爬虫学习与实践
- 一、爬虫介绍
- 二、爬虫原理
- TCP3次握手,4次挥手过程
- 三、页面解析之数据提取
- 四、正则表达式
- 五、实践
- 1. 抓取百度贴吧
- 2. 拉钩招聘网
- 六、 进阶版
一、爬虫介绍
网络爬虫,其实叫作网络数据采集更容易理解。就是通过编程向网络服务器请求数据(HTML表单),然后解析HTML,提取出自己想要的数据
爬虫步骤:
- 根据url获取HTML数据
- 解析HTML,获取目标信息
- 存储数据
- 预处理
- 排名,提供检索服务
二、爬虫原理
爬虫是 模拟用户在浏览器或者某个应用上的操作,把操作的过程、实现自动化的程序
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。
网络爬虫的基本工作流程如下:
a . 首先选取一部分精心挑选的种子URL;
b. 将这些URL放入待抓取URL队列;
c. 从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
d. 分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
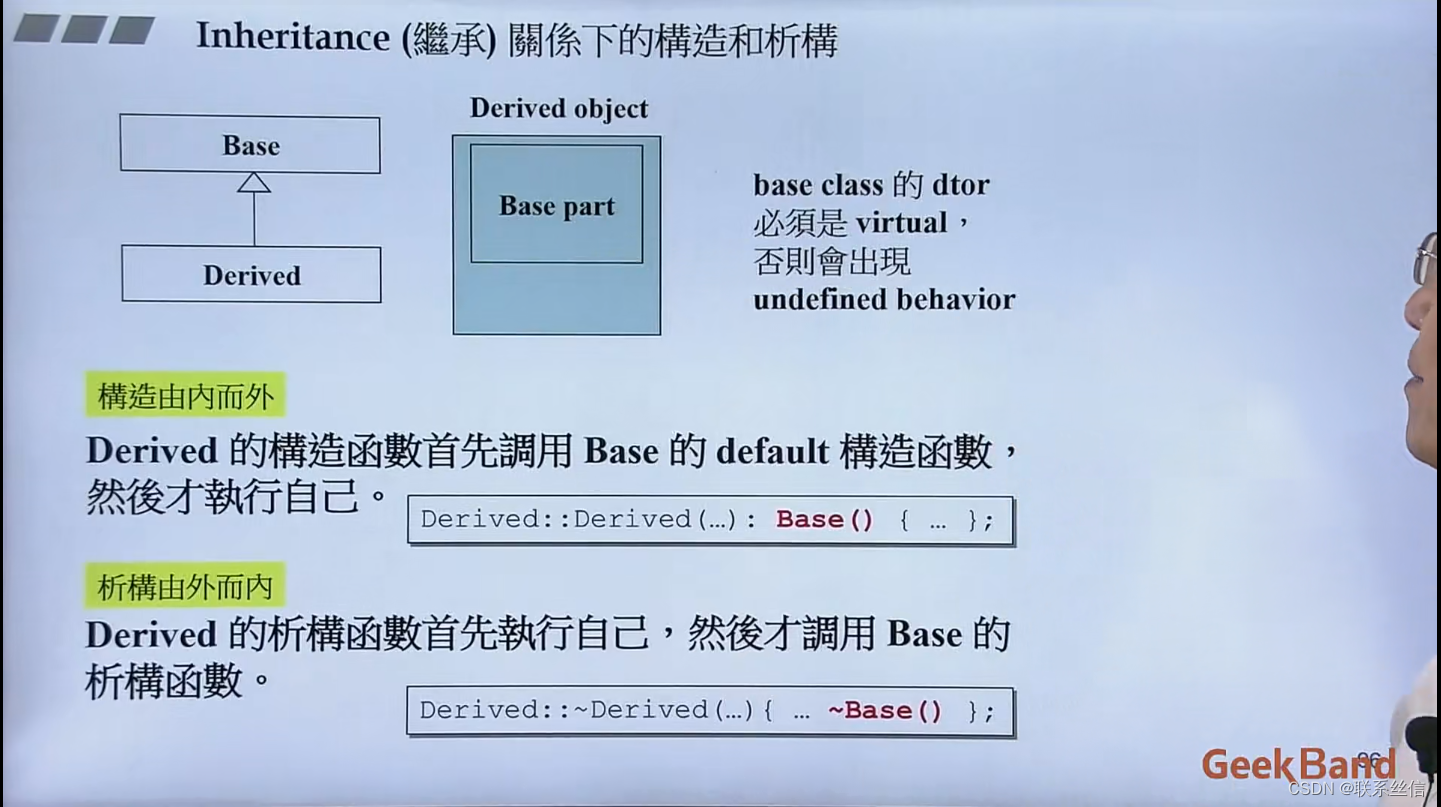
TCP3次握手,4次挥手过程
(1)客户端发送一个带SYN标志的TCP报文到服务器。这是三次握手过程中的报(2)服务器端回应客户端的,这是三次握手中的第2个报文,这个报文同时带ACK标志和SYN标志。因此它表示对刚才客户端SYN报文的回应;同时又标志SYN给客户端,询问客户端是否准备好进行数据通讯。
(3)客户必须再次回应服务段一个ACK报文,这是报文段3
连接终止协议(四次挥手):
(1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段4)。
(2) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个序号。
(3) 服务器关闭客户端的连接,发送一个FIN给客户端(报文段6)。
(4) 客户段发回ACK报文确认,并将确认序号设置为收到序号加1(报文段7)。
三、页面解析之数据提取
一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值,内容一般分为两部分,非结构化的文本,或结构化的文本。
关于结构化的数据
JSON、XML
关于HTML文本(包含JavaScript代码):
HTML文本(包含JavaScript代码)是最常见的数据格式,理应属于结构化的文本组织,但因为一般我们需要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归类于非结构化的数据处理中。
把网页比作一个人,那么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。
常见解析方式如下:XPath、CSS选择器、正则表达式
比如一段文本:
例如一篇文章,或者一句话,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储,如果是需要实时提取有用信息,常见的处理方式如下:
分词根据抓取的网站类型,使用不同词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词为方向,词频为长度。
NLP自然语言处理,进行语义分析,用结果表示,例如正负面等。
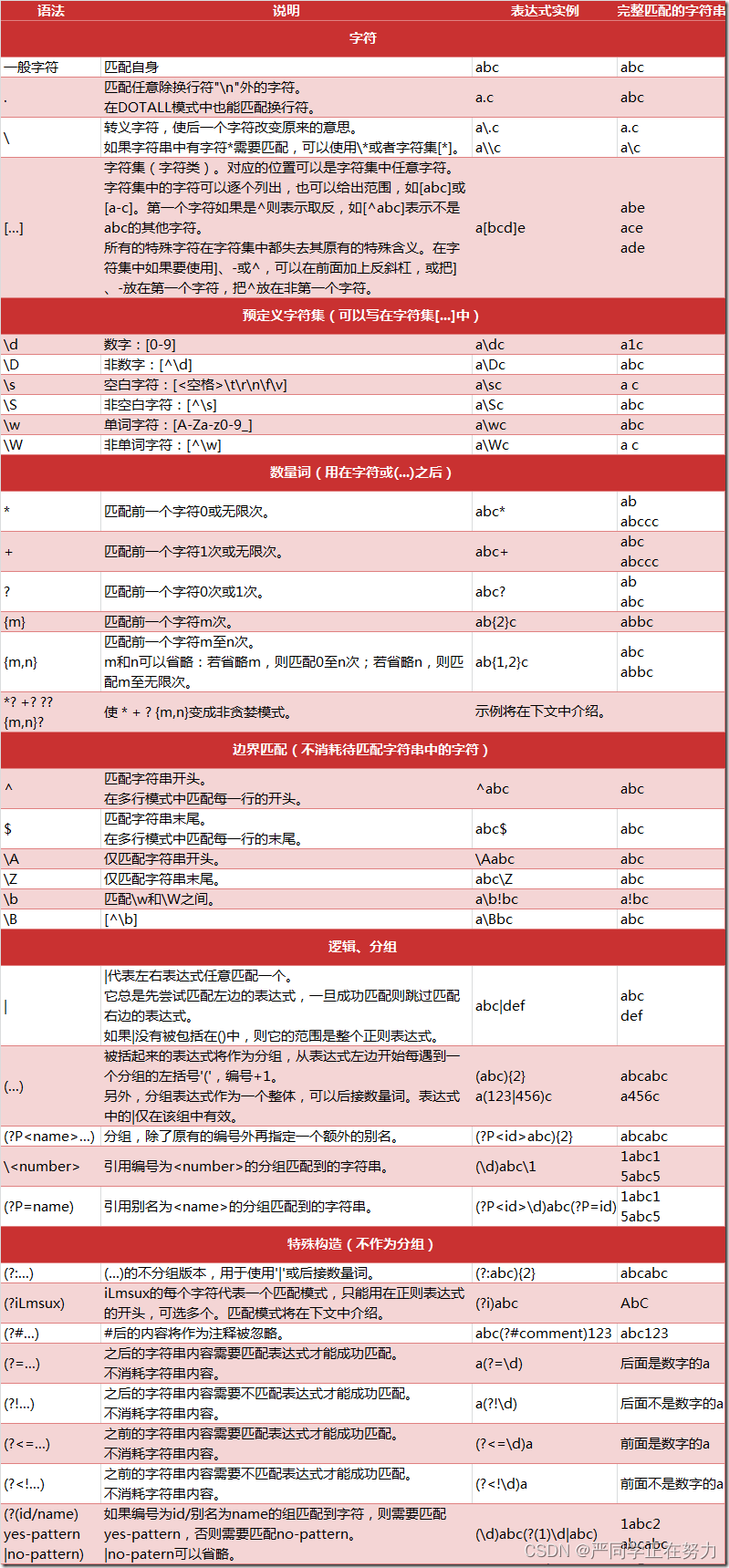
四、正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。
常见匹配符:
^ — 与字符串开始的地方匹配,不匹配任何字符;
$ — 与字符串结束的地方匹配,不匹配任何字符;
\b — 匹配一个单词边界,也就是单词和空格之间的位置,不匹配任何字符;
\B — \b取非,即匹配一个非单词边界;
五、实践
1. 抓取百度贴吧
源码
# -*- coding:utf-8 -*-
import urllib2
import urllib
from lxml import etree
import chardet
import json
import codecs
def GetTimeByArticle(url):
request = urllib2.Request(url)
response = urllib2.urlopen(request)
resHtml = response.read()
html = etree.HTML(resHtml)
time = html.xpath('//span[@class="tail-info"]')[1].text
print time
return time
def main():
output = codecs.open('tieba0812.json', 'w', encoding='utf-8')
for pn in range(0, 250, 50):
kw = u'网络爬虫'.encode('utf-8')
url = 'http://tieba.baidu.com/f?kw=' + urllib.quote(kw) + '&ie=utf-8&pn=' + str(pn)
print url
request = urllib2.Request(url)
response = urllib2.urlopen(request)
resHtml = response.read()
print resHtml
html_dom = etree.HTML(resHtml)
# print etree.tostring(html_dom)
html = html_dom
# site = html.xpath('//li[@data-field]')[0]
for site in html.xpath('//li[@data-field]'):
# print etree.tostring(site.xpath('.//a')[0])
title = site.xpath('.//a')[0].text
Article_url = site.xpath('.//a')[0].attrib['href']
reply_date = GetTimeByArticle('http://tieba.baidu.com' + Article_url)
jieshao = site.xpath('.//*[@class="threadlist_abs threadlist_abs_onlyline "]')[0].text.strip()
author = site.xpath('.//*[@class="frs-author-name j_user_card "]')[0].text.strip()
lastName = site.xpath('.//*[@class="frs-author-name j_user_card "]')[1].text.strip()
print title, jieshao, Article_url, author, lastName
item = {}
item['title'] = title
item['author'] = author
item['lastName'] = lastName
item['reply_date'] = reply_date
print item
line = json.dumps(item, ensure_ascii=False)
print line
print type(line)
output.write(line + "\n")
output.close()
print 'end'
if __name__ == '__main__':
main()
2. 拉钩招聘网
源码:
from lxml import etree
import requests
import re
response = requests.get('http://www.lagou.com/jobs/2101463.html')
resHtml = response.text
html = etree.HTML(resHtml)
title = html.xpath('//h1[@title]')[0].attrib['title']
#salary= html.xpath('//span[@class="red"]')[0].text
salary = html.xpath('//dd[@class="job_request"]/p/span')[0].text
worklocation = html.xpath('//dd[@class="job_request"]/p/span')[1].text
experience = html.xpath('//dd[@class="job_request"]/p/span')[2].text
education = html.xpath('//dd[@class="job_request"]/p/span')[3].text
worktype = html.xpath('//dd[@class="job_request"]/p/span')[4].text
Temptation = html.xpath('//dd[@class="job_request"]/p[2]')[0].text
print salary,worklocation,experience,education,worktype,Temptation
description_tag = html.xpath('//dd[@class="job_bt"]')[0]
description = etree.tostring( description_tag,encoding='utf-8')
#print description
deal_descp = re.sub('<.*?>','',description)
print deal_descp.strip()
publisher_name = html.xpath('//*[@class="publisher_name"]//@title')[0]
pos = html.xpath('//*[@class="pos"]')[0].text
chuli_lv = html.xpath('//*[@class="data"]')[0].text
chuli_yongshi = html.xpath('//*[@class="data"]')[1].text
print chuli_lv,chuli_yongshi,pos,publisher_name
六、 进阶版
爬虫框架,其中比较好用的是 Scrapy 和 PySpider
PySpider
优点:分布式框架,上手更简单,操作更加简便,因为它增加了 WEB 界面,写爬虫迅速,集成了phantomjs,可以用来抓取js渲染的页面。
缺点:自定义程度低
http://docs.pyspider.org/en/latest/Quickstart/
Scrapy
优点:自定义程度高,比 PySpider更底层一些,适合学习研究,需要学习的相关知识多,拿来研究分布式和多线程等等是最合适不过的。
缺点:非分布式框架(可以用scrapy-redis分布式框架)
爬虫技术越来越高级,需要我们不断学习、探索,今天就简单分享到这吧!

![[补题记录] Atcoder Beginner Contest 300(E)](https://img-blog.csdnimg.cn/672d848c3db243d5895d48328552cf6d.png)