文章目录
- 1. 克隆表 ---- 将数据表的数据记录生成到新的表中
- 1.1 方式一:先创建新表,再导入数据
- 1.2 方式二:创建的时候同时导入
- 2. 清空表 ---- 删除表内的所有数据
- 2.1 delete删除
- 2.2 truncate删除(重新记录)
- 2.3 创建临时表(退出数据库自动删除)
- 3. 创建外键约束 ---- 保证数据的完整性和一致性
- 3.1 MySQL约束特性
- 4. SQL进阶查询语句
- 4.1 添加示例表格
- 4.2 selecte ----- 显示表格中一个或数个字段的所有数据记录
- 4.3 distinct ---- 不显示重复的数据记录
- 4.4 where ---- 对源语句进行条件查询
- 4.5 and | or ---- 且 | 或
- 4.6 in ---- 显示已知的值的数据记录
- 4.7 between ---- 显示两个值范围内的数据记录
- 4.8 通配符
- 4.9 like ---- 模糊匹配
- 4.10 order by ---- 按关键字排序
- 4.11 group by ---- 汇总分组
- 4.12 having ---- 进行条件筛选
- 4.13 别名 ---- 字段別名 表格別名
- 4.14 子查询语句 ---- 连接表格
- 4.15 exists
- 5. MySQL数据库函数
- 5.1 数学函数
- 5.1.1 示例
- 5.2 聚合函数
- 5.2.1 示例
- 5.3 字符串函数
- 5.3.1 示例
- 6. 连接查询
- 6.1 表连接
- 6.2 union语句 ---- 联集
- 6.3 多表查询 --- 求交集值
- 6.3.1 示例
- 6.4 多表查询 ---- 求无交集值
- 6.4.1 示例
- 7. SQL语句的执行先后
1. 克隆表 ---- 将数据表的数据记录生成到新的表中
1.1 方式一:先创建新表,再导入数据
create table 新表 like 旧表;
insert into 新表 select * from 旧表;
#这种方式可以完全复制表内容和表结构
#示例
create table test1 like st; #通过 LIKE 方法,复制 info 表结构生成 test01 表
insert into test1 select * from st; #导入数据
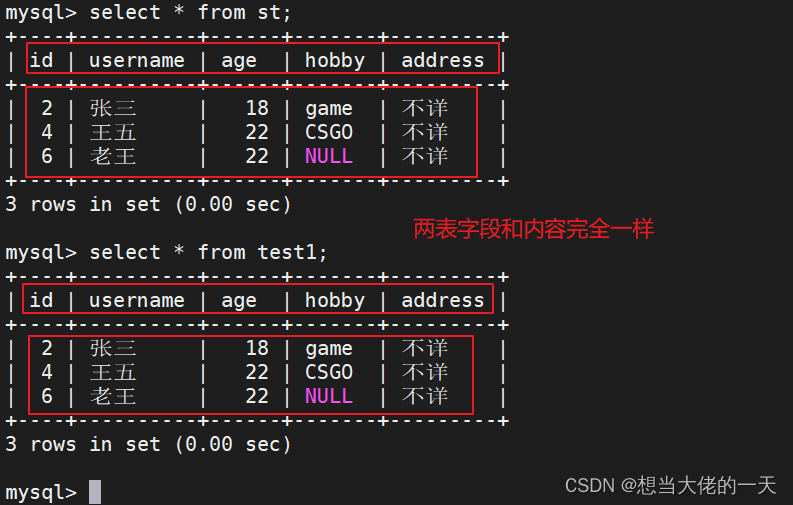
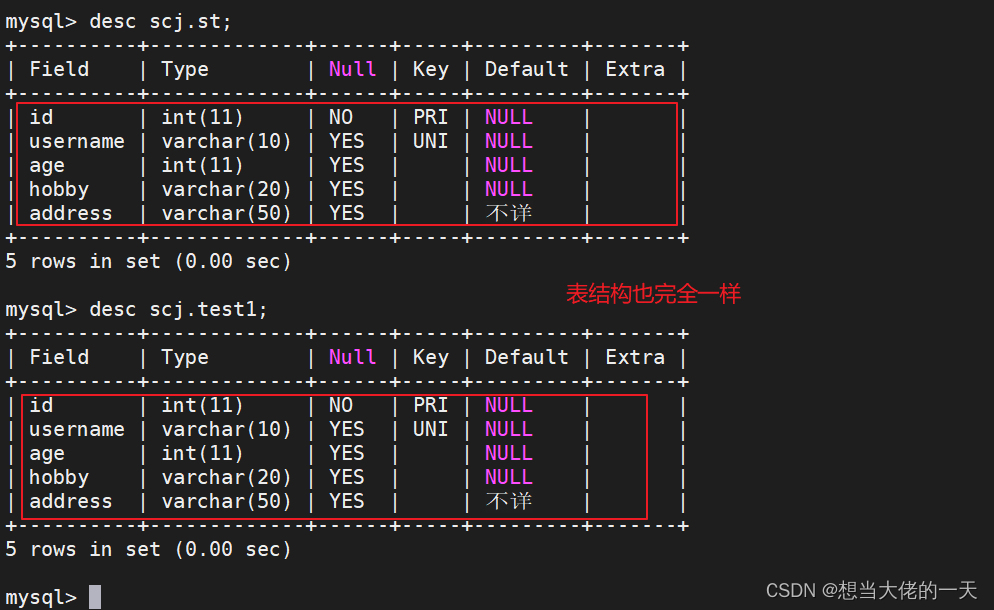
1.2 方式二:创建的时候同时导入
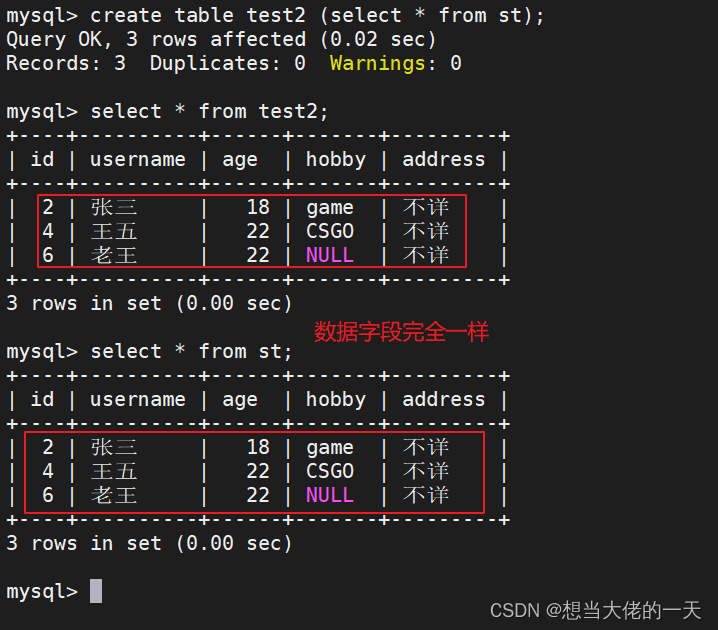
create table test2 (select * from st);
#创建内容来自st表的test2表
#这种方式不能克隆表结构,只能克隆表内容
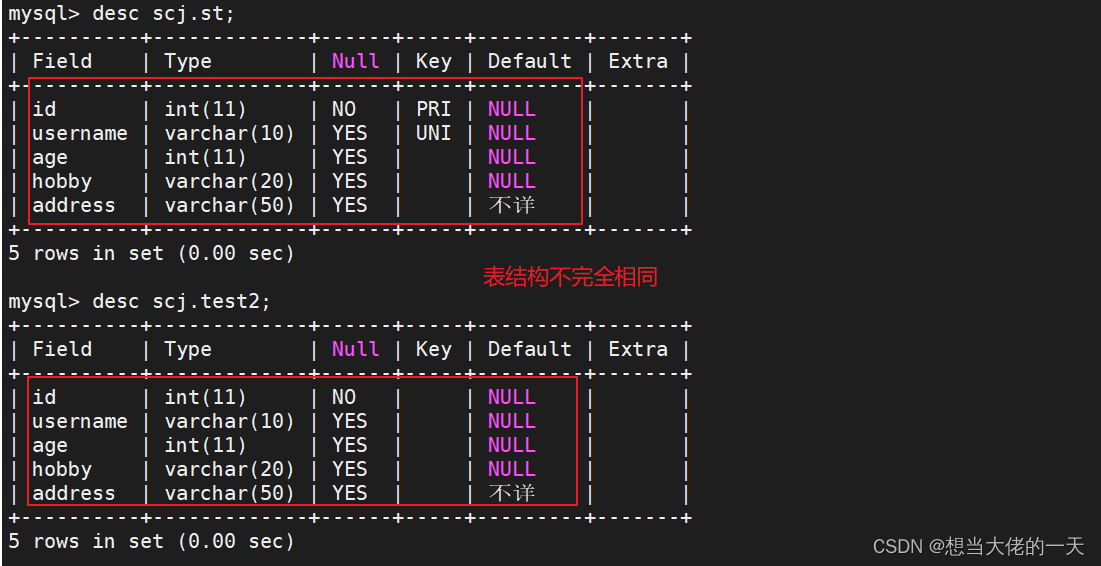
2. 清空表 ---- 删除表内的所有数据
2.1 delete删除
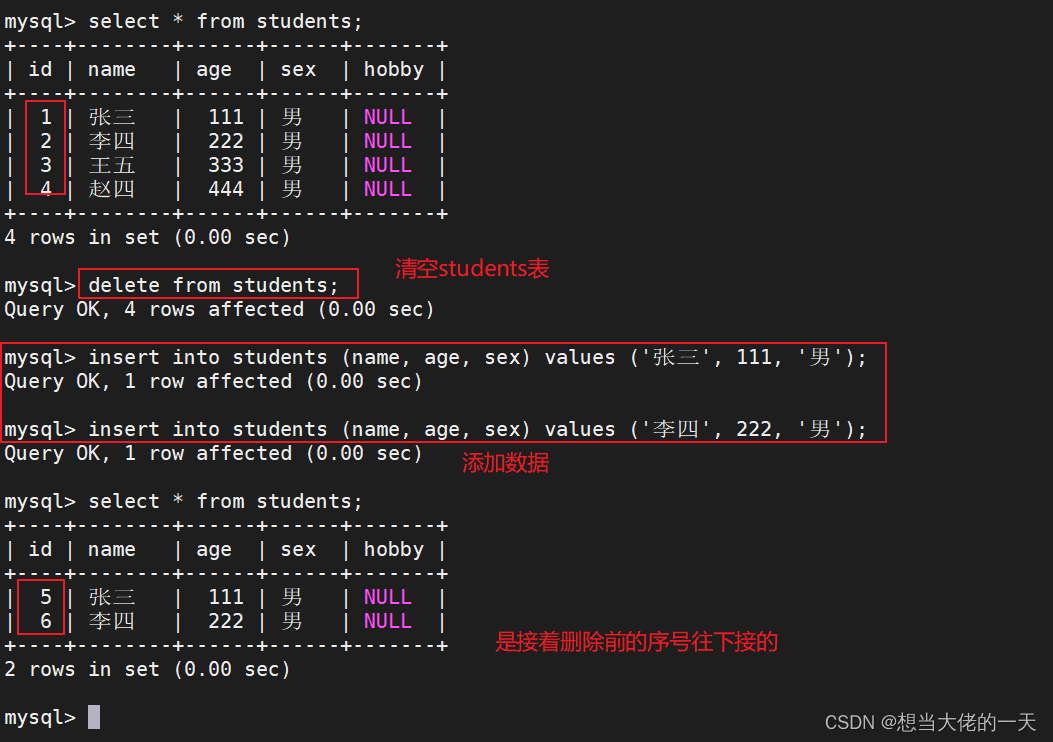
DELETE清空表后,返回的结果内有删除的记录条目;DELETE工作时是一行一行的删除记录数据的;如果表中有自增长字段,使用DELETE FROM 删除所有记录后,再次新添加的记录会从原来最大的记录 ID 后面继续自增写入记录。
delete from 表名;
delete from students;
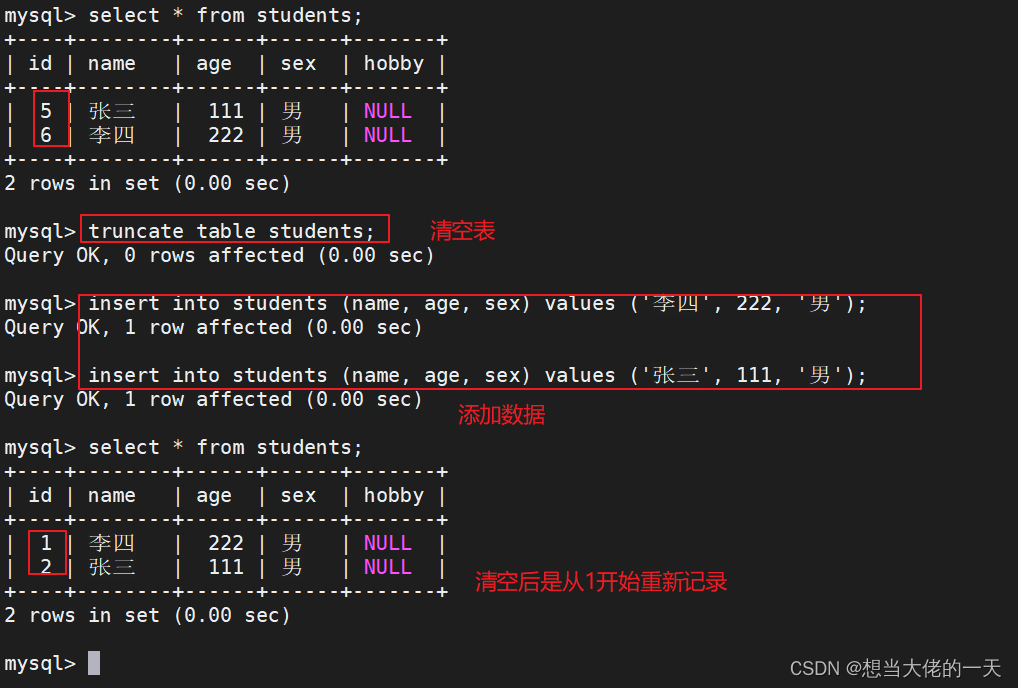
2.2 truncate删除(重新记录)
TRUNCATE 清空表后,没有返回被删除的条目;TRUNCATE 工作时是将表结构按原样重新建立,因此在速度上 TRUNCATE 会比 DELETE 清空表快;使用 TRUNCATE TABLE 清空表内数据后,ID 会从 1 开始重新记录。
truncate table 表名;
#示例
truncate table students;
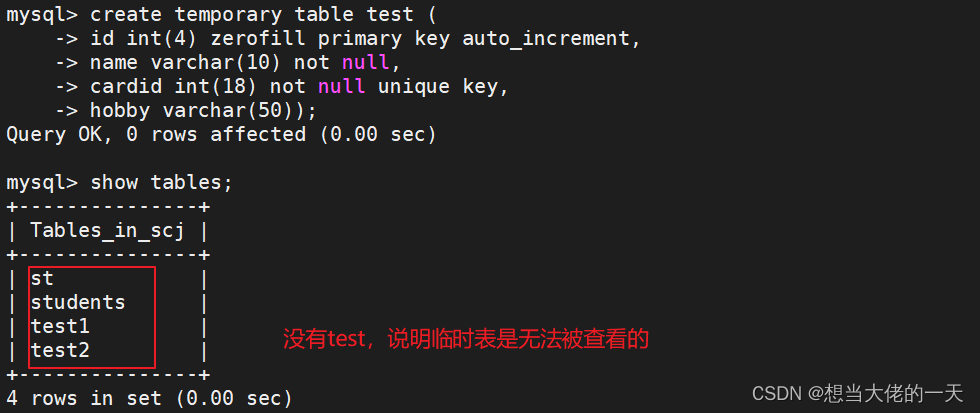
2.3 创建临时表(退出数据库自动删除)
临时表创建成功之后,使用SHOW TABLES命令是看不到创建的临时表的,临时表会在连接退出后被销毁。 如果在退出连接之前,也可以可执行增删改查等操作,比如使用 DROP TABLE 语句手动直接删除临时表。
create temporary table 表名 (字段1 数据类型,字段2 数据类型[,...][,primary key (主键名)]);
##添加临时表test
create temporary table test (
id int(4) zerofill primary key auto_increment,
name varchar(10) not null,
cardid int(18) not null unique key,
hobby varchar(50));
show tables; ## 查看当前库中所有表
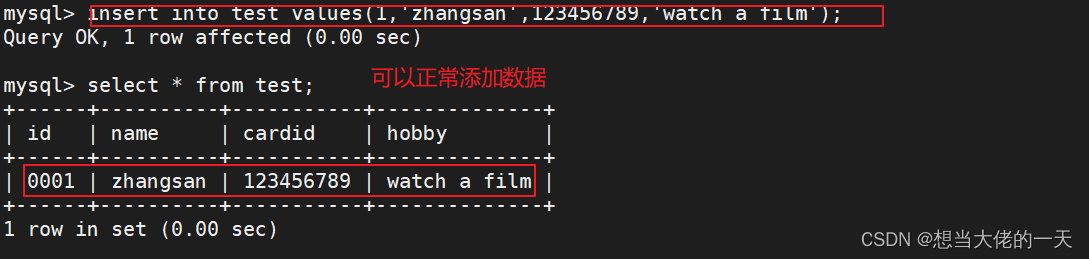
insert into test values(1,'张三',123456789); ##在临时表中添加数据
select * from test; ##查看当前表中所有数据
quit ##退出数据库
mysql -u root -p ##重新登录后进行查看
select * from test; ##查看之前创建的临时表中所有数据,发现已经被自动销毁

3. 创建外键约束 ---- 保证数据的完整性和一致性
如果同一个属性字段X在表一中是主键,而在表二中不是主键,则字段X称为表二的外键
主键表和外键表的区别
(1)以公共关键字作主键的表为主键表(父表、主表)
(2)以公共关键字作外键的表为外键表(从表、外表)
注:与外键关联的主表的字段必须设置为主键。要求从表不能是临时表,主从表的字段具备相同的数据类型、字符长度和约束。
#基本格式
外键约束
主键表: alter table 表名 add primary key (主键字段);
外键表: alter table 表名 add foreign key (外键字段) references 主键表名 (主键字段);
插入新数据时,需要先在主键表插入数据再在外键表插入对应数据;删除数据时,需要先在外键表删除数据再在主键表删除对应数据
#示例
#创建主表 profession
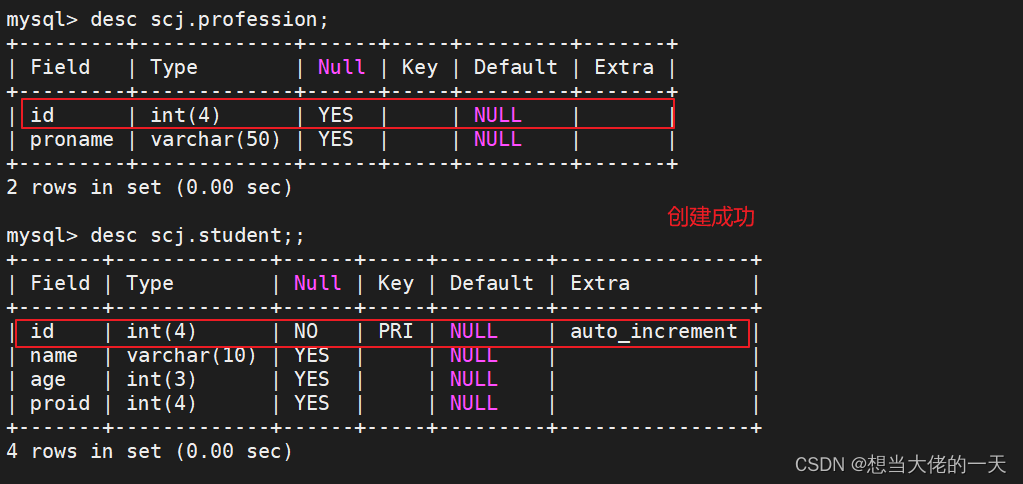
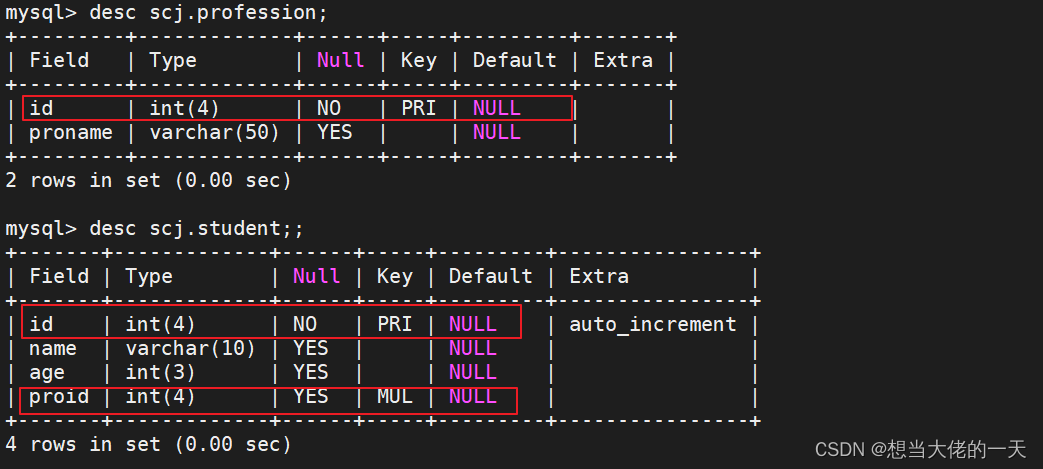
create table profession (id int(4),proname varchar(50));
#创建从表 student
create table student (id int(4) primary key auto_increment,name varchar(10),age int(3),proid int(4));
#创建一个以id为外键并自增长的表student
#为主表 profession 添加一个主键约束。主键名以“PK_”开头。
alter table profession add constraint PK_id primary key (id);
#为从表 student 表添加外键,并将 student 表的 proid 字段和 profession 表的 pid 字段建立外键关联。外键名以“FK_”开头。
alter table student add constraint FK_pro foreign key (proid) references profession (id);
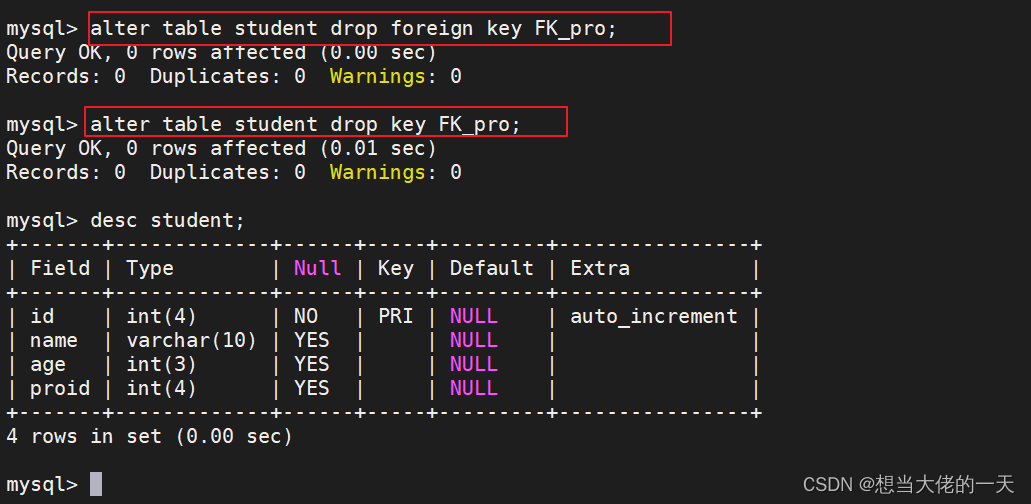
desc student;
**#插入新的数据记录时,要先主表再从表
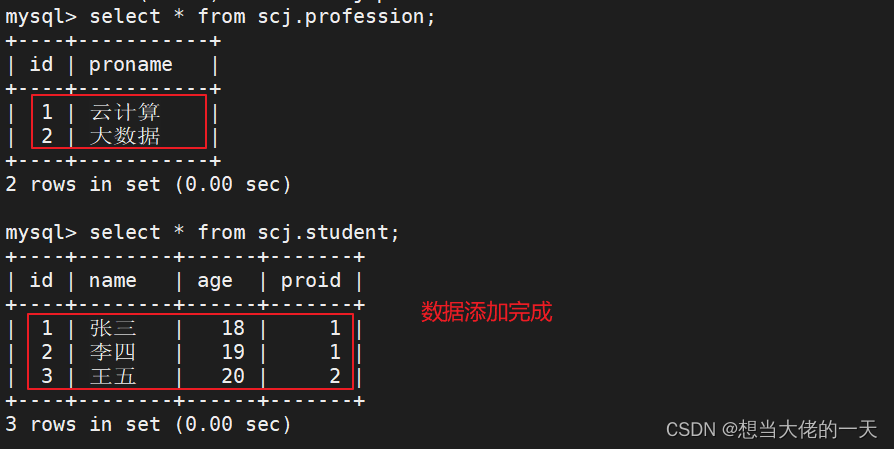
insert into profession values(1,'云计算');
insert into profession values(2,'大数据');
insert into student values(1,'张三',18,1);
insert into student values(2,'李四',19,1);
insert into student values(3,'王五',20,2);
#删数据记录时,要先从表再主表,也就是说删除主键表的记录时必须先删除其他与之关联的表中的记录。
delete from student where proid=1;
delete from profession where id=1;
#查看和删除外键约束
show create table student; #以sql语句方式显示表结构
desc student;
alter table student drop foreign key FK_pro;
alter table student drop key FK_pro;
3.1 MySQL约束特性
| 约束名 | 功能 |
|---|---|
| primary key | 主键约束 字段的值不能重复,且不能为null,一个自建的表只能有一个主键 |
| unique key | 唯一性约束 字段的值不能重复,能为null,一个表可以有多个唯一键 |
| not null | 非空约束 字段的值不能为null |
| default | 默认值约束 字段的值如果没有设置则使用默认值自动填充 |
| auto_increment | 自增约束 字段的值如果没有设置默认会从1开始每次自动递增1,要求自增字段必须设置主键 |
| foreign key | 外键约束 保证相关联的表数据的完整性和一致性 |
| int(N) zerofill | 零填充 表示若数值不满4位数,则前面用“0”填充,例0001 |
4. SQL进阶查询语句
4.1 添加示例表格
create database scj;
use scj;
create table location (Region char(20),Store_Name char(20));
#创建地域表
insert into location values('East','Boston');
insert into location values('East','New York');
insert into location values('West','Los Angeles');
insert into location values('West','Houston');

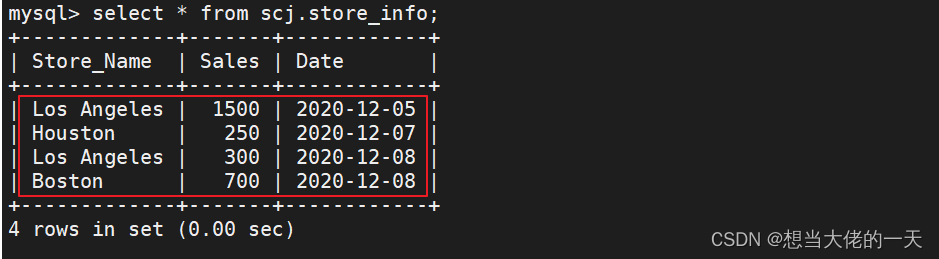
create table store_info (Store_Name char(20),Sales int(10),Date char(10));
insert into store_info values('Los Angeles','1500','2020-12-05');
insert into store_info values('Houston','250','2020-12-07');
insert into store_info values('Los Angeles','300','2020-12-08');
insert into store_info values('Boston','700','2020-12-08');
4.2 selecte ----- 显示表格中一个或数个字段的所有数据记录
显示表格中一个或数个字段的所有数据记录
#基本语法
select "字段" from "表名";
#示例
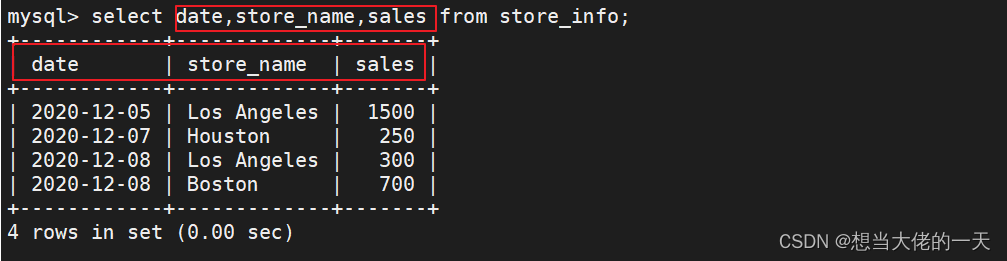
select date,store_name,sales from store_info;
#按照date,store_name,sales的顺序显示store_info表内容
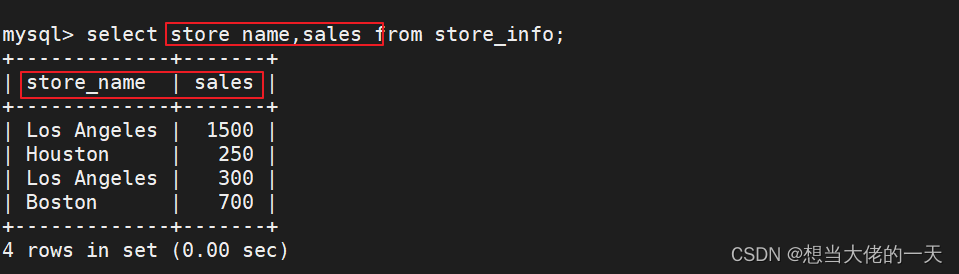
select store_name,sales from store_info;
#也可以只显示特定字段
4.3 distinct ---- 不显示重复的数据记录
#基本语法
select distinct "字段" from "表名";
#示例
select distinct store_name from store_info;
#显示store_info表并去重
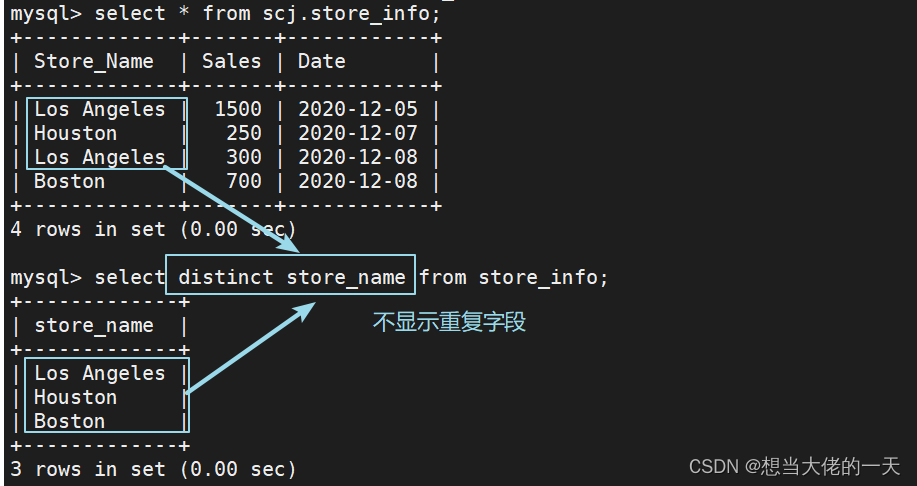
4.4 where ---- 对源语句进行条件查询
#基本格式
select "字段" from "表名" where "条件";
#示例
select store_name date from store_info where sales > 1000;
4.5 and | or ---- 且 | 或
#基本语法
select "字段" from "表名" where "条件1" {[and|or] "条件2"}+ ;
#示例
select store_name from store_info where salves >=1000 or (slave < 300 and salve >200 );

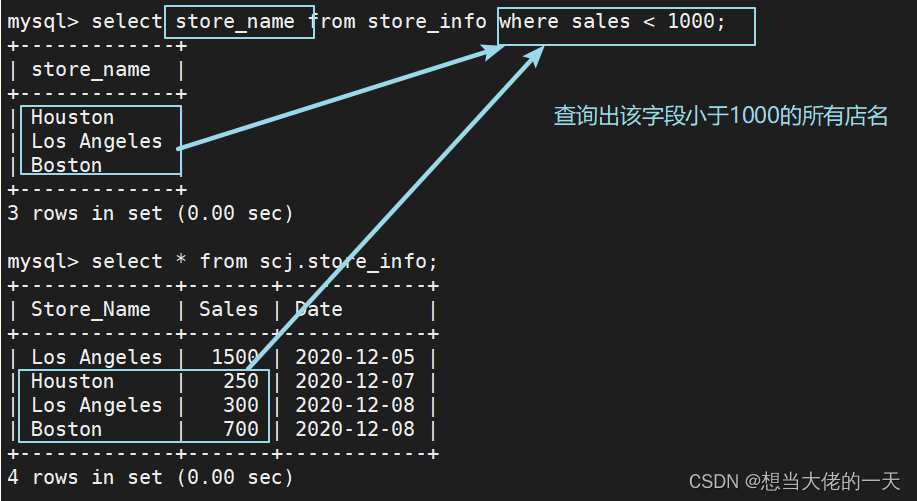
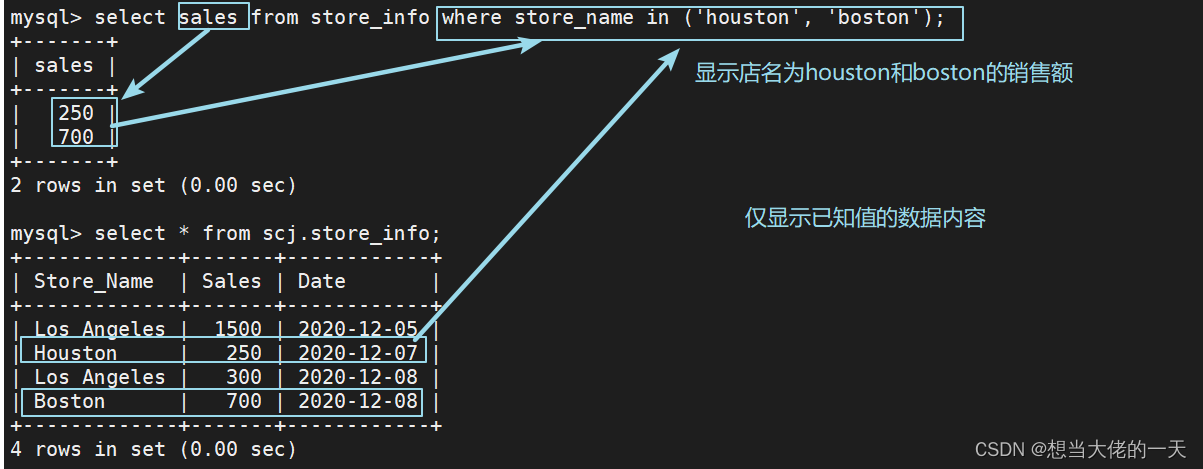
4.6 in ---- 显示已知的值的数据记录
#基本语法
select "字段" from "表名" where "字段" in ('值1', '值2', ...);
#示例
select sales from store_info where store_name in ('houston', 'boston');
4.7 between ---- 显示两个值范围内的数据记录
#基本语法
select "字段" from "表名" where "字段" between '值1' and '值2';
select * from store_info where date between '2020-12-06' and '2020-12-10';

4.8 通配符
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符
'A_Z':所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串。例如,'ABZ' 和 'A2Z' 都符合这一个模式,而 'AKKZ' 并不符合 (因为在 A 和 Z 之间有两个字符,而不是一个字符)。
'ABC%': 所有以 'ABC' 起头的字符串。例如,'ABCD' 和 'ABCABC' 都符合这个模式。
'%XYZ': 所有以 'XYZ' 结尾的字符串。例如,'WXYZ' 和 'ZZXYZ' 都符合这个模式。
'%AN%': 所有含有 'AN'这个模式的字符串。例如,'LOS ANGELES' 和 'SAN FRANCISCO' 都符合这个模式。
'_AN%':所有第二个字母为 'A' 和第三个字母为 'N' 的字符串。例如,'SAN FRANCISCO' 符合这个模式,而 'LOS ANGELES' 则不符合这个模式。
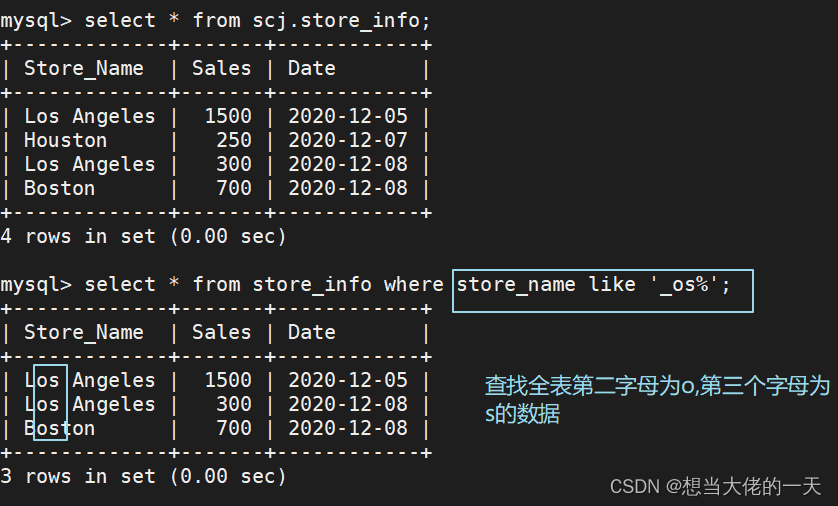
4.9 like ---- 模糊匹配
一般和通配符配合使用。
模糊匹配默认扫描全表,索引不生效
#基本语法
select "字段" from "表名" where "字段" like {模式};
#示例
select * from store_info where store_name like '_os%';
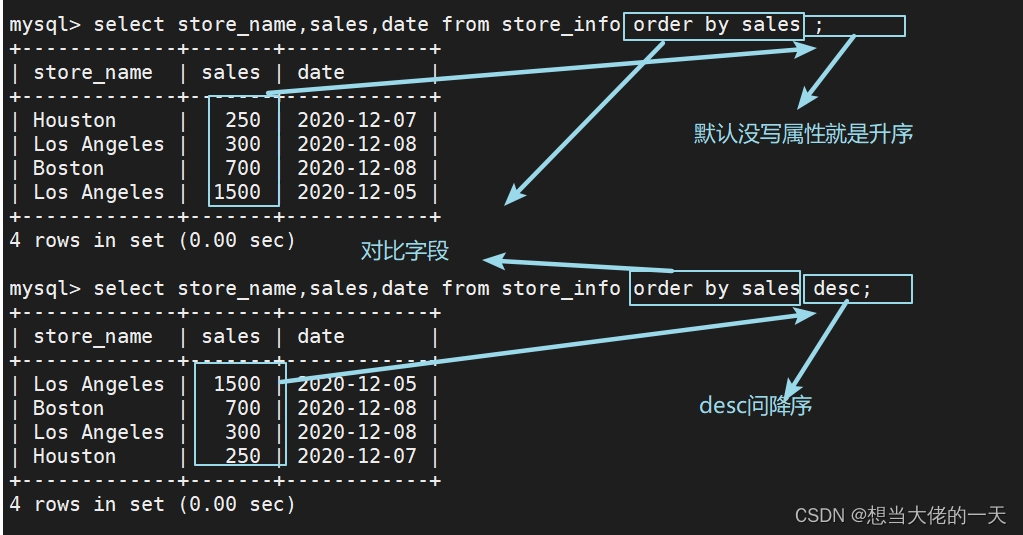
4.10 order by ---- 按关键字排序
#基本语法
select "字段" from "表名" [where "条件"] order by "字段" [asc, desc];
#asc 是按照升序进行排序的,是默认的排序方式。
#desc 是按降序方式进行排序。
select store_name,sales,date from store_info order by sales;
select store_name,sales,date from store_info order by sales desc;
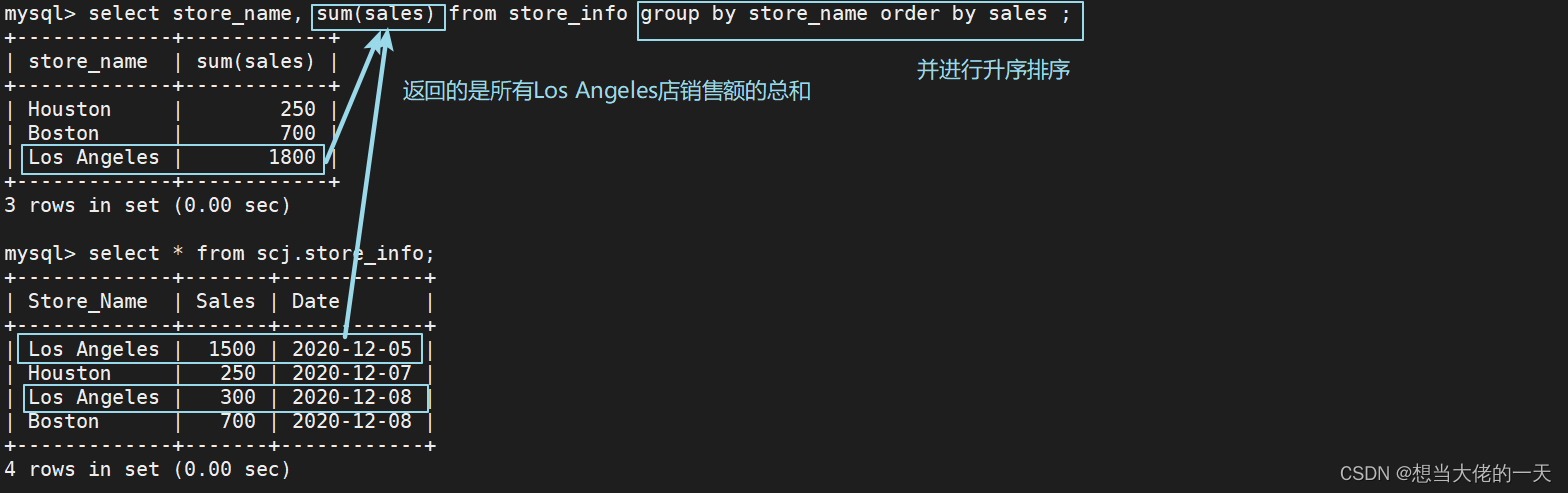
4.11 group by ---- 汇总分组
对 group by 后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
group by 有一个原则,凡是在 group by 后面出现的字段,必须在 select 后面出现;
凡是在 select 后面出现的、且未在聚合函数中出现的字段,必须出现在 group by 后面
#基本语法
select "字段1", sum("字段2") from "表名" group by "字段1";
#sum(x) 返回指定列的所有值之和
#示例
select store_name, sum(sales) from store_info group by store_name order by sales ;
select store_name,count(store_name) from store_info group by store_name desc;
#count() 返回指定列中非 NULL 值的个数

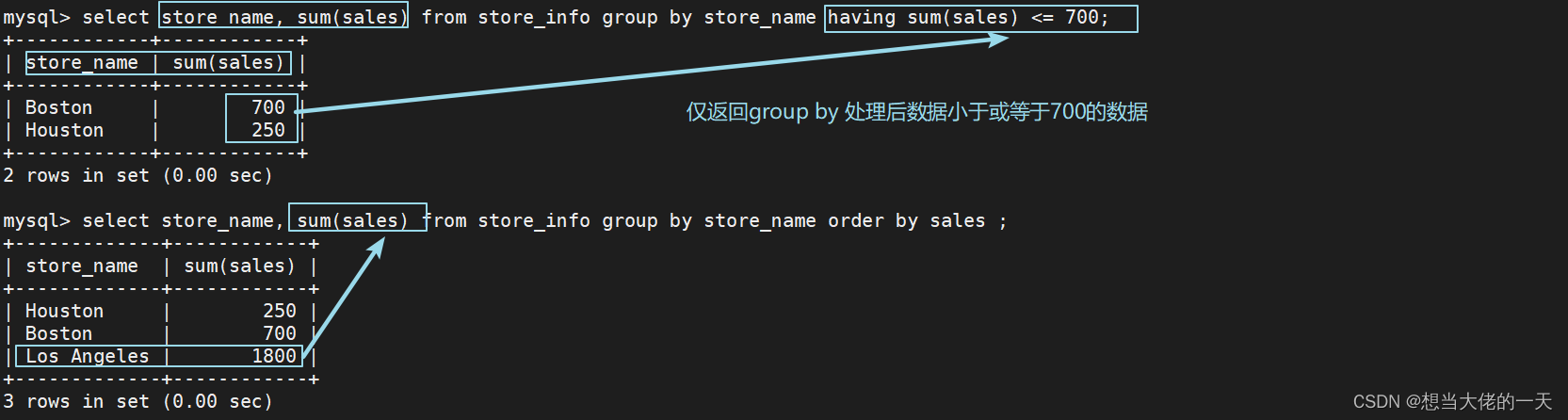
4.12 having ---- 进行条件筛选
用来过滤由 group by 语句返回的记录集,通常与 group by 语句联合使用.
having 语句的存在弥补了 where 关键字不能与聚合函数联合使用的不足。
#基本语法
select "字段1", sum("字段2") from "表格名" group by "字段1" having (函数条件);
select store_name, sum(sales) from store_info group by store_name having sum(sales) <= 700;
4.13 别名 ---- 字段別名 表格別名
as可省略,仅在当前SQL语句生效。
#基本语法
select "表格別名"."字段1" [as] "字段別名" from "表格名" [as] "表格別名";
#示例
select a.store_name store, sum(a.sales) as "total sales" from store_info as a group by a.store_name;

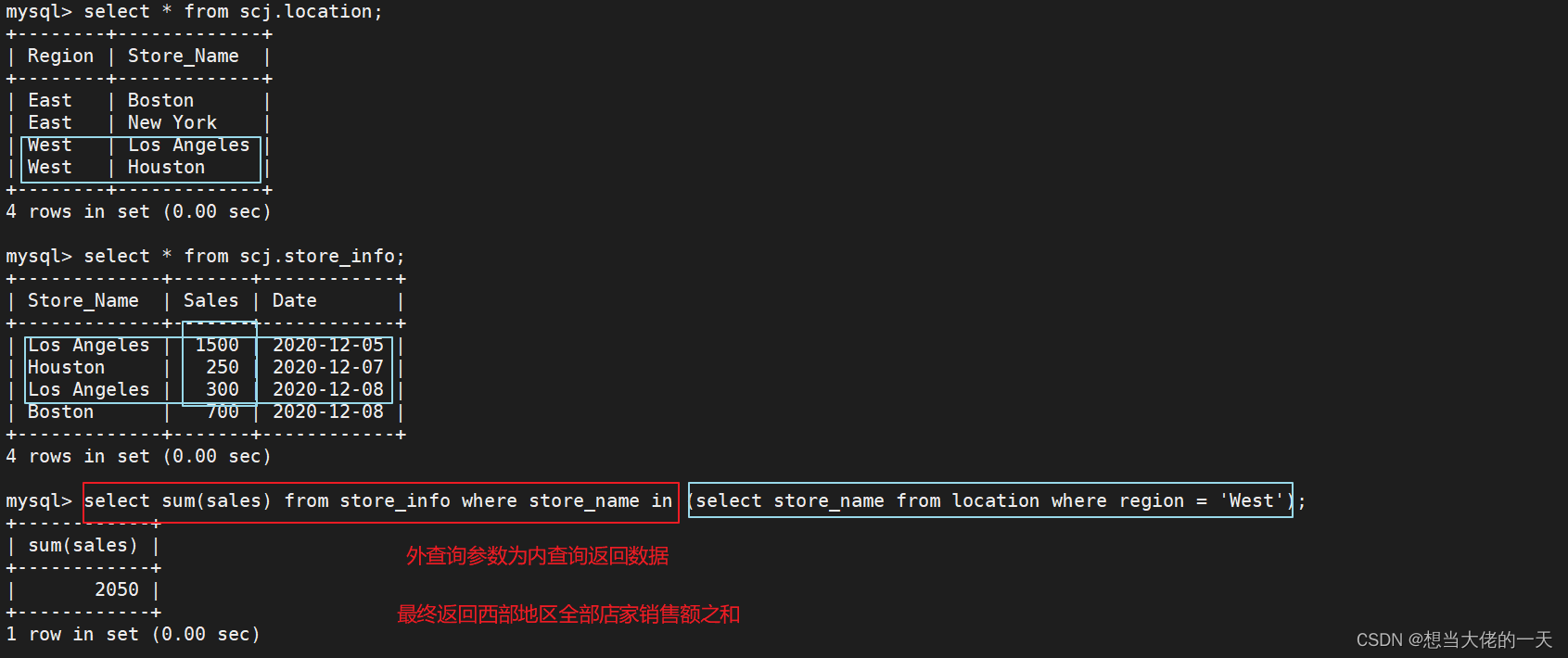
4.14 子查询语句 ---- 连接表格
在 where 子句或 having 子句中插入另一个 SQL 语句
#基本语法
select "字段1" from "表格1" where "字段2" [比较运算符] (select "字段1" from "表格2" where "条件");
#外查询 (#内查询)
#内查询的结果,作为外查询的参数
[比较运算符]
#可以是符号的运算符,例如 =、>、<、>=、<=
#也可以是文字的运算符,例如 like、in、between
select sum(sales) from store_info where store_name in (select store_name from location where region = 'West');
4.15 exists
用来测试内查询有没有产生任何结果。
如果有,系统就会执行外查询中的sql语句;
如果没有,那整个 SQL语句就不会产生任何结果。
#基本语法
select "字段1" from "表格1" where exists (select * from "表格2" where "条件";
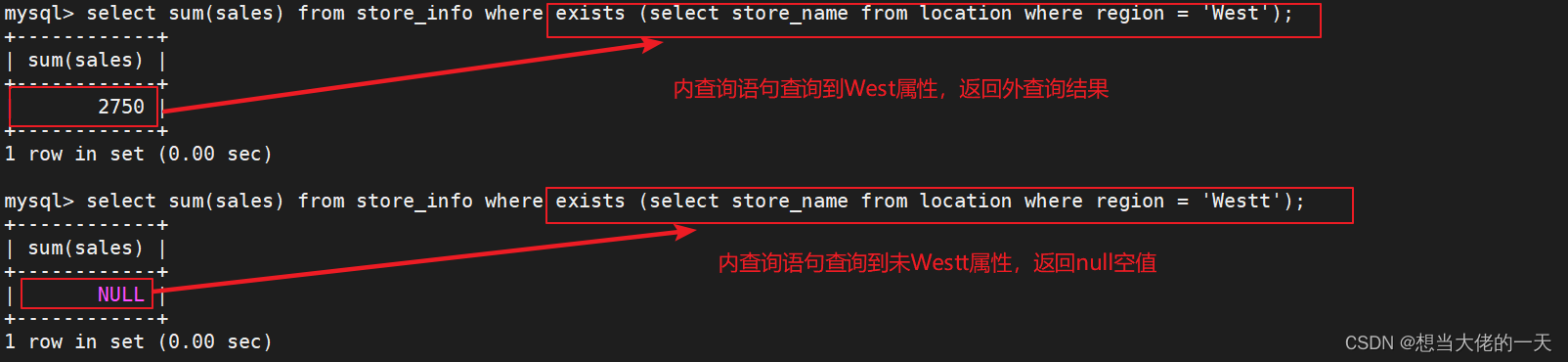
select sum(sales) from store_info where exists (select store_name from location where region = 'West');
select sum(sales) from store_info where exists (select store_name from location where region = 'Westt');
5. MySQL数据库函数
5.1 数学函数
| 函数名 | 功能 |
|---|---|
| abs(x) | 返回 x 的绝对值 |
| rand() | 返回 0 到 1 的随机数 |
| mod(x,y) | 返回 x 除以 y 以后的余数 |
| power(x,y) | 返回 x 的 y 次方 |
| round(x) | 返回离 x 最近的整数 |
| round(x,y) | 保留 x 的 y 位小数四舍五入后的值 |
| sqrt(x) | 返回 x 的平方根 |
| truncate(x,y) | 返回数字 x 截断为 y 位小数的值 |
| ceil(x) | 返回大于或等于 x 的最小整数 |
| floor(x) | 返回小于或等于 x 的最大整数 |
| greatest(x1,x2…) | 返回集合中最大的值,也可以返回多个字段的最大的值 |
| least(x1,x2…) | 返回集合中最小的值,也可以返回多个字段的最小的值 |
5.1.1 示例
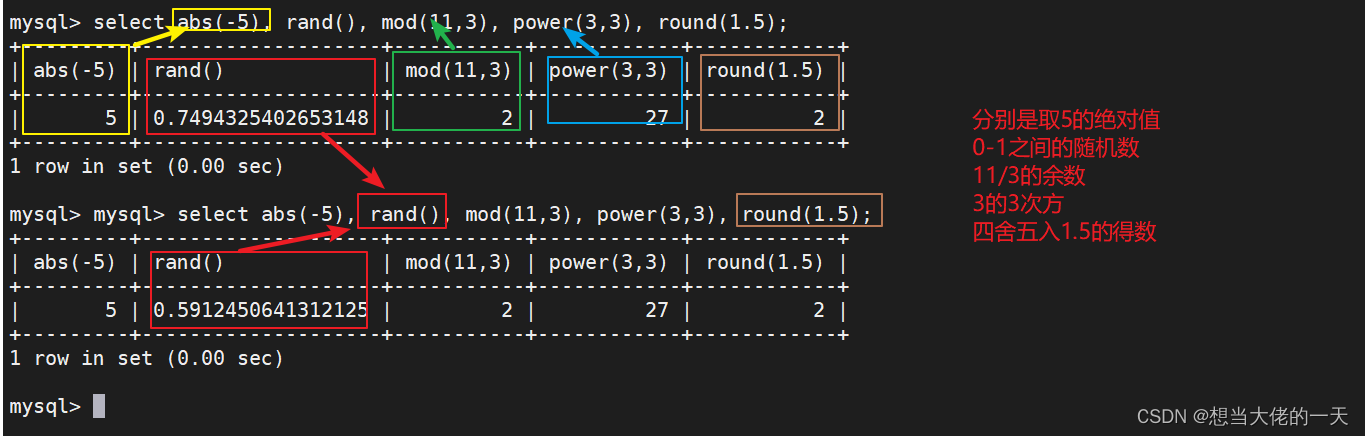
select abs(-5), rand(), mod(11,3), power(3,3), round(1.5);
select round(1.8915,2), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.1,3,6.1,2.1);

5.2 聚合函数
| 函数名 | 功能 |
|---|---|
| avg() | 返回指定列的平均值 |
| count( 字段 ) | 返回指定列中非 NULL 值的个数(行数) |
| count(*) | 返回指定列中所有行数,不忽略NULL值 |
| min( ) | 返回指定列的最小值 |
| max( ) | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
5.2.1 示例
avg
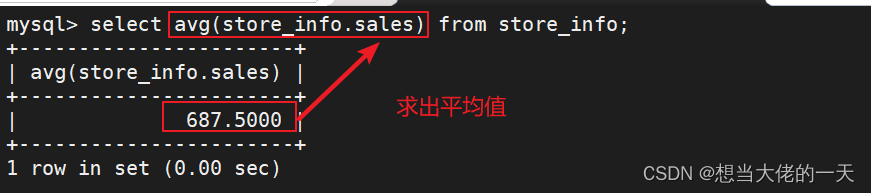
select avg(store_info.sales) from store_info;
count
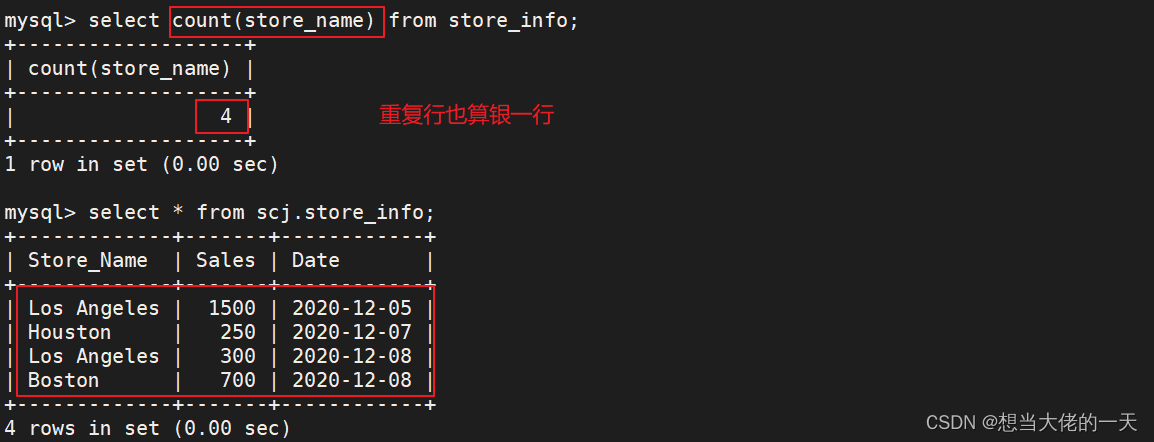
select count(store_name) from store_info;
select count(distinct store_name) from store_info;

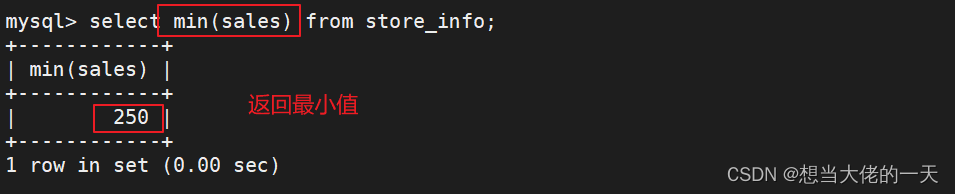
max 和 min
select max(sales) from store_info;
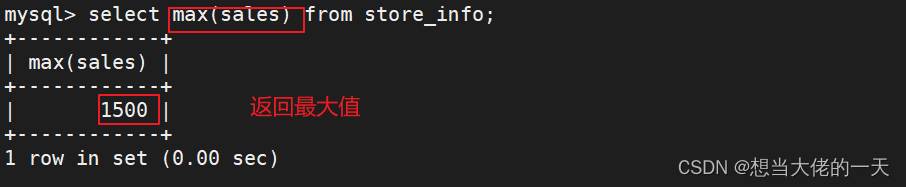
select min(sales) from store_info;
sum
select sum(sales) from store_info;

5.3 字符串函数
| 字符串函数 | 功能 |
|---|---|
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 替换,将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
5.3.1 示例
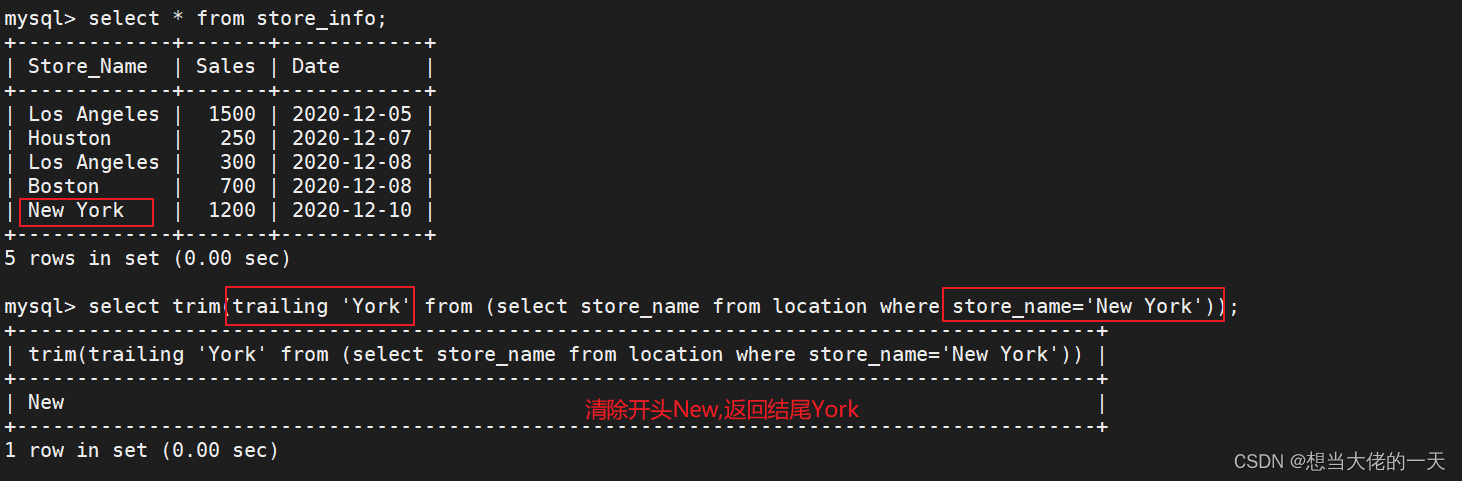
trim
#基本语法
select trim([ [位置] [要移除的字符串] from ] 字符串);
#[位置]:的值可以为 leading (起头), trailing (结尾), both (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
select trim(leading 'Los' from (select store_name from location where store_name='Los Angeles'))

select trim(trailing 'Nork' from (select store_name from location where store_name='New Nork'));
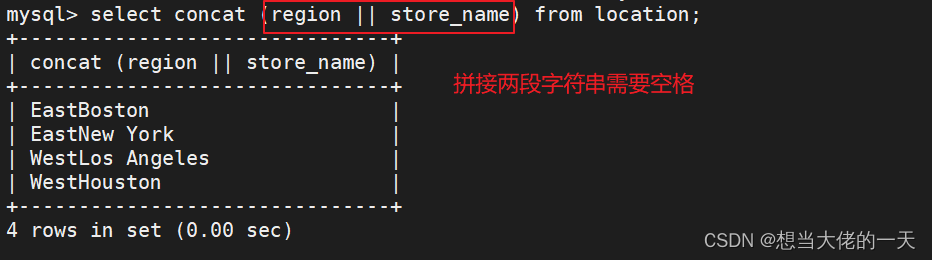
concat
字段名 不要加 ' '
字符串 要加' '
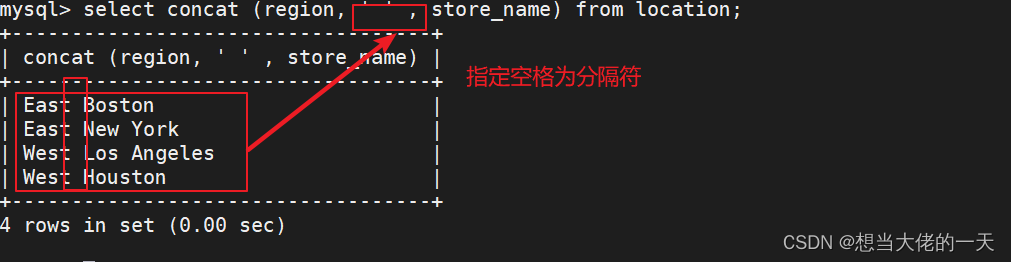
select concat (region || store_name) from location;
select concat (region, ' ' , store_name) from location;
substr
select substr(store_name,4) from location where store_name ='Los Angeles';
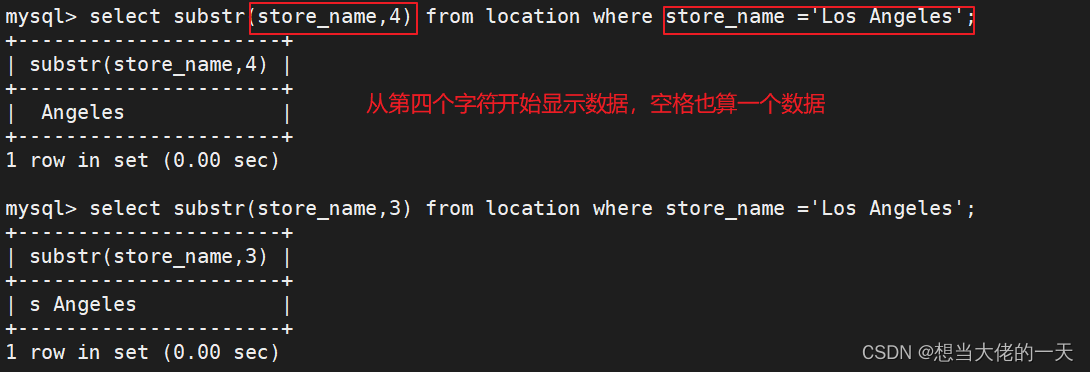
select substr(store_name,5,6) from location where store_name ='Los Angeles';

length
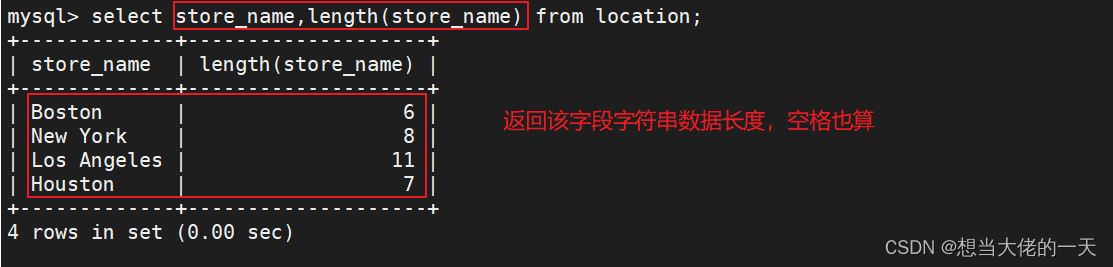
select store_name,length(store_name) from location;
replace
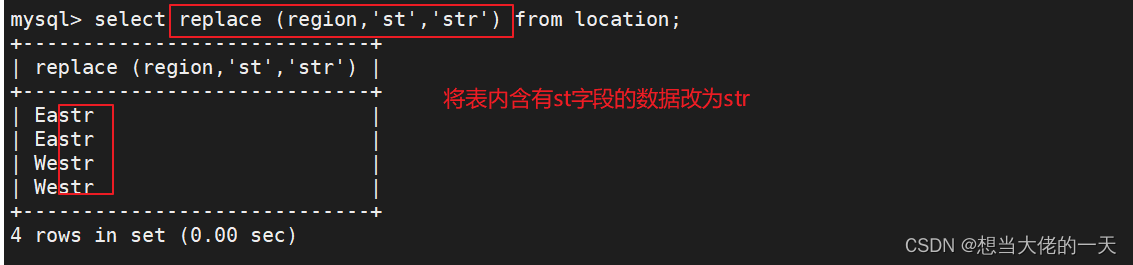
select replace (region,'st','str') from location;
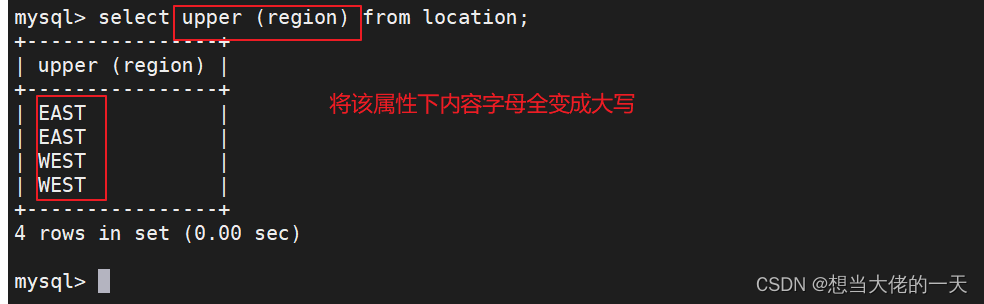
upper
select upper (region) from location;
6. 连接查询
6.1 表连接
| 表连接 | 概述 |
|---|---|
| inner join | 内连接 只返回两个表中联结字段相等的行记录 |
| left join | 左连接 返回包括左表中的所有记录和右表中联结字段相等的记录,不相等的部分返回NULL |
| right join | 右连接 返回包括右表中的所有记录和左表中联结字段相等的记录,不相等的部分返回NULL |
| union | 联集 将两个select查询语句的结果合并,并去重 |
| union all | 联集 将两个select查询语句的结果合并,不去重 |
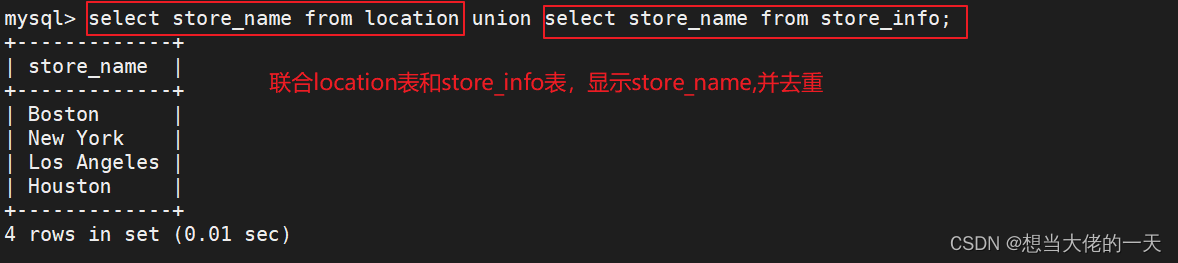
6.2 union语句 ---- 联集
联集,将两个sql语句的结果合并起来,两个sql语句所产生的字段需要是同样的数据记录种类。
union :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序。
#基本语法
[select 语句 1] union [select 语句 2];
select store_name from location union select store_name from store_info;
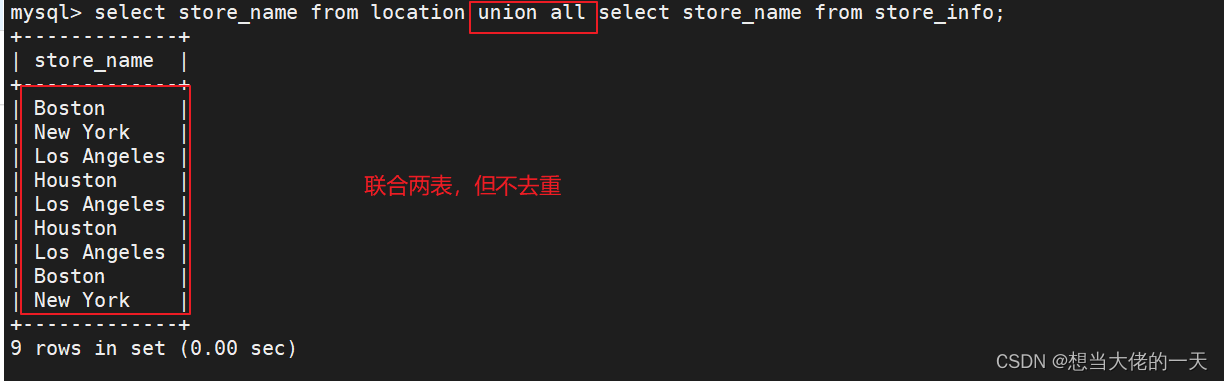
union all :将生成结果的数据记录值全部都列出来,但不去重
select store_name from location union all select store_name from store_info;
6.3 多表查询 — 求交集值
#基本语法格式
select A.字段 from 左表 A inner join 右表 B on A.字段 = B.字段;
select A.字段 from 左表 A inner join 右表 B using(同名字段);
select A.字段 from 左表 A, 右表 B where A.字段 = B.字段;
select A.字段 from 左表 A where A.字段 in (select B.字段 from 右表 B);
select A.字段 from 左表 A left join 右表 B on A.字段 = B.字段 where B.字段 is not null;
select B.字段 from 左表 A right join 右表 B on A.字段 = B.字段 where A.字段 is not null;
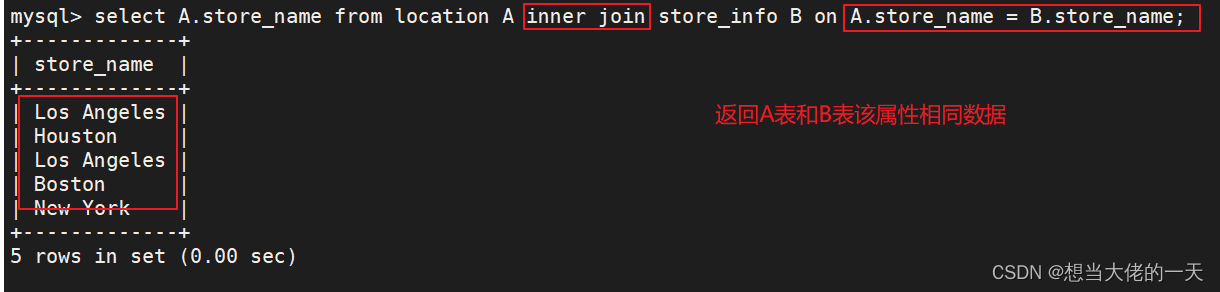
6.3.1 示例
#求交集
#方式一
select A.store_name from location A inner join store_info B on A.store_name = B.store_name;
select A.store_name from location A inner join store_info B using (store_name);
6.4 多表查询 ---- 求无交集值
显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复。
求左表无交集
select A.字段 from 左表 A left join 右表 B on A.字段 = B.字段 where B.字段 is null;
select 字段 from 左表 where 字段 not in (select 字段 from 右表);
求右表无交集
select B.字段 from 左表 A right join 右表 B on A.字段 = B.字段 where A.字段 is null;
select 字段 from 右表 where 字段 not in (select 字段 from 左表);
求多表的无交集
select A.字段 from (select distinct 字段 from 左表 union all select distinct 字段 from 右表) A group by A.字段 having count(A.字段)=1;
6.4.1 示例
select distinct store_name from location where (store_name) not in ( select store_name from store_info);
#子查询`select store_name from store_info`从"store_info"表中选择所有的店铺名称。
#主查询`select distinct store_name from location`从"location"表中选择所有不重复的店铺名称。
#使用`where (store_name) not in`条件将主查询中的店铺名称过滤掉那些在子查询结果中出现的店铺名称。

select A.store_name from location A left join store_info B on A.store_name = B.store_name where B.store_name is null;
#使用‘left join’ 将“location标记为左表A”,"store_info表标记为右表B"
#使用`where B.store_name is NULL`条件过滤掉在连接结果中,店铺名称在"location"表中出现但在"store_info"表中没有匹配的记录。

7. SQL语句的执行先后
FROM
<left table>
ON
<join_condition>
<join_type>
JOIN
<right_table>
WHERE
<where condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
SELECT
DISTINCT
<select list>
ORDER BY
<order_by_condition>
LIMIT
<limit number>
########################################################################################################
在SQL中,一般而言,SQL查询语句的执行顺序如下:
1. FROM:指定要查询的数据表或视图。
2. JOIN:根据指定的条件连接多个表。
3. WHERE:基于指定的条件筛选出符合要求的行。
4. GROUP BY:按照指定的列进行分组。
5. HAVING:对分组后的结果进行条件筛选。
6. SELECT:选择要返回的列。
7. DISTINCT:去除重复的行。
8. ORDER BY:按照指定的列进行排序。
9. LIMIT/OFFSET:限制返回的结果数量和起始位置。