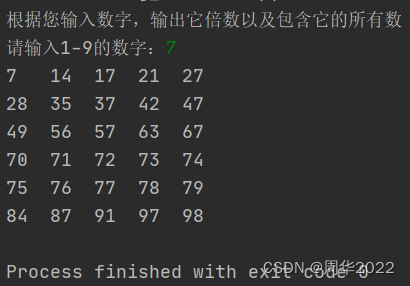
任务描述:现有一份“网易新闻语料”数据集,请尝试用Python或Java实现LDA算法并提取这份数据集中各个文档的主题,并显示出来(可参考下图的输出结果,可网上拷贝代码,但需对算法以及代码有一定的基本了解),其中,附件5中“news.dat”为“网易新闻语料”,包含了2043个文档,附件6为停止词列表(主要用于删除news.dat中的无效词,避免对主题提取的干扰)。
代码如下:
import jieba
import pickle
from gensim import corpora, models
# 1. 准备数据
with open('./Dateset/news.dat', 'r', encoding='utf-8') as f:
documents = f.readlines()
with open('./Dateset/stopword.txt', 'r', encoding='gbk') as f:
stopwords = [line.strip() for line in f.readlines()]
#
# 2. 数据预处理
texts = []
for doc in documents:
words = jieba.lcut(doc) #有关jieba.lcut 参见https://blog.csdn.net/liujingwei8610/article/details/121758179
words = [word for word in words if word not in stopwords]
texts.append(words)
# with open("texts.pkl", "wb") as f:
# pickle.dump(texts, f)
# with open("texts.pkl", "rb") as f:
# texts = pickle.load(f)
# 3. 构建词袋模型
dictionary = corpora.Dictionary(texts) #字典封装了规范化单词与其整数 ID 之间的映射。 简单来说,将每个字符串(词/词组)映射为不同数字
corpus = [dictionary.doc2bow(text) for text in texts] #dictionary.doc2bow(text) Convert `document` into the bag-of-words (BoW) format = list of `(token_id, token_count)` tuples.
# 4. 训练LDA模型
lda_model = models.LdaModel(corpus, num_topics=10, id2word=dictionary)
# #
# with open("lda_model.pkl", "wb") as f:
# pickle.dump(lda_model, f)
# with open("lda_model.pkl", "rb") as f:
# lda_model = pickle.load(f)
# 5. 提取主题
topics = []
for doc in corpus:
topic = lda_model.get_document_topics(doc,minimum_probability = 0.000001) #minimum_probability 避免概率过低,取不到足够的主题词
topics.append(topic)
# 6. 显示主题结果
print("10个文档的主题分布")
topicList=[]
for i, topic in enumerate(topics):
print(f"第 {i+1}个文档的前10个主题:")
for t in topic:
topicList.append(t[1])
print(topicList)
topicList.clear()
print()


完成一轮
for doc in documents:
words = jieba.lcut(doc) #有关jieba.lcut 参见https://blog.csdn.net/liujingwei8610/article/details/121758179
words = [word for word in words if word not in stopwords]
texts.append(words)texts内容如下:

完成 corpus = [dictionary.doc2bow(text) for text in texts] 后如下图。转换结果相当于每篇文章中的词频率统计。 说明:dictionary.doc2bow(text) Convert `document` into the bag-of-words (BoW) format = list of `(token_id, token_count)` tuples.

lda_model = models.LdaModel(corpus, num_topics=10, id2word=dictionary) 这里使用的Lda模型为发表于NIPS的论文:Online Learning for Latent Dirichlet Allocation 这里做简单介绍: 传统的LDA模型参见: 一文详解LDA主题模型 - 知乎 (zhihu.com)
《Online Learning for Latent Dirichlet Allocation》是一篇关于在线学习的隐含狄利克雷分配(Latent Dirichlet Allocation,简称LDA)的论文。
该论文主要介绍了一种在线学习的方法,用于在大规模文本数据集上进行LDA模型的训练和推断。传统的LDA算法需要将整个数据集加载到内存中进行批量处理,而在线学习的方法可以逐步处理数据,适用于数据量大、不断增长的场景。
论文中提出了一种基于变分推断的在线LDA算法,通过引入一些技巧和近似方法,实现了高效的在线学习和参数更新。该方法可以在不断到达新文档时,动态地更新模型参数,同时保持对历史文档的推断结果。
论文还介绍了在线LDA算法的推导过程、参数更新规则以及实验结果。通过在多个大规模文本数据集上进行实验,论文验证了在线LDA算法的有效性和可扩展性,对于处理大规模文本数据集和动态数据流具有重要的意义。
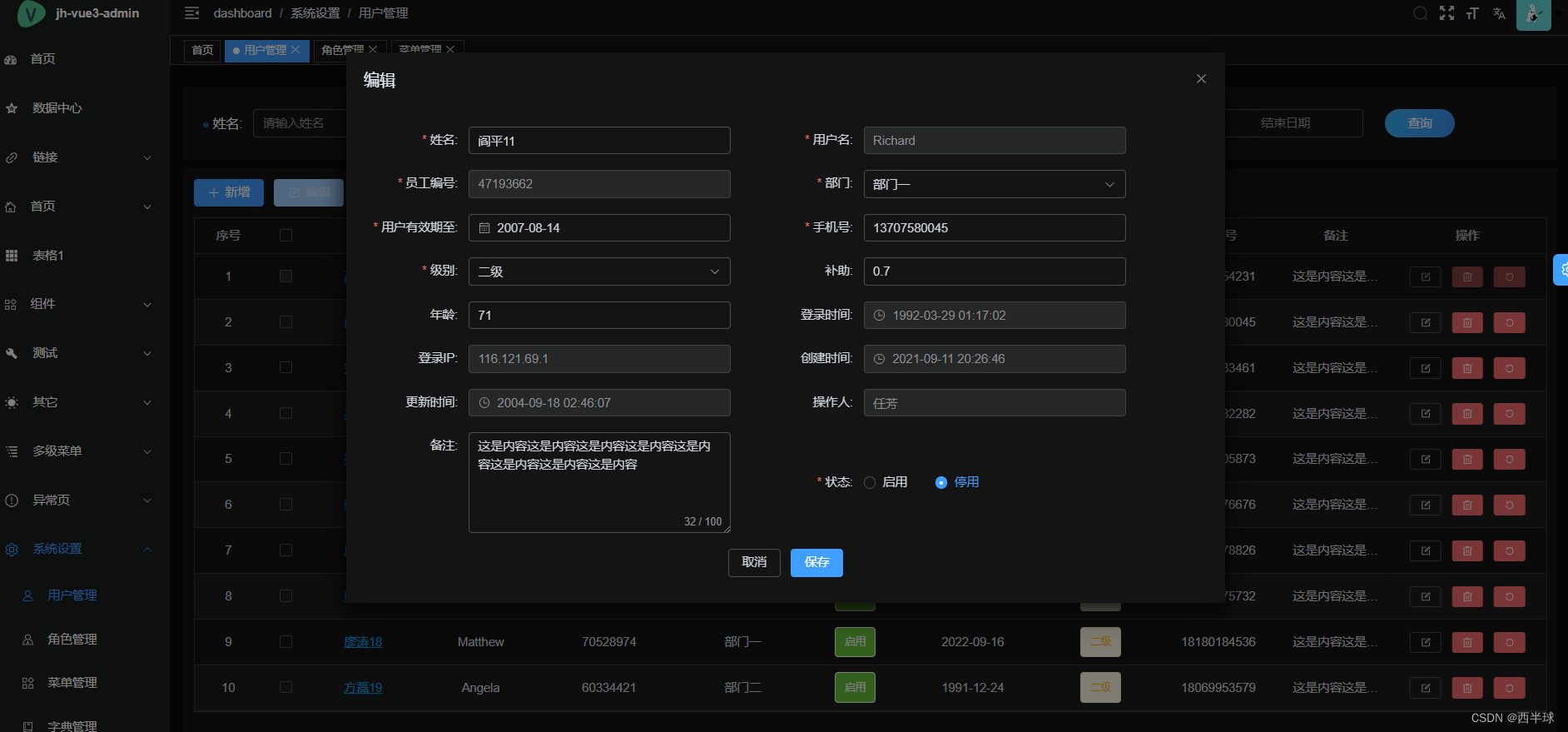
主题提取部分结果如下:
10个文档的主题分布
第 1个文档的前10个主题:
[0.01087394, 0.00019692296, 0.7152148, 0.00019692726, 0.00019692296, 0.00019694411, 0.00019694012, 0.15501586, 0.00019697643, 0.11771379]
第 2个文档的前10个主题:
[0.85160214, 6.795004e-05, 0.009034262, 6.7951565e-05, 6.795004e-05, 6.795801e-05, 6.795616e-05, 0.07648344, 0.044096787, 0.018443592]
第 3个文档的前10个主题:
[0.00025585885, 0.000102130005, 0.00010215806, 0.0001021321, 0.000102130005, 0.000102141545, 0.00010213848, 0.005841021, 0.86980826, 0.12348203]
第 4个文档的前10个主题:
[0.0006572597, 0.0006570946, 0.00065728865, 0.00065710756, 0.0006570946, 0.0006571689, 0.0006571418, 0.00065724866, 0.0006572691, 0.9940853]
第 5个文档的前10个主题:
[0.09089063, 5.748639e-05, 0.42282772, 5.748767e-05, 5.748639e-05, 5.7492874e-05, 5.749149e-05, 0.14581433, 0.03272865, 0.30745125]
第 6个文档的前10个主题:
[0.01268742, 4.7202997e-05, 0.2854256, 4.7204012e-05, 4.7202997e-05, 4.720842e-05, 4.720712e-05, 0.36365467, 0.04033447, 0.29766187]
第 7个文档的前10个主题:
[0.004294038, 6.870105e-05, 0.08180204, 6.8702626e-05, 6.870105e-05, 6.87093e-05, 6.870766e-05, 0.7040278, 6.871957e-05, 0.2094639]
第 8个文档的前10个主题:
[0.6133319, 0.0004353154, 0.23381416, 0.00043532476, 0.0004353154, 0.0004353643, 0.0004353534, 0.0004354392, 0.0004440389, 0.14979775]
第 9个文档的前10个主题:
[0.00048655766, 0.00048641532, 0.40117988, 0.00048642544, 0.00048641532, 0.0004864658, 0.00048645603, 0.521131, 0.00048655254, 0.07428386]
第 10个文档的前10个主题:
[0.017286241, 6.7313216e-05, 0.031750664, 6.7314664e-05, 6.7313216e-05, 6.732086e-05, 6.7319226e-05, 0.45735896, 0.012209379, 0.48105815]
第 11个文档的前10个主题:
[0.00032338154, 0.0003232927, 0.7388656, 0.00032329932, 0.0003232927, 0.00032332516, 0.00032331893, 0.074141674, 0.00032338157, 0.18472938]



![[管理与领导-101]:IT人对高情商的误解?什么是高情商?](https://img-blog.csdnimg.cn/f3ac280765174a1d8481a74fd0a1db40.png)