论文《Enhancing Hypergraph Neural Networks with Intent Disentanglement for Session-based Recommendation》阅读
- Introduction
- Preliminaries
- 问题形式化
- Hypergraph
- Methodology
- 嵌入层 (Intent-Aware Embedding)
- 会话超图构建
- 微观解耦
- 宏观解耦
- 预测层
- 模型训练
- Experiments
- 论文总结
今天给大家带来的是SIGIR 2022 一篇短文《Enhancing Hypergraph Neural Networks with Intent Disentanglement for Session-based Recommendation》,论文通过引入多意图解耦视角,分别从微观角度(超图构造和Intent Graph方法)与宏观角度(自监督意图分离)完成了会话推荐问题。论文由清华大学、美团共同完成,提出模型HIDE(Hypergraph Neural Networks with Intent DisEntanglement)。
论文地址:https://doi.org/10.1145/3477495.3531794
Introduction
作者在 intro 中回顾了会话推荐(Session-based Recommendation, SBR)的主要问题:
- 用户兴趣是动态的,复杂的
- Session 序列中除了能够体现user intent 的交互以外还包含 noises。
因此,作者提出了HIDE,主要思路就是将一个 item 对应到多个( K K K 个)embedding,每个 embedding 对应到一个 intent,通过在微观角度、宏观角度分别完成对意图的解耦(Disentanglement),完成SBR预测。
具体来说,微观角度,主要通过构造超图,通过 n2e (节点到超边)和 e2n (超边到节点)完成节点的embedding更新。宏观角度,对 K K K 个 intent 进行分离,主张多个 intent 应该对应到不同的 target item click,进行自监督训练,构成 auxiliary task。
下面进行详细介绍。
Preliminaries
问题形式化
V = { v 1 , v 2 , ⋯ , v m } \mathcal{V}=\{v_1, v_2, \cdots, v_m \} V={v1,v2,⋯,vm} 表示物品集合,个数一共 m m m 个。 一个匿名会话序列 s s s 由若干通过时间顺序排列的交互物品组成,表示为: s = [ v s , 1 , v s , 2 , ⋯ , v s , n ] s = \left[ v_{s,1}, v_{s,2}, \cdots, v_{s,n} \right] s=[vs,1,vs,2,⋯,vs,n], v s , i ∈ V v_{s,i} \in \mathcal{V} vs,i∈V 表示交互物品, n n n 表示会话长度。
问题形式化表示为:给定一个会话 session s s s 的前 n n n 个交互物品,需要预测第 n + 1 n+1 n+1 个物品( v s , n + 1 v_{s, n+1} vs,n+1)是什么。具体来说,完成一个排序问题,生成 K K K 个候选物品,完成模型的 evaluation。
Hypergraph
超图(Hypergraph),其实就是点集。正常图通过点,以及两点之间的连线组成边构成。
超图就是在这个概念上更进一步,若干个点构成一个超边(Hyperedge),可以理解为超边中的节点两两连接。具体表示为:
G
=
(
V
,
E
)
\mathcal{G} = \left(\mathcal{V}, \mathcal{E} \right)
G=(V,E),
V
\mathcal{V}
V 还是原来那个
V
\mathcal{V}
V,
E
=
{
e
}
\mathcal{E} = \left\{ e \right\}
E={e} 表示超边集合,每条超边表示为
e
=
{
v
i
1
,
v
i
2
,
⋯
,
v
i
k
}
e = \left\{ v_{i_{1}}, v_{i_{2}}, \cdots, v_{i_{k}} \right\}
e={vi1,vi2,⋯,vik},就是一个
V
\mathcal{V}
V的子集,即
e
⊆
V
e \subseteq \mathcal{V}
e⊆V。
Methodology

嵌入层 (Intent-Aware Embedding)
引入 Intent 概念,将 embedding 分为
K
K
K 组,每组保持独立。
即,对于任意
v
∈
V
v \in \mathcal{V}
v∈V,其 intent-aware embedding表示为
h
v
i
=
(
h
v
i
1
,
h
v
i
2
,
…
,
h
v
i
K
)
\mathbf{h}_{v_{i}}=\left(\mathbf{h}_{v_{i}}^{1}, \mathbf{h}_{v_{i}}^{2}, \ldots, \mathbf{h}_{v_{i}}^{K}\right)
hvi=(hvi1,hvi2,…,hviK)。每个物品具备
K
K
K 个 intent embedding
h
v
i
k
∈
R
d
K
\mathbf{h}_{v_{i}}^{k} \in \mathbb{R}^{\frac{d}{K}}
hvik∈RKd,用于表示物品不同的 intent。
多个 intent 的中心概念化为 intent prototype, 通过平均池化表示为:
h
p
k
=
Mean
(
h
v
i
k
∣
v
i
∈
V
)
\mathbf{h}_{p}^{k}=\operatorname{Mean}\left(\mathbf{h}_{v_{i}}^{k} \mid v_{i} \in \mathcal{V}\right)
hpk=Mean(hvik∣vi∈V)。
会话超图构建
如图1(a) 所示,通过 3 3 3 种 超边构造超图,分别如下:
- Transition Hyperedges E s t \mathcal{E}_{s}^{t} Est:每个 session 的会话图中所有 指向节点 v v v 的节点 (incoming nodes)构成超边。
- Context Hyperedges E s c \mathcal{E}_{s}^{c} Esc:通过一个窗口大小为 w w w 的滑动窗口,沿着会话序列方向移动,所有窗口内的物品构成超边。最大窗口为 W W W,取所有窗口截取到的超边并集作为上下文超边集合,即 E s c = ∪ w = 1 W E s w c \mathcal{E}_{s}^{c} = \cup_{w=1}^{W}\mathcal{E}_{s_{w}}^{c} Esc=∪w=1WEswc。
- Intent Hyperedges E s i \mathcal{E}_{s}^{i} Esi:对任意意图 k ∈ { 1 , 2 , ⋯ , K } k \in \left\{1, 2, \cdots, K\right\} k∈{1,2,⋯,K},任意物品与intent prototype的相似性表示为 S k i = cos ( h p k , h v i k ) S_{k i}=\cos \left(\mathbf{h}_{p}^{k}, \mathbf{h}_{v_{i}}^{k}\right) Ski=cos(hpk,hvik)。Top- ε ⋅ n \varepsilon \cdot n ε⋅n 相似性分数的物品构成超边。其中, ε \varepsilon ε 为 比例系数, n n n 为 session 长度。
上述所有超边的并集构成超边组合,即 E s = E s t ∪ E s c ∪ E s i \mathcal{E}_{s} = \mathcal{E}_{s}^{t} \cup \mathcal{E}_{s}^{c} \cup \mathcal{E}_{s}^{i} Es=Est∪Esc∪Esi。重合的边进行去除操作。
微观解耦
micro-disentanglement,实际上就是构造超图,完成 node->hyperedge->node 的embedding传播过程。具体而言:
1) Node to hyperedge (n2e) 可以表示为:
f
j
k
=
A
G
G
n
2
e
(
α
j
o
k
h
v
o
k
∣
v
o
∈
e
j
)
(1)
\mathbf{f}_{j}^{k}=\mathbf{AGG}_{n 2 e}\left(\alpha_{j o}^{k} \mathbf{h}_{v_{o}}^{k} \mid v_{o} \in e_{j}\right) \tag{1}
fjk=AGGn2e(αjokhvok∣vo∈ej)(1)
即通过GAT完成,GAT系数计算通过 softmax 进行归一化如下所示:
α j o k = exp ( LeakyReLU ( q 1 k ⊤ ( h c j k ⊙ h v o k ) ) ) ∑ v o ′ ∈ e j exp ( LeakyReLU ( q 1 k ⊤ ( h c j k ⊙ h v o ′ k ) ) ) (2) \alpha_{j o}^{k}=\frac{\exp \left(\operatorname{LeakyReLU}\left(\mathbf{q}_{1}^{k^{\top}}\left(\mathbf{h}_{c_{j}}^{k} \odot \mathbf{h}_{v_{\boldsymbol{o}}}^{k}\right)\right)\right)}{\sum_{v_{o^{\prime}} \in e_{j}} \exp \left(\operatorname{LeakyReLU}\left(\mathbf{q}_{1}^{k^{\top}}\left(\mathbf{h}_{c_{j}}^{k} \odot \mathbf{h}_{v_{o^{\prime}}}^{k}\right)\right)\right)} \tag{2} αjok=∑vo′∈ejexp(LeakyReLU(q1k⊤(hcjk⊙hvo′k)))exp(LeakyReLU(q1k⊤(hcjk⊙hvok)))(2)
2)Hyperedge to node (e2n) 可以表示为:
h
v
i
k
′
=
A
G
G
e
2
n
(
β
i
j
k
f
j
k
∣
e
j
∈
E
s
v
i
)
(3)
{\mathbf{h}_{v_{i}}^{k}}^{\prime} = \mathbf{AGG}_{e 2 n}\left(\beta_{i j}^{k} \mathbf{f}_{j}^{k} \mid e_{j} \in \mathcal{E}_{s_{v_{i}}}\right) \tag{3}
hvik′=AGGe2n(βijkfjk∣ej∈Esvi)(3)
其中,GAT 网络注意力系数计算如下:
β i j k = exp ( LeakyReLU ( q 2 k ⊤ ( h q v i k ⊙ f j k ) ) ) ∑ e j ′ ∈ E s v i exp ( LeakyReLU ( q 2 k ⊤ ( h q v i k ⊙ f j ′ k ) ) ) (4) \beta_{i j}^{k}=\frac{\exp \left(\operatorname{LeakyReLU}\left(\mathbf{q}_{2}^{k^{\top}}\left(\mathbf{h}_{q_{v_{i}}}^{k} \odot \mathbf{f}_{j}^{k}\right)\right)\right)}{\sum_{e_{j^{\prime}} \in \mathcal{E}_{s_{v_{i}}}} \exp \left(\operatorname{LeakyReLU}\left(\mathbf{q}_{2}^{k^{\top}}\left(\mathbf{h}_{q_{v_{i}}}^{k} \odot \mathbf{f}_{j^{\prime}}^{k}\right)\right)\right)} \tag{4} βijk=∑ej′∈Esviexp(LeakyReLU(q2k⊤(hqvik⊙fj′k)))exp(LeakyReLU(q2k⊤(hqvik⊙fjk)))(4)
这里, h q v i k = h v i k + s k \mathbf{h}_{q_{v_{i}}}^{k}=\mathbf{h}_{v_{i}}^{k}+\mathbf{s}^{k} hqvik=hvik+sk, s k \mathbf{s}^{k} sk 表示当前 intent 下 session 中所有物品 embedding 的期望。
通过n2e, e2n,得到 refined embedding h v i k ′ {\mathbf{h}_{v_{i}}^{k}}^{\prime} hvik′。
宏观解耦
Macro-disentanglement,即预测当前 intent 下的 target 目标,并计算损失:
y
^
s
p
=
Softmax
(
MLP
(
{
h
v
i
k
′
∣
v
i
∈
V
s
}
)
)
,
(5)
\hat{\mathbf{y}}_{s}^{p} =\operatorname{Softmax}\left(\operatorname{MLP}\left(\left\{\mathbf{h}_{v_{i}}^{k^{\prime}} \mid v_{i} \in \mathcal{V}_{s}\right\}\right)\right), \tag{5}
y^sp=Softmax(MLP({hvik′∣vi∈Vs})),(5)
这里,
MLP
(
⋅
)
\operatorname{MLP}\left(\cdot\right)
MLP(⋅) 表示单层MLP网络,得到了
y
^
s
p
\hat{\mathbf{y}}_{s}^{p}
y^sp 表示 session
s
s
s 下对所有物品的预测分数,只对当前 intent 进行计算,得到当前 intent 的计算分数如下:
L
d
s
=
−
∑
k
=
1
K
1
p
=
k
log
(
y
^
s
k
p
)
,
(6)
\mathcal{L}_{d}^{s}=-\sum_{k=1}^{K} 1_{p=k} \log \left(\hat{y}_{s k}^{p}\right), \tag{6}
Lds=−k=1∑K1p=klog(y^skp),(6)
这里
1
p
=
k
1_{p=k}
1p=k 表示 指示函数,只有在预测当前 intent 时赋值为
1
1
1。
预测层
如上所示,针对会话 s = [ v s , 1 , v s , 2 , ⋯ , v s , n ] s = \left[ v_{s,1}, v_{s,2}, \cdots, v_{s,n} \right] s=[vs,1,vs,2,⋯,vs,n],任意物品 v s i v_{s_{i}} vsi 具有intent-specific embedding chunks ( h v s i 1 ′ , h v s i 2 ′ , … , h v s i K ′ ) \left(\mathbf{h}_{v_{s_{i}}}^{1}{ }^{\prime}, \mathbf{h}_{v_{s_{i}}}^{2}{ }^{\prime}, \ldots, {{\mathbf{h}_{v_{s_i}}^{K}}^{\prime}}\right) (hvsi1′,hvsi2′,…,hvsiK′)。
Inspired by GCE-GNN,通过将最后一个物品作为锚,计算注意力系数 γ i k \gamma_i^k γik 对物品 embedding 进行整合,具体如下:
z
i
k
=
tanh
(
W
1
k
[
h
v
s
i
k
′
∥
p
n
−
i
+
1
]
)
,
h
s
∗
k
=
W
2
k
[
h
v
s
i
k
′
∥
h
v
s
n
k
′
]
,
γ
i
k
=
q
k
⊤
σ
(
(
W
3
k
[
h
v
s
i
k
′
′
⊙
h
s
∗
k
]
)
∥
(
W
4
k
h
s
∗
k
)
∥
(
W
5
k
z
i
k
)
+
b
k
)
,
(7)
\begin{aligned} & \mathbf{z}_i^k=\tanh \left(\mathbf{W}_1^k\left[\mathbf{h}_{v_{s_i}}^k{ }^{\prime} \| \mathbf{p}_{n-i+1}\right]\right), \quad \mathbf{h}_{s^*}^k=\mathbf{W}_2^k\left[\mathbf{h}_{v_{s_{i}}}^k{ }^{\prime} \| \mathbf{h}_{v_{s_{n}}}^k{ }^{\prime}\right], \\ & \gamma_i^k=\mathrm{q}^{k^{\top}} \sigma\left(\left(\mathbf{W}_3^k\left[\mathbf{h}_{v_{s_i}}^k{ }^{\prime}{ }^{\prime} \odot \mathbf{h}_{s *}^k\right]\right)\left\|\left(\mathbf{W}_4^k \mathbf{h}_{s *}^k\right)\right\|\left(\mathbf{W}_5^k \mathbf{z}_i^k\right)+\mathbf{b}^k\right), \end{aligned} \tag{7}
zik=tanh(W1k[hvsik′∥pn−i+1]),hs∗k=W2k[hvsik′∥hvsnk′],γik=qk⊤σ((W3k[hvsik′′⊙hs∗k])
(W4khs∗k)
(W5kzik)+bk),(7)
其中,
p
n
−
i
+
1
\mathbf{p}_{n-i+1}
pn−i+1 表示位置embedding,具体实现没说,应该是参考 GAT 的做法进行位置编码。
h
v
s
i
′
\mathbf{h}_{v_{s_i}}^{\prime}
hvsi′ 是物品 embedding。
W 1 k , W 2 k ∈ R d K × 2 d K \mathbf{W}_{1}^{k}, \mathbf{W}_{2}^{k} \in \mathbb{R}^{\frac{d}{K} \times \frac{2d}{K}} W1k,W2k∈RKd×K2d, W i k ∣ i = 3 5 ∈ R d K × d K \left.\mathbf{W}_{i}^{k}\right|_{i=3} ^{5} \in \mathbb{R}^{\frac{d}{K} \times \frac{d}{K}} Wik i=35∈RKd×Kd, b k \mathbf{b}^{k} bk,及 q k ∈ R 3 d K \mathbf{q}^{k} \in \mathbb{R}^{\frac{3 d}{K}} qk∈RK3d 都是 可训练权重参数。
从而得到 session 表示:
h
s
k
=
∑
i
=
1
n
γ
i
k
⋅
h
v
s
i
k
′
,
(8)
\mathbf{h}_{s}^{k}=\sum_{i=1}^{n} \gamma_{i}^{k} \cdot \mathbf{h}_{v_{s i}}^{k}{ }^{\prime}, \tag{8}
hsk=i=1∑nγik⋅hvsik′,(8)
对
K
K
K 个 intent 进行加和,得到预测分数:
p
s
i
=
∑
k
=
1
K
h
s
k
⊤
h
v
i
k
.
(9)
p_{s i}=\sum_{k=1}^{K} \mathbf{h}_{s}^{k^{\top}} \mathbf{h}_{v_{i}}^{k} . \tag{9}
psi=k=1∑Khsk⊤hvik.(9)
模型训练
损失项通过 primary & auxiliary 方式进行,如下所示:
L
r
s
=
−
∑
i
=
1
m
y
s
i
log
(
y
^
s
i
)
+
(
1
−
y
s
i
)
log
(
1
−
y
^
s
i
)
,
(10)
\mathcal{L}_{r}^{s}=-\sum_{i=1}^{m} y_{s i} \log \left(\hat{y}_{s i}\right)+\left(1-y_{s i}\right) \log \left(1-\hat{y}_{s i}\right), \tag{10}
Lrs=−i=1∑mysilog(y^si)+(1−ysi)log(1−y^si),(10)
L s = L r s + λ L d s (11) \mathcal{L}^{s} = \mathcal{L}_{r}^{s} + \lambda \mathcal{L}_{d}^{s} \tag{11} Ls=Lrs+λLds(11)
Experiments
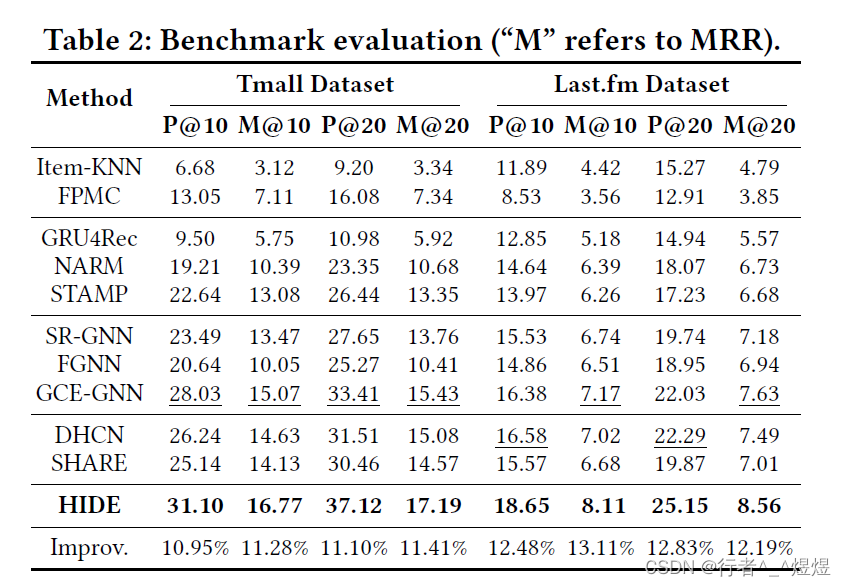
- 数据集:TMall 和 LastFM
- Metric:Precision@K、MRR@K
- 实验结果如下:
论文总结
文章整体较为完整,由于短文篇幅限制,一些内容语焉不详,例如超图在 K K K 个意图下的划分,除此以外比较突出。



![[python 刷题] 739 Daily Temperatures](https://img-blog.csdnimg.cn/c8fcb37733b04158bcebc74b3fe88319.jpeg#pic_center)