文章目录
- CAS
- Atomic 原子类
- 一般原子类
- 针对aba问题 —— AtomicStampedReference
- 针对大量自旋问题 —— LongAdder
CAS
原理大致如下:
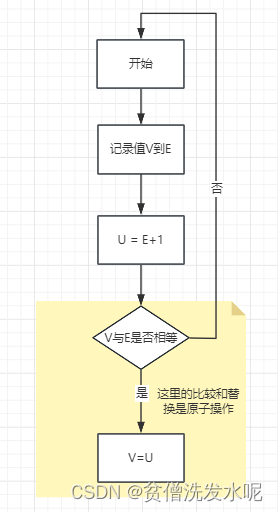
在java的 Unsafe 类里封装了一些 cas 的api。以 compareAndSetInt 为例,来看看其底层实现。
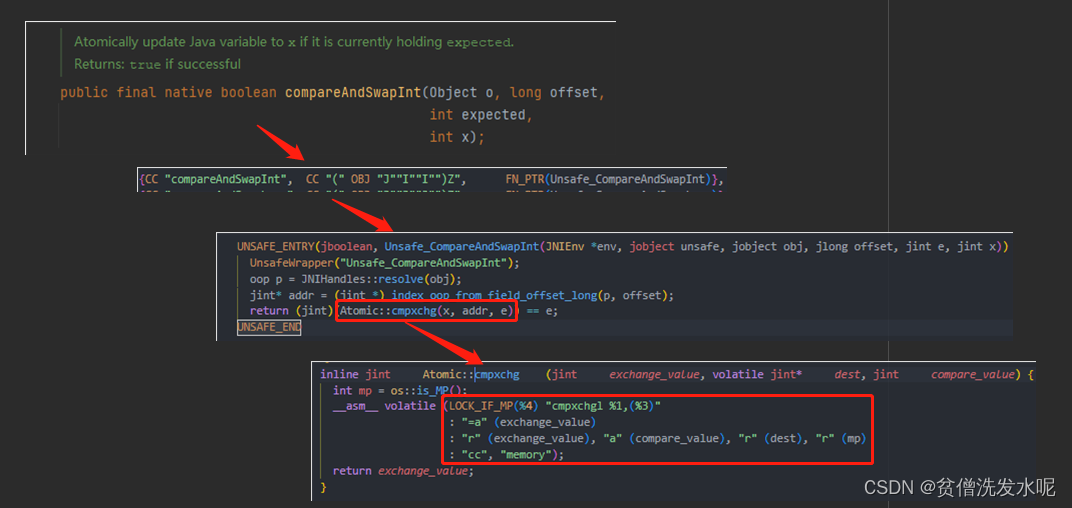
可以发现,最终会调用到 Atomic::cmpxchg 方法(Atomic::cmpxchg 在不同的操作系统中实现有所不同,上图所示是 linux_x86 的代码)。
Atomic::cmpxchg (exchange_value,dest, compare_value)
compare_value:是期望的当前值,如果 destination 的当前值等于 compare_value,则进行替换操作。
dest: 是要进行比较和替换的内存位置(通常是一个变量或内存地址)。
exchange_value: 是要设置到 destination 的新值。
返回:CAS成功返回替换值,CAS失败返回原值。
Atomic::cmpxchg 底层是 cmpxchgl 指令,该指令是一个硬件层面上的原子操作。除此之外如果是多核架构还加入lock前缀指令以实现内存屏障的效果。
cmpxchgl指令:首先比较 dest 指向的内存值是否和 compare_value 值相等,如果相等,则交换 dest 与 exchange_value,否则就单方面将 dest 指向的值赋给exchange_value。
Atomic 原子类
在理解了cas的底层实现后,再来看原子类。
一般原子类
一般的源自类无非就是直接调用了 Unsafe 中 cas 相关api。
以AtomicInteger为例:
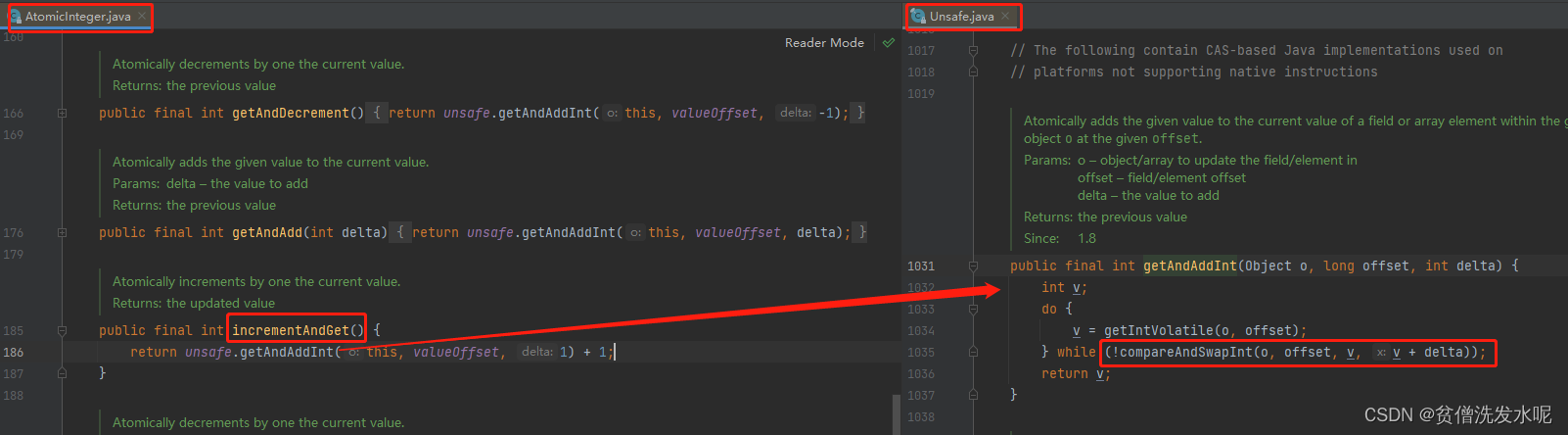
而上面是在不考虑CAS自身缺陷情况下的一个封装,如果考虑上CAS缺陷,原子类该如何应对?
cas缺陷:1、aba问题 2、可能大量自旋
针对aba问题 —— AtomicStampedReference
试想这么一个场景:从读取内存值开始到执行cas原子指令之前,值被修改了两次,一次+1,一次-1。此时对于cas指令来说,内存中的值是不变的,就好像没被修改过一样,进而指令操作成功。这就是aba问题。
为解决aba问题,jdk增加了 AtomicStampedReference 类。核心设计思想是多加版本号的概念。当cas替换时不仅比对内存中的值是否是期望值,还会去比对版本号是否跟一开始的相等, 如果不相等,所以在这期间被修改过了,此时就cas失败。
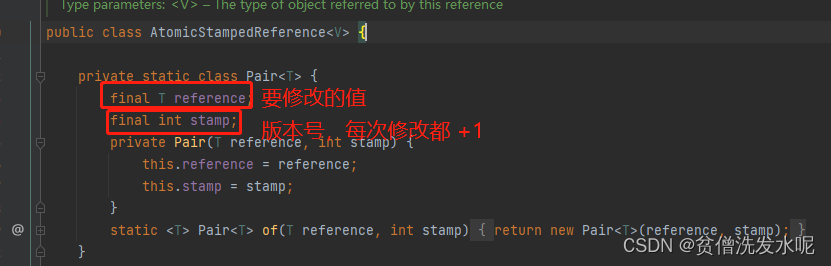
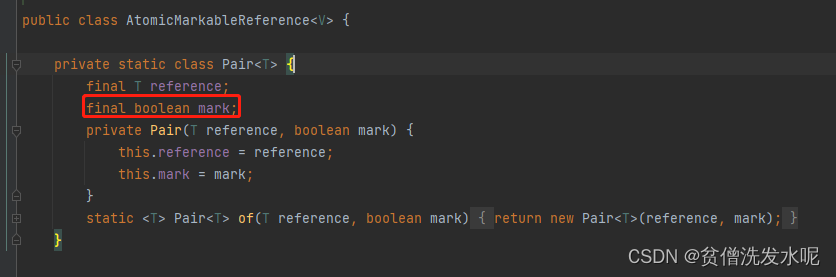
除了 AtomicStampedReference 还有 AtomicMarkableReference 。区别在于 AtomicMarkableReference 并不关心修改了多少次,只关心是否被修改过。所以mark是一个boolean类型。
针对大量自旋问题 —— LongAdder
试想这么一个场景,假如同一时刻大量线程对库存数量-1,此时必然会有大量的自旋线程占用cpu资源。这明显是一个资源的浪费。如果不用cas,加锁的话,就会有线程切换,对性能必然会有所影响。有没有那么一种方案,既不加锁阻塞线程,又可以避免大量的自旋呢?
为解决这类场景的问题,jdk 1.8 引入了 LongAdder。
除 LongAdder 外还有 DoubleAdder、DoubleAccumulator、LongAccumulator,基本原理是一样的,本文以 LongAdder为例。
LongAccumulator相当于LongAdder的增强版。LongAdder只能针对数值的进行加减运算,而LongAccumulator提供了自定义的函数操作。
LongAdder的基本思路:
分散热点,将value值分散到数组中,不同线程会命中到数组的不同槽,每个线程只对自己槽中的值进行CAS,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只需将各个槽中的变量值累加返回即可。
重要变量:base变量 + Cells[]数组
base变量:非竞态条件下,直接累加到该变量上
Cells[]数组:竞态条件下,累加个各个线程自己的槽Cell[i]中
接下来从源码看看 LongAdder 是如何累加的:
LongAdder#add
public void add(long x) {
Cell[] cs; long b, v; int m; Cell c;
if ((cs = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (cs == null || (m = cs.length - 1) < 0 ||
(c = cs[getProbe() & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
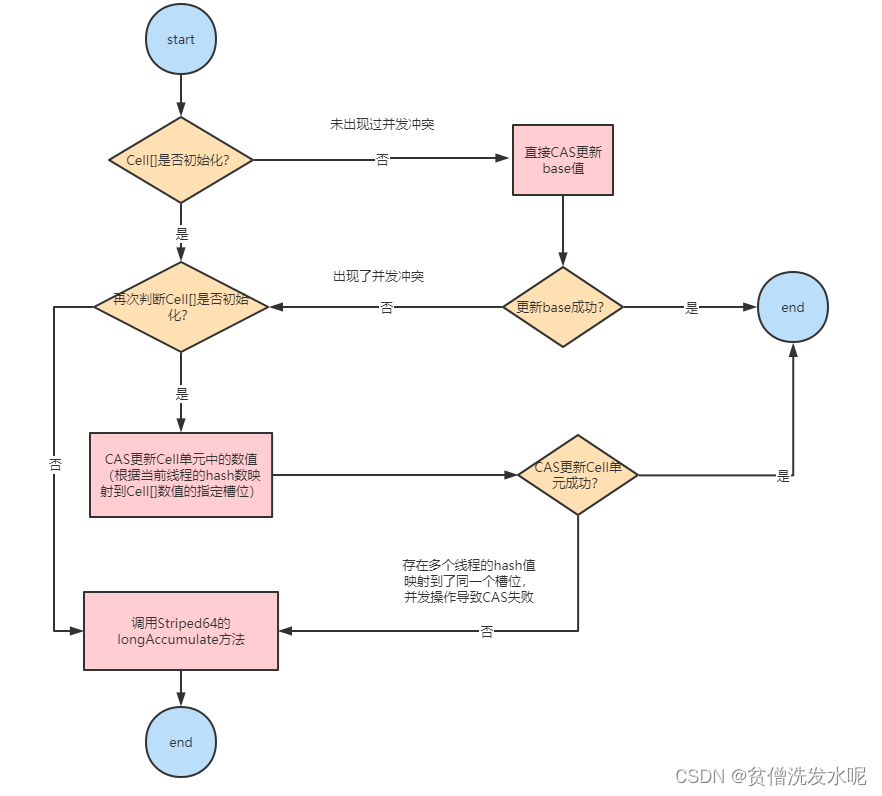
总之就是当 cells 还为初始化就直接cas base变量,如果一开始cells就已经初始化,或者cas base 变量失败就cas cells数组,如果cas cells数组也失败就进入Striped64#longAccumulate。
Striped64#longAccumulate
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
//...
//自旋循环
done: for (;;) {
Cell[] cs; Cell c; int n; long v;
//如果cells不为空
if ((cs = cells) != null && (n = cs.length) > 0) {
//映射的槽位为空,新建并设置槽位
if ((c = cs[(n - 1) & h]) == null) {
if (cellsBusy == 0) {
Cell r = new Cell(x);
if (cellsBusy == 0 && casCellsBusy()) {
try {
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
break done;
}
} finally {
cellsBusy = 0;
}
continue;
}
}
collide = false;
}
//...(自旋重试的标记位处理)
//不为空就 cas cell 槽位
else if (c.cas(v = c.value, (fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
//...(自旋重试的标记位处理)
//cas cell 槽位失败尝试扩容cells
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == cs) // Expand table unless stale
cells = Arrays.copyOf(cs, n << 1);
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
//如果为空就新建 cells 并设置 cell 槽位
else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {
try {
if (cells == cs) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
break done;
}
} finally {
cellsBusy = 0;
}
}
//如果正在扩容,直接cas base
else if (casBase(v = base,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break done;
}
}
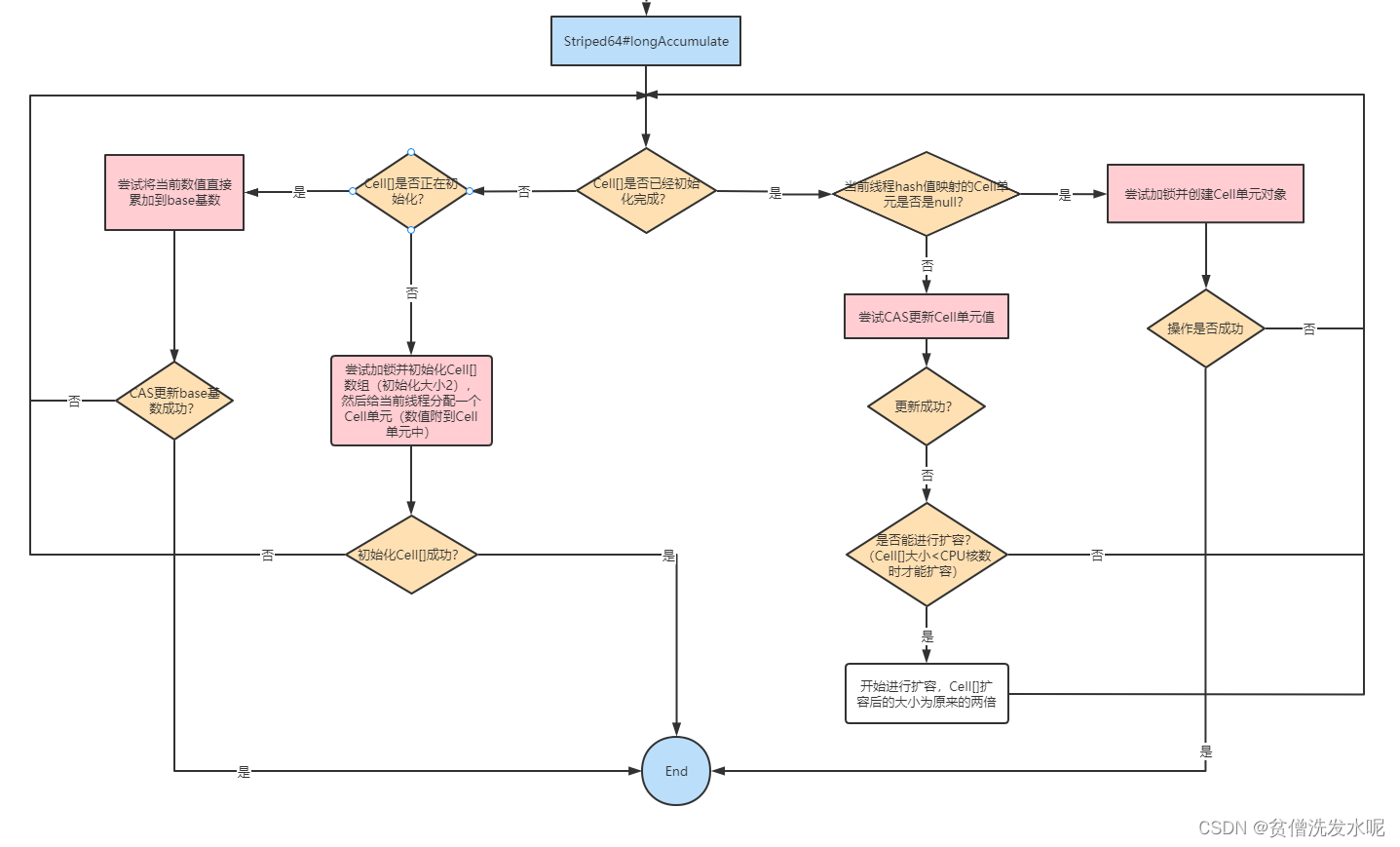
总之就是如果cells还未初始化就初始化并设置此次槽位。如果正在初始化就直接cas base。如果已经初始化,就映射槽位,如果槽位为null,就创建槽位并设值,如果槽位不为null,就cas该槽位,如果槽位cas失败,就尝试扩容(cells大小 < cpu核数 时扩容)。






![[maven] 实现使用 plugin 及 properties 简述](https://img-blog.csdnimg.cn/e9cf8aadd7044d079b7ddd57b602ba42.png)