1. 互相关运算
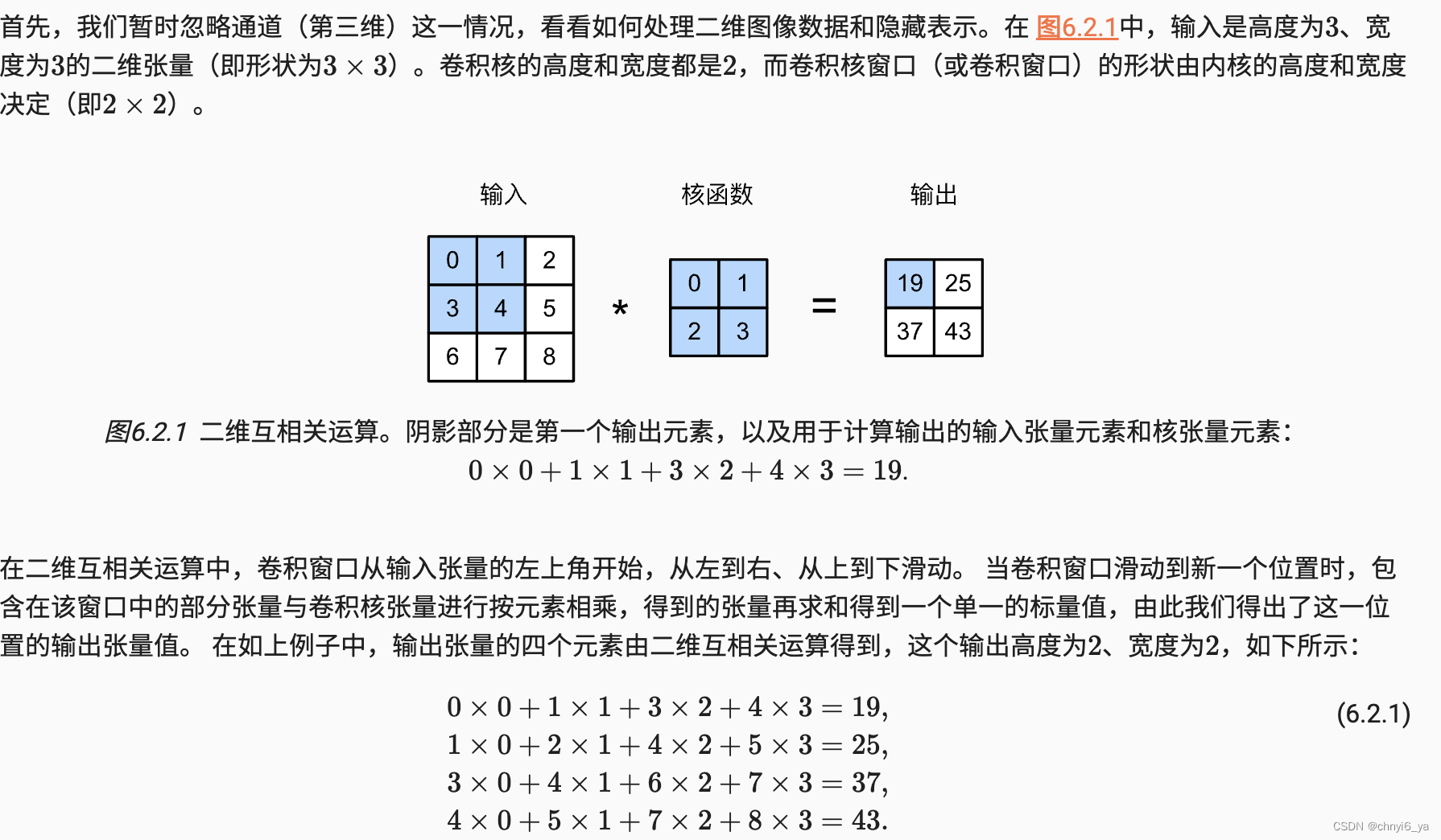
接下来,我们在corr2d函数中实现如上过程,该函数接受输入张量X和卷积核张量K,并返回输出张量Y。
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X,K): # X是输入,K是核矩阵
'''计算二维互相关运算'''
# 从K的shape中拿出h(height)--行数和w(wide)--列数
h, w = K.shape # 核的行数和列数
# 输出的行数=输入的行数-核的行数+1,列数同理
Y = torch.zeros((X.shape[0]-h+1,X.shape[1]-w+1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i,j] = (X[i:i+h,j:j+w] * K).sum()
return Y
验证上述二维互相关运算的输出。
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
corr2d(X, K)

2. 卷积层
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。 所以,卷积层中的两个被训练的参数是卷积核权重和标量偏置。 就像我们之前随机初始化全连接层一样,在训练基于卷积层的模型时,我们也随机初始化卷积核权重。
基于上面定义的corr2d函数实现二维卷积层。在__init__构造函数中,将weight和bias声明为两个模型参数。前向传播函数调用corr2d函数并添加偏置。
class Conv2D(nn.Module):
def __init__(self,kernel_size):
super().__init__()
# 可以在kernel_size这个参数传一个tuple,例如(3,3),则weight就是3*3的随机初始值了
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self,x):
return corr2d(x,self.weight) + self.bias
3.图像中目标的边缘检测
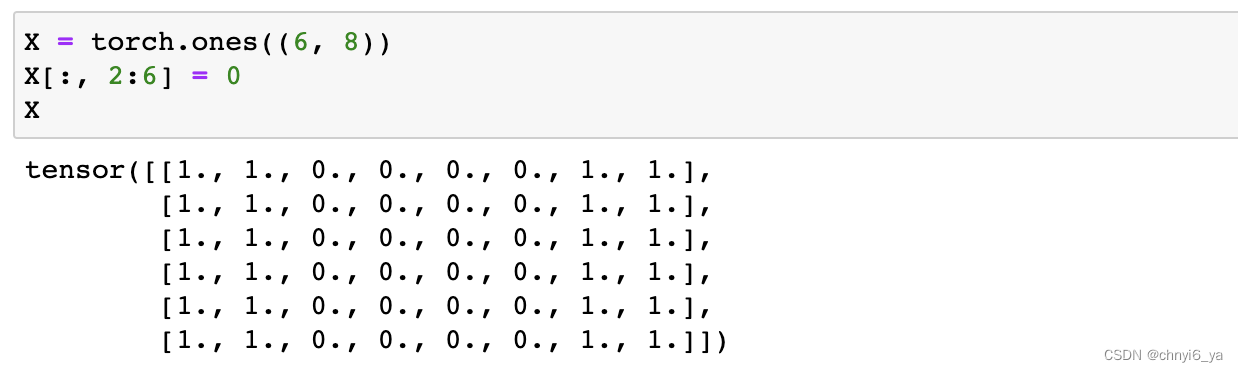
如下是卷积层的一个简单应用:通过找到像素变化的位置,来检测图像中不同颜色的边缘。 首先,我们构造一个6 * 8像素的黑白图像。中间四列为黑色(0),其余像素为白色(1)。
接下来,我们构造一个高度为1、宽度为2的卷积核K。当进行互相关运算时,如果水平相邻的两元素相同,则输出为零,否则输出为非零。
K = torch.tensor([[1.0, -1.0]])
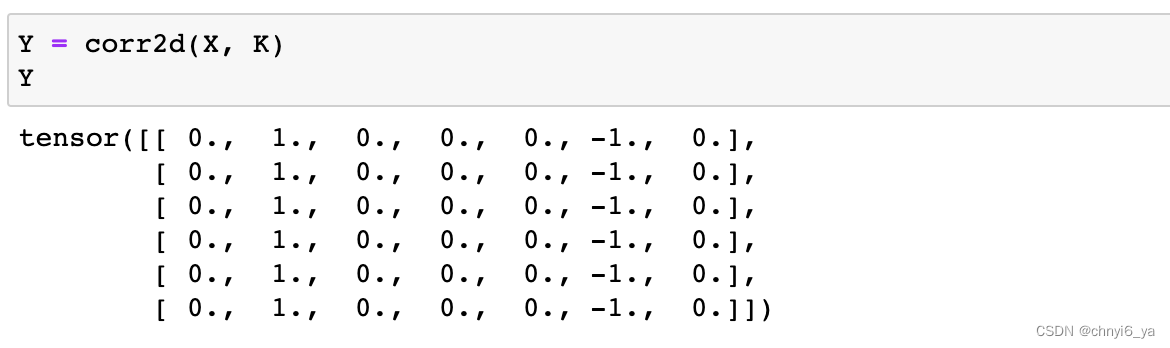
现在,我们对参数X(输入)和K(卷积核)执行互相关运算。 如下所示,输出Y中的1代表从白色到黑色的边缘,-1代表从黑色到白色的边缘,其他情况的输出为0。
如果两个元素没有改变,如都是1,则结果为0,或者两个元素都是0,结果也为0。反之,元素改变了如1,0,则结果为1,两个元素为0,1,则结果为-1.因此可以做白到黑的边缘检测。
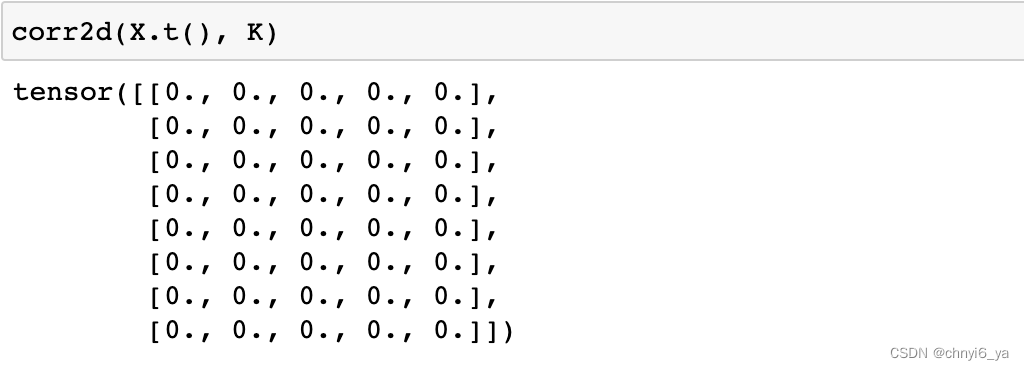
现在我们将输入的二维图像转置,再进行如上的互相关运算。 其输出如下,之前检测到的垂直边缘消失了。 不出所料,这个卷积核K只可以检测垂直边缘,无法检测水平边缘。
因为是1 * 2,只有相邻的2列参与运算,X转置后,相邻列元素是相同的,也就是每一行内的元素一致,进行相关运算后都为0,看不出变化,所以检测不了水平。要想解决的话,K也需要转置变成 2 *1。
4. 学习卷积核
如果我们只需寻找黑白边缘,那么以上[1, -1]的边缘检测器足以。然而,当有了更复杂数值的卷积核,或者连续的卷积层时,我们不可能手动设计滤波器。那么我们是否可以学习由X生成Y的卷积核呢?
现在让我们看看是否可以通过仅查看“输入-输出”对来学习由X生成Y的卷积核。 我们先构造一个卷积层,并将其卷积核初始化为随机张量。接下来,在每次迭代中,我们比较Y与卷积层输出的平方误差,然后计算梯度来更新卷积核。为了简单起见,我们在此使用内置的二维卷积层,并忽略偏置。
关于内置的二维卷积层
# 构造一个二维卷积层,它具有1个输入通道和输出通道,以及形状为(1,2)的卷积核
# 黑白图片通道为1,彩色图片通道为3
conv2d = nn.Conv2d(1,1,kernel_size=(1,2),bias = False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
# ps:对所有的框架来说,向Conv2d传递的参数都是4d的
X = X.reshape((1,1,6,8))
Y = Y.reshape((1,1,6,7))
# 手写训练逻辑,迭代10轮
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) **2
conv2d.zero_grad()
l.sum().backward()
# 做了backward()之后,就能通过.grad获得梯度
conv2d.weight.data[:] -= 3e-2 *conv2d.weight.grad # 3e-2是学习率
if (i+1) % 2 ==0: # 每两轮迭代就输出loss
print(f'batch {i+1},loss{l.sum():.3f}')

在10次迭代之后,误差已经降到足够低。现在我们来看看我们所学的卷积核的权重张量。

细心的读者一定会发现,我们学习到的卷积核权重非常接近我们之前定义的卷积核K。