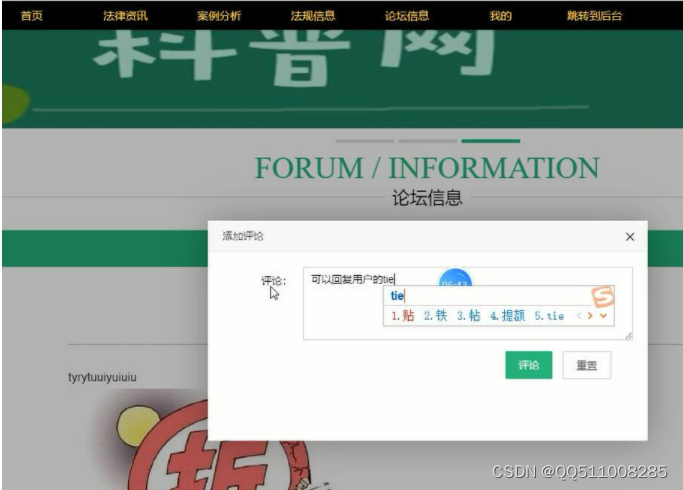
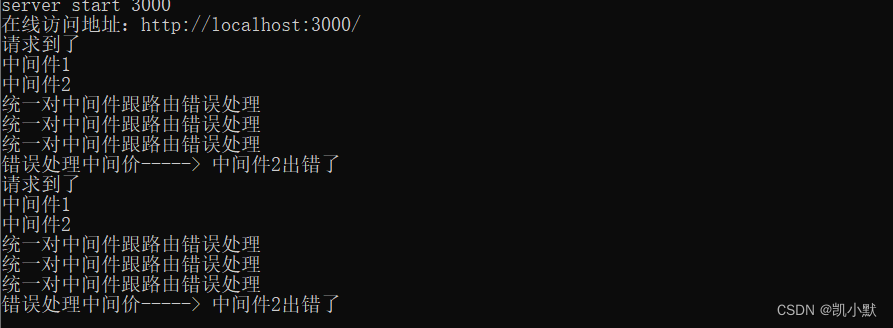
问题一:区域碳排放量以及经济、人口、能源消费量的现状分析
思路:
定义碳排放量 Prediction 模型:
CO2 = P * (GDP/P) * (E/GDP) * (CO2/E)
其中: CO2:碳排放量 P:人口数量 GDP/P:人均GDP E/GDP:单位GDP能耗 CO2/E:单位能耗碳排放量
2.收集并统计相关历史数据:
人口数量P
GDP总量与人均GDP
各产业部门能耗E
各产业部门碳排放量CO2
3.分析历史数据变化趋势:
GDP增长率、人均GDP增长率
部门能耗强度降低率
部门碳排放强度降低率
4.预测未来发展态势:
人口预测
GDP增长目标
部门能效提升目标
非化石能源替代目标
5.将预测数据代入碳排放预测模型,计算各年碳排放量。
6.比较碳排放量预测结果与碳中和目标差距,分析碳中和的难点。
代码:
# 导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取历史数据
df = pd.read_excel('history_data.xlsx')
# 数据预处理
df = df[['年份','人口','GDP','第一产业能耗','第二产业能耗','第三产业能耗','生活能耗','碳排放量']]
df['能耗总量'] = df[['第一产业能耗','第二产业能耗','第三产业能耗','生活能耗']].sum(axis=1)
df['人均GDP'] = df['GDP'] / df['人口']
df['能耗强度'] = df['能耗总量'] / df['GDP']
df['碳排放强度'] = df['碳排放量'] / df['能耗总量']
# 分析历史趋势
df['GDP增长率'] = df['GDP'].pct_change()
df['人均GDP增长率'] = df['人均GDP'].pct_change() #见完整版问题二
区域碳排放量以及经济、人口、能源消费量的预测模型
人口预测模型
根据历史人口数据,可以建立简单的线性回归模型来预测未来人口数量。也可以研究人口增长的S形曲线规律,建立logistic回归模型。需要收集人口出生率、死亡率等数据,来综合判断未来人口变化趋势。
2.人均能耗模型
可以基于每个时期人均GDP水平,结合Engel系数法则等分析人均能耗需求变化规律。随着生活水平提高,人均能耗呈现先增加后下降的趋势。建立人均能耗预测模型时,需要考虑收入弹性、技术进步抑耗作用等因素。
3.能耗强度模型
这反映了经济活动的能效提升程度。可以收集国内外同类产业的能耗强度基准,判断本区域的节能潜力空间。还需要考虑电气化、新材料应用等因素对能耗强度的影响。不同产业需要建立独立的强度预测模型。
4.部门能耗预测
基于能耗总量预测,结合产业发展规划、产业结构优化目标,合理预测各部门的能源需求。重点对能源密集型产业的清洁生产提出指导意见。
5.情景比较
建议设计高能效提升情景、低能效提升情景,以及高非化石能源替代情景、低替代情景。比较各情景下的碳排放量、能耗指标,分析实现碳中和的关键措施。
结合公式:
人口预测模型
线性回归模型:
人口数P = a + b*年份
logistic模型:
P = P_m / [1 + exp(-k(年份-t))]
2.人均能耗模型
人均能耗E_p = c * GDP_p^d
3.能耗强度模型
能耗强度I = a * exp(-b*年份)
4.部门能耗预测模型
第i部门能耗E_i = E_total * r_i
5.碳排放量预测
CO2 = ∑(E_i * f_i)
其中: P_m:人口饱和值上限 k,t:logistic模型参数 E_p:人均能耗 GDP_p:人均GDP I:能耗强度 E_i:第i部门能耗 E_total:总能耗 r_i:第i部门耗能占比 f_i:第i部门碳排放因子
代码:
# 导入库
import pandas as pd
from scipy.optimize import curve_fit
# 人口预测
p_data = df[['年份','人口']]
# 线性回归
def linear(x, a, b):
return a + b*x
pars, cov = curve_fit(linear, p_data['年份'], p_data['人口'])
a, b = pars
predict_p = [linear(x, a, b) for x in range(2025,2061)]
# Logistic回归
def logistic(x, p_m, k, t):#见完整版问题三
区域双碳(碳达峰与碳中和)目标与路径规划方法
构建多情景框架
设置无干预情景、碳中和情景等多种发展情景。确定各情景的经济增长、能效提升、非化石能源比例等参数。
2.碳排放预测模型
CO2 = Σ(Ei * fi)
Ei = Etotal * ri
其中Ei表示部门i能耗,fi表示对应碳排放因子,ri表示耗能占比。
3.部门能耗确定
工业:Ei = VAi * (1-η1) * η2
建筑:Ei = VAi * (1-η1) * η2
VAi表示部门增加值,η1表示管理节能率,η2表示技术节能率。
4.非化石能源置换
调整碳排放因子fi,设置不同替代情景。
5.GDP约束
∑VAi = GDP
增加值之和约束为GDP总量。
6.情景对比
比较不同情景下的碳排放量、非化石能源比例等结果
详细来说,
构建多情景框架
可以设置3-5种情景,如基准情景、进取情景、保守情景等
确定每个情景的核心参数:经济增速、能效提升目标、非化石能源替代目标
收集相关国内外研究报告,综合判断参数的合理取值范围
2.碳排放预测模型
排放量由各部门的能耗及排放因子决定
部门能耗取决于总量分配和结构优化
排放因子通过提升非化石替代来降低
3.部门能耗确定
考虑管理节能、技术进步来推动能效提升
收集行业案例研究,判断节能潜力空间
4.非化石能源置换
不同情景可以设置不同的替代目标
替代路径可以通过电力置换、氢能应用、生物质利用等途径实现
5.GDP约束
部门增加值之和等于GDP总量
需要平衡部门发展速度,实现经济平稳增长
6.情景对比
比较碳排放量、非化石能源比例差异
分析不同情景的可行性和政策含义
提出相关决策建议
# 导入库
import pandas as pd
from scipy.optimize import curve_fit
# 人口预测
p_data = df[['年份','人口']]
# 线性回归
def linear(x, a, b):
return a + b*x
pars, cov = curve_fit(linear, p_data['年份'], p_data['人口'])
a, b = pars
predict_p = [linear(x, a, b) for x in range(2025,2061)]
# Logistic回归
def logistic(x, p_m, k, t):#见完整版更多完整版见我的回答~
(5 封私信 / 2 条消息) 如何评价2023数学建模研赛? - 知乎 (zhihu.com)

![[python 刷题] 739 Daily Temperatures](https://img-blog.csdnimg.cn/c8fcb37733b04158bcebc74b3fe88319.jpeg#pic_center)