大多数业务项目都是由同步处理、异步处理和定时任务处理三种模式相辅相成实现的。
区别于同步处理,异步处理无需同步等待流程处理完毕,因此适用场景主要包括:
- 服务于主流程的分支流程。比如,在注册流程中,把数据写入数据库的操作是主流程,但注册后给用户发优惠券或欢迎短信的操作是分支流程,时效性不那么强,可以进行异步处理。
- 用户不需要实时看到结果的流程。比如,下单后的配货、送货流程完全可以进行异步处理,每个阶段处理完成后,再给用户发推送或短信让用户知晓即可。
异步处理因为可以有 MQ 中间件的介入用于任务的缓冲的分发,所以相比于同步处理,在应对流量洪峰、实现模块解耦和消息广播方面有功能优势。
用三个代码案例结合目前常用的 MQ 系统 RabbitMQ讲解
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
异步处理需要消息补偿闭环
使用类似 RabbitMQ、RocketMQ 等 MQ 系统来做消息队列实现异步处理,虽然说消息可以落地到磁盘保存,即使 MQ 出现问题消息数据也不会丢失,但是异步流程在消息发送、传输、处理等环节,都可能发生消息丢失。此外,任何 MQ 中间件都无法确保 100% 可用,需要考虑不可用时异步流程如何继续进行。
对于异步处理流程,必须考虑补偿或者说建立主备双活流程。
我们来看一个用户注册后异步发送欢迎消息的场景。用户注册落数据库的流程为同步流程,会员服务收到消息后发送欢迎消息的流程为异步流程。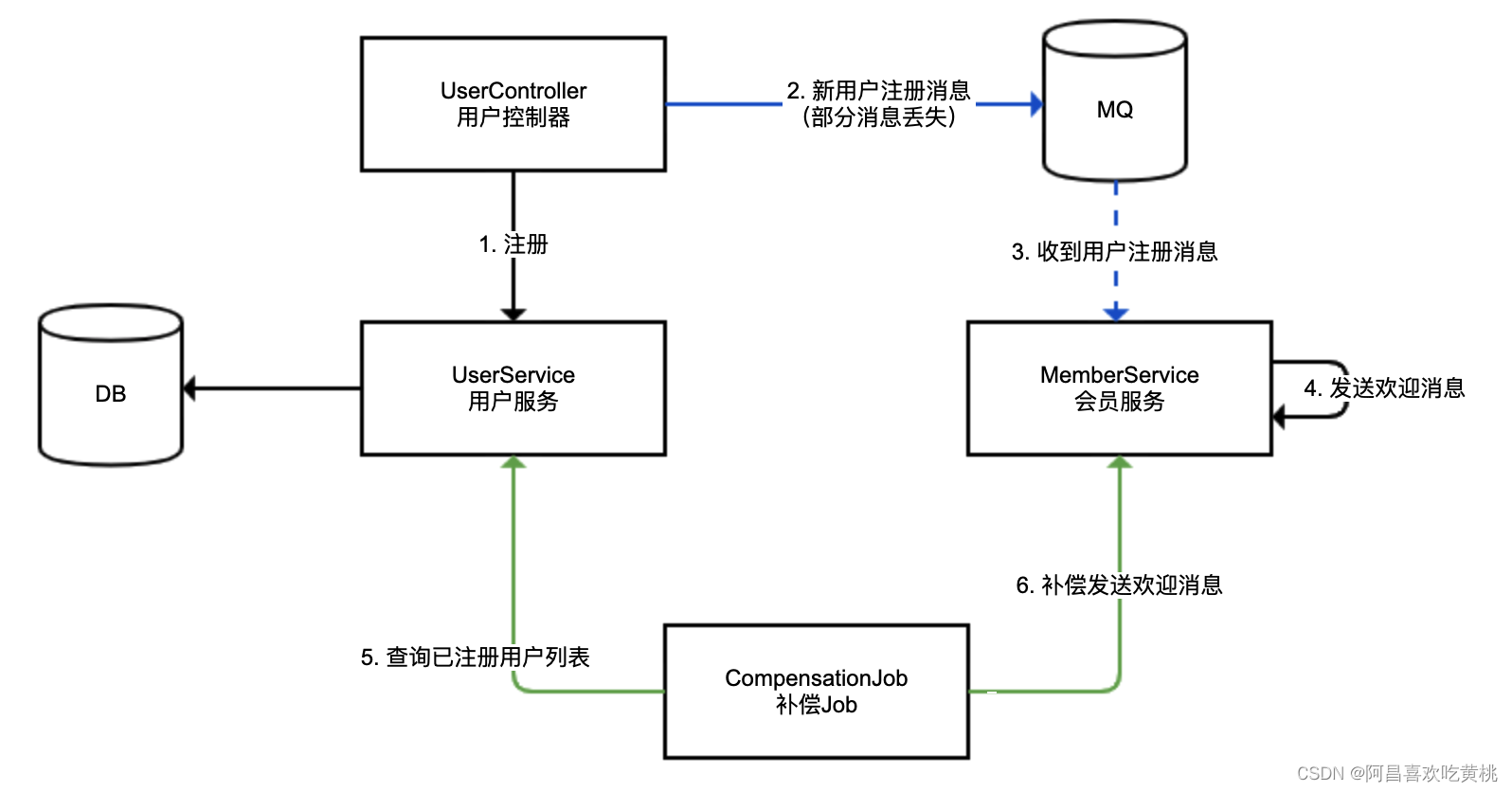
- 蓝色的线,使用 MQ 进行的异步处理,我们称作主线,可能存在消息丢失的情况(虚线代表异步调用);
- 绿色的线,使用补偿 Job 定期进行消息补偿,我们称作备线,用来补偿主线丢失的消息;
- 考虑到极端的 MQ 中间件失效的情况,我们要求备线的处理吞吐能力达到主线的能力水平。
实现代码:
首先,定义 UserController 用于注册 + 发送异步消息。对于注册方法,我们一次性注册 10 个用户,用户注册消息不能发送出去的概率为 50%。
@RestController
@Slf4j
@RequestMapping("user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("register")
public void register() {
//模拟10个用户注册
IntStream.rangeClosed(1, 10).forEach(i -> {
//落库
User user = userService.register();
//模拟50%的消息可能发送失败
if (ThreadLocalRandom.current().nextInt(10) % 2 == 0) {
//通过RabbitMQ发送消息
rabbitTemplate.convertAndSend(RabbitConfiguration.EXCHANGE, RabbitConfiguration.ROUTING_KEY, user);
log.info("sent mq user {}", user.getId());
}
});
}
}
然后,定义 MemberService 类用于模拟会员服务。会员服务监听用户注册成功的消息,并发送欢迎短信。
我们使用 ConcurrentHashMap 来存放那些发过短信的用户 ID 实现幂等,避免相同的用户进行补偿时重复发送短信:
@Component
@Slf4j
public class MemberService {
// 发送欢迎消息的状态
private Map<Long, Boolean> welcomeStatus = new ConcurrentHashMap<>();
// 监听用户注册成功的消息,发送欢迎消息
@RabbitListener(queues = RabbitConfiguration.QUEUE)
public void listen(User user) {
log.info("receive mq user {}", user.getId());
welcome(user);
}
//发送欢迎消息
public void welcome(User user) {
//去重操作
if (welcomeStatus.putIfAbsent(user.getId(), true) == null) {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
}
log.info("memberService: welcome new user {}", user.getId());
}
}
}
对于 MQ 消费程序,处理逻辑务必考虑去重(支持幂等),原因有几个:
- MQ 消息可能会因为中间件本身配置错误、稳定性等原因出现重复。
- 自动补偿重复,比如本例,同一条消息可能既走 MQ 也走补偿,肯定会出现重复,而且考虑到高内聚,补偿 Job 本身不会做去重处理。
- 人工补偿重复。出现消息堆积时,异步处理流程必然会延迟。如果我们提供了通过后台进行补偿的功能,那么在处理遇到延迟的时候,很可能会先进行人工补偿,过了一段时间后处理程序又收到消息了,重复处理。我之前就遇到过一次由 MQ 故障引发的事故,MQ 中堆积了几十万条发放资金的消息,导致业务无法及时处理,运营以为程序出错了就先通过后台进行了人工处理,结果 MQ 系统恢复后消息又被重复处理了一次,造成大量资金重复发放。
定义补偿 Job 也就是备线操作:
我们在 CompensationJob 中定义一个 @Scheduled 定时任务,5 秒做一次补偿操作,因为 Job 并不知道哪些用户注册的消息可能丢失,所以是全量补偿,补偿逻辑是:每 5 秒补偿一次,按顺序一次补偿 5 个用户,下一次补偿操作从上一次补偿的最后一个用户 ID 开始;对于补偿任务我们提交到线程池进行“异步”处理,提高处理能力
@Component
@Slf4j
public class CompensationJob {
// 补偿Job异步处理线程池
private static ThreadPoolExecutor compensationThreadPool = new ThreadPoolExecutor(
10, 10,
1, TimeUnit.HOURS,
new ArrayBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("compensation-threadpool-%d").get());
@Autowired
private UserService userService;
@Autowired
private MemberService memberService;
// 目前补偿到哪个用户ID
private long offset = 0;
// 10秒后开始补偿,5秒补偿一次
@Scheduled(initialDelay = 10_000, fixedRate = 5_000)
public void compensationJob() {
log.info("开始从用户ID {} 补偿", offset);
// 获取从offset开始的用户
userService.getUsersAfterIdWithLimit(offset, 5).forEach(user -> {
compensationThreadPool.execute(() -> memberService.welcome(user));
offset = user.getId();
});
}
}
为了实现高内聚,主线和备线处理消息,最好使用同一个方法。
本例中 MemberService 监听到 MQ 消息和 CompensationJob 补偿,调用的都是 welcome 方法。
此外值得一说的是,Demo 中的补偿逻辑比较简单,生产级的代码应该在以下几个方面进行加强:
- 考虑配置补偿的频次、每次处理数量,以及补偿线程池大小等参数为合适的值,以满足补偿的吞吐量。
- 考虑备线补偿数据进行适当延迟。比如,对注册时间在 30 秒之前的用户再进行补偿,以方便和主线 MQ 实时流程错开,避免冲突。
- 诸如当前补偿到哪个用户的 offset 数据,需要落地数据库。
- 补偿 Job 本身需要高可用,可以使用类似 XXLJob 或 ElasticJob 等任务系统。
上面的补偿代码还是可以的,就是补偿有一点点延迟。
注意消息模式是广播还是工作队列
消息广播,和我们平时说的“广播”意思差不多,就是希望同一条消息,不同消费者都能分别消费;而队列模式,就是不同消费者共享消费同一个队列的数据,相同消息只能被某一个消费者消费一次。
同一个用户的注册消息,会员服务需要监听以发送欢迎短信,营销服务同样需要监听以发送新用户小礼物。但是,会员服务、营销服务都可能有多个实例,我们期望的是同一个用户的消息,可以同时广播给不同的服务(广播模式),但对于同一个服务的不同实例(比如会员服务 1 和会员服务 2),不管哪个实例来处理,处理一次即可(工作队列模式):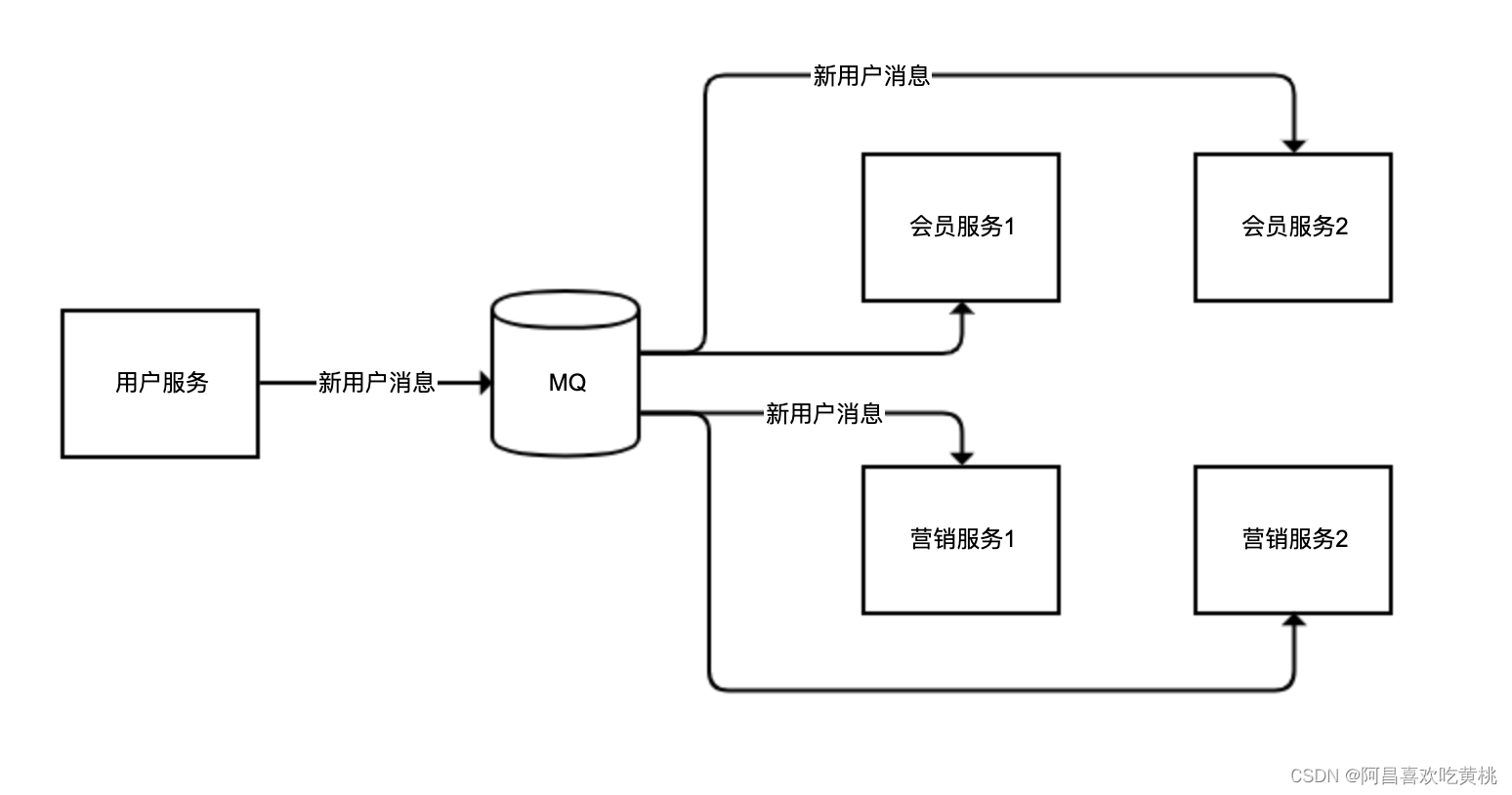
//为了代码简洁直观,我们把消息发布者、消费者、以及MQ的配置代码都放在了一起
@Slf4j
@Configuration
@RestController
@RequestMapping("workqueuewrong")
public class WorkQueueWrong {
private static final String EXCHANGE = "newuserExchange";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
//使用匿名队列作为消息队列
@Bean
public Queue queue() {
return new AnonymousQueue();
}
//声明DirectExchange交换器,绑定队列到交换器
@Bean
public Declarables declarables() {
DirectExchange exchange = new DirectExchange(EXCHANGE);
return new Declarables(queue(), exchange,
BindingBuilder.bind(queue()).to(exchange).with(""));
}
//监听队列,队列名称直接通过SpEL表达式引用Bean
@RabbitListener(queues = "#{queue.name}")
public void memberService(String userName) {
log.info("memberService: welcome message sent to new user {} from {}", userName, System.getProperty("server.port"));
}
}
目前这样,一个服务的两个实例都接收到了消息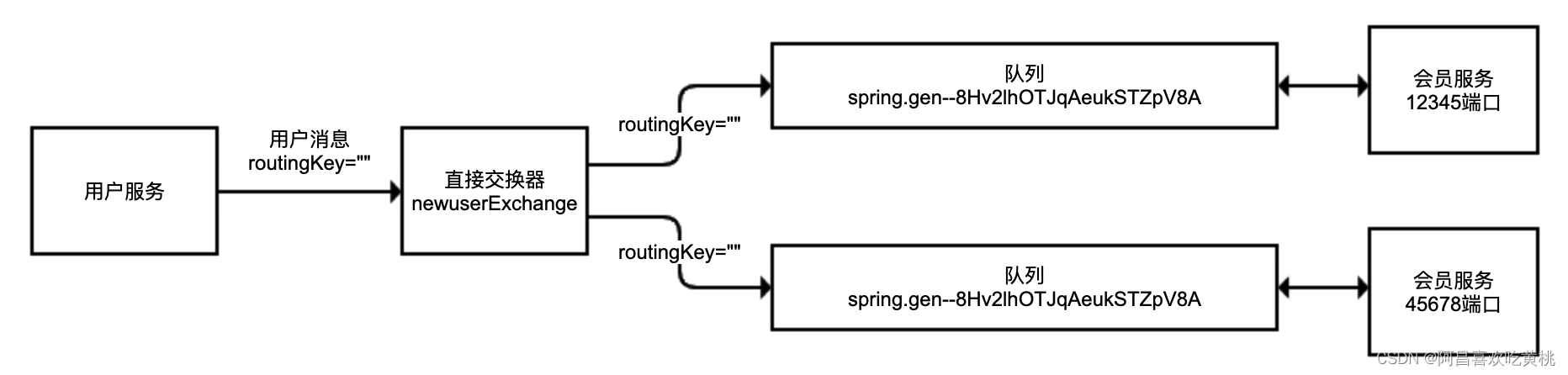
private static final String QUEUE = "newuserQueue";
@Bean
public Queue queue() {
return new Queue(QUEUE);
}
第二步,进一步完整实现用户服务需要广播消息给会员服务和营销服务的逻辑。
我们希望会员服务和营销服务都可以收到广播消息,但会员服务或营销服务中的每个实例只需要收到一次消息。
代码如下,我们声明了一个队列和一个广播交换器 FanoutExchange,然后模拟两个用户服务和两个营销服务:
@Slf4j
@Configuration
@RestController
@RequestMapping("fanoutwrong")
public class FanoutQueueWrong {
private static final String QUEUE = "newuser";
private static final String EXCHANGE = "newuser";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
//声明FanoutExchange,然后绑定到队列,FanoutExchange绑定队列的时候不需要routingKey
@Bean
public Declarables declarables() {
Queue queue = new Queue(QUEUE);
FanoutExchange exchange = new FanoutExchange(EXCHANGE);
return new Declarables(queue, exchange,
BindingBuilder.bind(queue).to(exchange));
}
// 会员服务实例1
@RabbitListener(queues = QUEUE)
public void memberService1(String userName) {
log.info("memberService1: welcome message sent to new user {}", userName);
}
//会员服务实例2
@RabbitListener(queues = QUEUE)
public void memberService2(String userName) {
log.info("memberService2: welcome message sent to new user {}", userName);
}
//营销服务实例1
@RabbitListener(queues = QUEUE)
public void promotionService1(String userName) {
log.info("promotionService1: gift sent to new user {}", userName);
}
//营销服务实例2
@RabbitListener(queues = QUEUE)
public void promotionService2(String userName) {
log.info("promotionService2: gift sent to new user {}", userName);
}
}
通过日志可以发现,一条用户注册的消息,要么被会员服务收到,要么被营销服务收到,显然这不是广播。
其实,广播交换器非常简单,它会忽略 routingKey,广播消息到所有绑定的队列。在这个案例中,两个会员服务和两个营销服务都绑定了同一个队列,所以这四个服务只能收到一次消息:
修改方式很简单,我们把队列进行拆分,会员和营销两组服务分别使用一条独立队列绑定到广播交换器即可
@Slf4j
@Configuration
@RestController
@RequestMapping("fanoutright")
public class FanoutQueueRight {
private static final String MEMBER_QUEUE = "newusermember";
private static final String PROMOTION_QUEUE = "newuserpromotion";
private static final String EXCHANGE = "newuser";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
@Bean
public Declarables declarables() {
//会员服务队列
Queue memberQueue = new Queue(MEMBER_QUEUE);
//营销服务队列
Queue promotionQueue = new Queue(PROMOTION_QUEUE);
//广播交换器
FanoutExchange exchange = new FanoutExchange(EXCHANGE);
//两个队列绑定到同一个交换器
return new Declarables(memberQueue, promotionQueue, exchange,
BindingBuilder.bind(memberQueue).to(exchange),
BindingBuilder.bind(promotionQueue).to(exchange));
}
@RabbitListener(queues = MEMBER_QUEUE)
public void memberService1(String userName) {
log.info("memberService1: welcome message sent to new user {}", userName);
}
@RabbitListener(queues = MEMBER_QUEUE)
public void memberService2(String userName) {
log.info("memberService2: welcome message sent to new user {}", userName);
}
@RabbitListener(queues = PROMOTION_QUEUE)
public void promotionService1(String userName) {
log.info("promotionService1: gift sent to new user {}", userName);
}
@RabbitListener(queues = PROMOTION_QUEUE)
public void promotionService2(String userName) {
log.info("promotionService2: gift sent to new user {}", userName);
}
}
对于每一条 MQ 消息,会员服务和营销服务分别都会收到一次,一条消息广播到两个服务的同时,在每一个服务的两个实例中通过轮询接收:
别让死信堵塞了消息队列
在很多时候,消息队列的堆积堵塞,是因为有大量始终无法处理的消息。
用户服务在用户注册后发出一条消息,会员服务监听到消息后给用户派发优惠券,但因为用户并没有保存成功,会员服务处理消息始终失败,消息重新进入队列,然后还是处理失败。这种在 MQ 中像幽灵一样回荡的同一条消息,就是死信。
随着 MQ 被越来越多的死信填满,消费者需要花费大量时间反复处理死信,导致正常消息的消费受阻,最终 MQ 可能因为数据量过大而崩溃。
我们更希望的逻辑是,对于同一条消息,能够先进行几次重试,解决因为网络问题导致的偶发消息处理失败,如果还是不行的话,再把消息投递到专门的一个死信队列。对于来自死信队列的数据,我们可能只是记录日志发送报警,即使出现异常也不会再重复投递。整个逻辑如下图所示: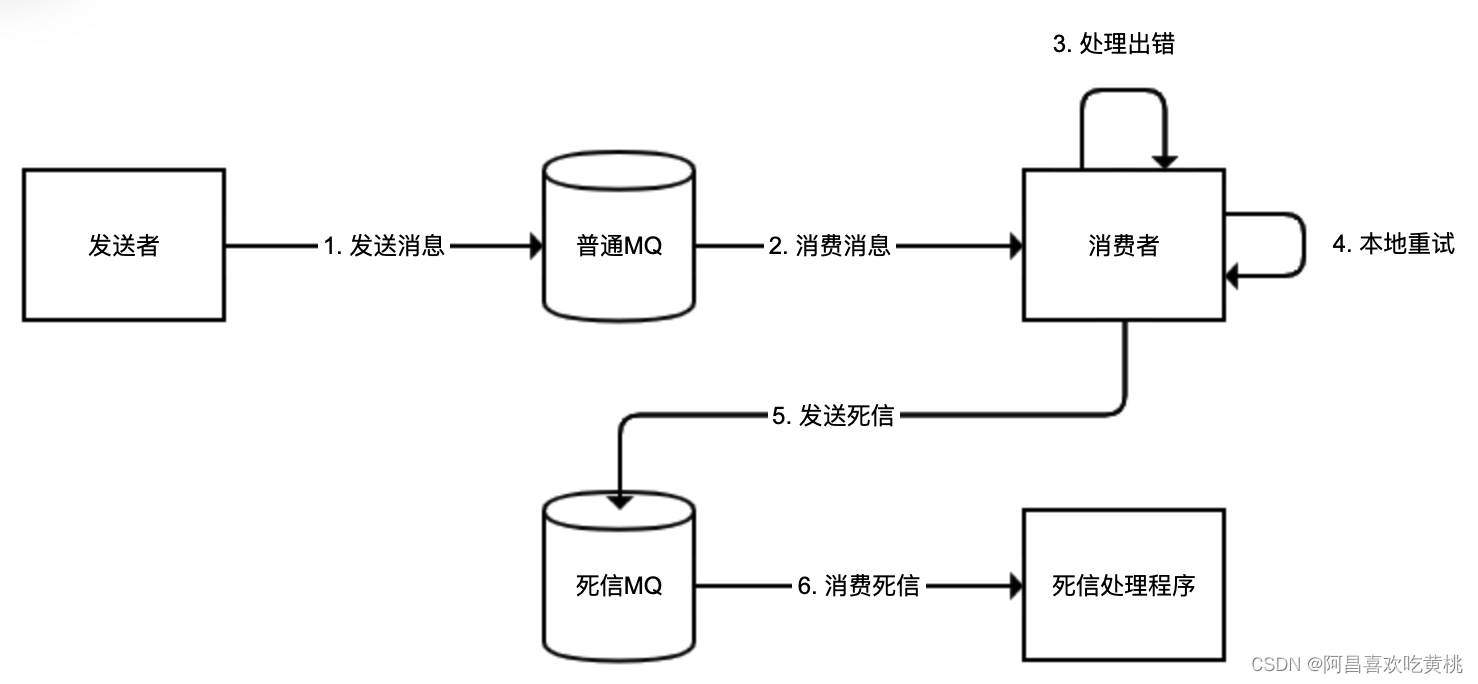
//定义死信交换器和队列,并且进行绑定
@Bean
public Declarables declarablesForDead() {
Queue queue = new Queue(Consts.DEAD_QUEUE);
DirectExchange directExchange = new DirectExchange(Consts.DEAD_EXCHANGE);
return new Declarables(queue, directExchange,
BindingBuilder.bind(queue).to(directExchange).with(Consts.DEAD_ROUTING_KEY));
}
//定义重试操作拦截器
@Bean
public RetryOperationsInterceptor interceptor() {
return RetryInterceptorBuilder.stateless()
.maxAttempts(5) //最多尝试(不是重试)5次
.backOffOptions(1000, 2.0, 10000) //指数退避重试
.recoverer(new RepublishMessageRecoverer(rabbitTemplate, Consts.DEAD_EXCHANGE, Consts.DEAD_ROUTING_KEY)) //重新投递重试达到上限的消息
.build();
}
//通过定义SimpleRabbitListenerContainerFactory,设置其adviceChain属性为之前定义的RetryOperationsInterceptor来启用重试拦截器
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setAdviceChain(interceptor());
return factory;
}
//死信队列处理程序
@RabbitListener(queues = Consts.DEAD_QUEUE)
public void deadHandler(String data) {
log.error("got dead message {}", data);
}
可以通过增加消费线程来避免性能问题,如下我们直接设置 concurrentConsumers 参数为 10,来增加到 10 个工作线程:
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setAdviceChain(interceptor());
factory.setConcurrentConsumers(10);
return factory;
}
—
我之前做过一个demo 是基于canal做mysql数据同步,需要将解析好的数据发到kafka里面,再进行处理。在使用的时候发现这么一个问题,就是kafka多partition消费时不能保证消息的顺序消费,进而导致mysql数据同步异常。由于kafka可以保证在同一个partition内消息有序,于是我自定义了一个分区器,将数据的id取hashcode然后根据partition的数量取余作为分区号,保证同一条数据的binlog能投递到同一个partition中,从而达到消息顺序消费的目的。
在用户注册后发送消息到 MQ,然后会员服务监听消息进行异步处理的场景下,有些时候会发现,虽然用户服务先保存数据再发送 MQ,但会员服务收到消息后去查询数据库,却发现数据库中还没有新用户的信息。
当时倒不是因为主从的问题,而是因为业务代码把保存数据和发MQ消息放在了一个事务中,有概率收到消息的时候事务还没有提交完成,当时开发同学的处理方式是收MQ消息的时候sleep 1秒,或许应该是先提交事务,完成后再发MQ消息,但是这又出来一个问题MQ消息发送失败怎么办?所以后来演化为建立本地消息表来确保MQ消息可补偿,把业务处理和保存MQ消息到本地消息表操作在相同事务内处理,然后异步发送和补偿发送消息表中的消息到MQ