Basic SHAP Interaction Value Example in XGBoost
- XGBoost中的基本SHAP交互值示例
- 解释没有交互的线性函数
- SHAP交互值
- 用一次交互解释线性模型
- SHAP交互值
用到的环境是python3.7(基于上一篇文章的环境),然后再装了xgboost和shap,没报什么错,挺顺利。。。
conda install xgboost
conda install shap
官方的代码在https://github.com/shap/shap/blob/master/notebooks/tabular_examples/tree_based_models/Basic%20SHAP%20Interaction%20Value%20Example%20in%20XGBoost.ipynb
XGBoost中的基本SHAP交互值示例
这个notebook展示了如何计算一个非常简单的函数的SHAP交互值。我们从一个简单的线性函数开始,然后添加一个交互项,看看它如何改变SHAP值和SHAP交互值。
SHAP值(Shapley Additive exPlanations)的主要思想就是Shapley值,Shapley值是一个来自合作博弈论(coalitional game theory)的方法,由Shapley在1953年创造的Shapley值是一种根据玩家对总支出的贡献来为玩家分配支出的方法,玩家在联盟中合作并从这种合作中获得一定的收益。用shaply值去解释机器学习的预测的话,其中“总支出”就是数据集单个实例的模型预测值,“玩家”是实例的特征值,“收益”是该实例的实际预测减去所有实例的平均预测。
一个简单模型(如线性回归)的最好解释是模型本身,它们容易理解。对于复杂的模型(如集成模型或深度学习模型),它们是不容易理解的,我们不能使用原始模型本身去作为它的解释,相反,我们必须使用一个简单的解释模型,我们将其定义为原始模型的任意解释逼近。SHAP将Shapley值解释表示为一种可加特征归因方法,SHAP将模型的预测值解释为每个输入特征的归因值之和。
当前的归因方法不能直接表示相互作用,但必须在每个特征之间划分相互作用的影响。为了直接捕捉成对的相互作用效果,我们基于博弈论中Shapley交互指数扩展SHAP值,提出了SHAP交互值(SHAP INTERACTION VALUES),SHAP交互值保证了一致性的同时可以解释单个预测的交互效果。
特征归因通常在输入特征之间分配,每个特征分配一个归因值,但是我们可以通过将交互效果与主要效果分离来获得额外的信息。如果我们考虑成对的相互作用,就会得到一个属性值矩阵,表示所有的两个特征对给定模型预测的影响。由于SHAP值是基于博弈论中的经典Shapley值,所以通过更现代的Shapley交互指标可以得到对交互效果的自然扩展。
import xgboost
import numpy as np
import shap
有一点警告提示,没啥影响,问题不大,忽略。
C:\Users\gxx\anaconda3\envs\tf-py37\lib\site-packages\tqdm\auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
解释没有交互的线性函数
# simulate some binary data and a linear outcome with an interaction term
# note we make the features in X perfectly independent of each other to make
# it easy to solve for the exact SHAP values
N = 2000
X = np.zeros((N,5))
X[:1000,0] = 1
X[:500,1] = 1
X[1000:1500,1] = 1
X[:250,2] = 1
X[500:750,2] = 1
X[1000:1250,2] = 1
X[1500:1750,2] = 1
X[:,0:3] -= 0.5
y = 2*X[:,0] - 3*X[:,1]
# ensure the variables are independent
np.cov(X.T)
输出结果:
array([[0.25012506, 0. , 0. , 0. , 0. ],
[0. , 0.25012506, 0. , 0. , 0. ],
[0. , 0. , 0.25012506, 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ]])
# and mean centered
X.mean(0)
输出结果:
array([0., 0., 0., 0., 0.])
# train a model with single tree
Xd = xgboost.DMatrix(X, label=y)
model = xgboost.train({
'eta':1, 'max_depth':3, 'base_score': 0, "lambda": 0
}, Xd, 1)
print("Model error =", np.linalg.norm(y-model.predict(Xd)))
print(model.get_dump(with_stats=True)[0])
输出结果:
Model error = 0.0
0:[f1<0] yes=1,no=2,missing=1,gain=4500,cover=2000
1:[f0<0] yes=3,no=4,missing=3,gain=1000,cover=1000
3:leaf=0.5,cover=500
4:leaf=2.5,cover=500
2:[f0<0] yes=5,no=6,missing=5,gain=1000,cover=1000
5:leaf=-2.5,cover=500
6:leaf=-0.5,cover=500
# make sure the SHAP values add up to marginal predictions
pred = model.predict(Xd, output_margin=True)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(Xd)
np.abs(shap_values.sum(1) + explainer.expected_value - pred).max()
输出结果:
0.0
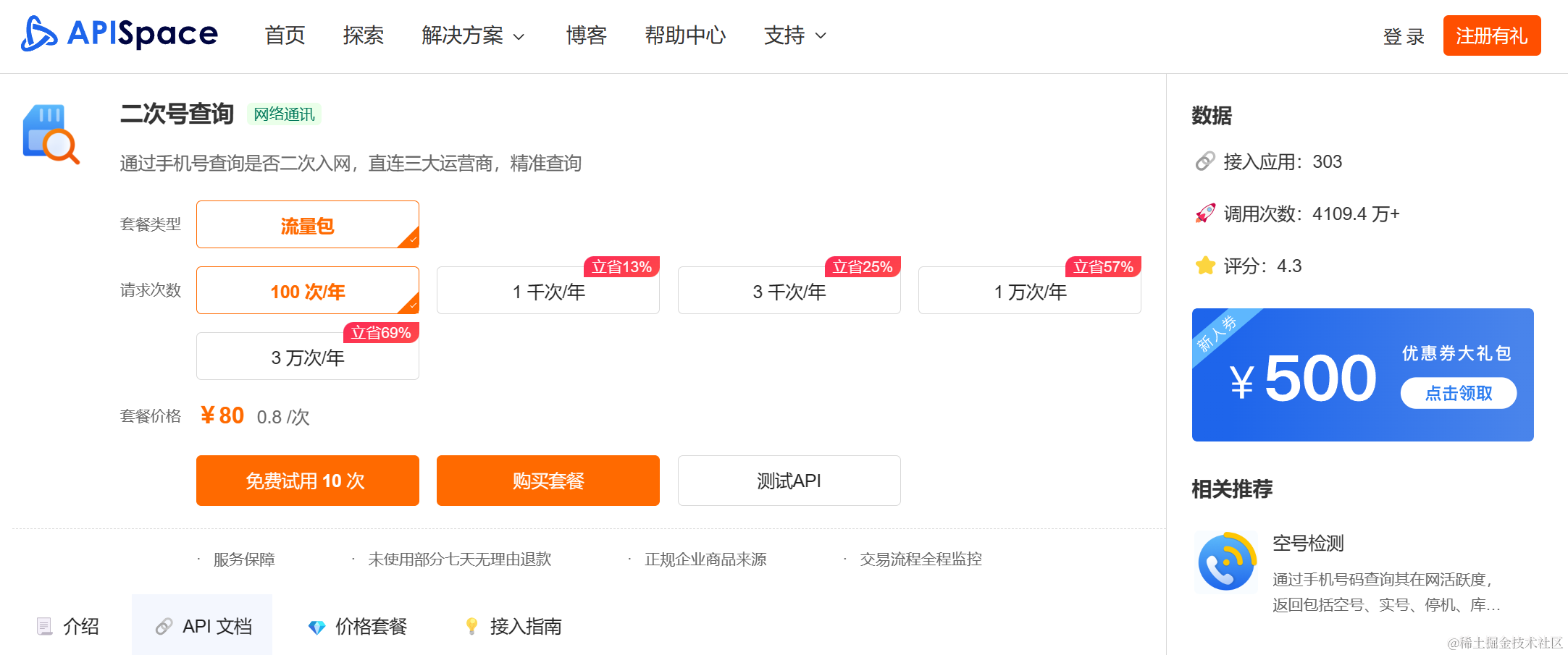
如果我们建立一个汇总图,我们可以看到只有特征1和2有任何影响,并且它们的影响只有两个可能的大小(一个为-0.5,一个为0.5)。
shap.summary_plot(shap_values, X)
输出结果:
# train a linear model
from sklearn import linear_model
lr = linear_model.LinearRegression()
lr.fit(X, y)
lr_pred = lr.predict(X)
lr.coef_.round(2)
输出结果:
array([ 2., -3., 0., 0., 0.])
# Make sure the computed SHAP values match the true SHAP values
# (we can compute the true SHAP values directly for this simple case)
main_effect_shap_values = lr.coef_ * (X - X.mean(0))
np.linalg.norm(shap_values - main_effect_shap_values)
输出结果:
2.1980906908667245e-13
SHAP交互值
注意,当不存在交互作用时,SHAP交互作用值只是对角线上的SHAP值的对角线矩阵。
shap_interaction_values = explainer.shap_interaction_values(Xd)
shap_interaction_values[0]
输出结果:
array([[ 1. , 0. , 0. , 0. , 0. ],
[ 0. , -1.5, 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. , 0. ]], dtype=float32)
# ensure the SHAP interaction values sum to the marginal predictions
np.abs(shap_interaction_values.sum((1,2)) + explainer.expected_value - pred).max()
输出结果:
0.0
# ensure the main effects from the SHAP interaction values match those from a linear model
dinds = np.diag_indices(shap_interaction_values.shape[1])
total = 0
for i in range(N):
for j in range(5):
total += np.abs(shap_interaction_values[i,j,j] - main_effect_shap_values[i,j])
total
输出结果:
1.3590530773134374e-11
用一次交互解释线性模型
# simulate some binary data and a linear outcome with an interaction term
# note we make the features in X perfectly independent of each other to make
# it easy to solve for the exact SHAP values
N = 2000
X = np.zeros((N,5))
X[:1000,0] = 1
X[:500,1] = 1
X[1000:1500,1] = 1
X[:250,2] = 1
X[500:750,2] = 1
X[1000:1250,2] = 1
X[1500:1750,2] = 1
X[:125,3] = 1
X[250:375,3] = 1
X[500:625,3] = 1
X[750:875,3] = 1
X[1000:1125,3] = 1
X[1250:1375,3] = 1
X[1500:1625,3] = 1
X[1750:1875,3] = 1
X[:,:4] -= 0.4999 # we can't exactly mean center the data or XGBoost has trouble finding the splits
y = 2* X[:,0] - 3 * X[:,1] + 2 * X[:,1] * X[:,2]
X.mean(0)
输出结果:
array([1.e-04, 1.e-04, 1.e-04, 1.e-04, 0.e+00])
# train a model with single tree
Xd = xgboost.DMatrix(X, label=y)
model = xgboost.train({
'eta':1, 'max_depth':4, 'base_score': 0, "lambda": 0
}, Xd, 1)
print("Model error =", np.linalg.norm(y-model.predict(Xd)))
print(model.get_dump(with_stats=True)[0])
输出结果:
Model error = 1.73650378306776e-06
0:[f1<0.000100001693] yes=1,no=2,missing=1,gain=4499.40039,cover=2000
1:[f0<0.000100001693] yes=3,no=4,missing=3,gain=999.999756,cover=1000
3:[f2<0.000100001693] yes=7,no=8,missing=7,gain=124.949997,cover=500
7:leaf=0.99970001,cover=250
8:leaf=-9.99800031e-05,cover=250
4:[f2<0.000100001693] yes=9,no=10,missing=9,gain=124.949951,cover=500
9:leaf=2.99970007,cover=250
10:leaf=1.99989998,cover=250
2:[f0<0.000100001693] yes=5,no=6,missing=5,gain=999.999756,cover=1000
5:[f2<0.000100001693] yes=11,no=12,missing=11,gain=125.050049,cover=500
11:leaf=-3.0000999,cover=250
12:leaf=-1.99989998,cover=250
6:[f2<0.000100001693] yes=13,no=14,missing=13,gain=125.050018,cover=500
13:leaf=-1.00010002,cover=250
14:leaf=0.000100019999,cover=250
# make sure the SHAP values add up to marginal predictions
pred = model.predict(Xd, output_margin=True)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(Xd)
np.abs(shap_values.sum(1) + explainer.expected_value - pred).max()
输出结果:
4.7683716e-07
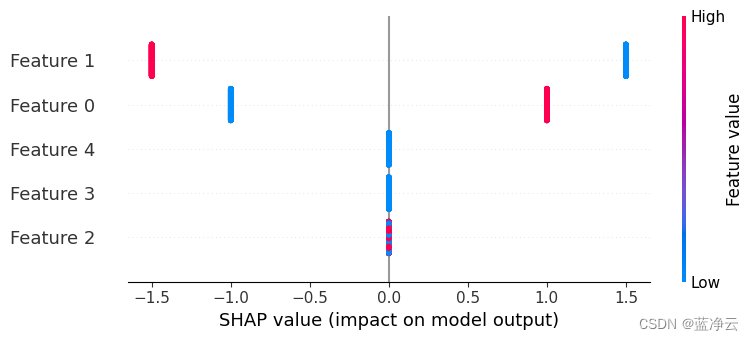
如果我们构建一个总结图,我们会发现现在只有功能3和4无关紧要,而功能1可能由于交互而具有四种可能的效果大小。
shap.summary_plot(shap_values, X)
输出结果:
# train a linear model
lr = linear_model.LinearRegression()
lr.fit(X, y)
lr_pred = lr.predict(X)
lr.coef_.round(2)
输出结果:
array([ 2., -3., 0., 0., 0.])
# Note that the SHAP values no longer match the main effects because they now include interaction effects
main_effect_shap_values = lr.coef_ * (X - X.mean(0))
np.linalg.norm(shap_values - main_effect_shap_values)
输出结果:
15.811387829626847
SHAP交互值
# SHAP interaction contributions:
shap_interaction_values = explainer.shap_interaction_values(Xd)
shap_interaction_values[0].round(2)
输出结果:
array([[ 1. , 0. , 0. , 0. , 0. ],
[ 0. , -1.5 , 0.25, 0. , 0. ],
[ 0. , 0.25, 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. , 0. ]], dtype=float32)
# ensure the SHAP interaction values sum to the marginal predictions
np.abs(shap_interaction_values.sum((1,2)) + explainer.expected_value - pred).max()
输出结果:
4.7683716e-07
# ensure the main effects from the SHAP interaction values match those from a linear model.
# while the main effects no longer match the SHAP values when interactions are present, they do match
# the main effects on the diagonal of the SHAP interaction value matrix
dinds = np.diag_indices(shap_interaction_values.shape[1])
total = 0
for i in range(N):
for j in range(5):
total += np.abs(shap_interaction_values[i,j,j] - main_effect_shap_values[i,j])
total
输出结果:
0.0005347490550661898
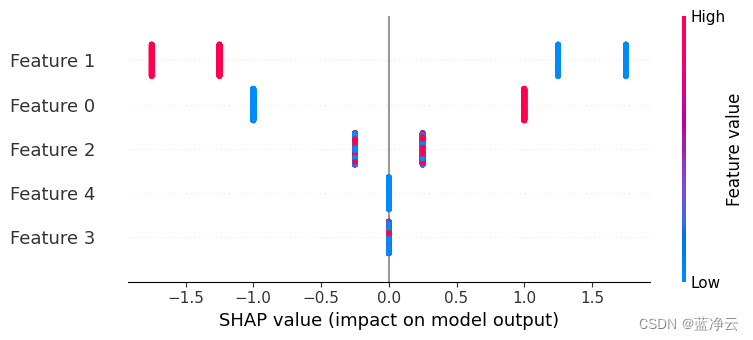
如果我们为特征0构建依赖图,我们会发现它只需要两个值,并且这些值完全取决于特征的值(特征0的值完全决定了它的效果,因为它与其他特征没有交互)。
shap.dependence_plot(0, shap_values, X)
输出结果:
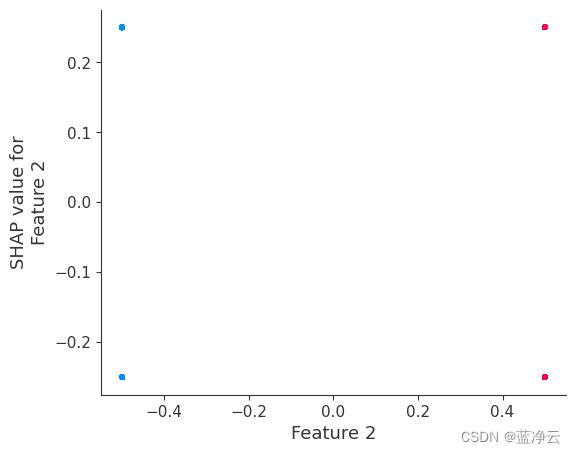
相反,如果我们为特征2建立依赖图,我们会看到它采用了4个可能的值,并且它们并不完全由特征2的值决定,相反,它们也取决于特征3的值。相关性图中的这种垂直分布表示非线性相互作用的影响。
shap.dependence_plot(2, shap_values, X)
警告: invalid value encountered in true_divide invalid value encountered in true_divide


![[计算机入门] Windows附件程序介绍(影音类)](https://img-blog.csdnimg.cn/720a25c99cbd4f108a4d1d2d48c37871.png)