目录
SQLAlchemy介绍
SQLAlchemy连接数据库
SQLAlchemy介绍
数据库是一个网站的基础!!!
比如MySQL、MongoDB、SQLite、PostgreSQL等,这里我们以MySQL为例进行讲解。
SQLAlchemy是一个ORM框架
对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序设计技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。
大白话
对象模型与数据库表的映射
为什么要有SQLAlchemy?
随着项目的越来越大,采用写原生SQL的方式在代码中会出现大量重复的SQL语句,那么,问题就出现了:
- SQL语句重复利用率不高,越复杂的SQL语句条件越多,代码越长,会出现很多相近的SQL语句
- 很多SQL语句 是在业务逻辑中拼接出来的,如果数据库需要更改,就要去修改这些逻辑,这会容易漏掉对某些SQL语句的修改
- 写SQL时容易忽略web安全问题,造成隐患
而ORM可以通过类的方式去操作数据库而不用再写原生的SQL语句,通过把表映射成类,把行作为实例(一条数据),把字段作为属性,ORM在执行对象操作的时候最终还是会把对象的操作转换为数据库的原生语句,但使用ORM有许多优点:
- 易用性:使用ORM做数据库开发可以有效减少重复SQL语句的概率,写出来的模型也更加直观、清晰
- 性能损耗小:ORM转换成底层数据库操作指令确实会有一些开销。但是从实际情况来看,这种性能损耗很少(不足5%),只要不是针对性能有严苛的要求,综合考虑开发效率、代码阅读性,带来的好处远大于性能损耗,而且项目越大作用越明显。
- 设计灵活:可以轻松的写出复杂的查询。
- 可移植性:SQLAlchemy封装了底层的数据库实现,支持多个关系数据库引擎,包括流行的Mysql、PostgreSQL和SQLite,可以非常轻松的切换数据库。
使用ORM操作数据库将变得非常简单
class Person:
name = 'xx'
age = 18
country ='xx'
# Person类 -> 数据库中的一张表
# Person类中的属性 -> 数据库中一张表字段
# Person类的一个对象 -> 数据库中表的一条数据
# p = Person('xx',xx)
# p.save()
# insert into table values ('xx',xx)
在操作数据库操作之前,先确保你已经安装了以下软件:
-
mysql
- 如果是在windows上,到官网下载
-
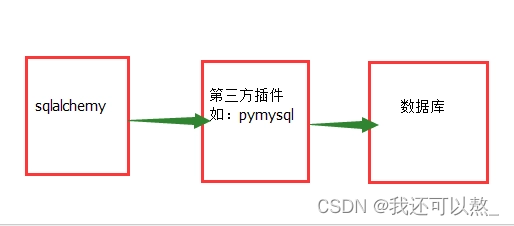
pymysql:pymysql是用Python来操作mysql的包
from sqlalchemy import create_enginepip install pymysql -
SQLAlchemy:SQLAlchemy是一个数据库的ORM框架,我们在后面会用到。
pip install SQLAlchemy
SQLAlchemy连接数据库
首先要引入SQLAlchemy
from sqlalchemy import create_engine
接下来,需要创建一个数据库引擎(engine)对象,它将负责与实际数据库进行通信。引擎对象的创建通常需要指定数据库的连接字符串,该字符串包含了连接数据库所需的信息(如用户名、密码、主机地址等)。
# 例如连接到一个名为'mydatabase'的SQLite数据库
engine = create_engine('sqlite:///mydatabase.db')
如果要连接到其他类型的数据库,连接字符串将有所不同。例如,连接到一个名为'mydatabase'的MySQL数据库:
engine = create_engine('mysql://username:password@localhost/mydatabase')
中间为数据库的变量:
def conn_db1():
# 数据库的变量
HOST = '192.168.30.151' # 127.0.0.1/localhost
PORT = 3306
DATA_BASE = 'flask_db'
USER = 'root'
PWD = '123'一个基本框架:
from sqlalchemy import create_engine
def conn_db1():
# 数据库的变量
HOST = '192.168.30.151' # 127.0.0.1/localhost
PORT = 3306
DATA_BASE = 'flask_db'
USER = 'root'
PWD = '123'
# DB_URI = f'数据库的名+驱动名://{USER}:{PWD}@{HOST}:{PORT}/{DATA_BASE}'
DB_URI = f'mysql+pymysql://{USER}:{PWD}@{HOST}:{PORT}/{DATA_BASE}'
engine = create_engine(DB_URI)
# 执行一个SQL
sql = 'select 2;'
conn = engine.connect()
rs = conn.execute(sql)
print(rs.fetchone())
逐条代码解释:
from sqlalchemy import create_engine: 这行导入了create_engine函数,它是SQLAlchemy提供的用于创建数据库引擎的函数。
def conn_db1():: 这是一个Python函数的定义,函数名为conn_db1。下面的一系列变量定义了连接到数据库所需的信息,包括主机地址(
HOST)、端口号(PORT)、数据库名(DATA_BASE)、用户名(USER)和密码(PWD)。
DB_URI = f'mysql+pymysql://{USER}:{PWD}@{HOST}:{PORT}/{DATA_BASE}': 这行代码构建了一个数据库连接字符串(DB_URI),它包括了数据库类型(mysql)、用户名、密码、主机地址、端口号以及数据库名。
engine = create_engine(DB_URI): 这行代码使用create_engine函数创建了一个数据库引擎(engine),该引擎将用于与数据库进行交互。
sql = 'select 2;': 这行代码定义了一个简单的SQL查询语句,它将返回数字2。
conn = engine.connect(): 这行代码使用数据库引擎建立了一个连接(conn)。
rs = conn.execute(sql): 这行代码使用连接执行了之前定义的SQL查询语句,并将结果赋给了变量rs。
print(rs.fetchone()): 这行代码使用fetchone()方法从查询结果中获取了一行数据,并将其打印出来。