文章目录
- 资源链接
- 复现开始
- 环境安装
- 创建 conda 虚拟环境,python 3.6 版本
- 安装程序运行环境
- 1. mkdoc 相关的环境
- 2. 程序运行需要的环境
- 流程参考
- 数据集创建
- 分类任务
- 1. 加载原数据集 VOC2007
- 2. 将所有类数据单独提取
- 3. 对于每个 class 的数据,构造正负例样本(为 finetune 准备)
- 4. 进行 Finetune (利用第 3 步生成的数据)
- 构造 FinetuneDataset
- Finetune 训练
- 5. 训练 Classifier
- 构造 ClassifierDataset
- Classifier 训练
- 好久没做视觉任务了,最近准备把古老的 RCNN, Fast-RCNN, Faster RCNN, Mask RCNN 利用空闲时间复现一遍,刚好网上这些内容比较少
资源链接
- github
- 参考讲解视频
- 原论文: Rich feature hierarchies for accurate object detection and semantic segmentation
Tech report (v5)
复现开始
环境安装
创建 conda 虚拟环境,python 3.6 版本
conda create -n rcnn python=3.6
conda activate rcnn
安装程序运行环境
1. mkdoc 相关的环境
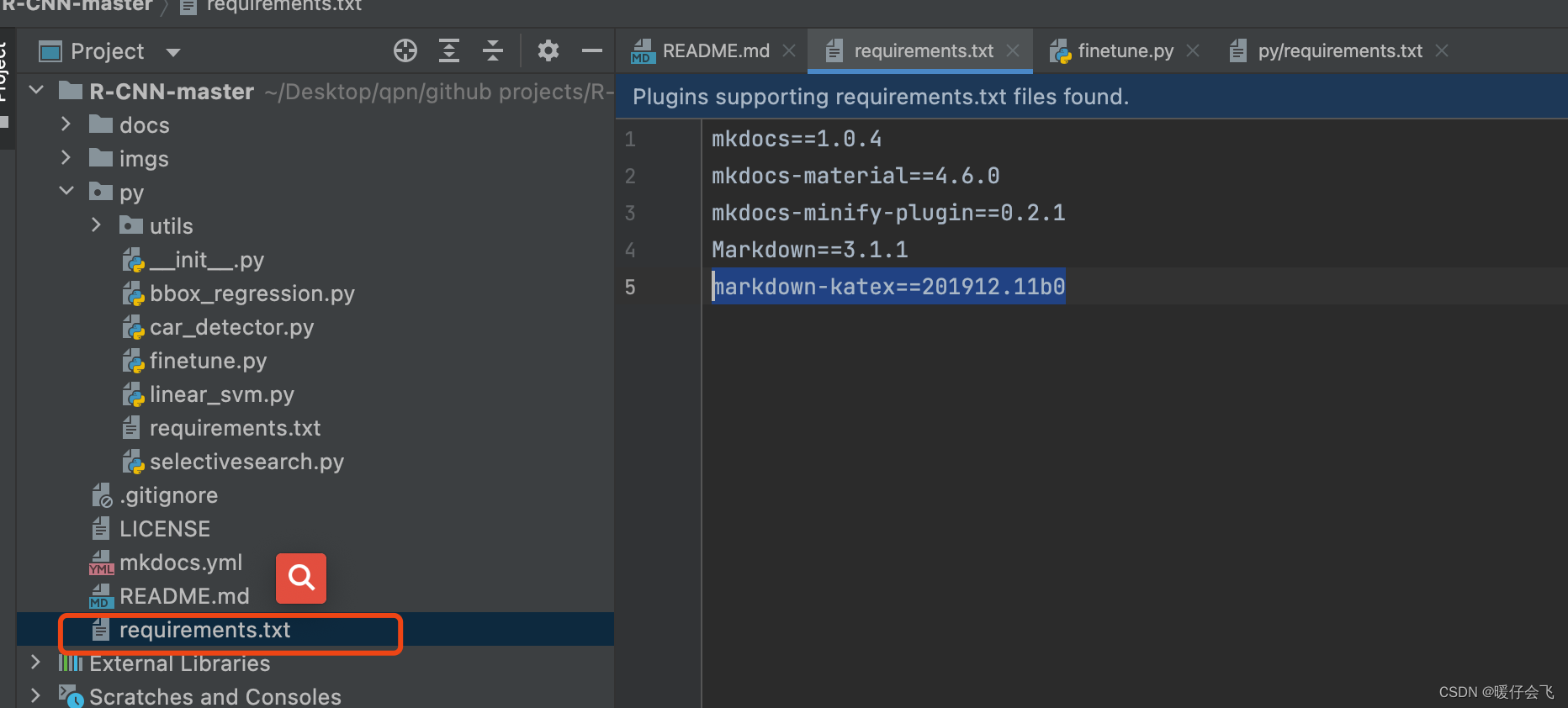
pip install -r requirements.txt
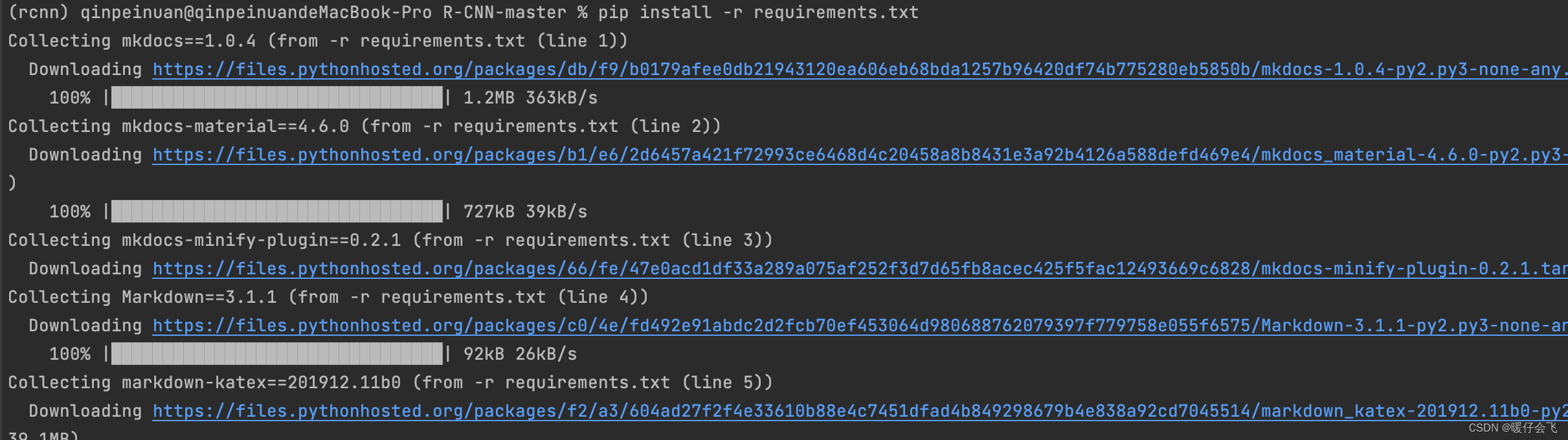
mkdoc安装的只是一个浏览网页功能,与本代码复现无关
2. 程序运行需要的环境
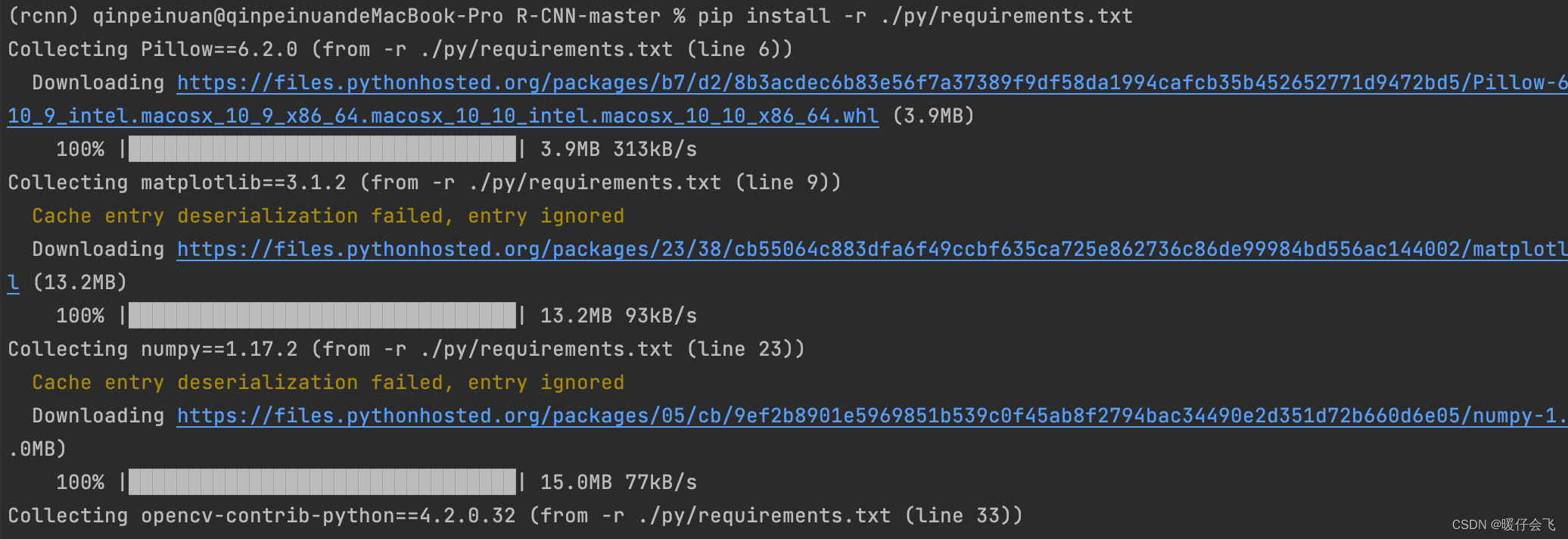
- 首先,他的 ./py/requirements.txt 中的环境是运行时候需要的 package,但是他这个文件中的包很多是有问题的,他应该是批量导出环境的时候出的错误,按照我下面的这种方式重新覆盖一下 ./py/requirements.txt 这个文件即可:
- 注意,这里的 opencv 一定要是
opencv-contrib-python如果直接安装opencv-python那么其中的cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()函数无法使用!!! - opencv 出问题可以参考
Pillow == 6.2.0
matplotlib == 3.1.2
numpy == 1.17.2
opencv-contrib-python
selectivesearch == 0.4
torch == 1.4.0
torchvision == 0.5.0
xmltodict == 0.12.0
tqdm
pip install -r ./py/requirements.txt
流程参考
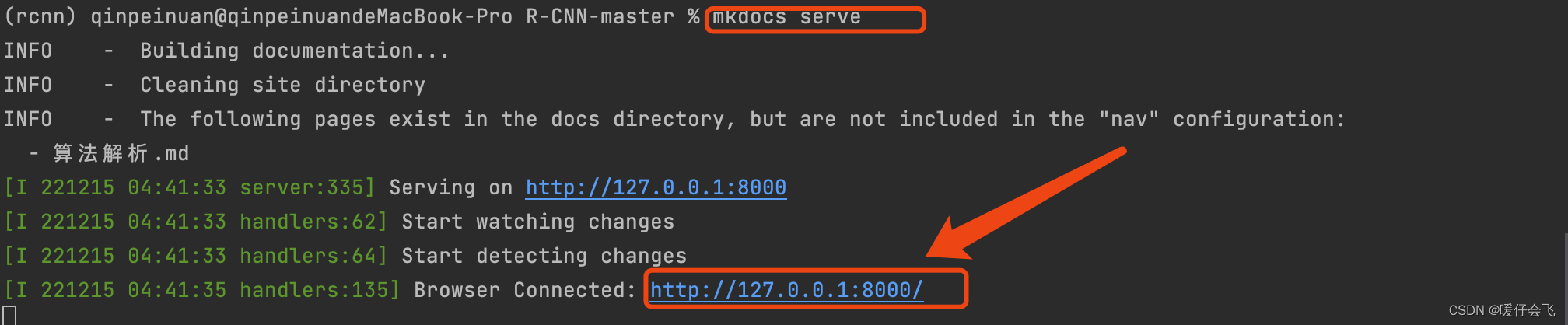
- 这个
github中通过mkdocs已经给我们提供了非常详细的工程实现步骤和教程,只需要在终端中输入mkdocs serve即可通过 8000 端口来访问这个参考手册
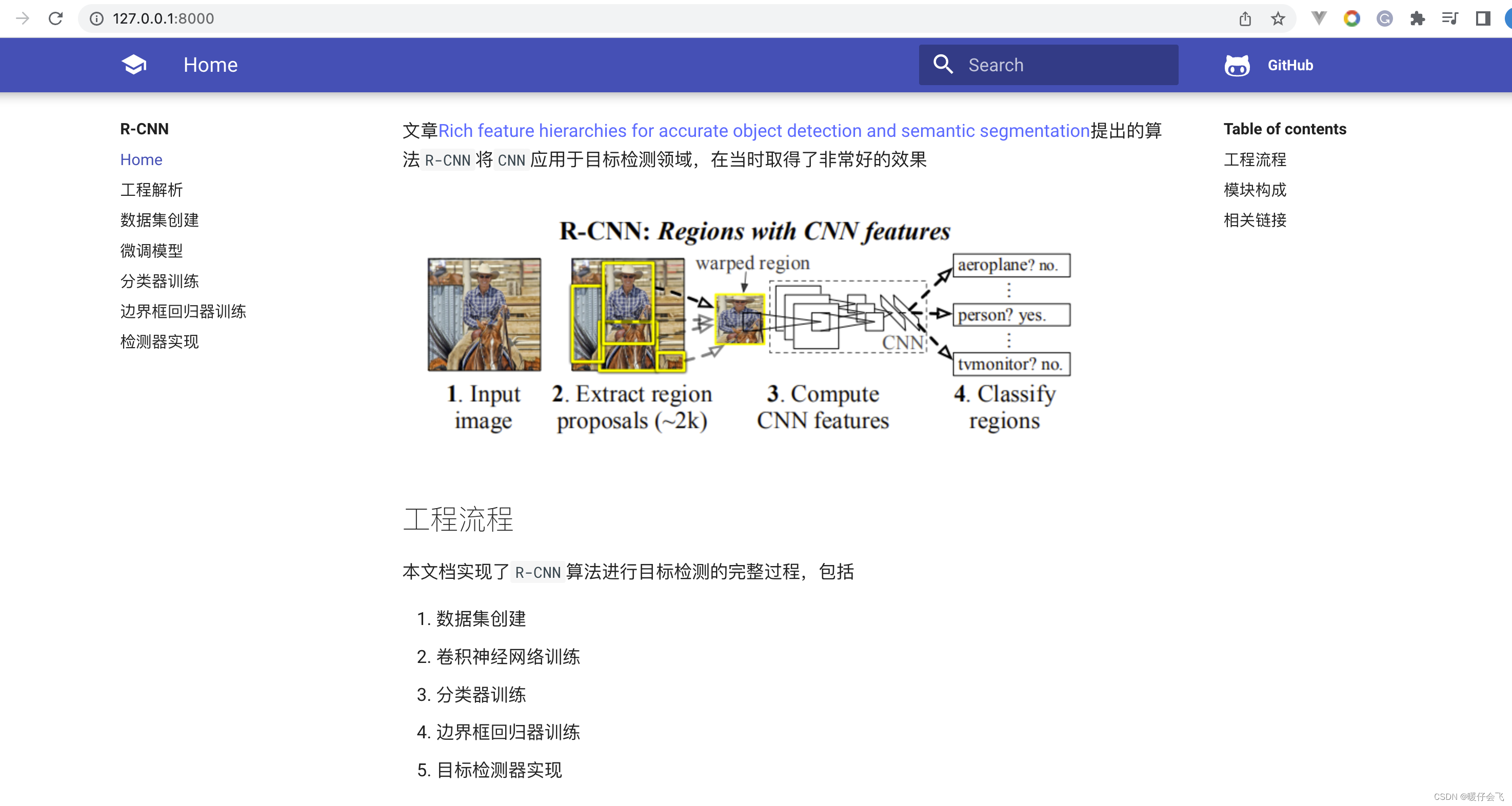
- 好,下面我们正式开始代码复现和讲解的过程
- 首先是关注一下文件目录:
├── docs # 说明文档
├── imgs # 测试图像
├── LICENSE
├── mkdocs.yml # 有关参考手册的内容,不管
├── py # 工程项目文件夹
│ ├── bbox_regression.py # 边界框回归器训练
│ ├── car_detector.py # 检测器实现
│ ├── finetune.py # 卷积神经网络微调训练
│ ├── __init__.py
│ ├── linear_svm.py # 分类器训练
│ ├── requirements.txt # python工程依赖
│ ├── selectivesearch.py # 选择性搜索算法实现
│ └── utils
│ ├── data # 创建数据/自定义数据处理类
│ └── util.py # 辅助函数
├── README.md
└── requirements.txt
数据集创建
- 在创建数据集之前我们需要先弄清楚,RCNN 是做什么的。
- RCNN 是一个目标检测
object detection任务。简而言之就是:给计算机一幅图片,计算机能够把其中的object(目标)给框出来,并能够识别他的类别 - 所以就注定了完成目标检测任务的模型需要实现 两个任务:
-
- 框定出目标物体在图片中的位置(回归任务)
-
- 识别出目标物体的类别(分类任务)
-
分类任务
- 让我们从简单的分类任务入手
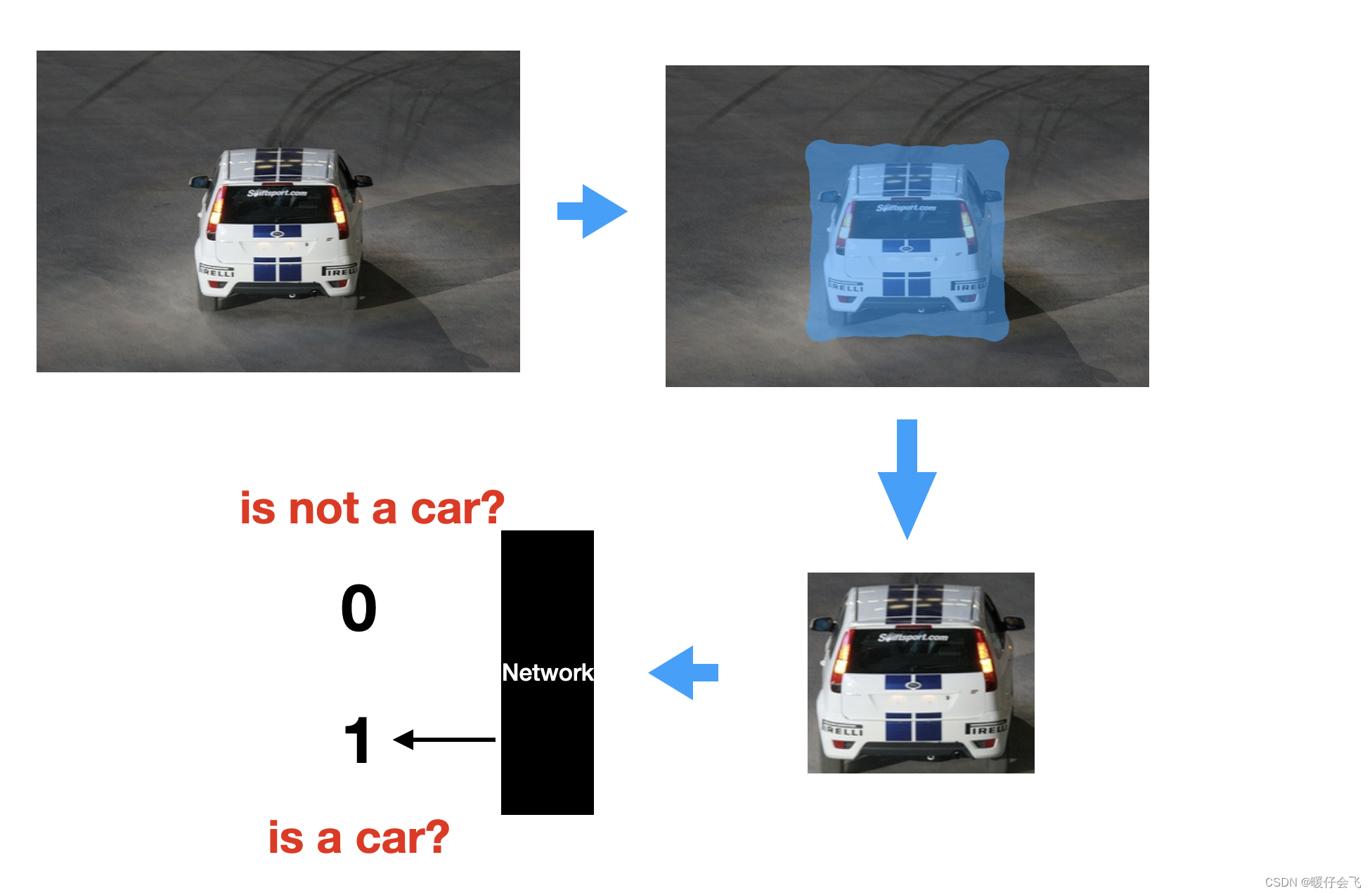
- 为了实现分类任务,我们需要给每个
object一个标签(VOC 2007 中一共有 20 个不同类别的物体),再次强调,是给每个object一个类别标签,而不是给每个image,因为一张图中可能包含多个的object。再深入思考一下,如果我们试图给每个object分类别打标签,我们就得首先从一个image中把想要分类的object给截取出来。 - 也就是说我们在 object 分类这个任务中传给神经网络的
input是一个从image中截取出来的袖珍image
1. 加载原数据集 VOC2007
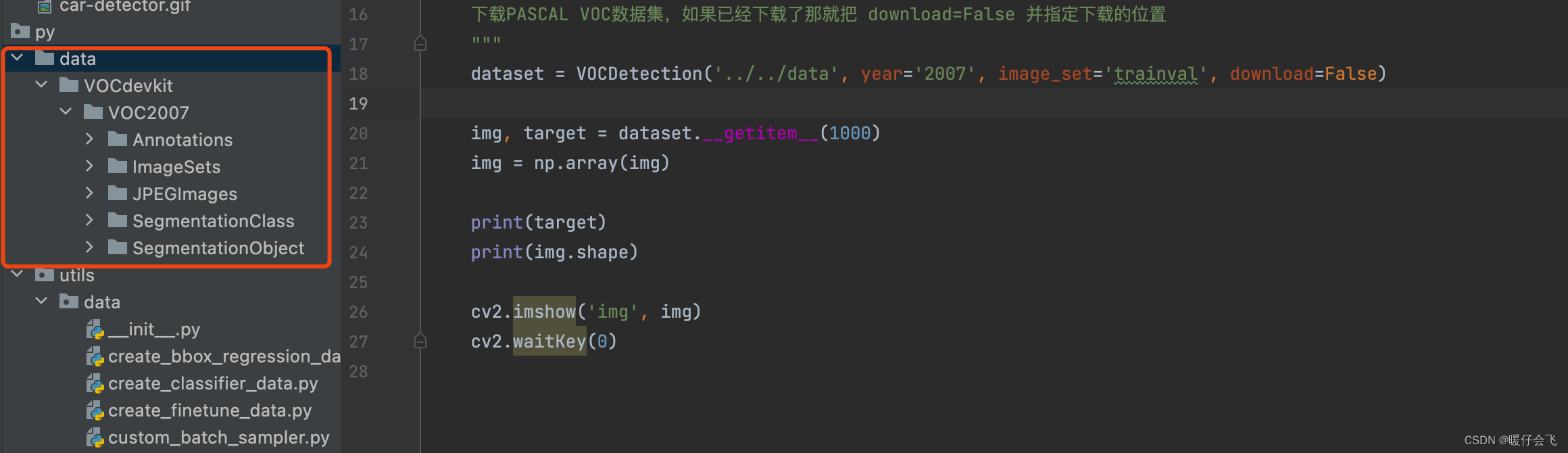
- 源代码中的
pascal_voc.py文件实现了这个功能 - 如果是自己解压到这个文件夹,那么一定要是下面这种文件层级,因为在
VOCDetection这个类初始化的时候,他会把VOCdevkit/VOC2007看做一个整体
2. 将所有类数据单独提取
-
作者在
pascal_voc_car.py文件中实现的这个步骤 -
但我个人更喜欢把数据和函数封装成模块,所以我重写了这个部分的代码
-
我按照自己的习惯更高程度的封装了:
- 构建了一个
SingleClassDataExtractor为每个class保存数据 - 然后批量化保存即可
""" @Time : 2022/12/15 @Author : Peinuan qin """ import os.path import shutil from pprint import pprint import numpy as np from tqdm import tqdm from configs.config_data import ini_config class SingleClassDataExtractor: """ 构建这个代码的目的是为每个类提供一个 extractor,以便构造这个类所有的单独数据文件夹 每个类的单独数据文件夹中的结构应该包括: voc_car: train: Annotations JPEGImages val: Annotations JPEGImages trainval: Annotations JPEGImages """ def __init__(self, cls_name): self.cls_name = cls_name self.args = ini_config() self.main_root = self.args.main_root_path self.train_path, self.val_path, self.trainval_path = self.get_cls_related_paths() self.img_root = self.args.img_root_path self.anno_root = self.args.anno_root_path # 保存这个单独的类的所有数据的根路径,就是找到 main_root 然后网上倒 4 层路径,以 voc_[clsname] 作为文件名称 # 本文中就是与 VOCdevkit 同一级路径,这个当然是按照个人喜好来的 self.save_root_path = os.path.join(self.main_root, "../../../../", f"voc_{cls_name}/") # 如果 save_path 不存在就创建一个 self.check_dir_and_create(self.save_root_path) self.display_info() def get_cls_related_paths(self): """ 返回所有与这个 cls 相关的路径 return the related paths given the class name for example: cls_name = 'car' return car_train.txt, car_val.txt, car_trainval.txt path :return: """ cls_train_path = os.path.join(self.main_root, f"{self.cls_name}_train.txt") cls_val_path = os.path.join(self.main_root, f"{self.cls_name}_val.txt") cls_trainval_path = os.path.join(self.main_root, f"{self.cls_name}_trainval.txt") return cls_train_path, cls_val_path, cls_trainval_path def get_data_from_path(self, path): """ 给定一个 datapth,从其中获取数据,例如给定 ..../car_train.txt 000056 -1 000058 1 那么我们就将 000058 这个 sample 放到 samples 里面 :param path: :return: """ samples = [] with open(path, 'r') as file: lines = file.readlines() for line in lines: res = line.strip().split() if len(res) == 2 and int(res[1]) == 1: samples.append(res[0]) return np.array(samples) def get_data_from_related_paths(self): """ 对应 train, val, trianval 三种不同的路径返回一个字典, 字典中的 key 是 type=[train, val, trainval] value是这种类型对应的所有 samples 的文件名称数组 :return: """ type_samples_dict = {} related_paths = [self.train_path, self.val_path, self.trainval_path] for path in related_paths: # path_type 就是 train / val / trainval,从 path 的信息中提取出来 path_type = path.split("_")[-1].split(".")[0] samples = self.get_data_from_path(path) # {train: samples} / {val: samples} temp_dict = {path_type: samples} # {trian: samples, val:samples, trainval:samples} type_samples_dict.update(temp_dict) return type_samples_dict def check_dir_and_create(self, path): """ 检查路径是否存在,不存在就创建 :param path: :return: """ if not os.path.exists(path): os.makedirs(path) def save_all_cls_materials(self, type_sample_dict): """ 将所有的与当前类有关的信息保存到一个 voc_classname [voc_car]文件夹中 ,分别从 main, JPEGImages, Annotations 提取出对应的数据 :return: """ # 区分 train, val, trainval 分别存入三个不同的文件夹 for usage_type, samples in type_sample_dict.items(): print(f"copying {usage_type} data...") for sample in tqdm(samples): paths_dict = self.make_src_and_dest_paths(usage_type, sample) shutil.copy(paths_dict["src_anno_path"], paths_dict["dest_anno_path"]) shutil.copy(paths_dict["src_img_path"], paths_dict["dest_img_path"]) # 保存 class_name.csv 文件, train, val, trainval 中各有一个 csv 文件,记录这些编号 csv_path = os.path.join(self.save_root_path, usage_type, f"{self.cls_name}.csv") np.savetxt(csv_path, samples, fmt='%s') print(f"saved csv file to {csv_path}") def make_src_and_dest_paths(self, usage_type, sample_name): """ :param type: [train, val, trainval] :param sample_name: :return: """ anno_suffix = ".xml" img_suffix = ".jpg" """ |save_root |train |Annotations |JPEGImages |val |Annotations |JPEGImages |trainval |Annotations |JPEGImages """ # 检查两个目标文件夹是否存在,不存在的话就创建 dest_anno_path = os.path.join(self.save_root_path, usage_type, "Annotations") self.check_dir_and_create(dest_anno_path) dest_img_path = os.path.join(self.save_root_path, usage_type, "JPEGImages") self.check_dir_and_create(dest_img_path) src_dest_path_dict = { "src_anno_path": os.path.join(self.anno_root, f"{sample_name}{anno_suffix}") # 就是在 save_root 路径下面区分 train 还是 val,并在 train / val 创建一个 Annotation 路径来存放所有提取出来当前类的标签文件 , "src_img_path": os.path.join(self.img_root, f"{sample_name}{img_suffix}") # 就是在 save_root 路径下面区分 train 还是 val,并在 train / val 创建一个 JPEGImages 路径来存放所有提取出来当前类的标签文件 , "dest_anno_path": os.path.join(dest_anno_path, f"{sample_name}{anno_suffix}") , "dest_img_path": os.path.join(dest_img_path, f"{sample_name}{img_suffix}") } return src_dest_path_dict def display_info(self): pprint(self.__dict__) if __name__ == '__main__': """ 调用方法: scde = SingleClassDataExtractor("car") type_sample_dict = scde.get_data_from_related_paths() scde.save_all_cls_materials(type_sample_dict) """""" Filename: make_single_data @Time : 2022/12/15 @Author : Peinuan qin """ import os from SingleClassDataExtractor import SingleClassDataExtractor from configs.config_data import ini_config def build_single_class_data(class_name): print(f"start building {class_name}\n") extractor = SingleClassDataExtractor(class_name) type_sample_dict = extractor.get_data_from_related_paths() extractor.save_all_cls_materials(type_sample_dict) def build_all_classes_data(): args = ini_config() # 从 main_path 文件夹中可以得到所有的类名称 main_path = args.main_root_path def right_files(string): """ 只用那些正确的文件名称来提取 class_name,例如 sofa_train.txt 我们能提取出 sofa 但是对于那些 train.txt, val.txt, trainval.txt 不包含类别信息,所以不用这些数据 :param string: :return: """ if len(string.split("_")) == 2: return True else: return False # 只保留 Main 这个文件夹中的有类别意义的文件 filenames = [filename for filename in os.listdir(main_path) if right_files(filename)] cls_names = [] for filename in filenames: cls_name = filename.split("_")[0] if cls_name not in cls_names: cls_names.append(cls_name) # 为了可读性,没有写在循环里,对每个类执行数据集构建操作 for cls_name in cls_names: build_single_class_data(cls_name) print(f"classes names are: {cls_names}\n total_categories = {len(cls_names)}") print("done") if __name__ == '__main__': build_all_classes_data() - 构建了一个
-
config文件如下""" Filename: config.py @Time : 2022/12/15 @Author : Peinuan qin """ import argparse def ini_config(): parser = argparse.ArgumentParser() parser.add_argument("--main_root_path", default="/Users/qinpeinuan/Desktop/qpn/github projects/R-CNN-master/py/data/VOCdevkit/VOC2007/ImageSets/Main") parser.add_argument("--img_root_path", default="/Users/qinpeinuan/Desktop/qpn/github projects/R-CNN-master/py/data/VOCdevkit/VOC2007/JPEGImages") parser.add_argument("--anno_root_path", default="/Users/qinpeinuan/Desktop/qpn/github projects/R-CNN-master/py/data/VOCdevkit/VOC2007/Annotations") args = parser.parse_args() return args
-
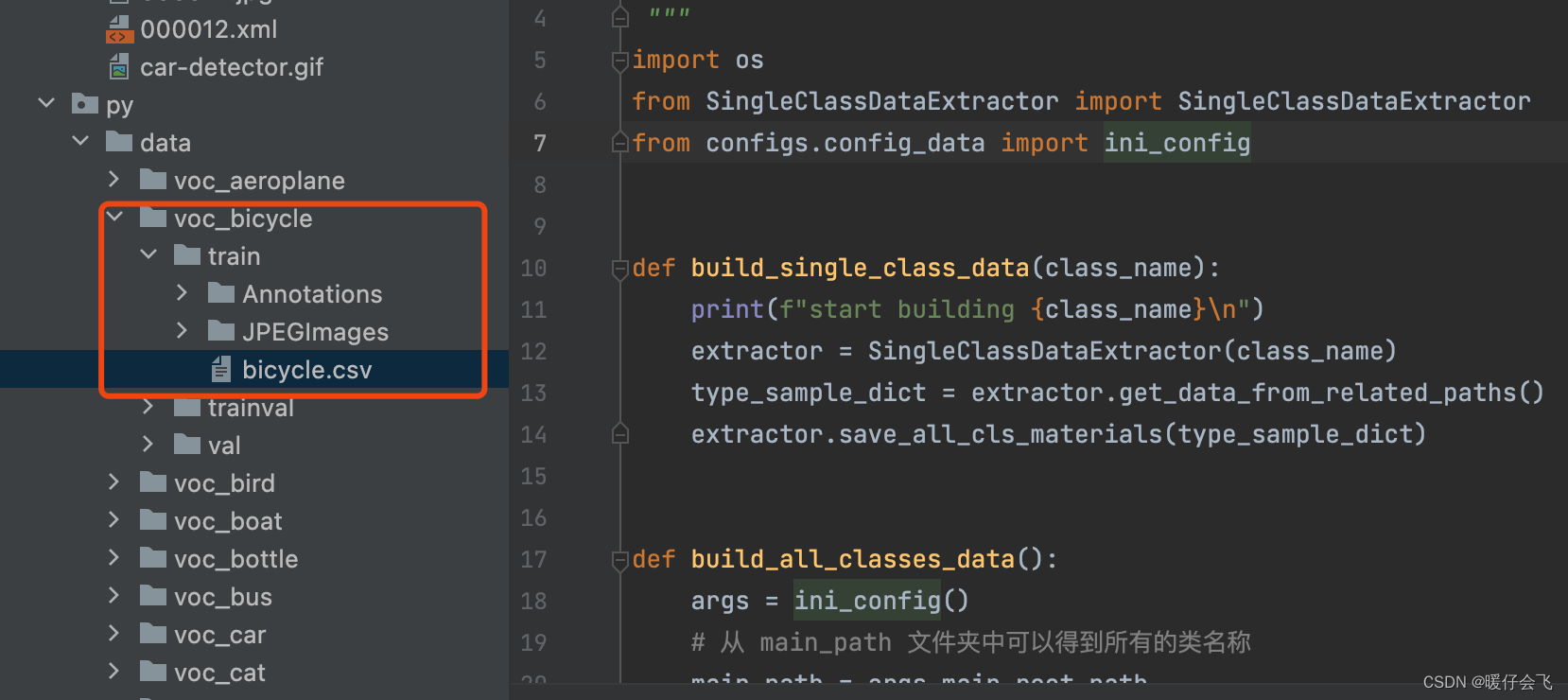
红框框出的部分是我重写的部分
-
这一步的目的是构造 所有类单独的数据文件夹,现在已经构造完成
3. 对于每个 class 的数据,构造正负例样本(为 finetune 准备)
-
对于任何一个 class,例如
car,都需要训练一个二分类器。也就是把car看成是正例,把其他的东西看成是反例。 -
而这一步构造正负样本的步骤如下:
- 在一张 image 上产生
N个矩形框,这些矩形框的大小、形态各异;假设当前的image上有M个object是有bounding box标注的,那么需要将N个矩形框与M个bounding box进行IOU计算
看个具体的例子:
- 假设现在轮到第
i个矩形框与这M个bounding box进行IOU计算,经过计算后,这个矩形框和第j个bounding box的IOU值是最大的,为v=0.7那么由于0.7是这个矩形框在这一批(M个)bounding box中能匹配到最重合的情况,所以0.7就可以作为一个标准去判断当前这个矩形框框出的图像内容是属于正例还是负例

- 把图中的
红框当做是image本身的bounding box标注,而蓝色框则是通过生成的候选区域得到的N个矩形框其中的第i个。可以看到这个蓝色框与左下方的bounding box的IOU是最大的,因此我们用这个IOU来作为判断蓝色框框出的内容是正例还是反例。 - 假设这个
IOU的值是0.6,那么这个值超过0.5所以这个蓝色框框出的内容被认为是一个正例

- 在一张 image 上产生
-
也就是说我下面这张图的标签有资格给成
car,我们也看到这里面确实包含了一部分汽车的像素。

-
但如果一个矩形框是绿色框体的情况:很显然他与图中任意一个
bounding box的IOU都不可能超过0.5因此他很有可能成为一个反例(但要被判断成反例其实需要两个条件,具体细节可以看代码,我把注释都写的很清楚)


-
这个步骤的代码,作者在
create_finetune_data.py里面构造的 -
我还是重写了这部分代码
""" Filename: FinetuneDataMaker.py @Time : 2022/12/15 @Author : Peinuan qin """ import sys import shutil import numpy as np import cv2 import os import xmltodict from tqdm import tqdm from configs.config_finetune_data_maker import ini_config class FinetuneDataMaker: """ 构造 finetune 的数据集 """ def __init__(self, cls_name, usage_type="train"): self.cls_name = cls_name self.usage_type = usage_type self.args = ini_config() """ root: voc_car: (class root) train Annotations JPEGImages val Annotations JPEGImages trainval Annotations JPEGImages voc_train ... """ self.root = self.args.root self.cls_root = os.path.join(self.root, f"voc_{cls_name}") self.cls_anno = os.path.join(self.cls_root, self.usage_type, "Annotations") self.cls_img = os.path.join(self.cls_root, self.usage_type, "JPEGImages") self.finetune_root = os.path.join(self.root, f"finetune_{cls_name}") self.finetune_anno = os.path.join(self.finetune_root, self.usage_type, "Annotations") self.finetune_img = os.path.join(self.finetune_root, self.usage_type, "JPEGImages") self.total_positive_num = 0 self.total_negative_num = 0 # 检查并尝试创建这些路径来存放 finetune 的数据集 self.check_dir_and_create(self.finetune_root) self.check_dir_and_create(self.finetune_anno) self.check_dir_and_create(self.finetune_img) self.samples = self.get_samples_from_csv() self.gs = self.get_selective_search() def display_info(self): print(self.__dict__) def get_samples_from_csv(self): csv_path = os.path.join(self.cls_root, self.usage_type, f"{self.cls_name}.csv") samples = np.loadtxt(csv_path, dtype=np.str) return samples def check_dir_and_create(self, path): """ 检查路径是否存在,不存在就创建 :param path: :return: """ if not os.path.exists(path): os.makedirs(path) def gs_config(self, img): """ :param img: :return: """ gs = self.gs strategy = self.args.gs_strategy gs.setBaseImage(img) if (strategy == 's'): gs.switchToSingleStrategy() elif (strategy == 'f'): gs.switchToSelectiveSearchFast() elif (strategy == 'q'): gs.switchToSelectiveSearchQuality() else: print(__doc__) sys.exit(1) def get_selective_search(self): """ 生成推荐区域 :return: """ gs = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation() return gs def get_rects(self): """ :return: """ rects = self.gs.process() rects[:, 2] += rects[:, 0] rects[:, 3] += rects[:, 1] return rects def parse_xml(self, xml_filepath): """ 根据一个 xml_file 得到这个 image 中包含的所有 bounding box 信息 :param xml_filepath: :return: """ with open(xml_filepath, "rb") as f: xml_dict = xmltodict.parse(f) # 一个 xml 文件对应一个 image,其中可能有多个 object,从而有多个 boundingbox bounding_boxes = [] objects = xml_dict['annotation']['object'] def tackle_objects(obj): """ 对每个 object 如下操作 :param obj: :return: """ # obj 的名称 obj_name = obj['name'] difficult = int(obj['difficult']) # 如果当前这个 object 和我们的 self.cls_name 是同一类 image 的话,那么这个数据的 bounding box 信息就要收集起来 # 忽略那些困难的样本 if self.cls_name.__eq__(obj_name) and difficult != 1: bounding_box = obj['bndbox'] # 一个位置元组包含了 bounding box 中四个边角的位置信息 position_tuple = ( int(bounding_box['xmin']), int(bounding_box['ymin']), int(bounding_box['xmax']), int(bounding_box['ymax'])) # bounding box 中现在收集了所有的 cls_name 这个类的图片的 bounding box 的位置信息 bounding_boxes.append(position_tuple) # 如果 object 的数量多于一个,那么 objects 就会是个列表 if isinstance(objects, list): # 遍历所有的 object for obj in objects: tackle_objects(obj) # 如果这个 image 中 object 的数量只有一个,那么他的他本身就是一个字典对象 if isinstance(objects, dict): tackle_objects(objects) # 返回当前 image 所有的 bounding box 的信息,是个数组,数组中的每个元素包含 4 个值 return np.array(bounding_boxes) def parse_img(self, xml_filepath, img_path): """ 给定一张图片及其标注信息,返回两个列表,一个正样本列表一个负样本列表 正样本列表中存放的是这个图片中所有的可以看做正样本的 rec 的信息 负样本列表中存放的是这个图片中所有的可以看作负样本的 rec 的信息 :param xml_filepath: :param img_path: :return: """ img = cv2.imread(img_path) # 按照何种方式生成待选区域 self.gs_config(img) # 对于这张图的生成 N 个矩形的候选区域 rects = self.get_rects() # 得到这个 image 所有的 object 的框位置信息 bounding_boxes = self.parse_xml(xml_filepath) # 选出区域最大的标定框 def bounding_box_area(box_tuple): """ 如果 box_tuple 只包含一组值,xmin, ymin, xmax, ymax, 那么就返回一个面积 如果 box_tuple 是个多维数组,那么就返回一堆面积 :param box_tuple: :return: """ if len(box_tuple.shape) == 1: xmin, ymin, xmax, ymax = box_tuple area = (ymax - ymin) * (xmax - xmin) return area else: areas = (box_tuple[:, 2] - box_tuple[:, 0]) * (box_tuple[:, 3] - box_tuple[:, 1]) return areas # 得到这张图上面积最大的当前类的 object 对应的边界框 max_bounding_box_area = max([bounding_box_area(box_tuple) for box_tuple in bounding_boxes]) # 将当前 image 所有的候选区域(2000)和所有的 object 边界框(N个) 同时进行 iou 计算 def get_iou_scores(rec_box, bounding_boxes): """ 拿一个 候选的 rec 矩形与 image 中的 N 个 object 的 bounding box 计算 IOU 这个部分的运算涉及到 numpy 的广播机制,不明白的可以去看一下 rec_box : (4,) bounding_boxes : (N, 4) :param rec_box: 给定一个候选的区域 :param bounding_boxes: 一个 img 中的所有当前类的 bounding box 信息 :return: """ # 如果这个 object 中的 bounding box 个数只有一个,也就是 bounding boxes 这个数组是个一维数组 if len(bounding_boxes.shape) == 1: # 那么就把他扩展成 2 维度来兼容 一张图片中有多个 bounding box 的情况 bounding_boxes = bounding_boxes[np.newaxis, :] # 扩展维度变成两维 # XA, XB, XC, XD 都是 rec 中的 xa, xb, xc, xd 分别和 image 中的 N 个 bounding box 一起比较,选出最大的参数 # XA 是个数组, image 中有几个 bounding box XA 中的值就有几个,即:rec 的 Xa 与 N 个 bounding box 逐个比较得到较大的 XA xA = np.maximum(rec_box[0], bounding_boxes[:, 0]) # (N, ) yA = np.maximum(rec_box[1], bounding_boxes[:, 1]) # (N, ) xB = np.minimum(rec_box[2], bounding_boxes[:, 2]) # (N, ) yB = np.minimum(rec_box[3], bounding_boxes[:, 3]) # (N, ) # 计算 rec 与每个 bounding box 的 intersection area,并保证结果 > 0 intersection_area = np.maximum(0.0, xB - xA) * np.maximum(0.0, yB - yA) # 计算 rec 与每个 bounding box 的 union area (并集面积) # rec 自己的面积 rec_box_area = bounding_box_area(rec) # (1, ) # N 个 bounding box 的面积组成的数组 bounding_box_areas = bounding_box_area(bounding_boxes) # (N, ) union_areas = rec_box_area + bounding_box_areas - intersection_area # (N, ) # 计算交并比 scores = intersection_area / union_areas # (N, ) return scores # 对 M 个 recs 都分别与一个 img 中的 N 个 object bounding boxes 进行 iou 计算 max_iou_lst = [] for rec in rects: # 每个 rec 都会与所有的 bounding box 算一个交并比,但是我们只要最大的那个值作为后面判断正负样本的标准 iou_scores = get_iou_scores(rec, bounding_boxes) # 对于当前 rec 来说, max_iou 就是 rec 在当前这张图中能够获得的最大交并比 max_iou = max(iou_scores) max_iou_lst.append(max_iou) # 现在根据这些最大交并比我们需要把数据分成正例(positive samples)和负例(negative samples) # 这两个列表中最终存放的还是 多个 tuple,每个 tuple 代表了一个框,通俗地说,这里的正负样本指的是从那些生成的 rec 中筛选 positive_sample_lst = [] negative_sample_lst = [] # rec_maxiou_tuples 中的每个 tuple 都有 rec 及其最大的 iou 值组成 rec_maxiou_tuples = list(zip(rects, max_iou_lst)) for rec, max_iou in rec_maxiou_tuples: # 如果当前 rec 能够在图中找到任何一个 object 的 bounding box 使得他们之间的 iou >= 0.5 这个 rec 就可以看做是正样本 if max_iou >= 0.5: positive_sample_lst.append(rec) # 如果不能找到一个 object 的 bounding box 使得 rec 与之的 iou 超过 0.5 # 并且 rec 的面积必须要超过 最大 bounding box 面积的 1/5,因为如果这个 rec 的面积太小了可能数量会非常庞大,当然这个值并不是固定的 # 可以根据自己的喜好来调整负样本的生成过程 rec_area = bounding_box_area(rec) if 0 < max_iou < 0.5 and rec_area > max_bounding_box_area / 5.0: negative_sample_lst.append(rec) return positive_sample_lst, negative_sample_lst def parse_all_imgs(self): # complete_positive_sample_lst = [] # complete_negative_sample_lst = [] print("making imgs and split positive & negative samples") for sample in tqdm(self.samples): img_path = os.path.join(self.cls_img, sample + self.args.img_suffix) anno_path = os.path.join(self.cls_anno, sample + self.args.anno_suffix) # 用 np.savetxt 是追加而非覆盖模式 positive_sample_list, negative_sample_list = self.parse_img(anno_path, img_path) self.total_positive_num += len(positive_sample_list) self.total_negative_num += len(negative_sample_list) dst_img_path = os.path.join(self.finetune_img, sample + self.args.img_suffix) dst_anno_positive_csv_path = os.path.join(self.finetune_anno, f"{sample}_1.csv") dst_anno_negative_csv_path = os.path.join(self.finetune_anno, f"{sample}_0.csv") # 图片原封不动复制 shutil.copy(img_path, dst_img_path) # 正负 rec 的样本区分保存 np.savetxt(dst_anno_positive_csv_path, np.array(positive_sample_list), fmt='%d', delimiter=' ') np.savetxt(dst_anno_negative_csv_path, np.array(negative_sample_list), fmt='%d', delimiter=' ') print("done") print('%s positive num: %d' % (self.cls_name, self.total_positive_num)) print('%s negative num: %d' % (self.cls_name, self.total_negative_num))""" Filename: config_finetune_data_maker.py @Time : 2022/12/15 @Author : Peinuan qin """ import argparse def ini_config(): parser = argparse.ArgumentParser() parser.add_argument("--root", default="/Users/qinpeinuan/Desktop/qpn/github projects/R-CNN-master/py/data/", help="所有class的上一级目录,也就是 ./data") # 只是为了从这个路径中获得各个类别的名称才加的这个 main root path 字段 parser.add_argument("--main_root_path", default="/Users/qinpeinuan/Desktop/qpn/github projects/R-CNN-master/py/data/VOCdevkit/VOC2007/ImageSets/Main", help="所有class的上一级目录,也就是 ./data") parser.add_argument("--gs_strategy", default="q", help="选择生成 selective 区域的方式") parser.add_argument("--img_suffix", default=".jpg", help="图片文件的后缀") parser.add_argument("--anno_suffix", default=".xml", help="标注文件的后缀") args = parser.parse_args() return args""" Filename: make_finetune_data.py @Time : 2022/12/15 @Author : Peinuan qin """ import os from FinetuneDataMaker import FinetuneDataMaker from configs.config_finetune_data_maker import ini_config def build_single_class_data(cls_name): """ 对一个 class 的数据,需要构造 train, val, trainval 三个 finetune data maker :param cls_name: :return: """ print(f"start building {cls_name}\n") train_maker = FinetuneDataMaker(cls_name, "train") val_maker = FinetuneDataMaker(cls_name, "val") train_val_maker = FinetuneDataMaker(cls_name, "trainval") train_maker.parse_all_imgs() val_maker.parse_all_imgs() train_val_maker.parse_all_imgs() def build_all_classes_data(): args = ini_config() # 从 main_path 文件夹中可以得到所有的类名称 main_path = args.main_root_path def right_files(string): """ 只用那些正确的文件名称来提取 class_name,例如 sofa_train.txt 我们能提取出 sofa 但是对于那些 train.txt, val.txt, trainval.txt 不包含类别信息,所以不用这些数据 :param string: :return: """ if len(string.split("_")) == 2: return True else: return False # 只保留 Main 这个文件夹中的有类别意义的文件 filenames = [filename for filename in os.listdir(main_path) if right_files(filename)] cls_names = [] for filename in filenames: cls_name = filename.split("_")[0] if cls_name not in cls_names: cls_names.append(cls_name) # 为了可读性,没有写在循环里,对每个类执行数据集构建操作 for cls_name in cls_names: build_single_class_data(cls_name) print(f"classes names are: {cls_names}\n total_categories = {len(cls_names)}") print("done")
4. 进行 Finetune (利用第 3 步生成的数据)
构造 FinetuneDataset
-
利用刚才第三步生成的数据构造
FinetuneDataset""" Filename: FinetuneDataset.py @Time : 2022/12/16 @Author : Peinuan qin """ import numpy as np import os import cv2 import tqdm from torch.utils.data import Dataset from py.utils.my_data.configs.config_finetune_dataset import ini_config class ImageRect: """ 一个 image rect 的对象,给定一个 img 图片和一个 rect 边界框信息 """ def __init__(self, img, rect, label=1): self.img = img self.anno_rect = rect self.label = label self.img_area = self.get_area() def get_area(self): """ 按照 rect 划定的区域在原图上截取出来 :return: """ xmin, ymin, xmax, ymax = self.anno_rect return self.img[ymin:ymax, xmin:xmax] class FinetuneDataset(Dataset): """ 用 FinetuneDataMaker 构造的数据来 build finetune使用的数据集 """ def __init__(self, cls_name, usage_type="train", transform=None): super(FinetuneDataset, self).__init__() self.cls_name = cls_name self.usage_type = usage_type self.args = ini_config() self.root = self.args.root self.finetune_root = os.path.join(self.root, f"finetune_{cls_name}") # /Users/qinpeinuan/Desktop/qpn/github projects/R-CNN-master/py/data/finetune_car/train/Annotations/ self.finetune_anno = os.path.join(self.finetune_root, self.usage_type, "Annotations") # /Users/qinpeinuan/Desktop/qpn/github projects/R-CNN-master/py/data/finetune_car/train/JPEGImages/ self.finetune_img = os.path.join(self.finetune_root, self.usage_type, "JPEGImages") self.transform = transform self.image_anno_dict = self.get_img_rect_dict() self.total_positive_num = self.get_sample_num(label=1) self.total_negative_num = self.get_sample_num(label=0) def get_sample_num(self, label=1): """ 给定一个 label 的种类,返回此类样本的总数量 :param label: :return: """ nums = 0 for obj in self.image_anno_dict.values(): if obj.label == label: nums += 1 return nums def get_img_rect_dict(self): """ 构建 image_anno 的字典,字典中的 index 从 0 开始增大, 字典的每个 value 是一个 ImageRect 对象 :return: """ img_rects = {} img_file_names = os.listdir(self.finetune_img) index = 0 def check_rect(rect): """ 检查现在这个图片的 rects 中有没有不符合规范的存在, 有的话返回 None :param rect: :return: """ try: assert rect.shape[0] == 4 return rect except Exception as e: """ 84 315 155 339 """ print(rect) return None # print(rect.shape) for img_name in tqdm.tqdm(img_file_names): img_path = os.path.join(self.finetune_img, img_name) img = cv2.imread(img_path) filename = img_name.split(".")[0] positive_rect_csv_filepath = os.path.join(self.finetune_anno, filename + "_1.csv") negative_rect_csv_filepath = os.path.join(self.finetune_anno, filename + "_0.csv") positive_rects = np.loadtxt(positive_rect_csv_filepath, dtype=np.int64, delimiter=" ") negative_rects = np.loadtxt(negative_rect_csv_filepath, dtype=np.int64, delimiter=" ") for rec in positive_rects: rect = check_rect(rec) if rect is not None: img_rects[index] = ImageRect(img, rect, label=1) index += 1 for rec in negative_rects: rect = check_rect(rec) if rect is not None: img_rects[index] = ImageRect(img, rect, label=0) index += 1 return img_rects def __getitem__(self, item): """ 因为我们的数据集是按照 rect 来构建的正负样本,所以我们进行索引的时候取得数据还是 某个图片中的 符合 rect index 的一部分区域, 所以当我们拿到一个 rect 的 index,我们需要先定位他原本是属于哪一张具体的 image :param item: :return: """ # 直接从之前构造的 img_rect 的字典中按照 index取出对应的正例或负例样本 img_anno = self.image_anno_dict[item] image = img_anno.img_area label = img_anno.label if self.transform: image = self.transform(image) return image, label def display_info(self): print(self.__dict__) def __len__(self): return self.total_negative_num + self.total_positive_num # if __name__ == '__main__': # dataset = FinetuneDataset("car") # dataset.img_anno()
```python
"""
Filename: config_finetune_dataset.py
@Time : 2022/12/16
@Author : Peinuan qin
"""
import argparse
def ini_config():
parser = argparse.ArgumentParser()
parser.add_argument("--root", default="./data/", help="所有class的上一级目录,也就是 ./data")
# 只是为了从这个路径中获得各个类别的名称才加的这个 main root path 字段
parser.add_argument("--main_root_path", default="./data/VOCdevkit/VOC2007/ImageSets/Main", help="所有class的上一级目录,也就是 ./data")
parser.add_argument("--gs_strategy", default="q", help="选择生成 selective 区域的方式")
parser.add_argument("--img_suffix", default=".jpg", help="图片文件的后缀")
parser.add_argument("--anno_suffix", default=".xml", help="标注文件的后缀")
args = parser.parse_args()
return args
```
Finetune 训练
-
使用
FinetuneDataset来训练模型""" Filename: config_finetune.py @Time : 2022/12/16 @Author : Peinuan qin """ import argparse def ini_config(): parser = argparse.ArgumentParser() parser.add_argument("--positive_sample_batch_size", default=32, help="一个batch中正样本的数量") # 只是为了从这个路径中获得各个类别的名称才加的这个 main root path 字段 parser.add_argument("--negative_sample_batch_size", default=96, help="一个batch中负样本的数量") parser.add_argument("-batch_size", default=128, help="batch_size") parser.add_argument("--num_workers", default=8, help="num_workers") parser.add_argument("--print_step", default=1, help="隔几个 step 打印一次") parser.add_argument("--device", default="2,3,4,6", type=str, help="gpu 设备编号") args = parser.parse_args() return args""" Filename:my_finetune.py @Time : 2022/12/16 @Author : Peinuan qin """ # -*- coding: utf-8 -*- import tqdm import os import copy import time import torch import torch.nn as nn import torch.optim as optim from torch.nn import DataParallel from torch.utils.data import DataLoader import torchvision.transforms as transforms import torchvision.models as models from utils.my_data.FinetuneDataset import FinetuneDataset from utils.my_data.FinetuneSampler import FinetuneSampler from utils.util import check_dir from py.utils.my_data.configs.config_finetune import ini_config args = ini_config() def load_data(cls_name): transform = transforms.Compose([ transforms.ToPILImage(), transforms.Resize((227, 227)), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) data_loaders = {} data_sizes = {} for name in ['train', 'val']: print(f"making {name} data ...") data_set = FinetuneDataset(cls_name, transform=transform) data_sampler = FinetuneSampler(data_set.total_positive_num , data_set.total_negative_num , args.positive_sample_batch_size , args.negative_sample_batch_size ) data_loader = DataLoader(data_set , batch_size=args.batch_size , sampler=data_sampler , num_workers=args.num_workers, drop_last=True) data_loaders[name] = data_loader data_sizes[name] = data_sampler.__len__() print("data is done") return data_loaders, data_sizes def train_model(data_loaders, model, criterion, optimizer, lr_scheduler, num_epochs=25, device=None): since = time.time() best_model_weights = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in tqdm.tqdm(range(num_epochs)): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-' * 10) # Each epoch has a training and validation phase for phase in ['train', 'val']: if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. counter = 0 for inputs, labels in tqdm.tqdm(data_loaders[phase]): inputs = inputs.to(device) labels = labels.to(device) # zero the parameter gradients optimizer.zero_grad() # forward # track history if only in train with torch.set_grad_enabled(phase == 'train'): outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, labels) # backward + optimize only if in training phase if phase == 'train': loss.backward() optimizer.step() step_loss = loss.item() * inputs.size(0) step_corrects_rate = torch.sum(preds == labels.data) / inputs.size(0) if counter % args.print_step == 0: print(f"step_loss = {step_loss}") print(f"step_corrects_rate = {step_corrects_rate}") # statistics running_loss += loss.item() * inputs.size(0) running_corrects += torch.sum(preds == labels.data) counter += 1 if phase == 'train': lr_scheduler.step() epoch_loss = running_loss / data_sizes[phase] epoch_acc = running_corrects.double() / data_sizes[phase] print('{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # deep copy the model if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc best_model_weights = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) # load best model weights model.load_state_dict(best_model_weights) return model def get_parameter_number(model): total_num = sum(p.numel() for p in model.parameters()) trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad) return {'Total': total_num, 'Trainable': trainable_num} if __name__ == '__main__': # os.environ["CUDA_VISIBLE_DEVICES"] = args.device os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5" device = torch.device("cuda" if torch.cuda.is_available() else "cpu") data_loaders, data_sizes = load_data('car') # model = torch.load("../pretrained_model/alexnet-owt-4df8aa71.pth", map_location=device) print("loading pretrained models...") dict = torch.load("../pretrained_model/alexnet-owt-4df8aa71.pth", map_location=device) model = models.alexnet(pretrained=False) model.load_state_dict(dict) # print(model) num_features = model.classifier[6].in_features model.classifier[6] = nn.Linear(num_features, 2) # print(model) model = model.to(device) print(get_parameter_number(model)) if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") model = DataParallel(model , device_ids=[0,1,2] # , device_ids=[int(i) for i in args.device.split(',')] ) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.9) lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1) best_model = train_model(data_loaders, model, criterion, optimizer, lr_scheduler, device=device, num_epochs=25) # 保存最好的模型参数 check_dir('./models') torch.save(best_model.state_dict(), 'models/alexnet_car.pth')