DN-DETR(CVPR 2022)
Accelerate DETR Training by Introducing Query DeNoising
匈牙利匹配不稳定导致了早期训练阶段的优化目标不一致
同一个图像,query在不同时期会对不同对象进行匹配
DN-DETR在真实的GT上添加噪声:xywh,label
使用了去噪技术加速网络训练,将detr训练视为两个过程:
- learning good anchors
- learning relative offsets
模型
DN:denoising
denoising只是一种training方式,不会改变模型结构,只是在输入的时候做了一些改变
把decoder embedding表示为加了noise的label, anchor表示为加了noise的bbox
对于DETR原始的匹配部分,我们可以添加一个 [Unknown] label来进行区分,anchor部分保持DETR的方式不变。
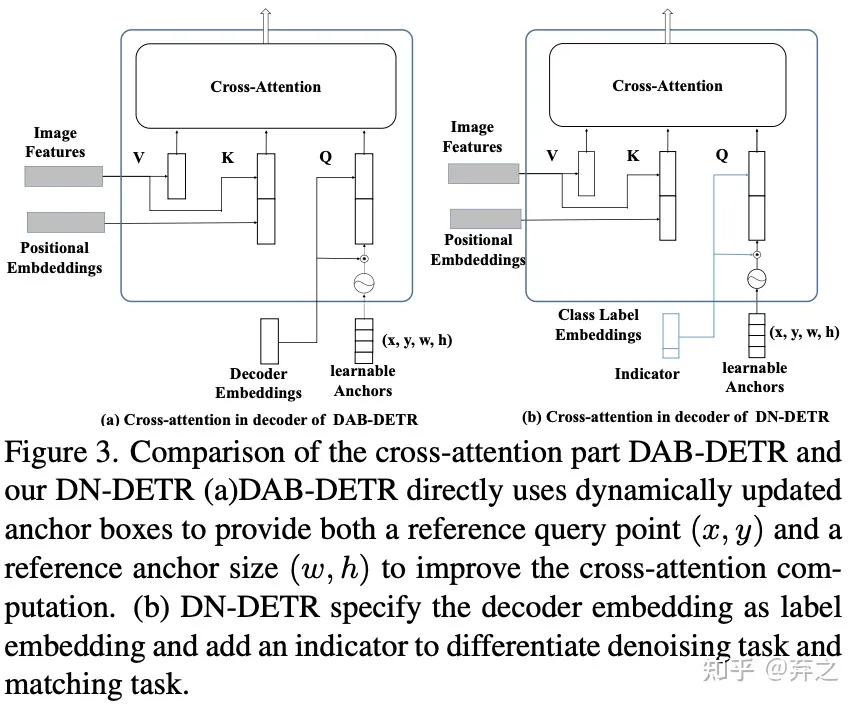
indicator标识embedding是不是原始300quey之中的还是加入的有噪声的GT
learnable anchors:对于正常300query,这里传入的就是embedding参数,如果是去噪GT,就是加上噪声的GT的值。
o
=
(
D
)
(
q
,
F
∣
A
)
(
c
r
o
s
s
−
a
t
t
e
n
t
i
o
n
−
D
A
B
−
D
E
T
R
)
o=(\mathbf{D})(\mathbf{q}, F \mid A)(cross-attention-DAB-DETR )
o=(D)(q,F∣A)(cross−attention−DAB−DETR)
o:decoder output,D:decoder,q:query,F:encoder 输出,A:attention mask
decoder query有两部分。一个是matching part。这一部分的输入是learnable anchors,其处理方式与DETR相同。也就是说,匹配部分采用二分图匹配,并学习近似具有匹配解码器输出的GT box-label对。另一部分是denoising part。这部分的输入是noised GT box-label对,在本文的其余部分中称为GT objects。去噪部分的输出旨在重建GT对象
o
=
D
(
q
,
Q
,
F
∣
A
)
\mathbf{o}=D(\mathbf{q}, \mathbf{Q}, F \mid A)
o=D(q,Q,F∣A)
o:decoder output,D:decoder,q:带有噪声的GT,Q:300query,F:encoder 输出,A:attention mask
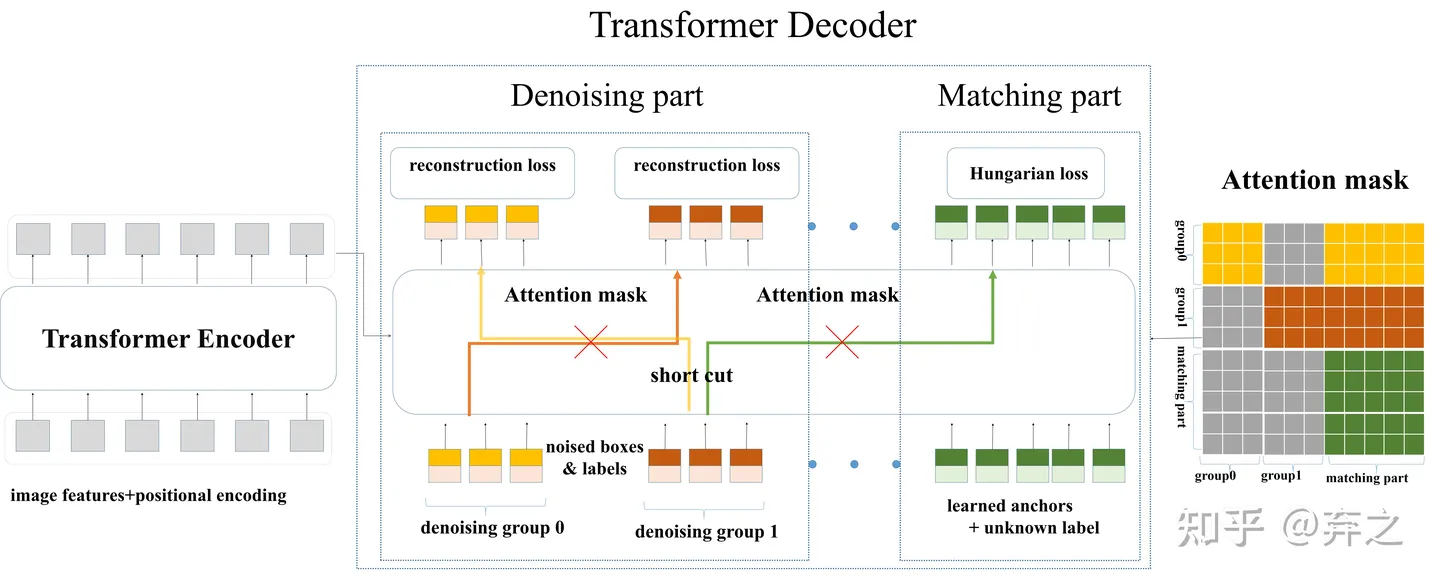
Denoising
notice that denoising is only considered in training, during inference the denoising part is removed, leaving only the matching part.
噪声类型:
-
怎么加入?
-
什么时候算?
-
For each image, we collect all GT objects and add random noises to both their bounding boxes and class labels.
-
**box噪声:**中心坐标偏移(不超过原始GT的范围)、高宽坐标缩放(可能不会同步缩放)
Loss: L1 loss,GIOU loss(加入的去噪的框体匈和300个query就不用匈牙利匹配算loss了,去噪矿体对应的GT是知道的(?))
-
**label噪声:**标签的随意更改,
Loss:focal loss
Attention Mask
加了Denoising之后模型的输入变为下图。原始DETR的匹配部分我们命名为Matching part,新加的denosing 部分命名为denoising part。需要注意的是,denoising part只需要在训练的时候加上,在inference的时候denoising part会直接移除,和原始模型一样,因此inference的时候不会增加计算量,训练的时候也只需要加入微小的计算量
Therefore, each query in the denoising part can be represented as
q
k
=
δ
(
t
m
)
qk = δ(t_m)
qk=δ(tm) where tm is
m
−
t
h
m-th
m−th GT object.
q
=
{
g
0
,
g
1
,
.
.
.
.
,
g
P
−
1
}
w
h
e
r
e
g
p
是第
p
组
d
e
n
o
i
s
i
n
g
g
r
o
u
p
g
p
=
{
q
0
p
,
q
1
p
,
.
.
.
.
,
q
M
−
1
p
}
M
=
b
s
中
G
T
的总和
\begin{aligned}\mathbf{q}&=\{\mathbf{g_0},\mathbf{g_1},....,\mathbf{g_{P-1}}\} where g_p是第p组denoising group \\\mathbf{g_p}&=\begin{Bmatrix}q_0^p,q_1^p,....,q_{M-1}^p\end{Bmatrix}M=bs中GT的总和\end{aligned}
qgp={g0,g1,....,gP−1}wheregp是第p组denoisinggroup={q0p,q1p,....,qM−1p}M=bs中GT的总和
a i j = { 1 , if j < P × M and ⌊ i M ⌋ ≠ ⌊ j M ⌋ ; 1 , if j < P × M and i ≥ P × M ; 0 , otherwise. \left.a_{ij}=\left\{\begin{array}{ll}1,&\text{if }j<P\times M\text{ and }\lfloor\frac{i}{M}\rfloor\neq\lfloor\frac{j}{M}\rfloor;\\1,&\text{if }j<P\times M\text{ and }i\ge P\times M;\\0,&\text{otherwise.}\end{array}\right.\right. aij=⎩ ⎨ ⎧1,1,0,if j<P×M and ⌊Mi⌋=⌊Mj⌋;if j<P×M and i≥P×M;otherwise.
除了加noise之外,在decoder的self attention我们需要加一个额外的attention mask防止信息泄露。因为denoising部分包含真实框和真实标签的信息,直接让matching part看到denoising part会导致信息泄漏。因此,训练的时候matching part不能看到denoising part,像原始模型一样训练。额外增加的denoising part看或者不看到matching part对结果影响不大,因为denosing部分含有最多的真实框和标签。
左边做reconstruct,右边300个query做匈牙利匹配
信息泄露:
1.matching part看到group
2.group之间
为什么attention mask不阻止group和matching?
Label Embedding(decoder embedding)
和label没有多大关系,名称上的区分
decoder embedding在模型中被指定为label embedding,以支持box去噪和label去噪
还在标签嵌入中添加了一个指示器(tensor最后一维加上标识)。如果一个查询属于去噪部分,则该指示器为1,否则为0。
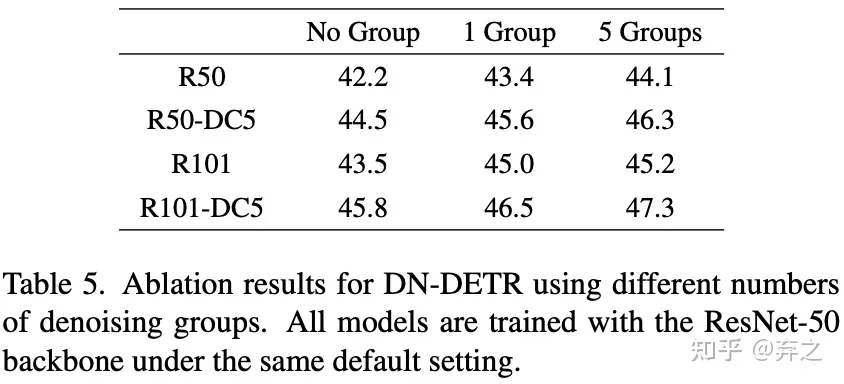
消融实验
不加attention mask结果很低