文章目录
- 任务介绍
- 完成和调参
任务介绍
-
问题描述

给出美国某一州过去3天的调查结果,然后预测第3天新检测阳性病例的百分比。 -
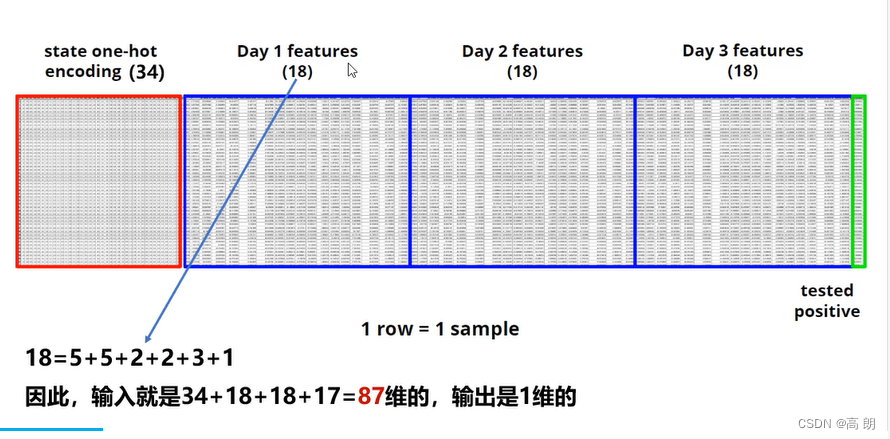
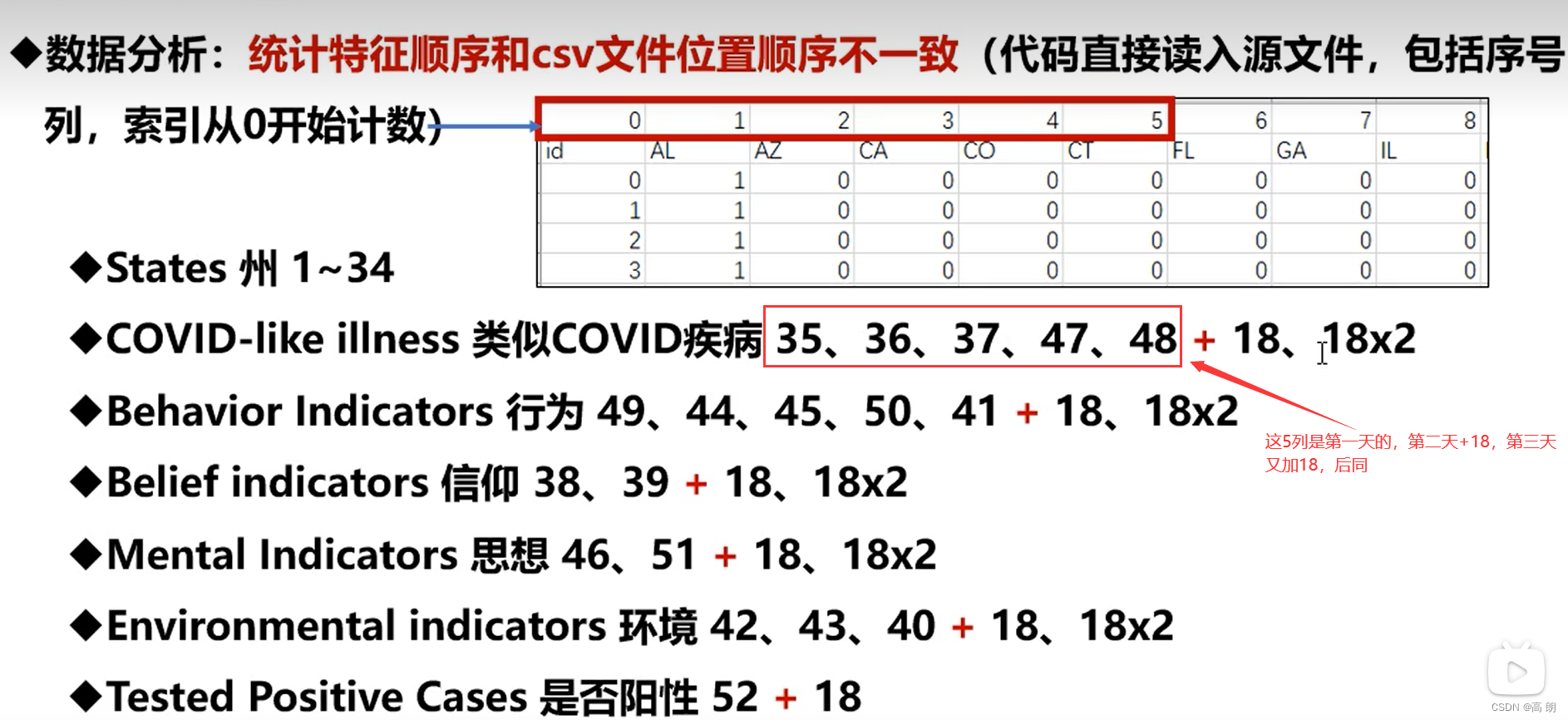
数据相关特征feature
- States(34, encode to one-hot vectors) 34个州
- COVID-like illness(5) 新冠相似疾病
- behavior idicators(5)行为习惯
- belief indicators(2)信仰
- mental indicators (2)精神
- environment indicators (3)环境
- tested postive cases(1)新冠测试阳性分数
输入是34+18+18+17=87维,最后一列是我们需要去预测的
- 文件数据说明:
完成和调参
- Some Utility Functions
def select_feat(train_data, valid_data, test_data, select_all=True):
""" Selects useful features to perform regression
:param train_data: 训练集
:param valid_data: 验证集
:param test_data: 测试集
:param select_all: 是否选择全部feature 默认全部
:return: x-特征属性,y-预测值
"""
# y-最后一列 x-去掉最后一列
y_train, y_valid = train_data[:, -1], valid_data[:, -1]
raw_x_train, raw_x_valid, raw_x_test = train_data[:, :-1], valid_data[:, :-1], test_data
if select_all:
feat_idx = list(range(1, raw_x_train.shape[1]))
else:
# TODO: Select suitable feature columns.
# StatesCOVIDPositive
feat_idx = list(np.array([35, 36, 37, 47, 48, 52])) # 1 day: COVIDPositive
feat_idx += list(np.array([35, 36, 37, 47, 48, 52]) + 18) # 2 day: COVIDPositive
feat_idx += list(np.array([35, 36, 37, 47, 48]) + 36) # 3 day: COVID
feat_idx.sort()
return raw_x_train[:, feat_idx], raw_x_valid[:, feat_idx], raw_x_test[:, feat_idx], y_train, y_valid
def same_seed(seed):
""" Fixes random number generator seeds for reproducibility.
:param seed: 确保每次的随机种子都相同
"""
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
def train_valid_split(data_set, valid_ratio, seed):
"""
Split provided training data into training set and validation set
:param data_set: 数据集
:param valid_ratio: 验证集占总个数据集的比例
:param seed: 随机种子
:return:
"""
valid_set_size = int(valid_ratio * len(data_set))
train_set_size = len(data_set) - valid_set_size
train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size],
generator=torch.Generator().manual_seed(seed))
return np.array(train_set), np.array(valid_set)
def predict(test_loader, model, device):
"""
进行预测
:param test_loader: 测试数据集
:param model: 模型
:param device: gpu还是cpu
:return:
"""
model.eval() # Set your model to evaluation mode.
preds = []
for x in tqdm(test_loader):
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
preds = torch.cat(preds, dim=0).numpy()
# 保存好每次验证的结果
save_pred(preds, os.path.join(config['result_path'], 'result.csv'))
return preds
def save_pred(preds, file):
''' Save predictions to specified file '''
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
- 网络模型和数据预处理
# 网络模型
class SimpleModel(nn.Module):
def __init__(self, input_dim):
super(SimpleModel, self).__init__()
# TODO: modify model's structure, be aware of dimensions.
self.layers = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
class COVID19Dataset(udata.Dataset):
'''
x: Features.
y: Targets, if none, do prediction.
'''
def __init__(self, x, y=None):
if y is None:
self.y = y
else:
self.y = torch.FloatTensor(y)
self.x = torch.FloatTensor(x)
def __getitem__(self, idx):
if self.y is None:
return self.x[idx]
else:
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)
- train
def trainer(train_loader, valid_loader, model, config, device, loss_csv):
criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.
# Define your optimization algorithm.
# TODO: Please check https://pytorch.org/docs/stable/optim.html to get more available algorithms.
# TODO: L2 regularization (optimizer(weight decay...) or implement by your self).
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.7)
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = []
# tqdm is a package to visualize your training progress.
train_pbar = tqdm(train_loader, position=0, leave=True)
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x)
loss = criterion(pred, y)
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
# Display current epoch number and loss on tqdm progress bar.
train_pbar.set_description(f'Epoch [{epoch + 1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record) / len(loss_record)
model.eval() # Set your model to evaluation mode.
loss_record = []
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record) / len(loss_record)
print(f'Epoch [{epoch + 1}/{n_epochs}], Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
loss_csv.write('Epoch [{:04d}/{:04d}], Train loss: {:.4f}, Valid loss: {:.4f}\n'.format(
epoch + 1, n_epochs, mean_train_loss, mean_valid_loss))
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['model_path']) # Save your best model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return
- main
def main():
same_seed(config['seed']) # 得到一个随机数种子
# 创建文件夹
if not os.path.exists(config['result_path']):
os.makedirs(config['result_path'])
# 创建需要保存的loss文件
loss_csv = open(os.path.join(config['result_path'], 'loss.csv'), 'a+')
loss_csv.write(
"N_epochs:{}, Batch:{}, Init_lr:{}\n".format(config['n_epochs'], config['batch_size'], config['learning_rate']))
# 读取训练集
train_data, test_data = pd.read_csv('./data/covid_train.csv').values, pd.read_csv('./data/covid_test.csv').values
# 把训练集分成 训练集+数据集
train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed'])
# Print out the data size.
print(f"""train_data size: {train_data.shape}
valid_data size: {valid_data.shape}
test_data size: {test_data.shape}""")
# Select features
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])
# Print out the number of features.
print(f'number of features: {x_train.shape[1]}')
loss_csv.write("Number of features:{} \n".format(x_train.shape[1]))
train_dataset, valid_dataset, test_dataset = COVID19Dataset(x_train, y_train), \
COVID19Dataset(x_valid, y_valid), \
COVID19Dataset(x_test)
# Pytorch data loader loads pytorch dataset into batches.
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)
model = SimpleModel(input_dim=x_train.shape[1]).to(
device) # put your model and data on the same computation device.
print('Parameters number is {}'.format(sum(param.numel() for param in model.parameters())))
loss_csv.write('Parameters number is {} \n'.format(sum(param.numel() for param in model.parameters())))
trainer(train_loader, valid_loader, model, config, device, loss_csv)
predict(test_loader, model, device)
if __name__ == '__main__':
main()
print(torch.__version__)







![计算机视觉与深度学习-卷积神经网络-卷积图像去噪边缘提取-图像去噪 [北邮鲁鹏]](https://img-blog.csdnimg.cn/364f66a79e0546ddafbdcdc104d4fea0.png)