最近黄金比较火爆,想要获取黄金实时价格,方便后续监控预警价格,一般实时刷新的网页数据都是动态加载的,需要用到selenium自动化测试获取动态页面数据。
昨天学会了获取动态网页小说内容,同理也可以获取动态网页的黄金实时价格。
第一步:先确定目标网址
网上随便百度一下黄金实时价格: 网址地址:'https://gushitong.baidu.com/futures/ab-AU888'
第二步:确定章节目录和内容元素坐标
通过谷歌浏览器F12调试功能可以很快的定位页面元素位置.

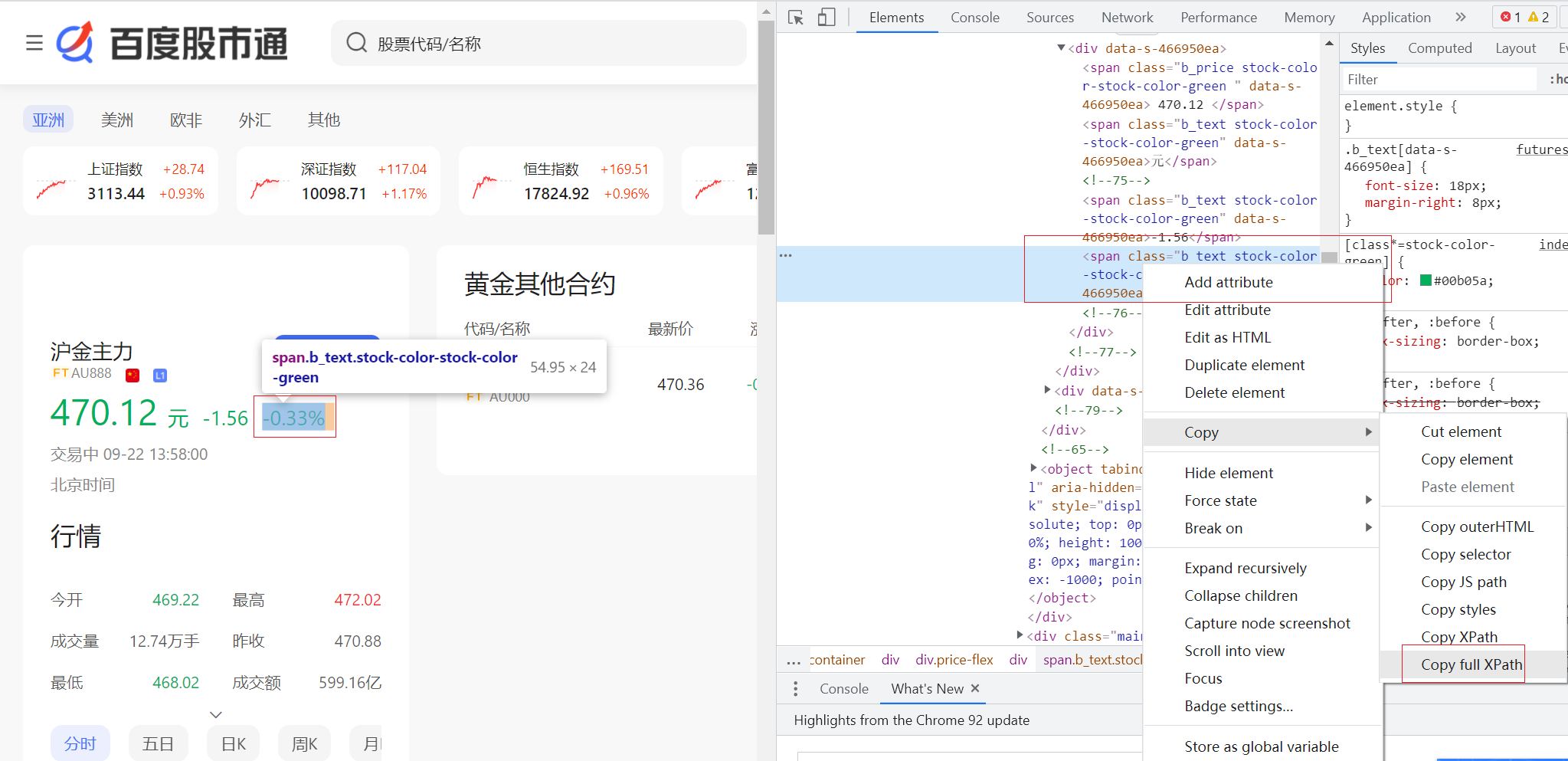
这次定位采用 full XPath 方式,因为该网站通过id或者class属性不好定位,而且采用 full XPath 方式更加方便简单,无需分析元素层级转换格式。
同时采用 selenium 自动化测试工具的浏览器驱动模块访问定位元素值,不再使用bs4库的方式转换取html的元素值。
比如:实时价格,full XPath 值:/html/body/div/div/div/div[1]/div[2]/div/div/div/div[2]/div[1]/div/div/div/div/div[2]/div[1]/div[2]/div[1]/div/span[1]
代码中元素定位取值如下:
# 实时价格,full xpath 定位
real_price_xpath = '/html/body/div/div/div/div[1]/div[2]/div/div/div/div[2]/div[1]/div/div/div/div/div[2]/div[1]/div[2]/div[1]/div/span[1]'
# 实时价格
real_price = driver.find_element(By.XPATH, real_price_xpath).text想要获取其他页面元素值,依次类推即可。
第三步:编写代码
依旧采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块,代码中缺少的封装方法代码,详情参考之前的《selenium自动化测试》文章。
requests_webdriver.py:
def spider_gold_price():
'''
@方法名称: 爬取黄金实时价格
@中文注释: 爬取黄金实时价格
@入参:
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param rsp_dict dict 响应容器
@作 者: PandaCode辉
@创建时间: 2023-09-22
@使用范例: spider_gold_price()
'''
try:
# 返回容器初始化
rsp_dict = {}
# 爬取黄金实时价格,网址
gold_url = 'https://gushitong.baidu.com/futures/ab-AU888'
# 实时价格,full xpath 定位
real_price_xpath = '/html/body/div/div/div/div[1]/div[2]/div/div/div/div[2]/div[1]/div/div/div/div/div[2]/div[1]/div[2]/div[1]/div/span[1]'
# 涨跌百分比,full xpath 定位
ud_percent_xpath = '/html/body/div/div/div/div[1]/div[2]/div/div/div/div[2]/div[1]/div/div/div/div/div[2]/div[1]/div[2]/div[1]/div/span[4]'
# 交易时间,full xpath 定位
trans_datetime_xpath = '/html/body/div/div/div/div[1]/div[2]/div/div/div/div[2]/div[1]/div/div/div/div/div[2]/div[1]/div[2]/div[2]/span[2]'
print('打开浏览器驱动')
open_driver()
# 打开网址网页
print('打开网址网页')
driver.get(gold_url)
# 等待6秒启动完成
driver.implicitly_wait(6)
print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2))
# 实时价格
real_price = driver.find_element(By.XPATH, real_price_xpath).text
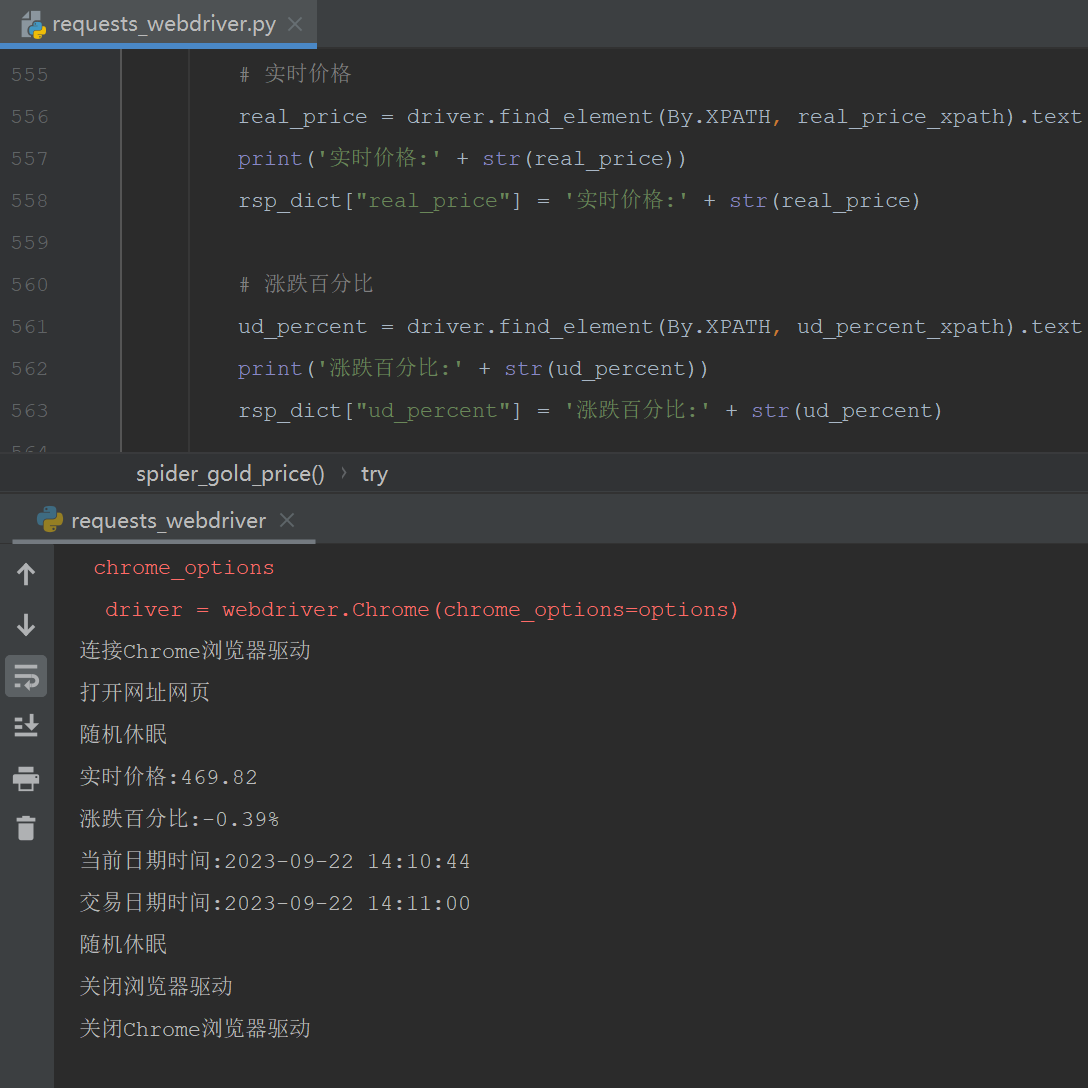
print('实时价格:' + str(real_price))
rsp_dict["real_price"] = '实时价格:' + str(real_price)
# 涨跌百分比
ud_percent = driver.find_element(By.XPATH, ud_percent_xpath).text
print('涨跌百分比:' + str(ud_percent))
rsp_dict["ud_percent"] = '涨跌百分比:' + str(ud_percent)
# UTC格式当前时区时间
t = time.localtime()
work_time = time.strftime("%Y-%m-%d %H:%M:%S", t)
print('当前日期时间:' + str(work_time))
now_year = str(work_time)[:4]
# 交易时间
trans_datetime = driver.find_element(By.XPATH, trans_datetime_xpath).text
print('交易日期时间:' + str(now_year + '-' + trans_datetime))
rsp_dict["trans_datetime"] = '交易日期时间:' + str(now_year + '-' + trans_datetime)
print('随机休眠')
# 休眠3秒
time.sleep(3)
print('关闭浏览器驱动')
close_driver()
# 返回容器
return [1, '000000', '爬取实时黄金价格信息成功', [rsp_dict]]
except Exception as e:
print('关闭浏览器驱动')
close_driver()
print("爬取实时黄金价格信息异常," + str(e))
return [0, '999999', "爬取实时黄金价格信息异常," + str(e), [None]]第四步:运行测试效果
-------------------------------------------end---------------------------------------