本文整理自阿里云研发工程师刘大龙(风离),在 Streaming Lakehouse Meetup 的分享。内容主要分为三个部分:
- Flink Batch on Paimon 挑战
- Flink Batch 核心优化
- 后续规划
点击查看原文视频 & 演讲PPT
一、Flink Batch on Paimon 挑战
众所周知,Paimon 在创立之初就是为了解决流式数仓场景的问题。从下面的架构图里我们可以看到,这里有 Flink CDC 的高效入湖,Flink SQL 进行流式、批式的 ETL、Ad-hoc 分析,用一套引擎完成数据的入湖、分析与查询,整个架构上非常简洁,语义统一,解决了传统 lambda 架构下实时离线的数据一致性问题。
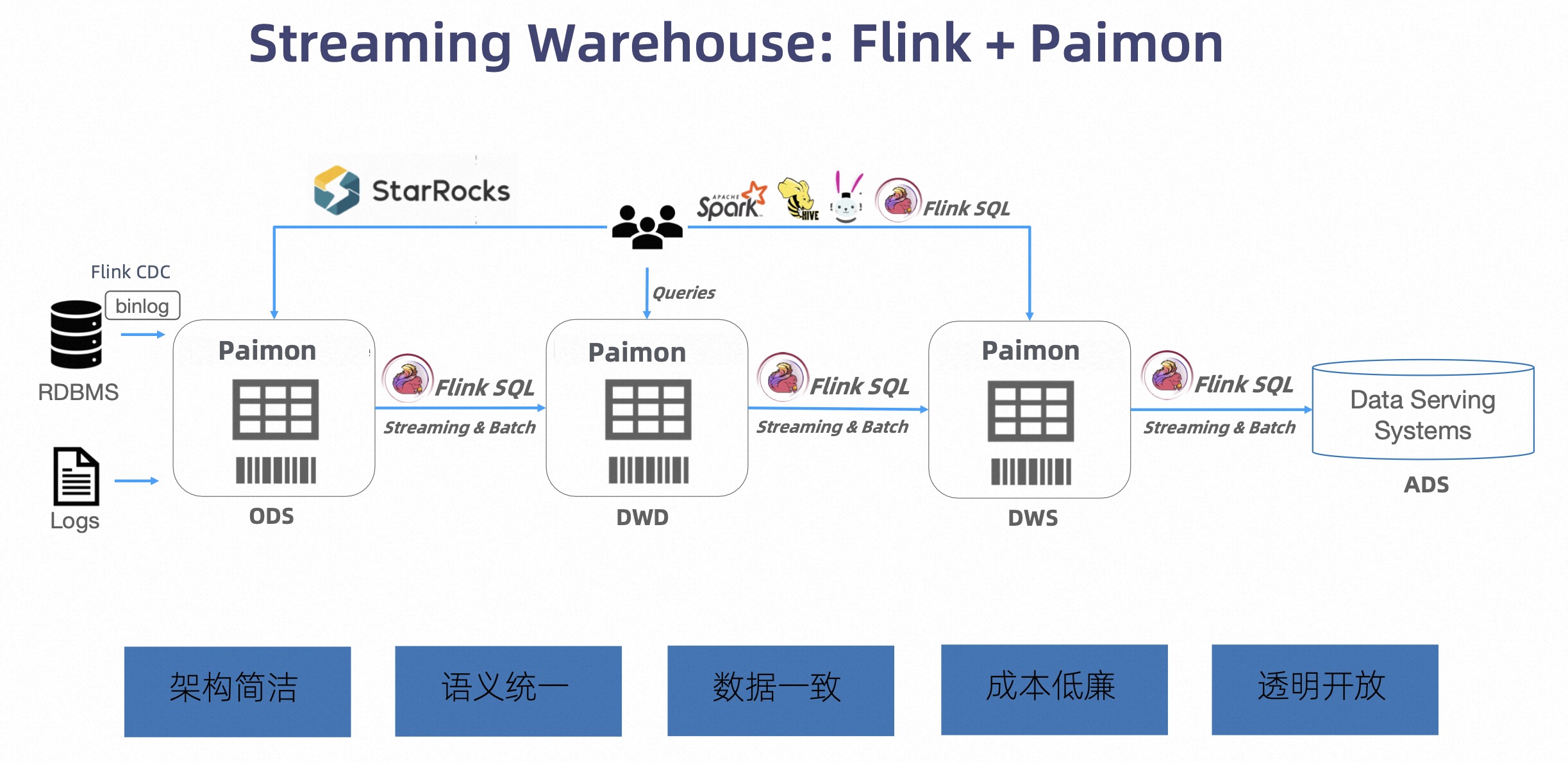
Flink 作为一个流批一体的计算引擎,天生就具备上述能力。
作为流计算引擎,Flink 已经是业界的事实标准;在批处理领域,Spark 是业界的事实标准,Flink Batch 虽然整体能力上不差,但是如果想在数据湖分析场景占据一席之地,确实还面临一些挑战。针对 Flink + Paimon 构建流式数仓场景的需求,我们对 Flink Batch 可能存在的问题进行了总结,主要有如下几个方面:
- Flink 如果作为一个流计算引擎,对于 Schema 变更是没有强需求的,但是和存储结合之后,就需要不断完善这类 API,补齐相关能力;
- 在数据湖场景,会存在行级的数据更新、删除等需求;
- 一般湖上的数据都是有版本的,每次的写入与更新,可能都会产生一个新的 Snapshot,因此我们也需要对 Sanpshot 进行管理,比如通过 CALL 命令清理过期 Snapshot,时间旅行查询;
- 除了数据管理方面的需求,另外一个重要的挑战就是如何通过 Flink Batch 对湖上数据进行高效的 ETL&Ad-hoc 分析,同时还要保证稳定性。
针对这些挑战,从 1.16 版本社区开始投入大量精力对 Flink Batch 做了诸多方面的优化。
二、Flink Batch 核心优化
在介绍 Flink Batch 核心优化之前,首先我们按版本主线回顾一下过去三个版本分别做了哪些重要的功能。

- Flink 1.16 从易用性、稳定性、性能方面做了诸多改进,包括 SQL Gateway、统计信息增强、Join Hint、动态分区裁剪等,该版本是 Flink 批处理里程碑式的版本,也是走向成熟的重要一步。
- Flink 1.17 持续在批处理方面对性能、稳定性和可用性方面做了显著的改进,包括 Update&Delete API 完善,引入新的 Join Reorder 算法改进 Join 性能,自适应的批处理调度器成为默认的调度器,用户不再需要关心作业并行度等。
- Flink 1.18 社区继续投入大量精力优化 Batch,完整的支持了湖存储上需要的各类 API,Gateway 支持 JCBC Driver,在执行层面做了 Runtime Filter,多算子融合 CodeGen 等持续优化算子性能。
2.1 Lakehouse API 增强
Flink SQL 在 API 设计这块之前更多的是面向流场景,批场景或数据分析场景的很多 API 都没有考虑也没有去做。从 1.16 版本开始增强这方面的 API,以提供更好的数据管理能力。

在数据湖场景中,Schema Evolution 是一个比较常见的需求。于是,我们在 API 层面增强了这些方面的能力,包括支持了各类变更 Schema 的 DDL。在建表方面,我们也支持了 Create/Replace Table As Select 语法,可以直接基于源表简单高效的创建目标表,同时把数据导入到目标表里。

其次,增强了数据湖的数据管理相关 API,在时间旅行查询、数据更新和删除、CALL 命令等方面都有所加强。综上所述,Lakehouse API 主要是围绕着数据湖分析场景做了完善了诸多功能。
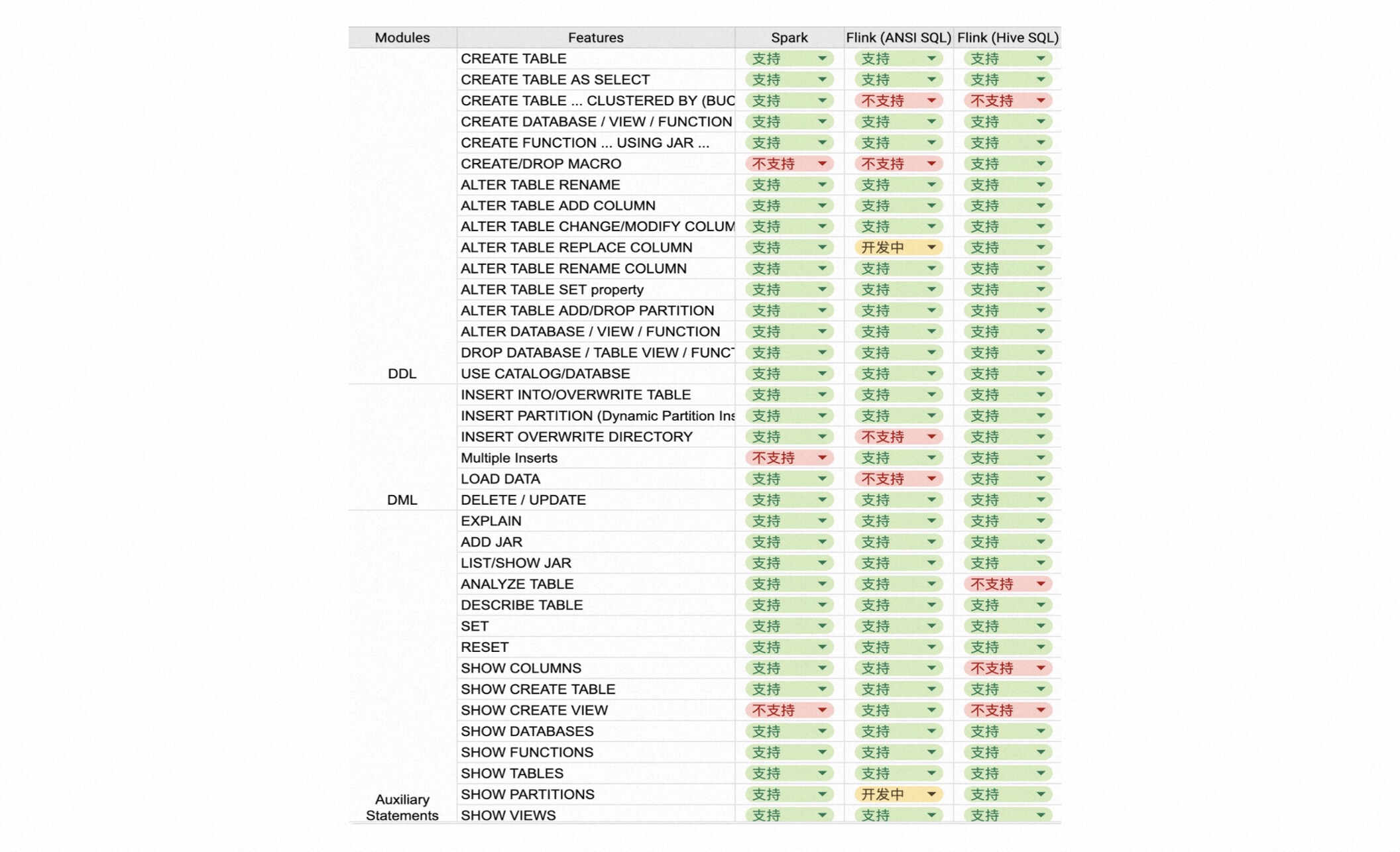
下面是 Flink 和 Spark 在 API 方面的对比图,这里把其分为 DDL、DML 和 Auxlilary Statements 三类,从图中可以看出,Flink Batch 已经基本追平 Spark。API 上已经比较完善,用户可以尽情的把 Flink Batch 用起来。
2.2 Join 优化
当 Flink Batch 易用性方面比较完善之后,那么用的好不好、稳不稳、快不快,就是下一个需要关注的点。
Join 是我们在业务中遇到的最多的场景,尤其是数仓大宽表的场景,可能存在几十个表进行 Join。根据笔者之前做业务的经验来看,很多时候报表出不来,都是因为上游的 Join 太慢。因此对于很多的计算引擎,Join 算子是重点优化的部分。

如果想让 Join 执行的快,前提是需要有丰富的统计信息。统计信息对优化器来说非常重要,只有拥有足够丰富的统计信息,它才能优化出高效的执行计划来。所以,我们首先要做的是针对统计信息的优化,这可以通过两步完成。
- 第一,通过 Analyze Table 语法来做,用户写一个分析统计信息的 SQL,其会转化成 Flink Batch 作业,查询物理存储生成所需的统计信息,然后写回到 Catalog 中。
- 第二,通过 SuppotReportStatistics 接口来获取,由 Format 或是湖存储来实现这个接口,优化器优化的过程中如果从 Catalog 中拿不到统计信息,那么就可以通过这个接口实时收集统计信息,然后再基于收集到的统计信息进行执行计划的优化。在 Flink 内置的 Format 中,Parquet 和 ORC 等列存格式已支持,另外 Paimon 也已支持。
如果遇到无论用以上哪种方式都拿不到统计信息时,该如何让优化器给出一个合理的 Join 策略呢?这种情况下,在业界也有成熟的解决方案,那就是 Join Hint。
在介绍 Join Hint 之前,先介绍下 Flink Batch Join 底层的算子实现策略。
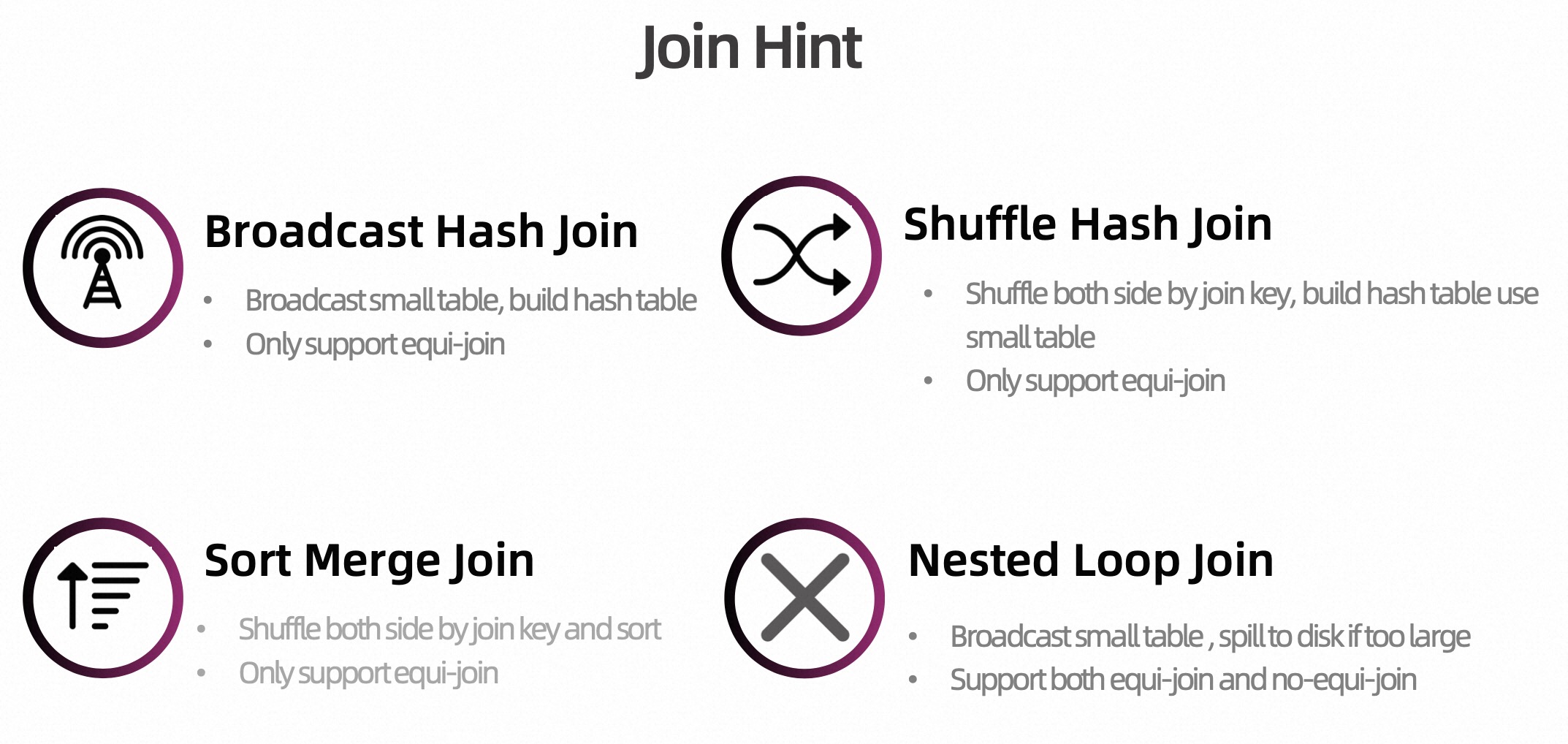
如上图所示,一共有四种 Join 策略,也是业界主流计算引擎采用的 Join 策略。
当统计信息准确的时候,基于 CBO 的优化器是可以给出比较优的执行计划。但是在无统计信息或者统计信息不准时,优化器可能选择出错误的 Join 策略,导致 Join 执行的很慢,或者无法执行成功。针对这种情况,一种解决办法是 Join Hint。在 FLIP-229 中 Flink 提供了 4 种 Join Hint,与上文提到的四种 Join 策略一一对应,每种 Join 策略都有对应的 Hint 策略。具体如下:
- BROADCAST
- SHUFFLE_HASH
- SHUFFLE_MERGE
- NEST_LOOP

介绍完 Join Hint 之后,来介绍下 Join 可能存在的另外一个问题,即多表 Join。针对多表 Join,需要优化器能选择出一个比较优的执行计划,这样才能提高执行效率。

以上图 TPC-DS q18 为例,它涉及到了 6 张表的 Join,大表是 catalog_sales 和 customer 相关的一些表,除此之外还有一些小维表等。我们的目标是针对这几张表,通过 Join Reorder 算法,让 Join 顺序相对合理,从而使得 Query 的执行效率最高。
目前,Flink 默认采用了基于左深树的 Join Reorder 算法。针对 q18 这个例子,其优化出来的执行计划如下图所示。
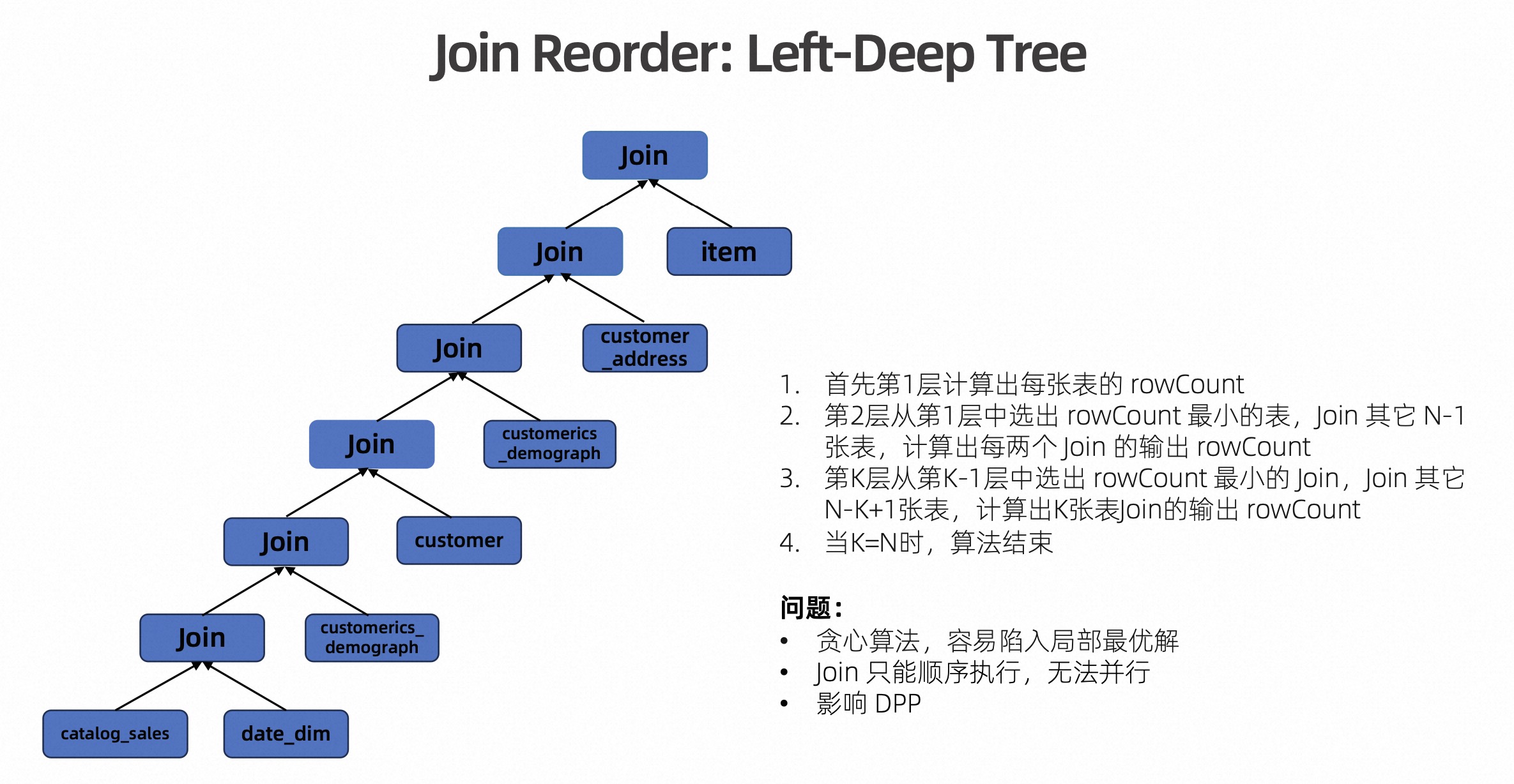
什么是左深树呢?左深树如上图所示是二杈树,它的右侧是叶子节点。也就是说先用 catalog_sales 和 date_dim 两个小表进行 Join,输出的 Row Count 是最小的,然后再和剩余的表一一进行比较,然后再选出输出 Row Count 最小的表进行 Join,以此类推。
这是一种贪心的算法,也就是每次 Join 都只看到当前最优的 Join 顺序,然后再继续往后 Join。左深树算法虽然搜索空间小,优化速度很快,但是存在几个问题:首先是很容易陷入局部最优,二是只能按顺序执行,一定只能从左侧最小面的 Join 开始执行。所以当资源比较充足的时候,导致资源利用率不高。另外,左深树算法还会对动态分区裁剪有一定影响,导致某些表无法应用上动态分区裁剪。
基于以上存在的问题,我们在 Flink Batch 1.17 中引入了基于稠密树的 Join Reorder 算法,如下图所示。
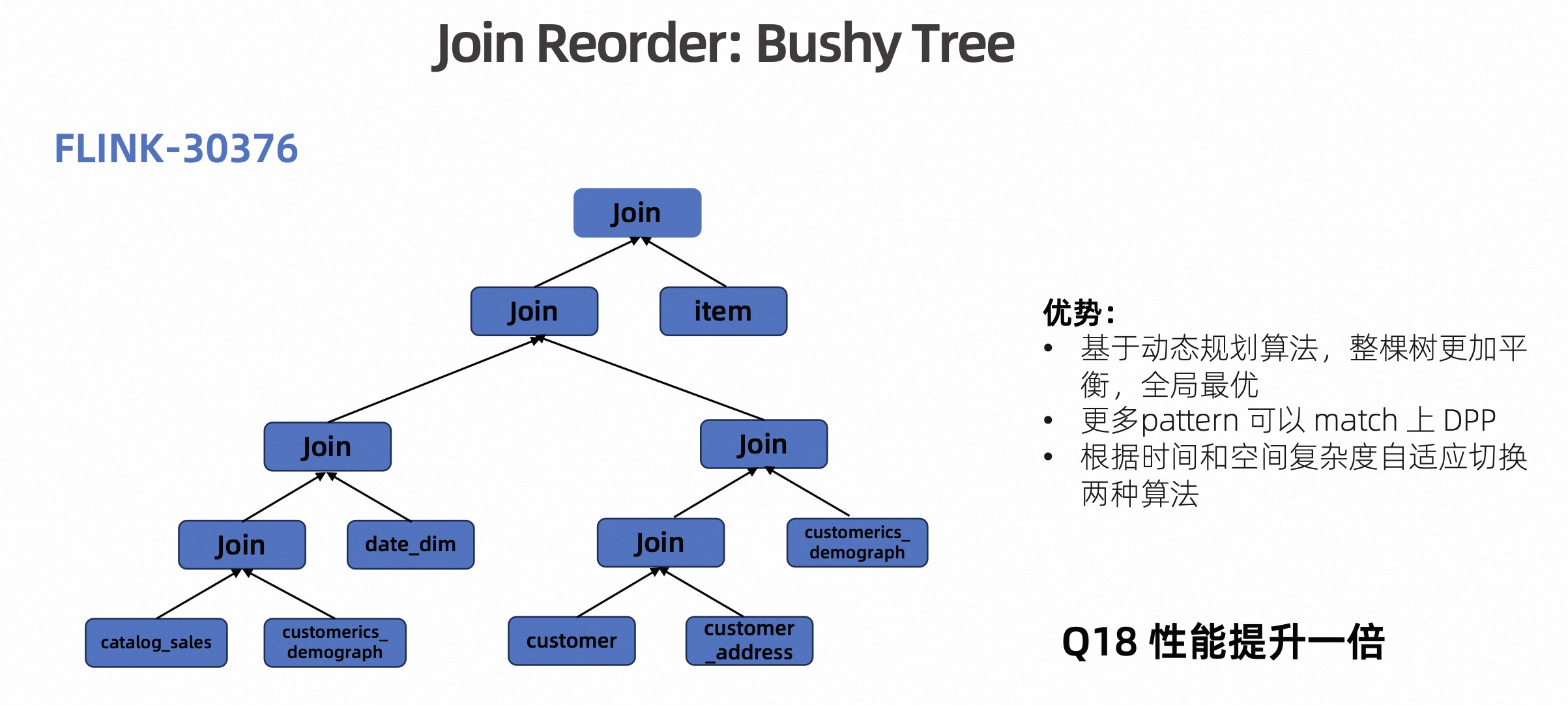
针对 Q18 这个例子,基于稠密树算法优化出来的执行计划树已经比较平衡了。在 Join 的过程中,catalog_sales 表并不是先和 date_dim 这个维表做 Join,因为它采用的是动态规划的算法,也就是全局枚举,不会只考虑当前的最优,而是全局最优,这就大大提高了 Join 的效率,Q18 的性能提升了一倍以上。
总结来讲,左深树算法是贪心的,不用枚举所有的执行计划,所以速度比较快;稠密树算法基于动态规划,搜索的空间更大,也更费时间。这两种算法分别适用于不同复杂度的业务场景,也各有优缺点,目前优化器会综合考虑 Query 复杂度和优化耗时,在两个算法之间做自适应的切换。
对于 Hive 数仓或是数据湖分析场景,很多时候我们会遇到分区表 Join。对于该类场景,我们是可以在执行层进行优化,比如少读一些不必要的分区,这样就可以大大减少 Join 所需的数据量。
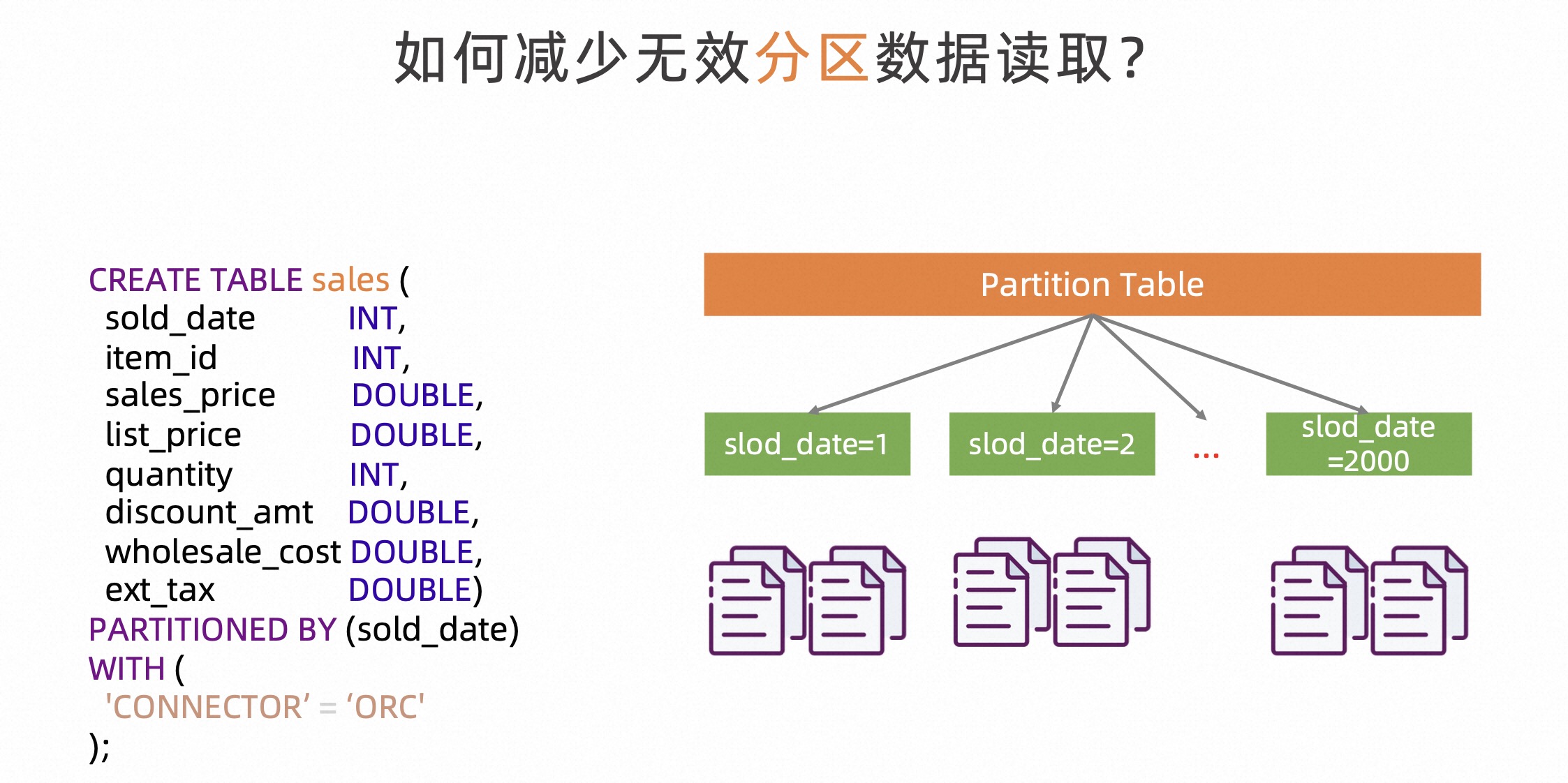
下面介绍如何减少无效分区数据读取。
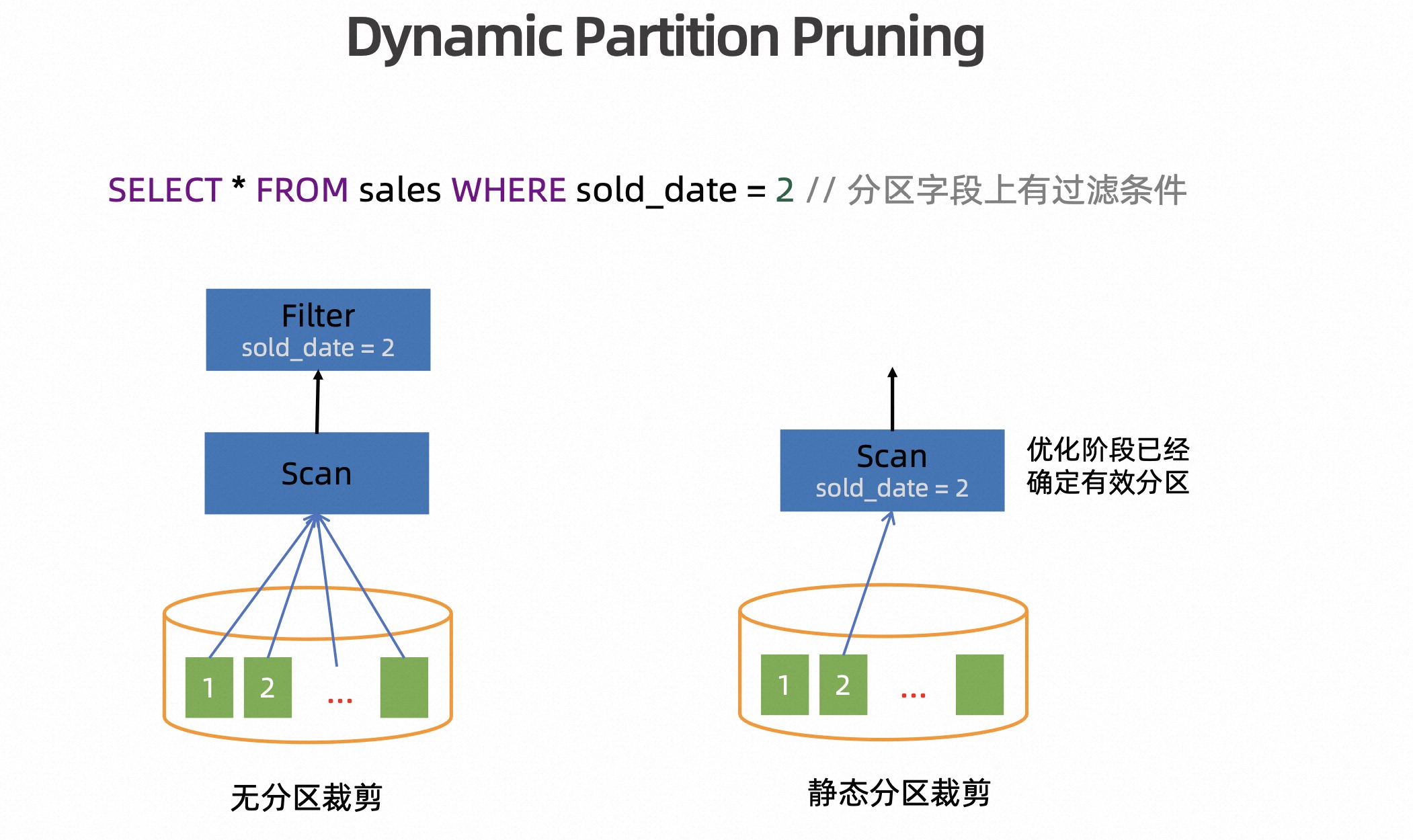
对于分区表裁剪,有两种方法,分别是静态分区裁剪和动态分区裁剪。静态分区裁剪要求在 Query 里面一定要指定分区的过滤条件,这样才能在优化阶段裁剪掉。另外一种情况是,没有具体指定哪个分区,但是在 Join 过程中,可以根据维表里数据动态确定要读取的分区,从而动态的进行分区裁剪。
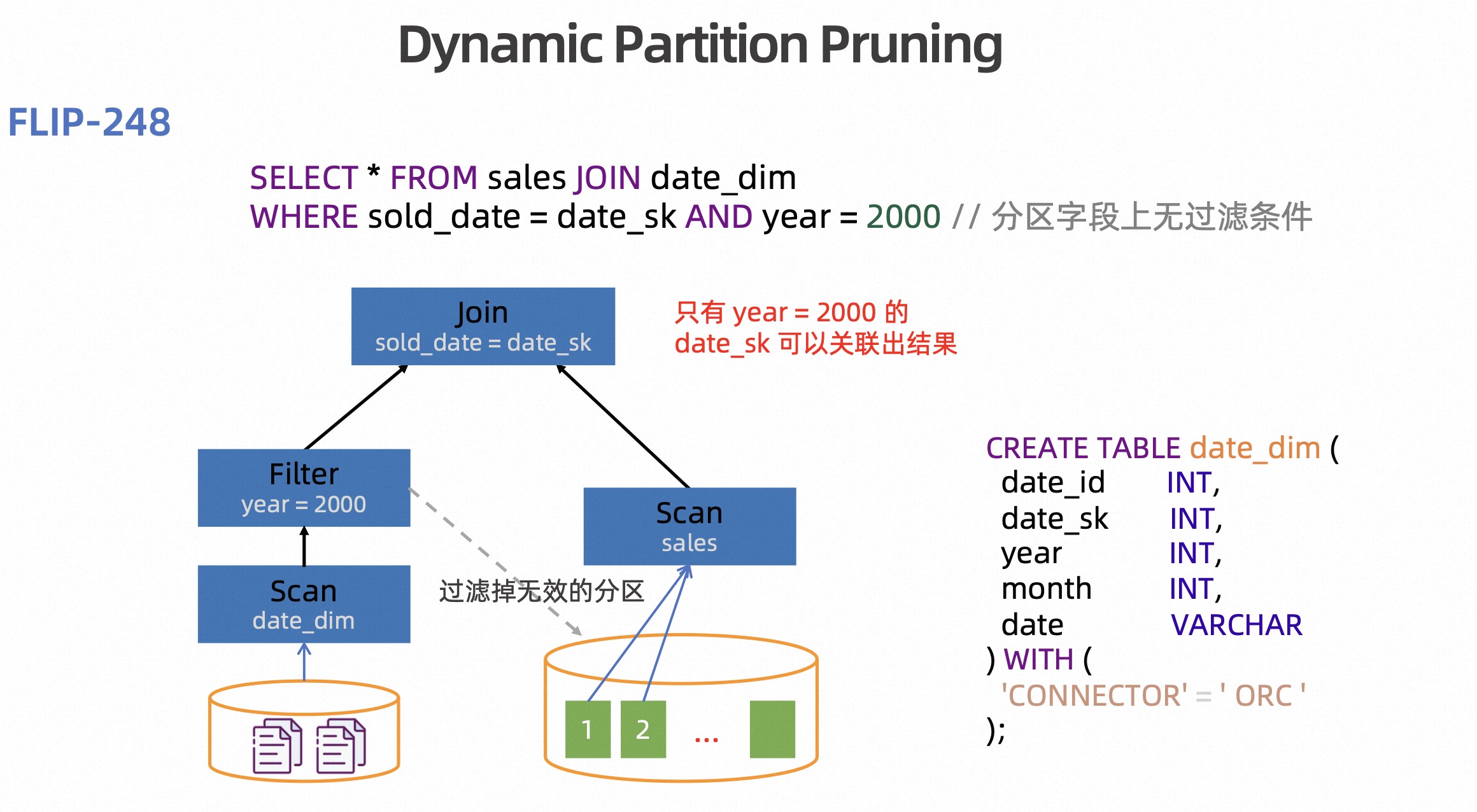
在 FLIP-248 中,提出并引入了动态分区裁剪优化。如下图所示,sold_date 是分区表的分区字段,但是并没有指定读哪些分区。但是在 date_dim 维表中,有“year=2000”这个过滤条件,通过这个条件,在运行时就可以确定需要读取的分区信息,对于不需要读取的分区可以直接过滤掉,减少无效数据量。
前面是针对分区表 Join 的优化,那么如果 Join 条件中没有带分区字段,是否也可以减少 Join 需要处理的数据量?事实上针对这个问题也有成熟的解决方案 Runtime Filter,其核心思路是减少 Join 大表侧需要 Shuffle 的数据量。
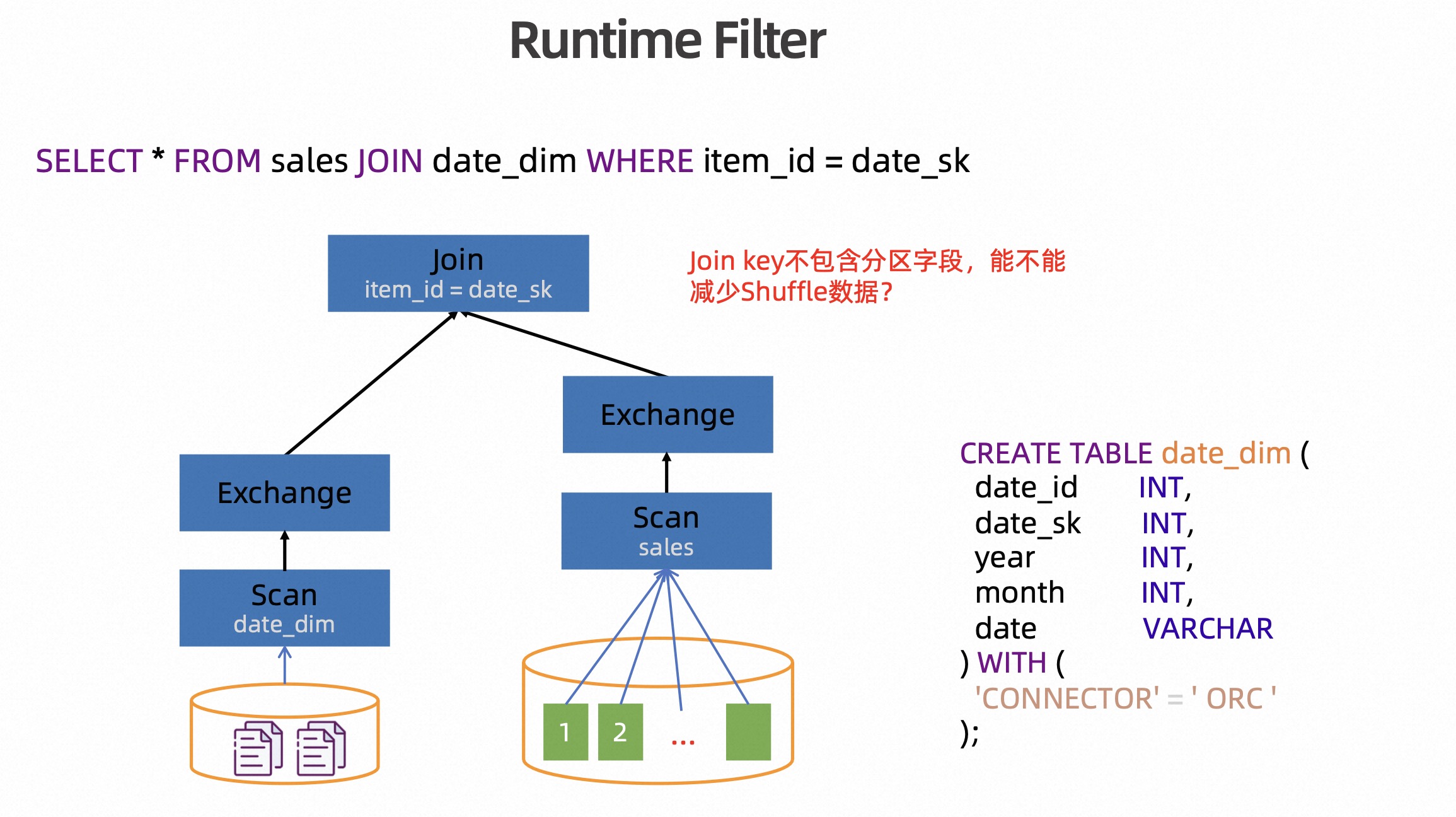
如上图所示,sales 表 Join date_dim 表,item_id 字段是 Join 的等值条件,但是其并不是分区字段,那我们是没法做动态分区裁剪的。虽然没法做动态分区裁剪,但在运行时读取完维表的数据后,我们是可以拿到 item_id 的集合,通过其来减少大表侧需要 Shuffle 的数据量。
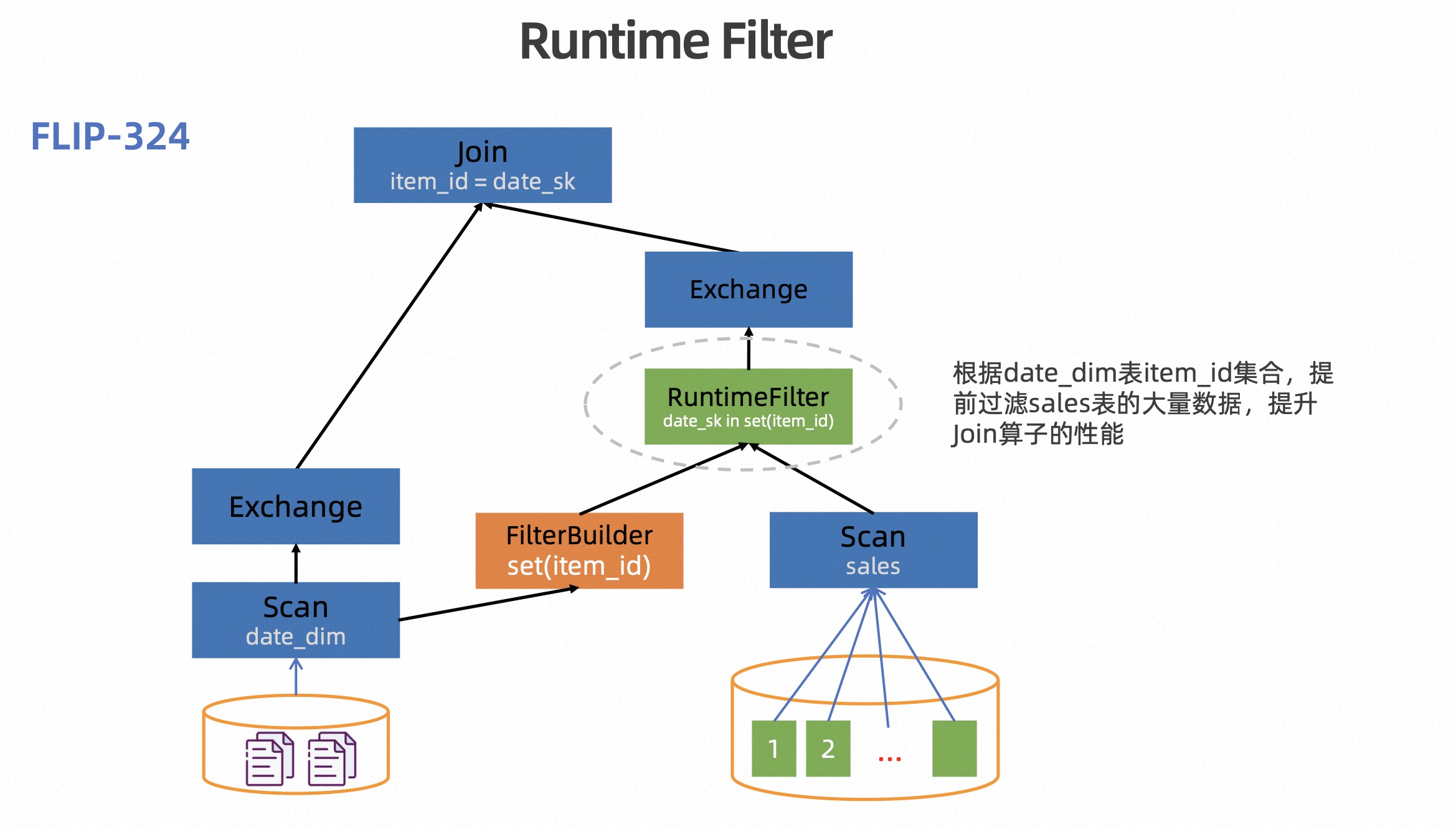
在 Flink 1.18 版本中,该功能默认是关闭的,大家可以通过 table.optimizer.runtime-filter.enabled 参数打开。
2.3 Runtime 优化
除了上文介绍的 Join 层面的优化,在执行层面也进行了一些优化。这里介绍两个核心的优化,第一个是 Operator Fusion CodeGen,第二个是 Adaptive Batch Scheduler。
(1)Operator Fusion CodeGen
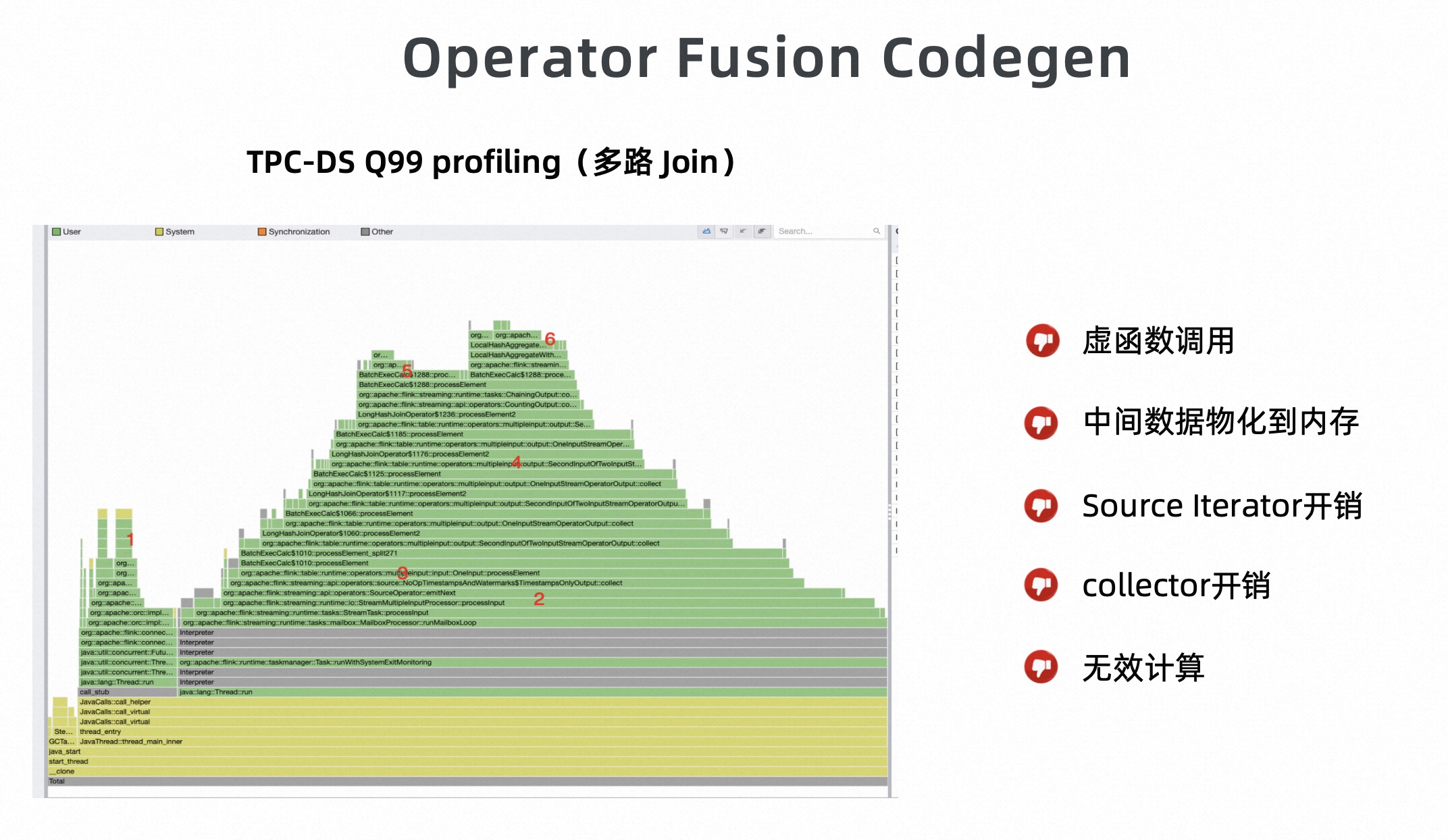
首先我们从一个具体问题切入,来看一下为什么要做 Operator Fusion CodeGen。在跑 TPC-DS 的过程中,对相关 Query 进行 profie 分析的时候,我们从中发现了一些问题。下图是 Q99 的火焰图,通过该图可知,在多次 Join 的过程中,CPU 时间消耗的很分散,有很多无效的 CPU 计算,主要包括下面几个方面:
- 虚函数调用开销;
- 中间数据物化到内存的开销;
- Source Iterator 开销;
- 多个算子之间的通过 collector 传递数据的开销;
- 其他无效计算开销。
这些框架和算子层面的开销其实是可以省掉的,从而提升 Query 的执行效率。因此我们可以从下面几点进行优化:
- 尽量避免内存访问,数据驻留在寄存器中;
- 消除虚函数调用;
- 编译执行,面向每个 Query 生成最优的代码,执行效率会更高;
- 从 Source 读完数据之后,用一个 For 循环去处理;
- 延迟计算。
针对上述优化点,一种成熟的解决方案是 Operator Fusion CodeGen。那什么是 Operator Fusion CodeGen 呢,简称多算子融合 CodeGen,来自于托马斯-诺依曼的论文,其核心思路是把多个算子的代码通过 produce-consume 接口融合到一起,每个算子只生成一部分代码片段,最后把所有算子的代码片段拼接组装在一起,最终只生成一个算子,该算子包含了原来所有算子处理数据逻辑的代码。

Operator Fusion CodeGen 核心目标就是尽量把整个 Query 的多个算子通过 CodeGen 的方式编译组装到一个函数或是一个算子里,这样就能尽可能的消除一些冗余的代码和计算,让整个 Pipeline 的数据处理更加高效。
在 FLIP-315 中,我们为 Flink 引入了这个优化,目前支持了 Calc、HashJoin、HashAgg 算子。当前还是个实验性质的功能,默认是关闭的,用户可以通过参数 table.exec.operator.fusion.codegen 打开。
(2)Adaptive Batch Scheduler
Adaptive Batch Scheduler 是另外一个优化,这个在 Flink 1.15 版本中就已经引入了,它解决的是批作业并行度设置的问题。
在流场景中,设置并行度是很正常的事情。但是对于批作业来讲,每天的数据量都可能在变化,而且批作业的数量相比流作业会多很多,这就导致我们无法 case by case 的对每个批作业进行并行度调优,因此也就需要具备自动设置并行度的能力。
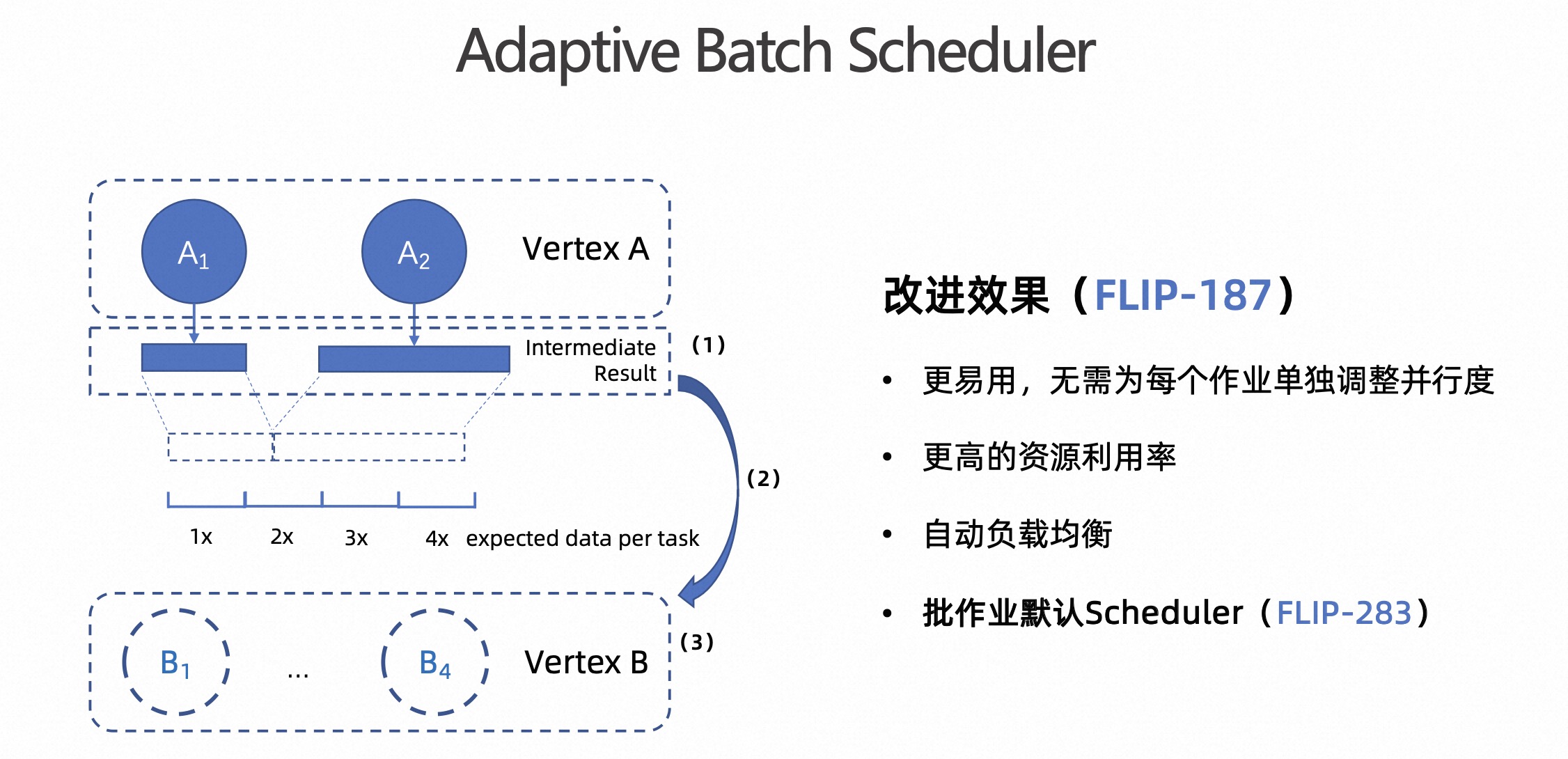
在 Flink 1.17 版本中,我们将 Adaptive Batch Scheduler 设置为批作业默认的 Scheduler,也就是说用户不需要额外去打开这个功能。除了动态设置并发,后续可能会做更深入的 Adaptive Query Execution,可以动态的调整 Join 策略,以及解倾斜等。
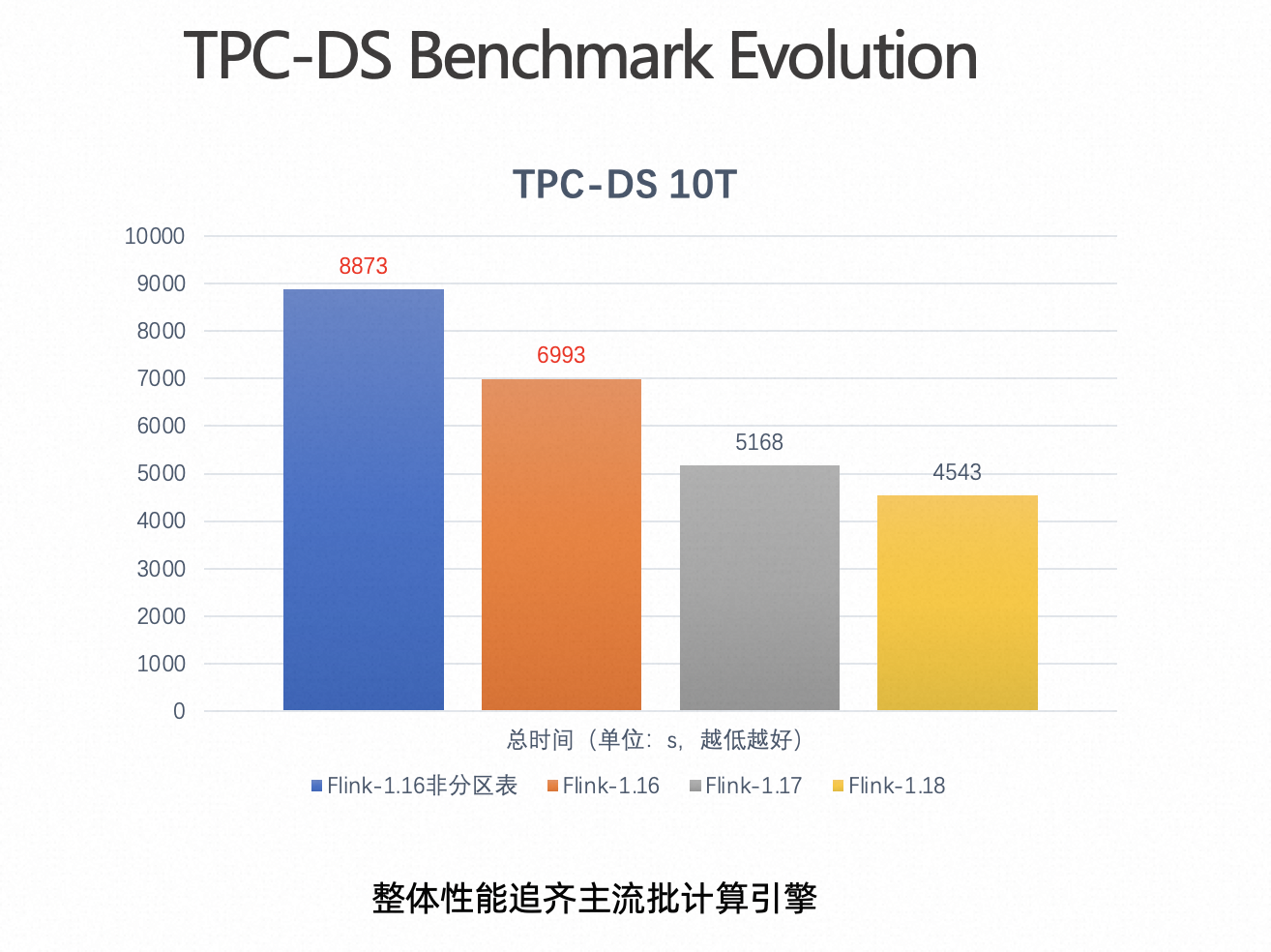
基于上述我们在 QO 和 QE 层面做的优化,Flink Batch 过去几个版本在 TPC-DS 10T 数据集场景下,性能一直在提升,整体时间也已追平主流批计算引擎。
2.4 稳定性优化
除了性能方面的优化,我们也在持续优化 Flink Batch 的稳定性。在稳定性方面,做的第一个优化是 Adaptive Hash Join。
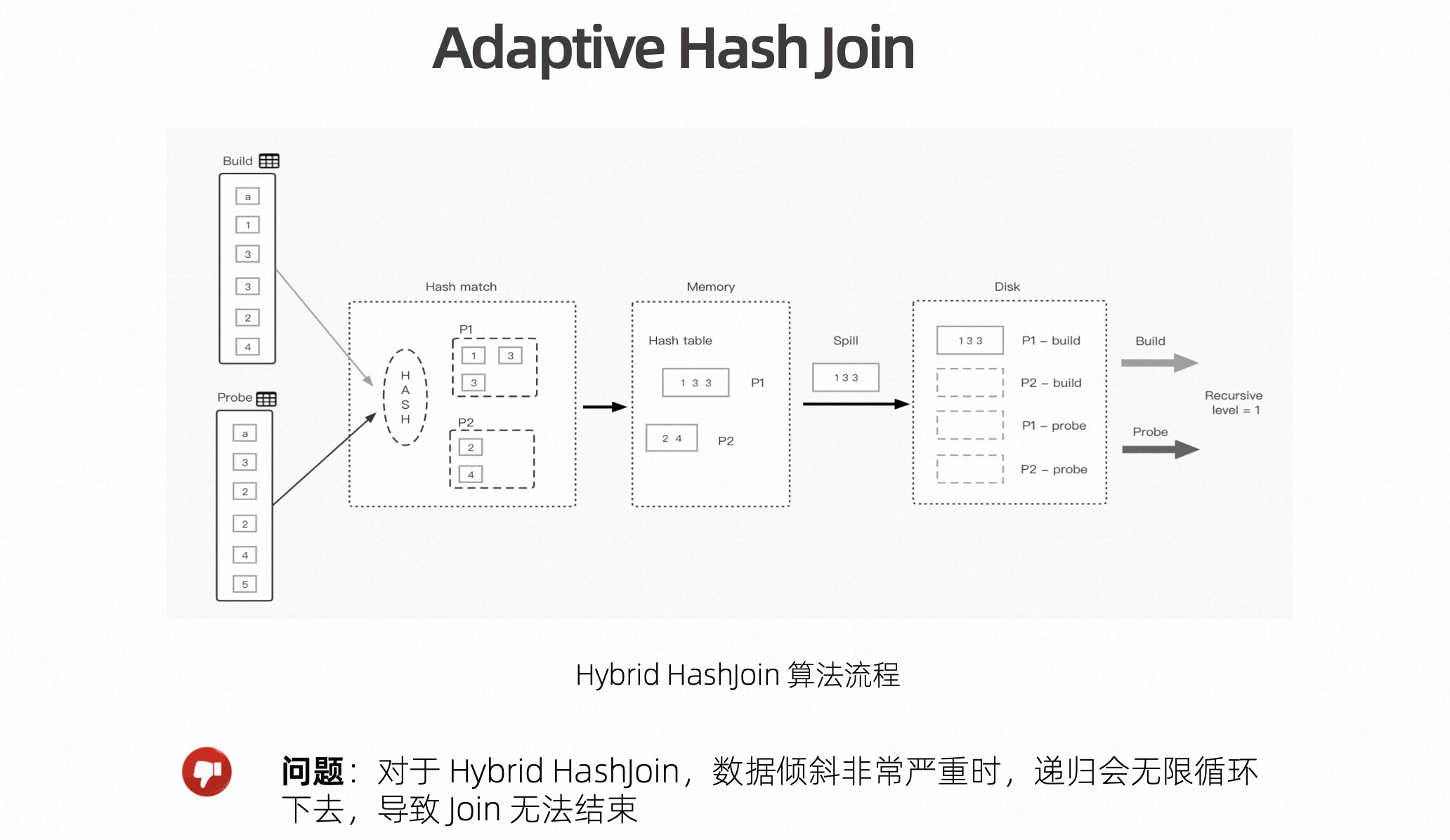
由于一些历史原因,Flink 的 HashJoin 没有选择纯内存版的 Join 算法,而是选择了 Hybird HashJoin 算法。算法的基本思路是根据 Join key 对 build 端先划分 Partition,当内存不够时,会选择当前占用内存最大的 Partition 进行落盘,释放一部分内存;接着构建新的分区。当 probe 端数据来的时候,会判断当前数据对应的 build 端的 Partition 是否在内存中,如果在内存中,则直接 Join。如果不在内存中,则会把 probe 端数据同样落盘,等前面所有内存中的 Partition 处理完之后再来处理,依次递归处理下去。该算法虽然可以避免 OOM,但也存在一个问题,当 Join key 数据倾斜严重,也就是当某个 Partition 数据量特别大的话,递归会无限循环下去,导致 Join 永远都无法结束。
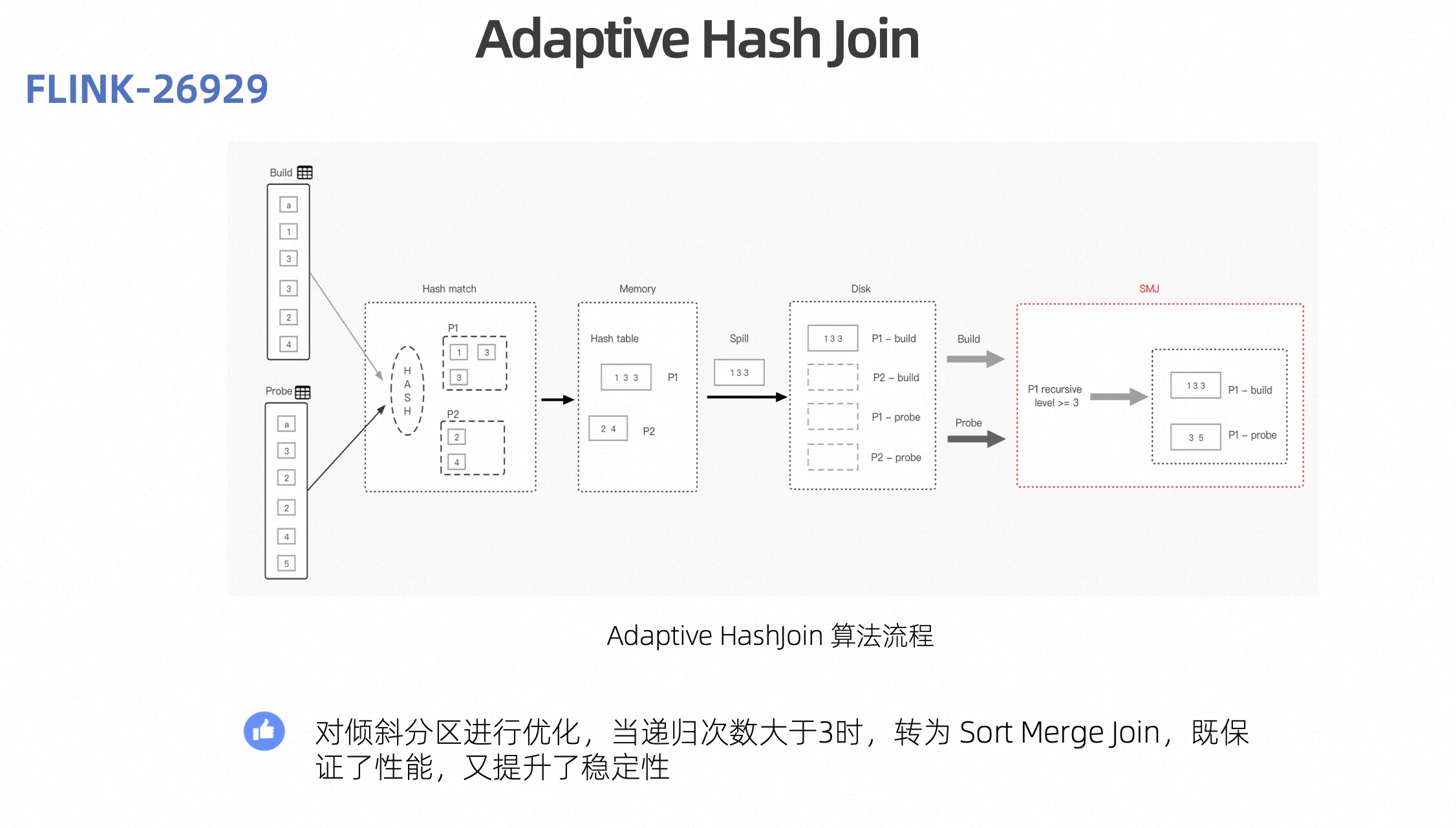
针对这个问题,在 Flink 1.16 版本对倾斜分区进行了优化,即当它的递归次数大于 3 次之后,说明该 Partition 倾斜已经非常严重了,这个时候可以自适应的 fallback 到 Sort Merge Join 策略来处理,我们把这个过程称作 Adaptive Hash Join。Adaptive Hash Join 的核心思路是把内存中可以放的下的 Partition 用 Hash Join 来处理,内存中放不下的 Partition 用 Sort Merge Join 来处理,这样既保证了性能,又提升了稳定性。
Speculative Execution 推测执行
在生产中,很多时候作业是共享集群的,不同的业务跑在同一个集群上,这都可能导致机器热点,使得上面运行的 Flink 任务异常缓慢。这些缓慢的任务会影响整个作业的执行时间,使得作业的产出基线无法得到保障,成为了部分用户使用 Flink 来进行批处理的阻碍。
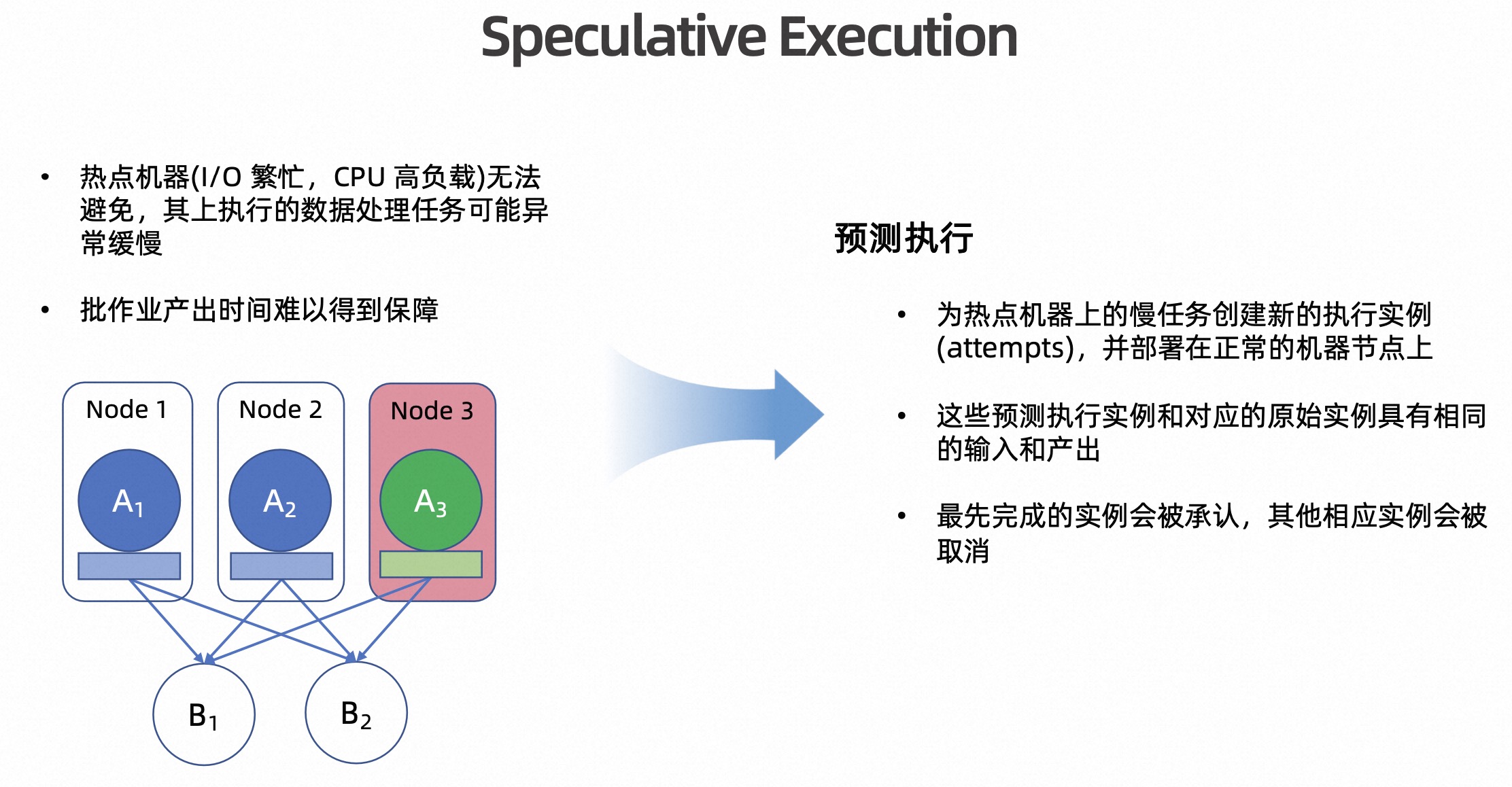
Speculative Execution,也叫推测执行,是一种已经得到普遍的认可、用来解决这类问题的方法,因此我们也在 Flink 1.16 中引入了这套机制。
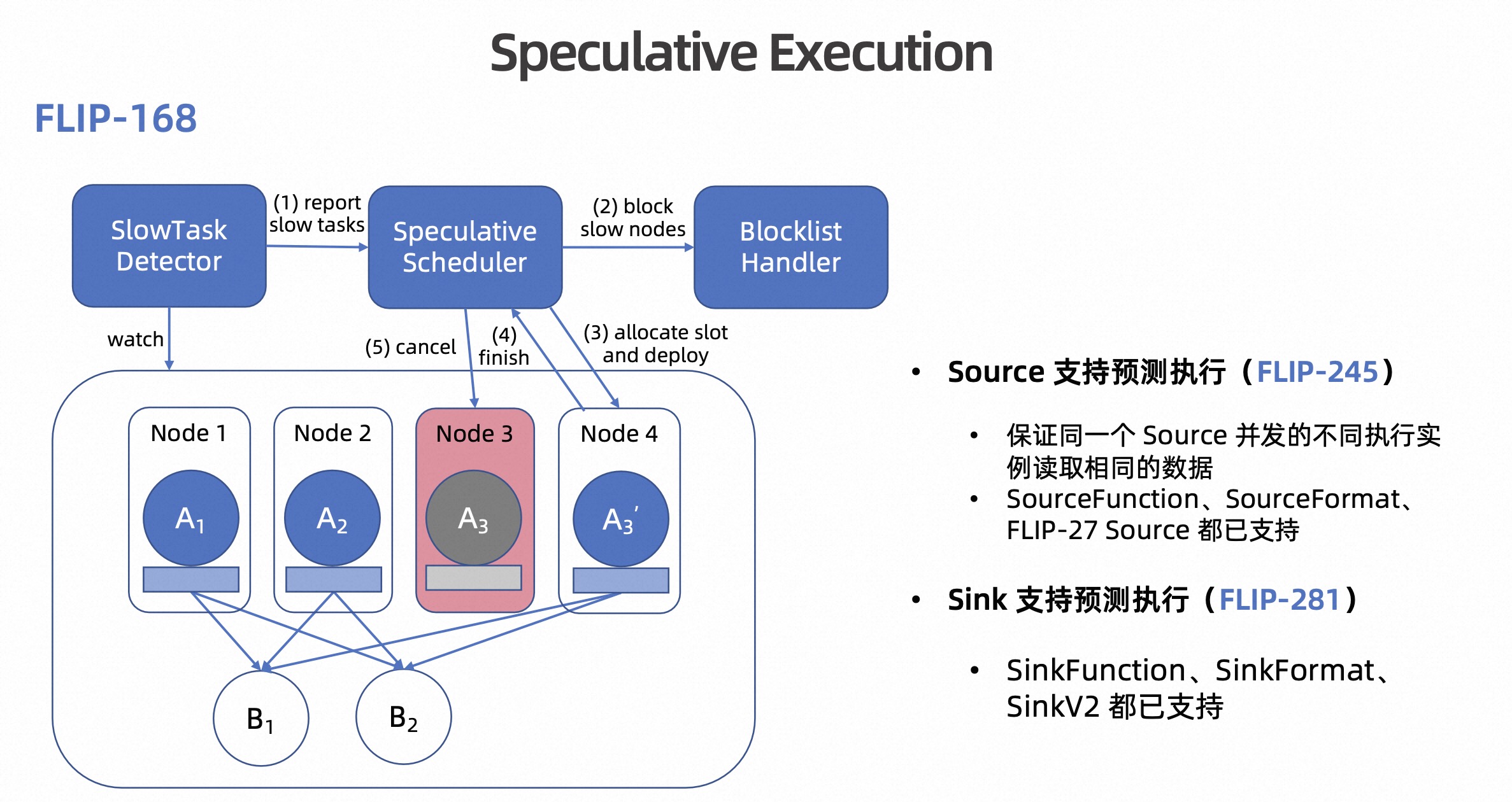
推测执行方案的整体架构如下图所示,在 FLIP-168 中框架层面对内部算子支持了推测执行,在 FLIP-245 里对 Source 实现了支持;在 FLIP-281 中,对 Sink 实现了支持。总而言之,经过多个版本的迭代,推测执行在 Flink Batch 中的支持已经比较完善,用户可以放心的用起来。
2.5 SQL 服务化
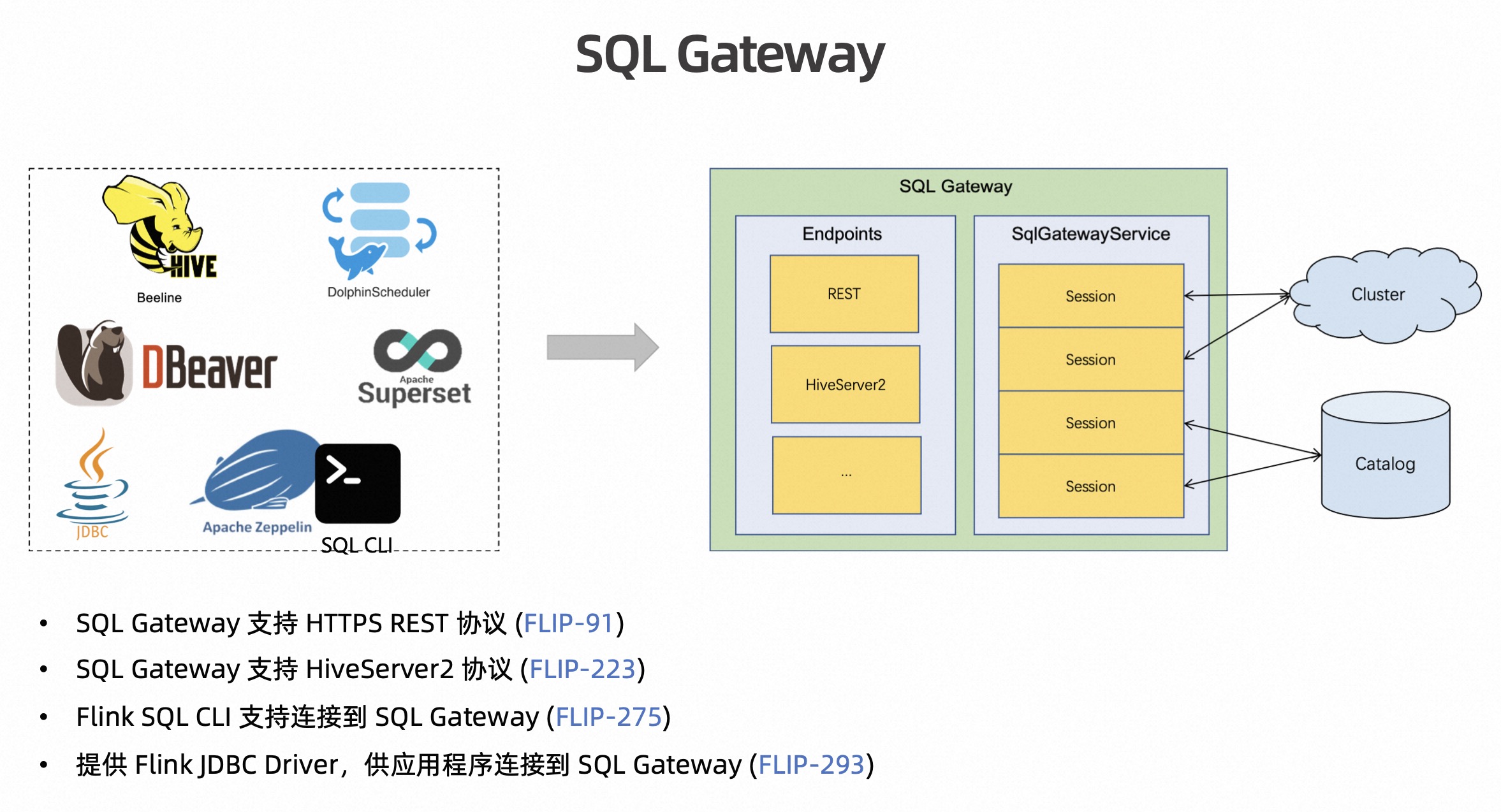
Flink 是一个流批一体计算引擎,Flink SQL 可以满足 Streaming/Batch/OLAP 三类场景的需求。面对这么多不同类的需求,如果有一个统一的 SQL 服务化组件,可以很方便我们提交 SQL、管理作业,不用每个用户都自己去搭一套服务化组件,避免重复开发。另外,其实最早社区在 Github Ververica 组织下提供了 SQL Gateway,后来由于一些原因就没有再持续开发,但社区一直有用户在用。考虑到 Flink Batch 的需求,以及社区用户的呼声,因此在 1.16 版本社区在 Flink 主仓库引入了 SQL Gateway 组件。
SQL Gateway 是一种支持远程多个客户端并发执行 SQL 的服务化网关,其在架构设计上由可插拔的 Endpoint 和 SQLGatewayService 组成,可以支持不同协议,包括 HTTPS REST 协议、HiveServer2 协议,可以兼容不同 SQL 的语法。
基于前置的工作,在 FLIP-275 中,社区对 SQL Client 也进行了重构,把底座统一架在 SQL Gateway 上,这样两者的能力是共享和对齐的,SQL Client 也就更加灵活。
另外社区提供了 Flink JDBC Driver,其兼容老的 SQL Gateway(底层基于 RestClient),并且可以支持用户以 JDBC 的方式提交 Flink 流作业和批作业,这对已有的批作业迁移到 Flink 上也很方便,客户端只需要把 JDBC Driver 换成 Flink 的即可,无需大的改动。
三、后续规划
上文介绍了 Flink Batch 过去三个版本做的一些核心优化,后续我们也会在 Flink Batch 上持续投入,主要会从两个方面去做。首先在引擎层面会持续进行优化,比如继续完善 OFCG、Runtime Filter 等,同时也会考虑去支持 Adaptive Query Execution。

其次,我们会花更多精力在用户落地方面,比如去对接数据湖存储 Paimon、Hudi、Iceberg 等,在新兴数据湖分析场景持续打磨 Flink Batch 引擎。
Q&A
Q:请问 SQL Gateway 在 Flink 社区是否有长线规划?未来是否会跟 Kyuubi 竞争?
A:目前没有这样的计划,因为 SQL Gateway 更多考虑还是面向 Flink 本身。Flink 是流批一体的计算引擎,Gateway 在设计上,更多的兼容了 Flink 流批两种模式。Kyuubi 是一个独立社区,它集成了 Flink SQL,但是主要面向 Hive/Spark 等 Batch 生态,在流模式的服务化上支持的不太完善。从长远来看,社区目前没有将 SQL Gateway 变成独立的外部 Service 组件的计划。
Q:请问通过优化器优化掉的数据,未来是否可以再恢复?
A:如果是基于 CBO 的优化,优化器在优化的过程中产生的 Plan 都是会保留的,只是它最终会根据不同的 Plan 计算 cost,哪个最小就会选哪个。
点击查看原文视频 & 演讲PPT
Flink Forward Asia 2023 正式启动
点击查看活动详情