参考博文:目标检测(Object Detection)_YEGE学AI算法的博客-CSDN博客
这篇参考的相当多,写的真的很好很入门,觉得很有用,想详细了解的可以去看看,侵删↑
上回组会分享了DETR和MDETR,然后我一个一直做分割的虽然跑过Yolo5但是其实里面还有点原理不太懂,老师叫我明天组会详细分享一下,我只能把目标检测速通一下,,,啊!!!!搞科研哪有不疯的!!!
基本概念
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
 目标检测是一个分类、回归问题的叠加。
目标检测是一个分类、回归问题的叠加。
核心问题
(1)分类问题:即图片(或某个区域)中的图像属于哪个类别。
(2)定位问题:目标可能出现在图像的任何位置。
(3)大小问题:目标有各种不同的大小。
(4)形状问题:目标可能有各种不同的形状。
分类
Onestage
不用区域生成,该区域称之为region proposal(简称RP,一个有可能包含待检物体的预选框),直接在网络中提取特征来预测物体分类和位置。
任务流程:特征提取–> 分类/定位回归。
常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。
Twostage
先进行RP,再通过卷积神经网络进行样本分类。
任务流程:特征提取 --> 生成RP --> 分类/定位回归。
常见tow stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。
原理
目标检测分为两大系列——RCNN系列和YOLO系列,RCNN系列是基于区域检测的代表性算法,YOLO是基于区域提取的代表性算法,另外还有著名的SSD是基于前两个系列的改进
1. 候选区域产生
很多目标检测技术都会涉及候选框(bounding boxes)的生成,物体候选框获取当前主要使用图像分割与区域生长技术。区域生长(合并)主要由于检测图像中存在的物体具有局部区域相似性(颜色、纹理等)。目标识别与图像分割技术的发展进一步推动有效提取图像中信息
1)滑动窗口
首先对输入图像进行不同窗口大小的滑窗进行从左往右、从上到下的滑动。每次滑动时候对当前窗口执行分类器(分类器是事先训练好的)。如果当前窗口得到较高的分类概率,则认为检测到了物体。对每个不同窗口大小的滑窗都进行检测后,会得到不同窗口检测到的物体标记,这些窗口大小会存在重复较高的部分,最后采用非极大值抑制(Non-Maximum Suppression, NMS)的方法进行筛选,获得检测到的物体。
滑窗法简单易于理解,但是不同窗口大小进行图像全局搜索导致效率低下,而且设计窗口大小时候还需要考虑物体的长宽比。所以,对于实时性要求较高的分类器,不推荐使用滑窗法。
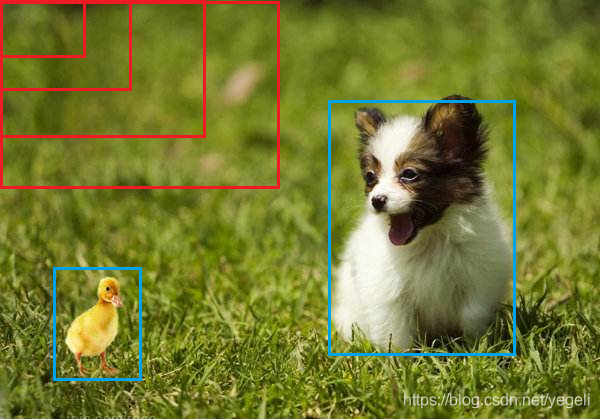
* proposals
在目标检测中,"proposals"(提议)通常指的是候选物体边界框或区域,它们被算法提出作为可能包含感兴趣物体的候选区域。这些提议是用来减少目标检测任务的计算复杂性。
滑动窗口非常耗时,特别是在大型图像数据集上。为了加速这个过程,引入了提议生成器(proposal generator)或候选区域生成器,它的任务是快速生成一组可能包含物体的候选边界框↓。一旦提议生成器生成了这些候选区域或边界框,接下来的目标检测模型将在这些提议上执行物体检测任务。这个目标检测模型可以是传统的机器学习方法,也可以是深度学习模型,如卷积神经网络(CNN)
2)选择性搜索
① 什么是选择性搜索
滑窗法类似穷举进行图像子区域搜索,但是一般情况下图像中大部分子区域是没有物体的。学者们自然而然想到只对图像中最有可能包含物体的区域进行搜索以此来提高计算效率。选择搜索(selective search,简称SS)方法是当下最为熟知的图像bounding boxes提取算法,由Koen E.A于2011年提出。
选择搜索算法的主要思想:图像中物体可能存在的区域应该是有某些相似性或者连续性区域的。因此,选择搜索基于上面这一想法采用子区域合并的方法进行提取bounding boxes。首先,对输入图像进行分割算法产生许多小的子区域。其次,根据这些子区域之间相似性(相似性标准主要有颜色、纹理、大小等等)进行区域合并,不断的进行区域迭代合并。每次迭代过程中对这些合并的子区域做bounding boxes(外切矩形),这些子区域外切矩形就是通常所说的候选框。
step0:生成区域集R
step1:计算区域集R里每个相邻区域的相似度S={s1, s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
评估标准
IoU (Intersection over Union,交并比)
分割人的好朋友
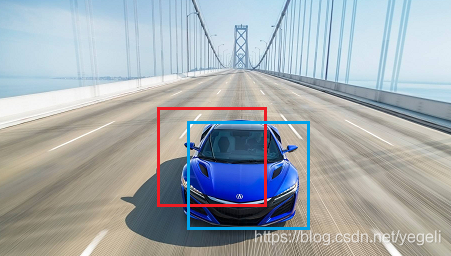
NMS(Non-Maximum Suppression,非极大值抑制)
预测结果中,可能多个预测结果间存在重叠部分,需要保留交并比最大的、去掉非最大的预测结果。如下图所示,对同一个物体预测结果包含三个概率0.8/0.9/0.95,经过非极大值抑制后,仅保留概率最大的预测结果。

常用模型
这里就捞最常用的几个模型理清一下流程
R-CNN

② 流程
1. 预训练模型。选择一个预训练 (pre-trained)神经网络(如AlexNet、VGG)。
2. 重新训练全连接层。使用需要检测的目标重新训练(re-train)最后全连接层(connected layer)。
3. 提取 proposals并计算CNN 特征。利用选择性搜索(Selective Search)算法提取所有proposals(大约2000幅images),调整(resize/warp)它们成固定大小,以满足 CNN输入要求(因为全连接层的限制),然后将feature map 保存到本地磁盘。
4. 训练SVM。利用feature map 训练SVM来对目标和背景进行分类(每个类一个二进制SVM)
边界框回归(Bounding boxes Regression)。训练将输出一些校正因子的线性回归分类器
Fast R-CNN
是一个改进region proposal的方式

缺点:
依旧采用selective search提取region proposal(耗时2~3秒,特征提取耗时0.32秒)
无法满足实时应用,没有真正实现端到端训练测试 利用了GPU,但是region proposal方法是在CPU上实现的
🤔DETR就是端到端了欸
"端到端"(End-to-End)是一种方法或系统设计理念,它强调在一个整体系统中从输入到输出的一体化处理,而不需要中间的多个处理步骤或模块。简言之,端到端意味着将整个任务或流程作为一个单一的过程来解决,而不是将其分解为多个独立的子任务或阶段。
Faster RCNN
经过R-CNN和Fast-RCNN的积淀,Ross B.Girshick在2016年提出了新的Faster RCNN,在结构上将特征抽取、region proposal提取, bbox regression,分类都整合到了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。真正实现了一个完全的End-To-End的CNN目标检测模型。
整体流程
1. Conv Layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的卷积/激活/池化层提取图像的特征,形成一个特征图,用于后续的RPN层和全连接层。
2. Region Proposal Networks(RPN)。RPN网络用于生成候选区域,该层通过softmax判断锚点(anchors)属于前景还是背景,在利用bounding box regression(包围边框回归)获得精确的候选区域。
3. RoI Pooling。该层收集输入的特征图和候选区域,综合这些信息提取候选区特征图(proposal feature maps),送入后续全连接层判定目标的类别。
4. Classification。利用取候选区特征图计算所属类别,并再次使用边框回归算法获得边框最终的精确位置。
锚点(anchors)
锚点的主要作用是提供了一组候选边界框,这些边界框涵盖了输入图像的不同位置和尺度上可能存在的物体。这些候选边界框是通过在图像的每个像素位置应用不同大小和宽高比的锚点来生成的。具体来说,锚点是一组预定义的矩形框,每个锚点由其中心坐标、宽度和高度表示。模型会在每个锚点位置尝试预测物体是否存在以及物体的位置和类别。
Anchors(锚点)指一组矩阵,每个矩阵对应不同的检测尺度大小。
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
其中每行4个值x1 y1 x2 y2 对应矩形框左上角、右下角相对于中心点的偏移量。9个矩形共有三种形状,即1:1, 1:2, 2:1,即进行多尺度检测。

锚点尺度和宽高比(Scale and Aspect Ratio): 锚点可以根据任务的需求来选择不同的尺度和宽高比。这意味着可以创建适应不同物体大小和形状的锚点。通常,锚点包括多个尺度和宽高比的组合,以便捕捉多样性。
锚点的生成: 锚点是在图像上以每个像素位置生成的。对于每个位置,每个尺度和宽高比的锚点都会生成一个候选边界框。这些候选边界框将被送入模型进行物体检测。就相当于每个像素都会生成上图那么多的框!
位置回归和类别分类: 模型会针对每个锚点位置和每个锚点框执行两项任务:位置回归(预测边界框的精确位置)和类别分类(判断边界框内是否包含物体以及物体的类别)。
损失函数
对一个图像的损失函数,是一个分类损失函数与回归损失函数的叠加:

分类损失函数
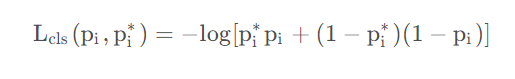
位置损失函数

其中:
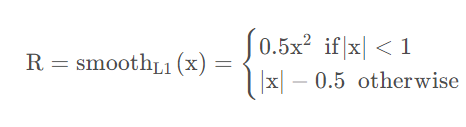
目标检测的概念差不多都理顺了,解决了我之前看论文的一些疑问,暂时就先写到这里吧TWT










![[极客大挑战 2019]RCE ME 取反绕过正则匹配 绕过disable_function设置](https://img-blog.csdnimg.cn/0ec4f5eb8a4e4d698e6aab117546840d.png)