CBOW (以txt文本小说为例 pytorch实战
今天博主做了一个不错的实验,我认为,很多小伙伴可能都可以从中学到东西。
我先说一下这个实验,我做了什么,在这个实验中,博主会从零,开始从一个txt文件开始,对这个文件的中文词语进行分词,并进行one-hot编码,处理完数据之后,还搭建了cbow网络。之后,我们训练了自己的模型,在此基础上,我们也对模型进行了些许验证,就是通过我们得到的嵌入词向量,然后计算某一个词语与其最近的k个词语,在验证过程中,我们发现数据集质量很差,不过,经过验证确实,模型还是有一定效果的。
先看一下,我们能数据集处理和模型训练的代码:
#coding=gbk
import os
import jieba
import torch
from torch import nn, optim
from torch.autograd import Variable
import torch.nn.functional as F
path="E:\\data\\dataz.txt"
def read_file(path):
fp=open(path,encoding='utf8')
text=fp.readlines()
fp.close()
return text
def cut_words(text):
dict_index={}
index=0
words_list=[]
for line in text:
line=line.replace('"','')
line=line.replace('“','')
line=line.replace('”','')
line=line.replace('。','')
line=line.replace('\n','')
line=line.replace(' ','')
words_cut=line.split(',')
for i in words_cut:
words_l=jieba.lcut(i)
for word in words_l:
if word not in dict_index.keys():
dict_index[word]=index
index=index+1
if len(words_l)>0:
words_list.append(words_l)
return words_list,dict_index
def get_data_corpus(words_list,window_size):
data_corpus=[]
for words in words_list:
if len(words)<2:
continue
else:
for index in range(len(words)):
l=[]
target=words[index]
l.append(target)
try:
l.append(words[index+1])
l.append(words[index+2])
except:
pass
try:
l.append(words[index-1])
l.append(words[index-2])
except:
pass
data_corpus.append(l)
return data_corpus
text=read_file(path)
words_list,dict_index=cut_words(text)
#print(words_list,dict_index)
data_corpus=get_data_corpus(words_list,2)
#print(data_corpus)
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# self.proj = nn.Linear(embedding_dim, vocab_size)
self.output = nn.Linear(embedding_dim, vocab_size)
def forward(self, inputs):
embeds = sum(self.embeddings(inputs)).view(1, -1)
# out = F.relu(self.proj(embeds))
out = self.output(embeds)
nll_prob = F.log_softmax(out, dim=-1)
return nll_prob
length=len(dict_index.keys())
data_final=[]
for words in data_corpus[0:10000]:
target_vector=torch.zeros(length)
context_id=[]
if len(words)==5:
target_vector[dict_index[words[0]]]=1
for i in words[1:]:
context_id.append(dict_index[i])
data_final.append([target_vector,context_id])
#print(data_final)
epochs=5
model=CBOW(length,100)
loss_function=nn.NLLLoss()
optimizer=optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
losses=[]
for epoch in range(epochs):
total_loss = 0
for data in data_final:
target=data[0]
context=data[1]
# context_vector = make_context_vector(context, word_to_idx).to(device) # 把训练集的上下文和标签都放到cpu中
target = torch.tensor(target).type(dtype=torch.long)
context=torch.tensor(context)
model.zero_grad() # 梯度清零
train_predict = model(context) # 开始前向传播
# print("train_predict",train_predict[0])
# print("target",target)
loss = loss_function(train_predict[0], target)
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_loss += loss.item()
print("loss ",total_loss)
losses.append(total_loss)
#保存
torch.save(model,'E:\\data\\cbow.pt')
#读取
os.system("pause")
下面则是对某一个词语进行最近词汇测评的代码:
#coding=gbk
import os
import jieba
import torch
from torch import nn, optim
from torch.autograd import Variable
import torch.nn.functional as F
path="E:\\data\\dataz.txt"
def read_file(path):
fp=open(path,encoding='utf8')
text=fp.readlines()
fp.close()
return text
def cut_words(text):
dict_index={}
index=0
words_list=[]
for line in text:
line=line.replace('"','')
line=line.replace('“','')
line=line.replace('”','')
line=line.replace('。','')
line=line.replace('\n','')
line=line.replace(' ','')
words_cut=line.split(',')
for i in words_cut:
words_l=jieba.lcut(i)
for word in words_l:
if word not in dict_index.keys():
dict_index[word]=index
index=index+1
if len(words_l)>0:
words_list.append(words_l)
return words_list,dict_index
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# self.proj = nn.Linear(embedding_dim, vocab_size)
self.output = nn.Linear(embedding_dim, vocab_size)
def forward(self, inputs):
embeds = sum(self.embeddings(inputs)).view(1, -1)
# out = F.relu(self.proj(embeds))
out = self.output(embeds)
nll_prob = F.log_softmax(out, dim=-1)
return nll_prob
def get_data_corpus(words_list,window_size):
data_corpus=[]
for words in words_list:
if len(words)<2:
continue
else:
for index in range(len(words)):
l=[]
target=words[index]
l.append(target)
try:
l.append(words[index+1])
l.append(words[index+2])
except:
pass
try:
l.append(words[index-1])
l.append(words[index-2])
except:
pass
data_corpus.append(l)
return data_corpus
text=read_file(path)
words_list,dict_index=cut_words(text)
print(dict_index)
path='E:\\data\\cbow.pt'
model = torch.load('E:\\data\\cbow.pt')
print(type(model.state_dict())) # 查看state_dict所返回的类型,是一个“顺序字典OrderedDict”
for param_tensor in model.state_dict(): # 字典的遍历默认是遍历 key,所以param_tensor实际上是键值
print(param_tensor,'\t',model.state_dict()[param_tensor].size())
embedings=model.state_dict()['embeddings.weight']
print(embedings)
print(len(embedings[0]))
# print("萧炎:",dict_index['萧炎'])
dict_values={}
for key in dict_index.keys():
dict_values[dict_index[key]]=key
def get_most_approch(embedings,target_id,k):
target_vec=embedings[target_id]
dict_k={}
index=0
for vec in embedings:
dict_k[index]=float(torch.dot(vec,target_vec))
index=index+1
sort_z=sorted(dict_k.items(),key=lambda e:e[1],reverse=True
) #排序
for i in sort_z[0:k]:
print(dict_values[i[0]])
get_most_approch(embedings,dict_index['萧炎'],10)
os.system("pause")
看一下,我们的一个测试结果:
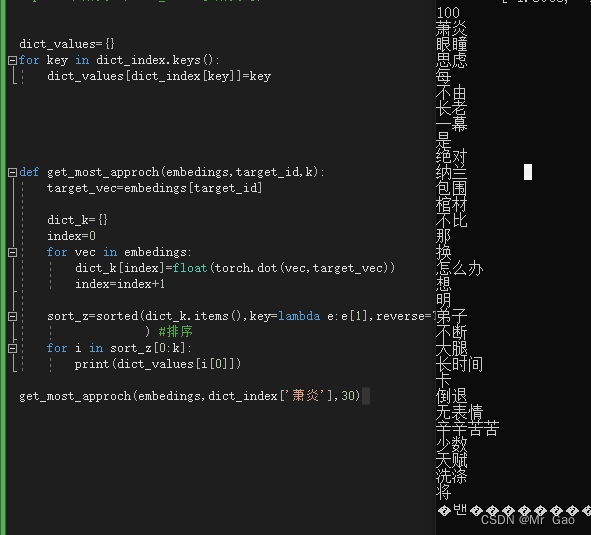
上图是我们测试跟萧炎有关的30个词语,大家可以发现还还是可以的,因为上面很多词语都是人发出的,萧炎是一个人名,其次弟子,长老,纳兰,跟其萧炎很有关系,说明该模型是有一定效果的。
数据集我会上传到我的资源,想运行代码的可以下载数据集。






![[杂谈]-八进制数](https://img-blog.csdnimg.cn/8f8fb0457025428a992f6ff950ee05d2.png#pic_center)