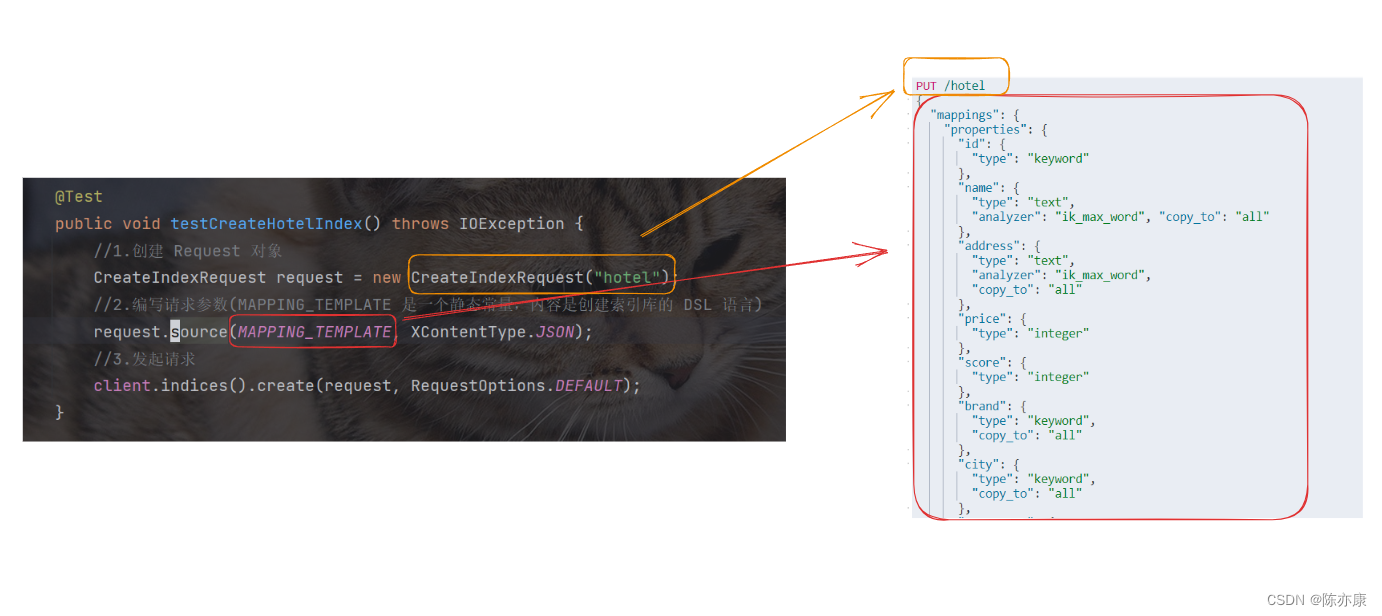
创建索引库代码如下:
@Test
public void testCreateHotelIndex() throws IOException {
//1.创建 Request 对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
//2.编写请求参数(MAPPING_TEMPLATE 是一个静态常量,内容是创建索引库的 DSL 语句)
request.source(MAPPING_TEMPLATE, XContentType.JSON);
//3.发起请求
client.indices().create(request, RequestOptions.DEFAULT);
}
- CreateIndexRequest 的构造参数就是请求创建的索引库的名字.
- MAPPING_TEMPLATE:是自定义的静态常量,内容是创建索引库的 DSL 语句.
- client.indices(): 这个方法的返回值是一个对象(indices 是 index 的复数形式),包含了操作索引库的所有方法.
- RequestOptions.DEFAULT :就表示走默认的方法.
执行以后发现运行成功了~
之后去 Elastic DevTools 上去 GET,就可以看到新增的索引库了~
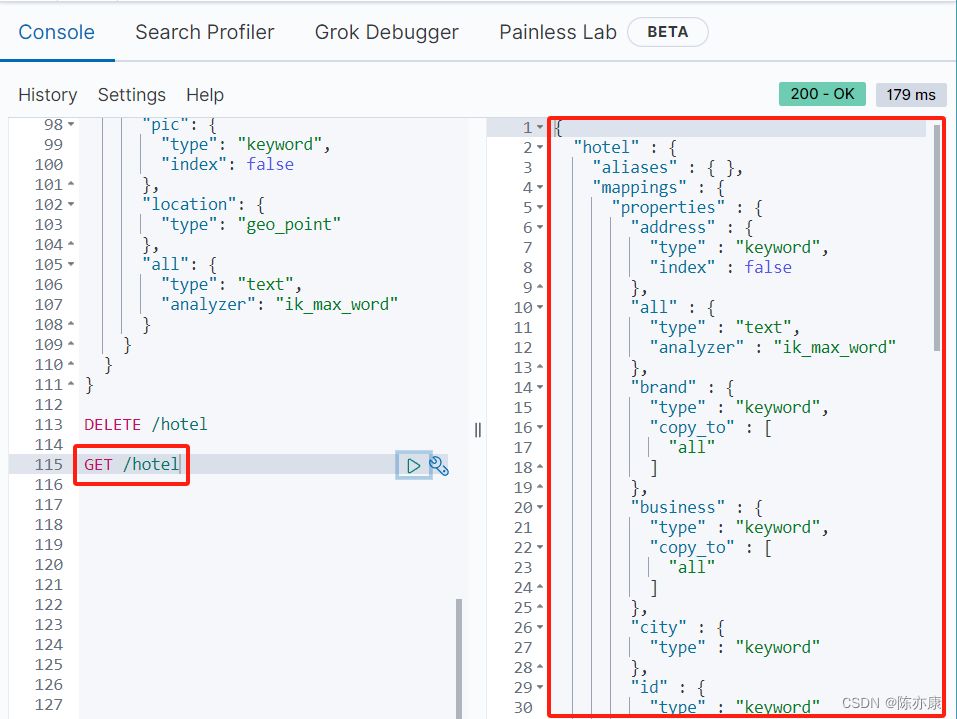
1.2.3、判断索引库是否存在
判断索引库是否存在代码如下:
@Test
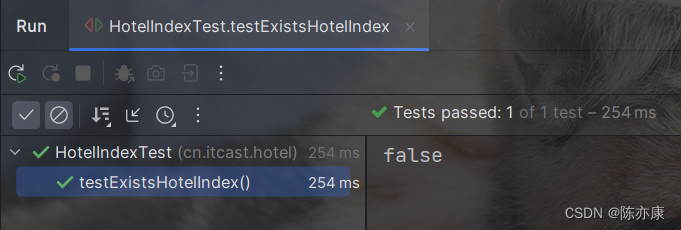
public void testExistsHotelIndex() throws IOException {
//1.创建 Request 对象
GetIndexRequest request = new GetIndexRequest("hotel");
//2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
很多时候,我们先写 client.indices().exists 就可以之间看出需要什么参数
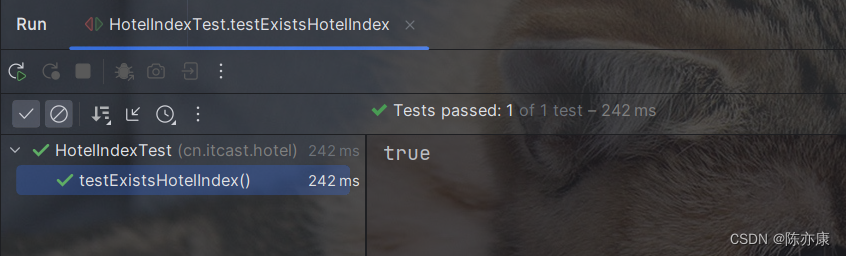
运行以后,可以看到通过了(true 是因为上个案例添加索引库是存在的).
1.2.4、删除索引库
判断删除索引库代码如下:
@Test
public void testDeleteHotelIndex() throws IOException {
//1.创建 Request 对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
//2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
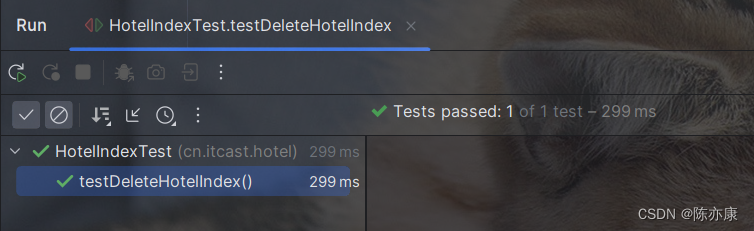
之后再查询就发现查询不到了,表明删除成功.
1.3、JavaRestClient 实现文档的 CRUD
1.3.1、初始化 JavaRestClient
这里的初始化操作和操作索引库的初始化一样(本质上都是连接 JavaRestClient 客户端).
@SpringBootTest
class HotelDocumentTest {
private RestHighLevelClient client;
@BeforeEach
public void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://云服务器ip:9200")
));
}
@AfterEach
public void tearDown() throws IOException {
client.close();
}
}1.3.2、添加文档(酒店数据)到索引库
Ps:操作文档前需要先创建对应索引库
这里我先通过 MyBatis-Puls 从数据库拿到数据,然后添加文档.
实体类如下(这里重写构造方法主要是为了 location 属性(地理位置),将经度,纬度合二为一):
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
@NoArgsConstructor:生成无参构造.
编写添加文档代码:
@Test
public void testAddDocument() throws IOException {
//1.获取酒店数据
Hotel hotel = hotelService.getById(5865979L);
//2.转化文档(主要是地理位置)
HotelDoc hotelDoc = new HotelDoc(hotel);
//3.转化为 JSON 格式
String hotelJson = objectMapper.writeValueAsString(hotelDoc);
//4.构造请求
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
//5.添加请求参数(json 格式)
request.source(hotelJson, XContentType.JSON);
//6.发送请求
client.index(request, RequestOptions.DEFAULT);
}
运行后发现通过了

在 Kibana 上查询就可以得到对应的数据
1.3.3、根据 id 查询酒店数据
这里值得注意的是:通过 client.get 查询到的是一个 GetResponse 对象,需要获取里面的原数据.
代码如下:
@Test
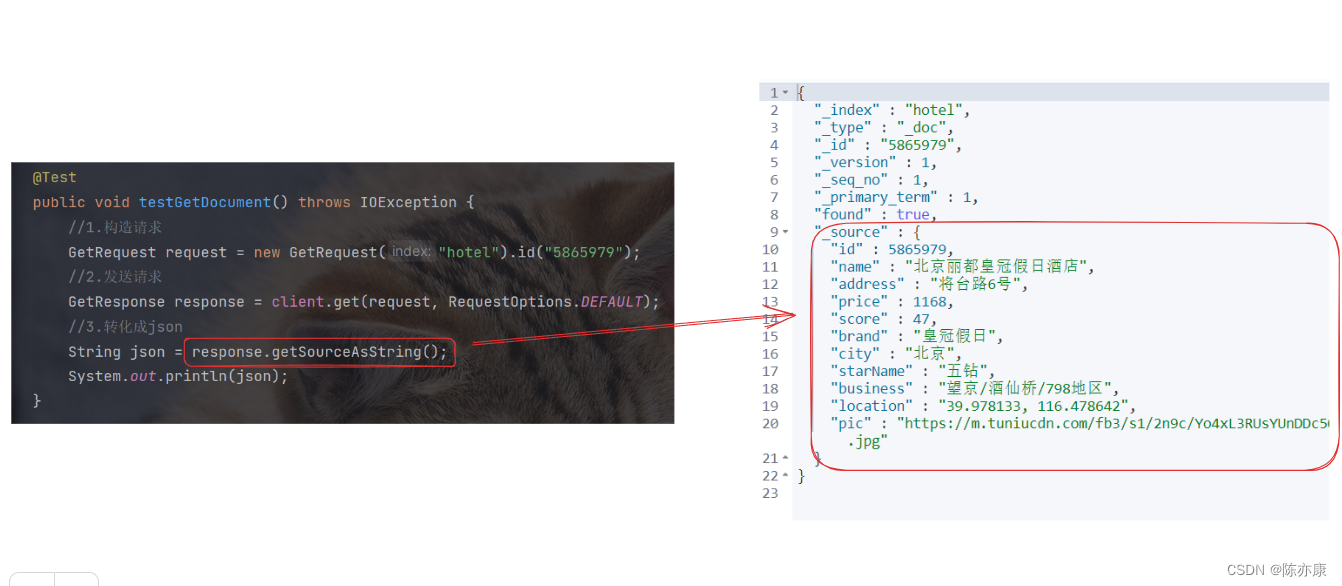
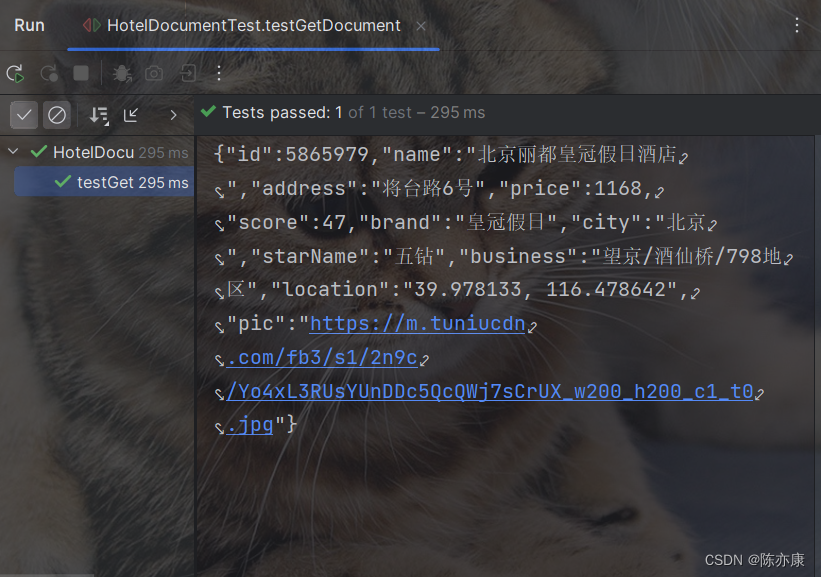
public void testGetDocument() throws IOException {
//1.构造请求
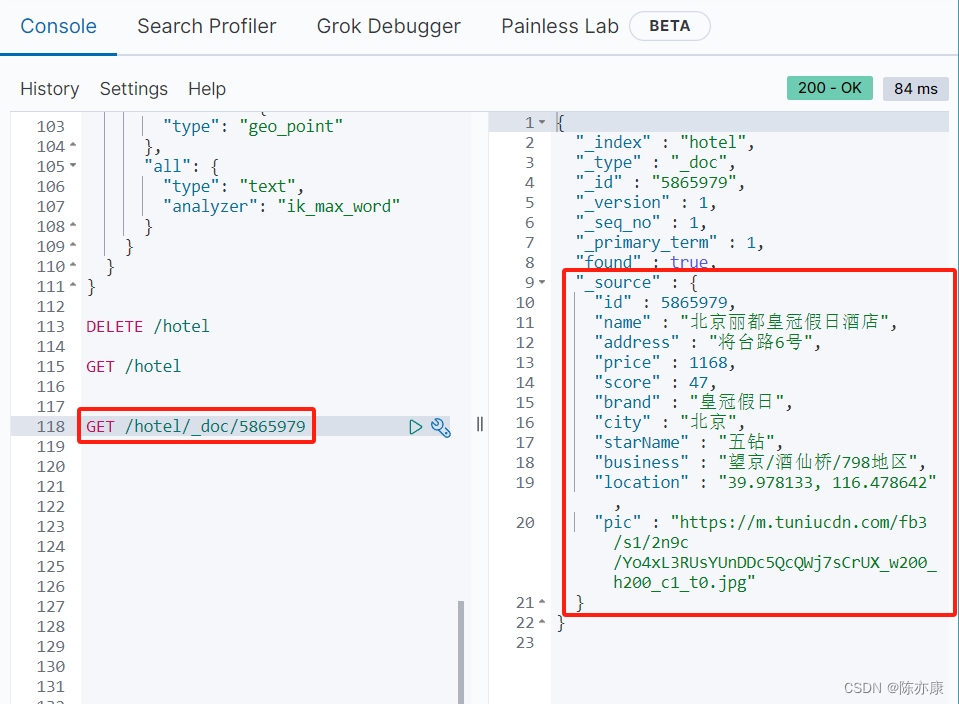
GetRequest request = new GetRequest("hotel").id("5865979");
//2.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3.转化成json
String json = response.getSourceAsString();
System.out.println(json);
}
运行后就可以得到对应的数据
1.3.4、根据 id 修改酒店数据
修改文档数据有两种方式(之前提到过):
- 全量更新:再次写入 id 一样的文档,就会删除旧文档,添加新文档.
- 局部更新(演示这个):只更新部分字段.
@Test
public void testUpdateDocument() throws IOException {
//1.构造请求
UpdateRequest request = new UpdateRequest("hotel", "5865979");
//2.填写参数
request.doc(
"name", "地表最强酒店",
"price", "99999"
);
//3.发送请求
client.update(request, RequestOptions.DEFAULT);
}

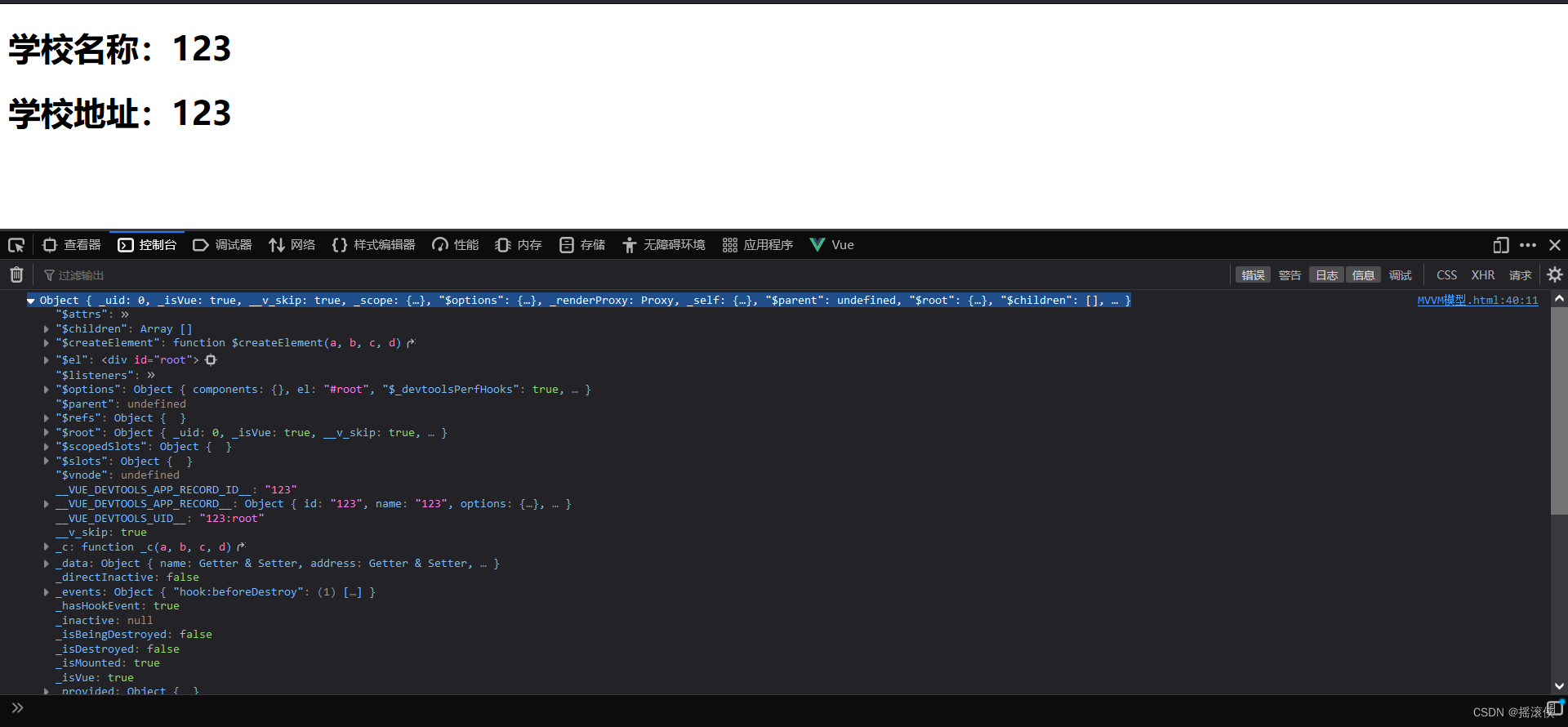
在 Kibana 上通过 GET 查询如下:
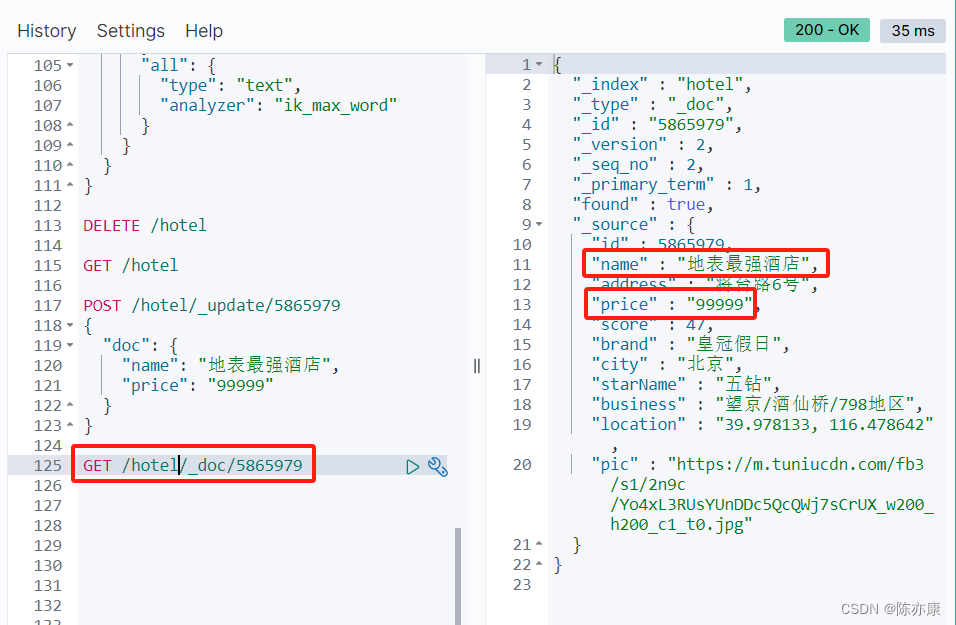
1.3.5、根据 id 删除文档数据
删除文档代码如下:
@Test
public void testDeleteDocument() throws IOException {
//1.构造请求
DeleteRequest request = new DeleteRequest("hotel", "5865979");
//2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}
1.3.6、批量导入文档
例如导入酒店的所有数据,代码如下:
@Test
public void testBulkDocument() throws IOException {
//1.获取酒店所有数据
List<Hotel> hotelList = hotelService.list();
//2.构造请求
BulkRequest request = new BulkRequest();
//3.准备参数
for(Hotel hotel : hotelList) {
//转化为文档(主要是地理位置)
HotelDoc hotelDoc = new HotelDoc(hotel);
String json = objectMapper.writeValueAsString(hotelDoc);
request.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(json, XContentType.JSON));
}
//4.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}
运行后可以看到通过了

之后再 Kibana 上随机查询一个酒店数据都是存在的