char* trtModelStream{ nullptr }; //char* trtModelStream==nullptr; 开辟空指针后 要和new配合使用,比如89行 trtModelStream = new char[size]
size_t size{ 0 };//与int固定四个字节不同有所不同,size_t的取值range是目标平台下最大可能的数组尺寸,一些平台下size_t的范围小于int的正数范围,又或者大于unsigned int. 使用Int既有可能浪费,又有可能范围不够大。
std::ifstream file("D:/match/SimpleNet/pt/feature_aggregator.trt", std::ios::binary);
std::cout << file.good();
if (file.good()) {
std::cout << "load engine success" << std::endl;
file.seekg(0, file.end);//指向文件的最后地址
size = file.tellg();//把文件长度告诉给size
file.seekg(0, file.beg);//指回文件的开始地址
trtModelStream = new char[size];//开辟一个char 长度是文件的长度
assert(trtModelStream);//
file.read(trtModelStream, size);//将文件内容传给trtModelStream
file.close();//关闭
}
else {
std::cout << "load engine failed" << std::endl;
return 1;
}
IRuntime* runtime = createInferRuntime(gLogger);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);
IExecutionContext *context = engine->createExecutionContext();
void* buffers[2];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
// Create GPU buffers on device
cudaMalloc(&buffers[inputIndex], 3 * INPUT_H * INPUT_W * sizeof(float));
cudaMalloc(&buffers[outputIndex], OUTPUT_SIZE * sizeof(float));
context->setTensorAddress(INPUT_BLOB_NAME, buffers[inputIndex]);
context->setTensorAddress(OUTPUT_BLOB_NAME,buffers[outputIndex]);
cudaStream_t stream;
cudaStreamCreate(&stream);
Mat src = imread("D:/dataset/coco/blag/5FC4EZ01A00009_CD_20221223111215_1.png", 1);
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
//uchar * data = new uchar[512 * 512 * 3];
cudaMemcpyAsync(buffers[inputIndex],src.data,3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream);
//context.enqueue(batchSize, buffers, stream, nullptr);
context->enqueueV3(stream);
// 假设CUDA stream中的数据是一张图像,大小为128x128,数据类型为float
int width = 4096;
int height = 512;
//int channel = 512;
size_t dataSize = width * height * sizeof(float);
// 在主机内存中分配空间
float* hostData = new float[dataSize];
//在CUDA stream中分配空间
float* deviceData = nullptr;
//cudaError_t cudaMemcpy(void *dist, const void* src, size_t count, CudaMemcpyKind kind);
cudaMalloc((void **)&deviceData, dataSize);
//cudaMalloc(float(**)&addr, n * sizeof(float))
// 将数据从CUDA stream拷贝到主机内存
cudaMemcpyAsync(hostData, deviceData, dataSize, cudaMemcpyDeviceToHost, stream);
// 等待CUDA操作完成
cudaStreamSynchronize(stream);
// 将主机内存中的数据转换为cv::Mat类型
cv::Mat img = cv::Mat::zeros(cv::Size(width,height),CV_8U);
memcpy(img.data,hostData,dataSize);

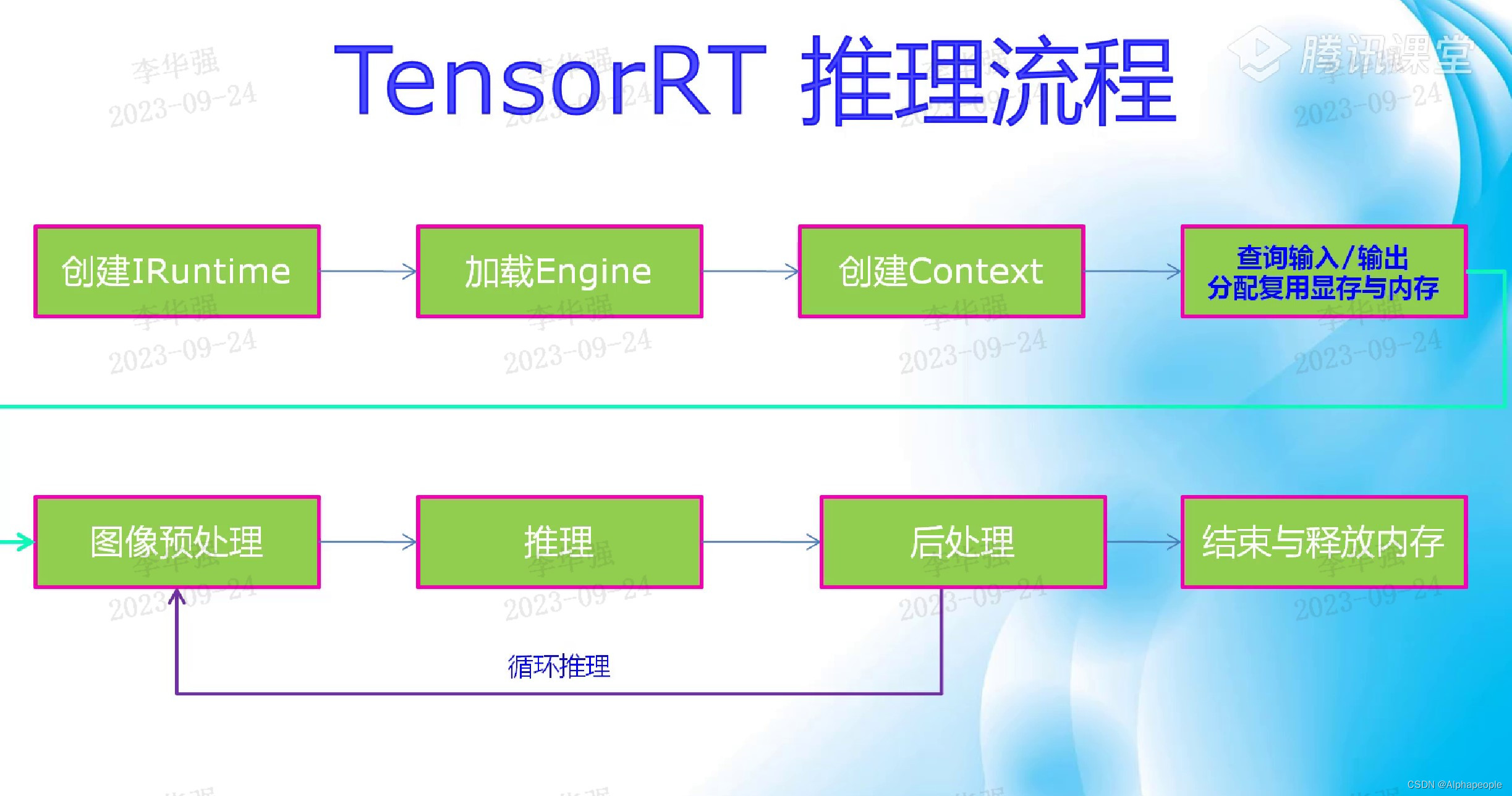
onnx导engine:
trtexec.exe --onnx=resnet18.onnx --saveEngine=resnet18.engine --fp16