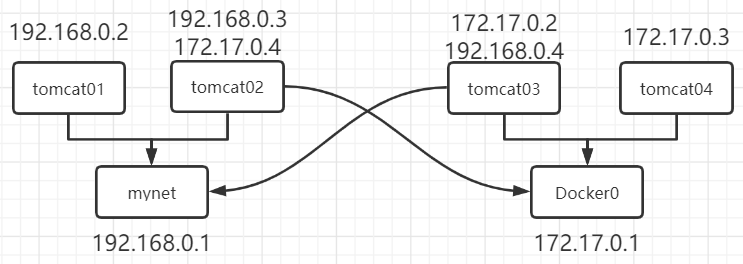
首先我们要清楚java执行groovy的逻辑,这里我们采用了GroovyClassLoader的方法,因为它能缓存编译结果,不用每次执行相同的脚本都需要重新编译,提升执行效率
GroovyCodeSource groovyCodeSource = new GroovyCodeSource(context.getScriptContent(), scriptMd5DStr + ".groovy", "groovy/script/function");
Class clazz = groovyClassLoader.parseClass(groovyCodeSource, true);GroovyCodeSource构造函数的第二个参数是我们执行groovy脚本的脚本名称,这个结合parseClass的第二个参数,表示是否缓存我们本地的编译结果,这样当我们的脚本没有发生变化时,可以无需编译直接从缓存中拿到之前编译过的脚本直接执行。
我们先来看一下执行一段普通脚本(没有引入jar包)的类加载器的变化
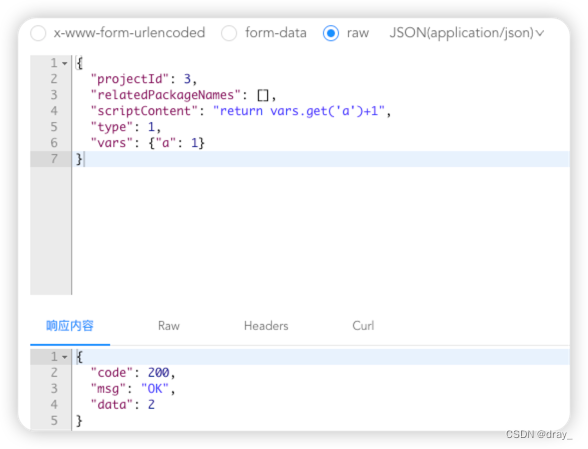
运行前:
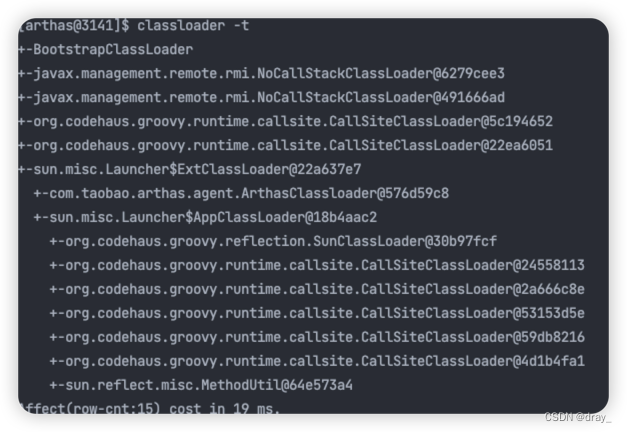
运行后

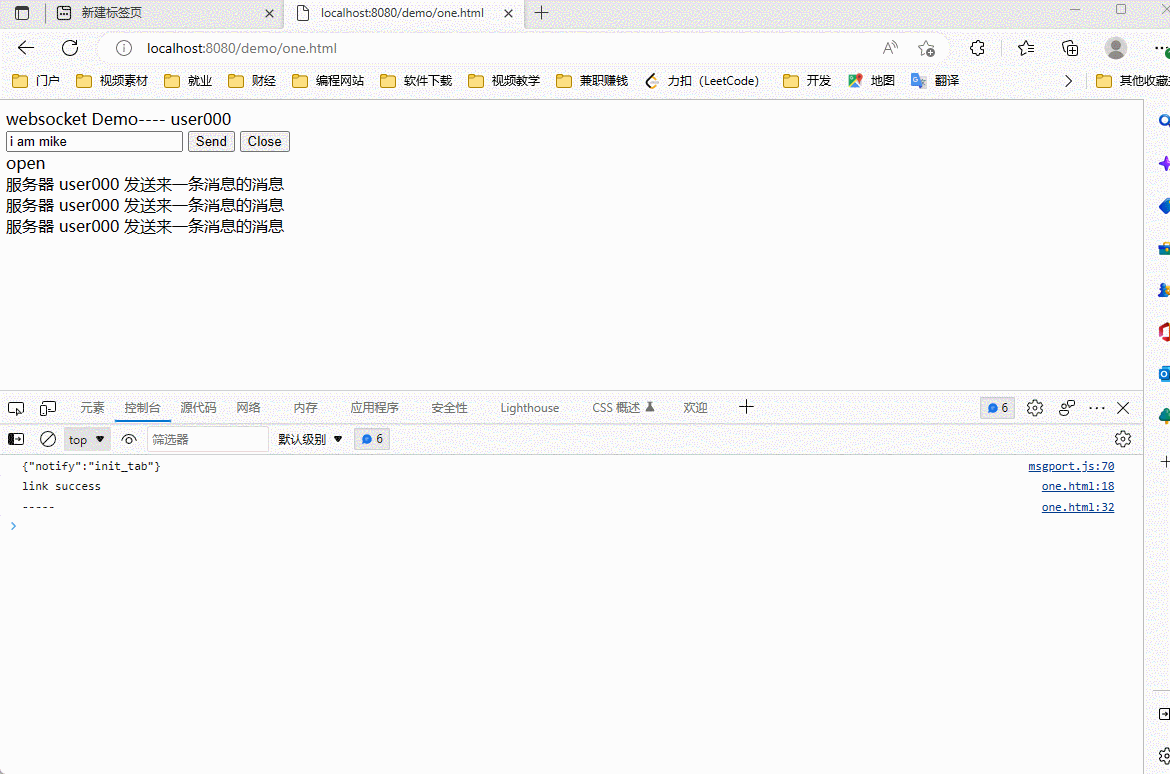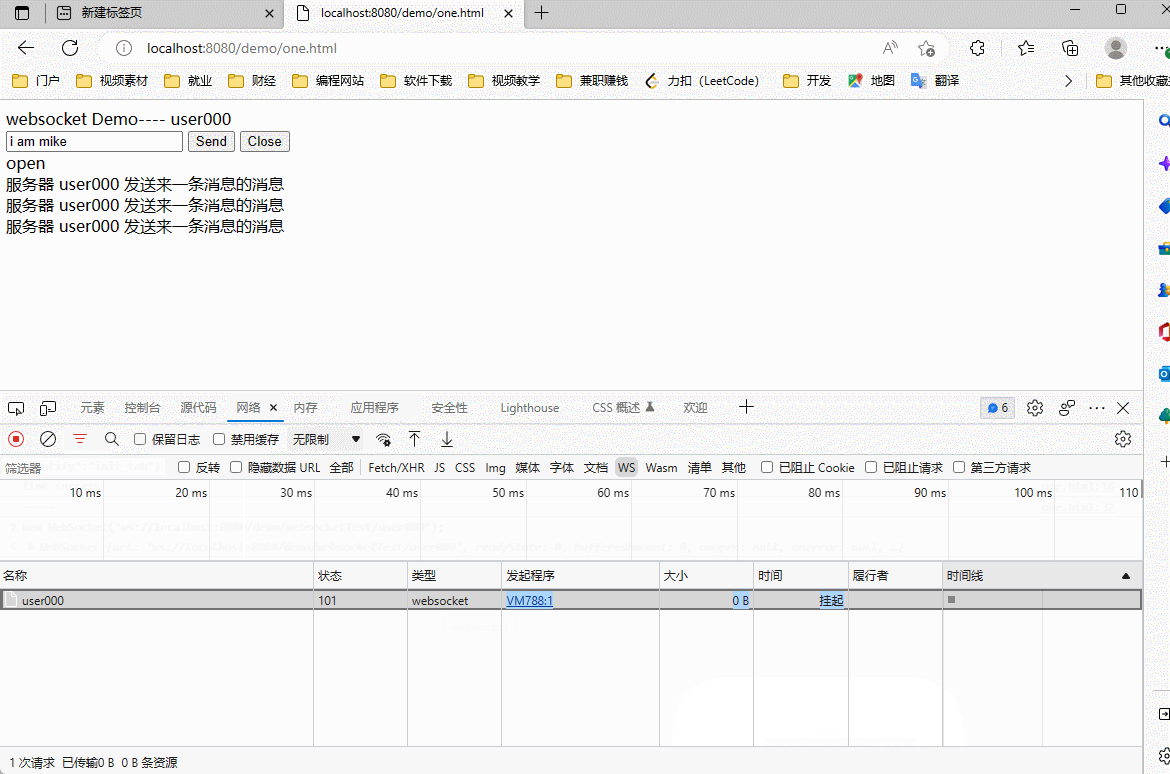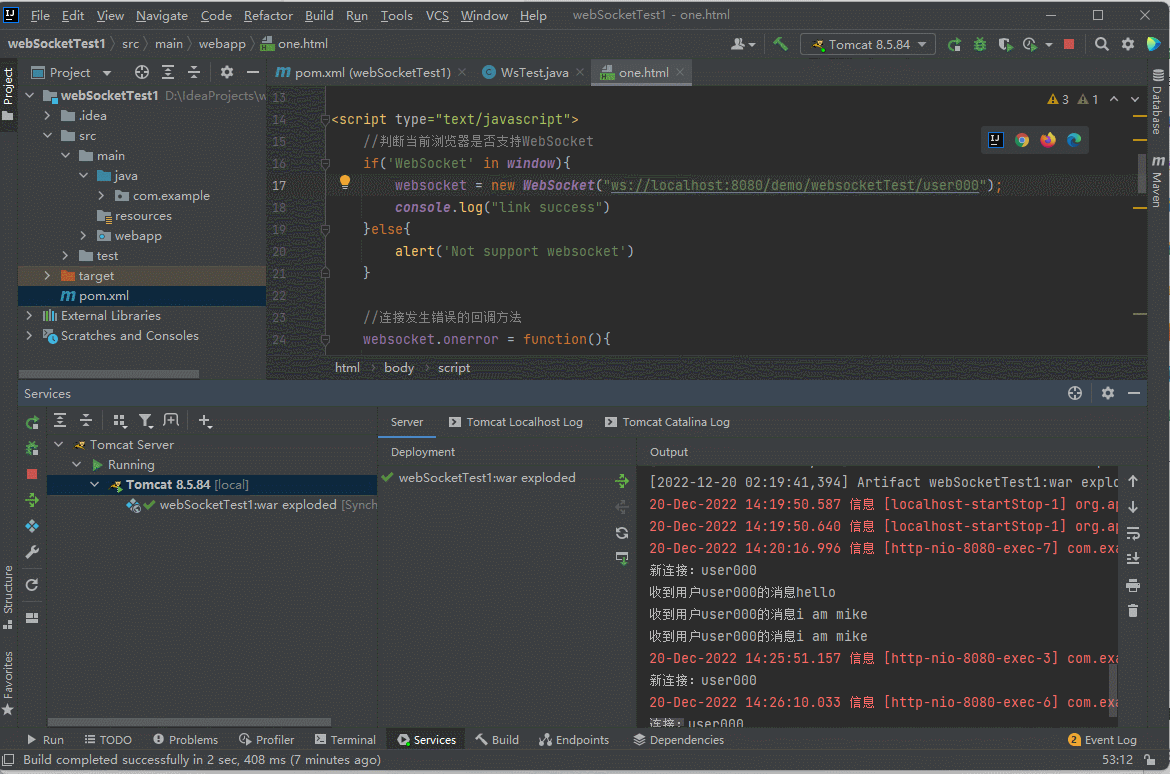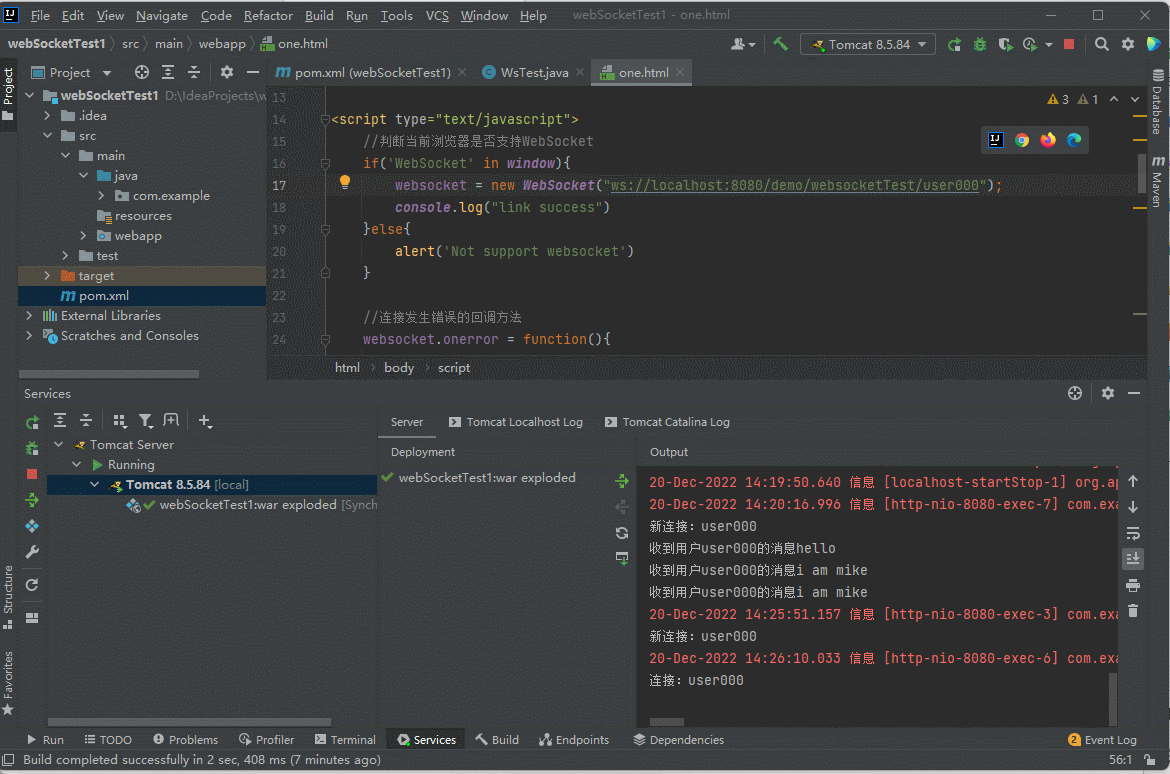
通过对比我们可以看出,我们运行一次脚本多出了一个GroovyClassLoader和GroovyClassLoader$InnerLoader的类加载器,如果我们频繁的运行脚本,哪怕是一样的脚本,我们的类加载器会越来越多,进而导致(jdk1.8为例)
java.lang.OutOfMemoryError: Metaspace
那有什么解决的方法呢?
- 首先我们要明确如果运行相同的代码是没有必要使用不同的GroovyClassLoader的,所以我们要对GroovyClassLoader进行缓存,这样,针对相同脚本的运行,我们将不会生成新的类加载器。
- 其次如果是不同脚本的执行我们将面临之前同样的问题,所以我们需要一个类加载器的回收方法,幸运的是GroovyClassLoader提供了close()方法能清楚缓存以及其加载器。当然有的小伙伴会有这种想法既然有这么好的方法,为啥我不在每次执行完这个方法后清除类加载器就好了么?这样只会导致jvm频繁的进行垃圾回收进而导致用户进程的迟缓甚至宕机。
我们可以看下close方法的效果,我们这边生成了三个GroovyClassLoader,其中有一个我已经调用了close方法,我们需要进行一次垃圾回收,看是否能达到我们的目的(调用close方法只是标记了类加载器不可用,真正回收需要FullGC,这里我们模拟一下FullGC的情况)
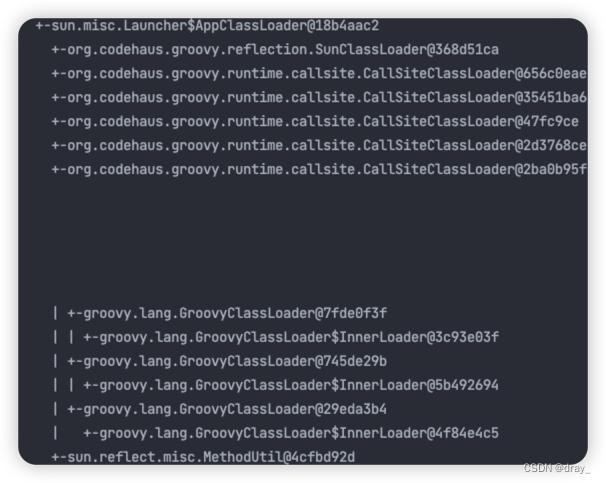
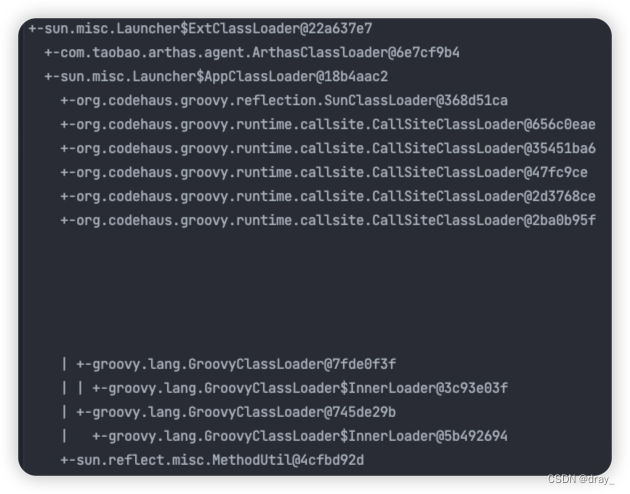
毫无疑问我们得到了我们想要的结果。
- 然后我们缓存了类加载器,也知道了清除类加载器的方法,那我们什么时候关闭类加载器呢?才能保证程序平稳运行。这里我们引入guava的一个并发map
public static ConcurrentLinkedHashMap<String, GroovyClassLoader> classLoaderCache = new ConcurrentLinkedHashMap.Builder<String, GroovyClassLoader>() .maximumWeightedCapacity(512).weigher(Weighers.singleton()).listener( (key, value) -> { try { //当缓存失效时,关闭classLoader,这里关键点,只有发生full gc的时候才会回收类加载器,所以jvm一定要给元空间配置边界 value.close(); } catch (IOException e) { throw new RuntimeException(e); } } ).build();这个map可以根据容量配置一个最近最久未使用的算法,将长时间未使用的类加载器先行销毁,这样即保留了热点数据,又清理了内存,正如代码中所说,我们需要给云空间配置最大值,这样让空间不足时才会发生full gc进而回收内存,否则云空间会直接膨胀占用系统内存。这里还有一点需要说明的是,我们缓存的key是以脚本md5后的字符串为key,当我们的脚本中存在变量时,因为变量值不一样而导致脚本不一样从而生成新的缓存是积极浪费的。
vars.put("b",${a}+1);
针对上面的方法我们可以是使用绑定传参的方式,这样经过md5后脚本是一致的不会生成新的类加载器
groovyScript.setBinding(binding);
Map<String, Object> runParams = context.getVars();
binding.setVariable(context.getParamBindName(), vars);
vars.put("b",vars.get("a")+1);通过上述的手段我们从一定角度上解决了java调用groovy脚本的oom问题,但是有一种情况我们需要额外分析,当groovy脚本调用jar包里的方法的时候
当我们引入jar包时,我们通过
groovyClassLoader.addClasspath(localJar);
将jar包加入GroovyClassLoader的classpath,我们调用后发现,除了之前的classloader,新生成了一个CallSiteClassLoader,真正去加载jar包的其实是这个类加载器,我们使用之前的方法关闭GroovyClassLoader试试

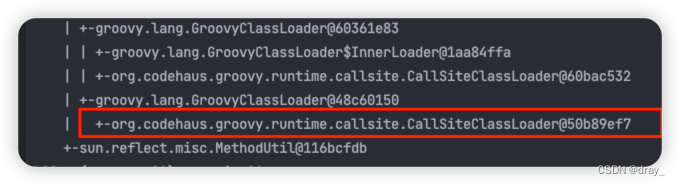
不幸的是CallSiteClassLoader无法回收,groovy也没有提供removeClassPath的方法,我们只能另辟蹊径去处理这个了,好在平台使用jar包调用的地方不多,虽然不能完全避免发生OOM的可能,但是将其尽发生可能的时间拉长,是我们需要解决的问题。
- 首先,我们当然也需要缓存脚本,为了和普通脚本区分,我们需要另外一个concurrentHashMap来存储我们的脚本,为了尽可能少的生成GroovyClassLoader,我们的map里的key使用的是业务id,而不是脚本的hash值
- 其实,按照我们业务逻辑,只有自定义函数,或者调用自定义函数的部分会和jar包打交道,所以我们将不采用以往拼接自定义函数的方式来执行脚本,而是将自定义函数执行完的结果返回给脚本,例如:
def a = {{getInfo(1))}} vars.put("a",a)
以前我们的脚本是
def getInfo(){ return a+1; } def a = getInfo(1)) vars.put("a",a)
而我们现在针对包含jar包的函数,则会先运行函数,然后直接赋值给变量,这样独立运行的自定义脚本将不会生成新的类加载器。
- 最后,我们还有一个关键问题点未解决,当我们的jar更新后,我们使用同一个类加载器将无法加载新的jar包,需要我们重启script-agent服务达到更新jar包的方法,针对这个问题,这里就需要讲一下我们这里的设计点,以前的jar包是每次执行脚本发现有关联jar时都回去文件中心拉取文件,当然文件哪怕是更新了也不会重新加载,这个每次拉的过程会比较耗时,我们这里使用mq做了一个异步功能,当jar发生变更时,agent监听这个事件就会在本地jar文件库做一个相应的变更,所以,我们针对上述问题就可以这样解决,当监听到jar是更新的时候,我们根据业务id找到缓存的GroovyClassLoader销毁,然后生成新的GroovyClassLoader,这样就可以加载新的jar包到程序中,后续的调用都会走新包的逻辑。
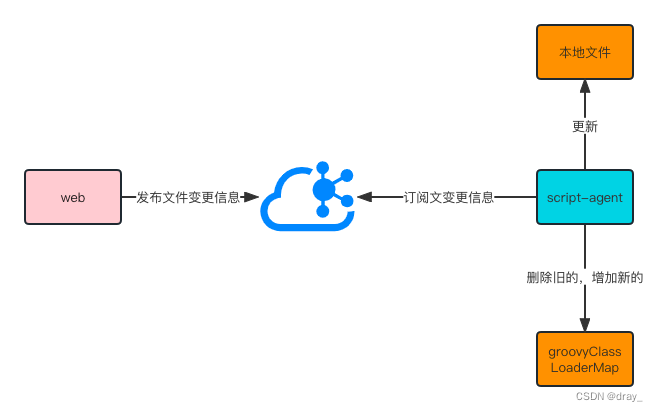
以上就是整个groovy脚本执行的设计,虽然没有百分百的根治OOM的问题,但是大部分场景下已经够用,也大大降低了程序因为脚本调用产生OOM的可能。