注意:在开始安装之前,请确保您的CentOS 7系统已经正确安装和配置了Java。Hadoop需要Java来运行。
目录
- 一、下载与配置Hadoop框架:
- 1.1、下载与环境变量设置
- 1.2、XML配置文件Hadoop设置
- 1.3、格式化HDFS
- 二、Hadoop 3.x版本中hdfs命令的问题解决与配置方法
- 2.1、问题描述与解决方法
- 2.2、设置JAVA_HOME环境变量
- 2.3、Hadoop 3.x版本中某些脚本已弃用和新的使用方法
- start-all.sh脚本已弃用
- mr-jobhistory-daemon.sh脚本已弃用
- 2.4、验证HDFS集群是否已经启动
- 检查Hadoop进程
- 最后验证Hadoop是否已成功安装并正常运行
- 三、案例及用途
- 3.1、Hadoop和相关技术的不同用途和应用
- 3.2、访问Hadoop Web界面
- HDFS Web界面:http://localhost:9870/
- YARN ResourceManager Web界面:http://localhost:8088/
- MapReduce JobHistoryServer Web界面(如果使用MapReduce):http://localhost:19888/
- 参考资料
一、下载与配置Hadoop框架:
1.1、下载与环境变量设置
访问Hadoop官方网站(https://hadoop.apache.org/)或镜像站点(https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/)以获取Hadoop 3.3.6的下载链接。使用wget或curl来下载Hadoop二进制文件。假设您下载的是hadoop-3.3.6.tar.gz文件:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
解压Hadoop:
使用以下命令解压下载的Hadoop文件:
tar -xzvf hadoop-3.3.6.tar.gz
移动Hadoop:
将解压后的Hadoop文件夹移动到您选择的安装目录。例如,将其移动到/opt目录下:
sudo mv hadoop-3.3.6 /opt/hadoop
配置环境变量:
编辑~/.bashrc文件,添加以下行来配置Hadoop的环境变量:
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
然后运行以下命令以使更改生效:
source ~/.bashrc
1.2、XML配置文件Hadoop设置
进入Hadoop配置目录:
cd /opt/hadoop/etc/hadoop
在这里,您需要编辑Hadoop的配置文件。以下是一些常见的配置文件和修改的示例:
core-site.xml:配置Hadoop的核心设置。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml:配置HDFS设置。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml:配置MapReduce设置。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:配置YARN设置。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
这些只是示例配置,您可以根据您的需求进行更改。
1.3、格式化HDFS
在首次启动Hadoop之前,需要格式化HDFS。运行以下命令:
hdfs namenode -format
启动Hadoop:
使用以下命令启动Hadoop:
start-all.sh
这将启动HDFS和YARN。
访问Hadoop Web界面:
打开Web浏览器并访问以下URL以查看Hadoop集群的Web界面:
HDFS:http://localhost:9870/
YARN ResourceManager:http://localhost:8088/
现在,您已经成功在CentOS 7上安装和配置了Hadoop 3.3.6。接下来,您可以开始使用Hadoop来处理大数据任务。请根据您的需求创建Hadoop用户、配置集群更多细节、创建Hive等等。
注意:如果上述执行之后出现下面的问题说明,您的系统没有设置JAVA_HOME环境变量或者JAVA_HOME环境变量设置不正确,也就是下面要讲 的内容和解决方法。
二、Hadoop 3.x版本中hdfs命令的问题解决与配置方法
2.1、问题描述与解决方法
hdfs namenode -format
ERROR: JAVA_HOME is not set and could not be found.
解决方法:在运行Hadoop命令之前,您需要确保已经正确配置了Java环境。以下是解决此问题的步骤:检查Java安装:首先,请确保您已经在CentOS 7上正确安装了Java。您可以运行以下命令来检查Java的安装情况:
java -version
如果Java已经安装,您将看到Java的版本信息。如果没有安装,您可以使用以下命令安装OpenJDK 8,如下介绍。
sudo yum install java-1.8.0-openjdk-devel
2.2、设置JAVA_HOME环境变量
一旦Java安装完成,您需要设置JAVA_HOME环境变量。编辑~/.bashrc文件,并在文件末尾添加以下行,将JAVA_HOME设置为Java安装的路径:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export PATH=$PATH:$JAVA_HOME/bin
确保路径/usr/lib/jvm/java-1.8.0-openjdk与您系统上Java的实际安装路径一致。保存文件后,运行以下命令使更改生效:
source ~/.bashrc
再次尝试格式化HDFS,重新运行格式化HDFS的命令:hdfs namenode -format。
假设你的系统已经安装了java环境但是HDFS还是没有检测到,解决的方法如下:
如何查找下面的java安装路径:
java -version
openjdk version "1.8.0_382"
OpenJDK Runtime Environment (build 1.8.0_382-b05)
OpenJDK 64-Bit Server VM (build 25.382-b05, mixed mode)
使用以下命令来查找Java的安装路径:
readlink -f $(which java)
这个命令会找到系统上java命令的符号链接,并且使用readlink命令查找它的实际路径。输出将是Java二进制文件的完整路径。
在您的情况下,根据您提供的Java版本信息,这个命令可能会返回类似于以下内容的路径:
/usr/lib/jvm/java-1.8.0-openjdk-<版本号>/jre/bin/java
其中<版本号>会因实际安装的Java版本而有所不同。上述路径中的/usr/lib/jvm/java-1.8.0-openjdk-<版本号>就是Java的安装路径。您可以将这个路径用于设置JAVA_HOME环境变量或者在Hadoop配置文件中配置Java的路径。
在~/.bashrc文件中设置JAVA_HOME环境变量:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64
export PATH=$PATH:$JAVA_HOME/bin
保存文件后,运行以下命令使更改生效:
source ~/.bashrc
再次执行命令出现下面的结果:
fsimage.ckpt_0000000000000000000 of size 396 bytes saved in 0 seconds .
2023-09-21 00:21:16,403 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-09-21 00:21:16,437 INFO namenode.FSNamesystem: Stopping services started for active state
2023-09-21 00:21:16,437 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-09-21 00:21:16,444 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-09-21 00:21:16,446 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1
************************************************************/
从上述的提供的日志中看,似乎已经成功格式化了HDFS,并且NameNode已经正常启动。然后,您尝试重新启动Hadoop集群,但遇到了start-all.sh: 未找到命令…错误。
2.3、Hadoop 3.x版本中某些脚本已弃用和新的使用方法
start-all.sh脚本已弃用
[root@localhost hadoop]# start-all.sh
bash: start-all.sh: 未找到命令...
主要的原因和解决的方法如下:在Hadoop 3.x版本中,start-all.sh脚本已经不再提供,因此不再支持使用该脚本来启动整个Hadoop集群。相反,您需要单独启动Hadoop的各个组件。
以下是启动Hadoop集群各个组件的命令:
启动HDFS(分布式文件系统):
hdfs --daemon start namenode
hdfs --daemon start datanode
启动YARN(资源管理器):
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
mr-jobhistory-daemon.sh脚本已弃用
启动MapReduce(如果需要):
mr-jobhistory-daemon.sh start historyserver
但是,上述很可能出现下面的问题:
mr-jobhistory-daemon.sh start historyserver
bash: mr-jobhistory-daemon.sh: 未找到命令...
解决的方法如下:
在Hadoop 3.x版本中,mr-jobhistory-daemon.sh脚本已经不再提供,因此不再支持使用该脚本来启动MapReduce历史服务器。相反,您可以使用以下命令启动MapReduce历史服务器:
mapred --daemon start historyserver
如果上述命令也未找到,您可以尝试使用完整的路径来启动MapReduce历史服务器。MapReduce历史服务器的启动脚本通常位于Hadoop的bin目录下。例如:
/opt/hadoop/bin/mapred --daemon start historyserver
请确保在启动MapReduce历史服务器之前,已经启动了HDFS和YARN组件,因为MapReduce依赖于这些组件运行。
要确保Hadoop服务正在运行,您可以运行以下命令来检查它们的状态,检查HDFS状态:
hdfs dfsadmin -report
检查YARN状态:
yarn node -list
这些命令将显示有关HDFS和YARN的详细信息,包括其状态和运行状况。
2.4、验证HDFS集群是否已经启动
hdfs dfsadmin -report
Configured Capacity: 57638281216 (53.68 GB)
Present Capacity: 35719229440 (33.27 GB)
DFS Remaining: 35719225344 (33.27 GB)
DFS Used: 4096 (4 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 127.0.0.1:9866 (localhost)
Hostname: localhost
Decommission Status : Normal
Configured Capacity: 57638281216 (53.68 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 21919051776 (20.41 GB)
DFS Remaining: 35719225344 (33.27 GB)
DFS Used%: 0.00%
DFS Remaining%: 61.97%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Thu Sep 21 00:24:55 PDT 2023
Last Block Report: Thu Sep 21 00:23:25 PDT 2023
Num of Blocks: 0
上述生成内容描述:
HDFS集群看起来已经成功启动,并且有一个DataNode(本地主机)正常运行。
以下是一些关于您HDFS集群状态的重要信息:
配置容量 (Configured Capacity):这是HDFS集群的总容量,为 53.68 GB。
当前容量 (Present Capacity):当前HDFS集群中可用的容量,为 33.27 GB。
DFS 剩余容量 (DFS Remaining):尚未使用的DFS容量,为 33.27 GB。
DFS 已使用 (DFS Used):已经使用的DFS容量,仅为 4 KB。
DFS 使用率 (DFS Used%):DFS已使用容量相对于总容量的百分比,这里是0.00%。
存活的DataNode (Live datanodes):您的HDFS集群中有一个DataNode,主机名是localhost。
DataNode的容量信息:DataNode的容量配置、已使用和剩余容量等信息。
块复制信息 (Replicated Blocks):有关块副本、未副本化的块、损坏副本的块和丢失块的信息。
擦除编码块组信息 (Erasure Coded Block Groups):有关擦除编码块组的信息。
总体来说,HDFS集群看起来正常运行,并且大部分容量仍然可用。请注意,DFS Used%为0.00%,这表示您尚未将大量数据存储在HDFS中。如果您计划使用HDFS来存储和处理大数据,请将文件或数据上传到HDFS以填充存储容量。
要验证Hadoop是否已成功安装并正常运行,您可以执行以下操作:
检查Hadoop进程
使用以下命令来检查Hadoop的各个组件是否在运行:
HDFS:运行 jps 命令,应该能看到 NameNode、DataNode 和 SecondaryNameNode 进程在运行。示例:
1234 NameNode
5678 DataNode
9012 SecondaryNameNode
YARN:同样,运行 jps 命令,应该能看到 ResourceManager 和 NodeManager 进程在运行。示例:
1234 ResourceManager
5678 NodeManager
MapReduce(如果使用):运行 jps 命令,应该能看到 JobHistoryServer 进程在运行。
但是上述jps很可能会出现下面的情况:
[root@localhost hadoop]# jps
bash: jps: 未找到命令...
[root@localhost hadoop]# jps
bash: jps: 未找到命令...
[root@localhost hadoop]#
上述问题的原因和解决方法:执行jps命令时遇到了"未找到命令"的错误。这是因为jps命令通常随着Java安装的JDK(Java Development Kit)一起提供,用于列出正在运行的Java进程。由于您遇到了这个错误,可能是因为jps命令未在系统的PATH中,或者您的Java JDK没有正确安装。
为了解决这个问题,您可以尝试以下步骤:安装OpenJDK的JDK:请确保您已经正确安装了OpenJDK的JDK(Java Development Kit)。jps命令通常随着JDK一起提供。如果尚未安装,请使用以下命令安装:
要再次确认是否下面的命令已经安装:
sudo yum install java-1.8.0-openjdk-devel
如果您已经安装了JDK,请确保安装的版本与您之前查找到的Java版本一致(OpenJDK 1.8.0)。
使用完整路径运行jps:如果在步骤1中安装了JDK,但仍然无法使用jps命令,可以尝试使用完整路径运行jps命令。通常,jps命令位于JDK的bin目录中。例如:
/usr/lib/jvm/java-1.8.0-openjdk-<版本号>/bin/jps
请根据您的JDK安装路径替换<版本号>部分。
将jps所在目录添加到PATH:另一种方法是将jps所在的目录添加到系统的PATH环境变量中。在大多数情况下,jps位于/usr/lib/jvm/java-1.8.0-openjdk-<版本号>/bin/目录中。您可以编辑~/.bashrc文件并将以下行添加到文件末尾:
export PATH=$PATH:/usr/lib/jvm/java-1.8.0-openjdk-<版本号>/bin/
然后运行以下命令使更改生效:
source ~/.bashrc
然后再次尝试运行jps命令。运行结果如下:
jps
3139 Main
11717 Jps
10534 NameNode
10694 DataNode
10838 ResourceManager
11149 NodeManager
11423 JobHistoryServer
根据输出结果,可以看到以下Hadoop组件正在运行:
NameNode:这是Hadoop的主要组件,负责管理HDFS文件系统的命名空间和元数据。
DataNode:这是Hadoop的数据存储组件,负责存储HDFS中的数据块。
ResourceManager:这是YARN资源管理器,负责管理集群上的资源。
NodeManager:这是YARN节点管理器,负责管理每个节点上的资源和容器。
JobHistoryServer:这是MapReduce作业历史服务器,用于记录和查询MapReduce作业的历史信息。
还有一个名为Jps的Java进程,用于列出正在运行的Java进程。
根据这些信息,您的Hadoop集群似乎已经成功安装并正常运行。您可以通过访问Hadoop的Web界面(如HDFS、YARN ResourceManager等)来进一步验证集群的状态和运行情况。
最后验证Hadoop是否已成功安装并正常运行
查看Hadoop进程:
使用 ps 命令,确保Hadoop的各个组件仍然在运行。您可以运行以下命令来查看Hadoop进程:
ps aux | grep hadoop
确保列出的进程中包括NameNode、DataNode、ResourceManager、NodeManager和JobHistoryServer等组件。
访问Hadoop Web界面:
再次访问Hadoop的Web界面来查看集群的状态和运行情况。这些界面包括:
HDFS Web界面:http://localhost:9870/
YARN ResourceManager Web界面:http://localhost:8088/
MapReduce JobHistoryServer Web界面(如果使用MapReduce):http://localhost:19888/
如果能够访问这些界面并查看集群状态信息,说明Hadoop正在运行。
创建和操作HDFS文件:
尝试在HDFS上创建文件、目录,上传文件,以及查看HDFS文件列表。例如,您可以使用以下命令在HDFS上创建一个目录并上传文件:
hdfs dfs -mkdir /user/your_username
hdfs dfs -put /local/path/to/your/file /user/your_username/
如果这些操作都成功完成,说明Hadoop的HDFS部分正常工作。
提交MapReduce作业(如果使用MapReduce):
如果您使用MapReduce,可以再次提交一个简单的MapReduce作业来验证MapReduce是否正常工作。首先,确保已经编写了一个MapReduce作业,并将JAR文件准备好,然后使用以下命令提交作业:
yarn jar /path/to/your/MapReduceJob.jar input_dir output_dir
如果作业成功运行并生成输出,说明MapReduce部分正常工作。
查看Hadoop日志:
检查Hadoop的日志文件以查看是否有任何错误或异常。通常,Hadoop的日志文件位于/opt/hadoop/logs/目录下。您可以使用ls命令查看这个目录中的日志文件,并使用cat或tail命令来查看日志内容。
#、
三、案例及用途
3.1、Hadoop和相关技术的不同用途和应用
数据清洗和预处理:使用MapReduce作业,从原始日志文件中提取和清洗数据,以便进一步的分析和可视化。
用户行为分析:使用Hive编写查询,分析网站或应用程序的用户行为数据,例如页面浏览量、用户访问模式等。
推荐系统:基于用户历史行为数据,使用Hadoop和机器学习算法构建个性化的推荐系统,为用户提供定制的建议。
文本分析和情感分析:使用Hadoop和自然语言处理技术,对大规模文本数据进行分析,例如情感分析、主题建模等。
实时数据处理:使用Apache Kafka和Apache Storm等流处理技术,构建实时数据处理管道,用于监控和分析实时事件流。
图分析:使用Hadoop图处理框架(如Apache Giraph)来解决复杂的图分析问题,例如社交网络分析或路网分析。
日志分析和异常检测:使用Hadoop和ELK(Elasticsearch、Logstash、Kibana)堆栈,分析日志数据并检测异常事件。
批处理ETL作业:使用Apache NiFi等工具,构建批处理ETL(提取、转换、加载)作业,将数据从不同来源汇总到数据仓库中。
时间序列数据分析:使用Hadoop和时间序列数据库,对时间序列数据进行分析,例如股票市场数据、传感器数据等。
地理信息系统(GIS)分析:
使用Hadoop和GIS库,分析地理信息数据,执行地理空间查询和地图分析。
这些案例涵盖了大数据处理的多个领域,包括数据清洗、分析、机器学习、实时处理和更多。根据您的兴趣和需求,您可以选择其中一个或多个案例来深入了解和实践。
3.2、访问Hadoop Web界面
Hadoop提供了Web界面,可以通过浏览器访问并查看Hadoop集群的状态。以下是一些常用的Web界面:
HDFS Web界面:http://localhost:9870/
YARN ResourceManager Web界面:http://localhost:8088/
MapReduce JobHistoryServer Web界面(如果使用MapReduce):http://localhost:19888/
下面详细介绍以及用法:
Hadoop提供了一组Web界面,用于监视和管理Hadoop集群的不同组件。这些界面提供了关于集群健康、作业状态、资源使用等方面的重要信息。以下是Hadoop集群中一些常见的Web界面及其详细介绍:
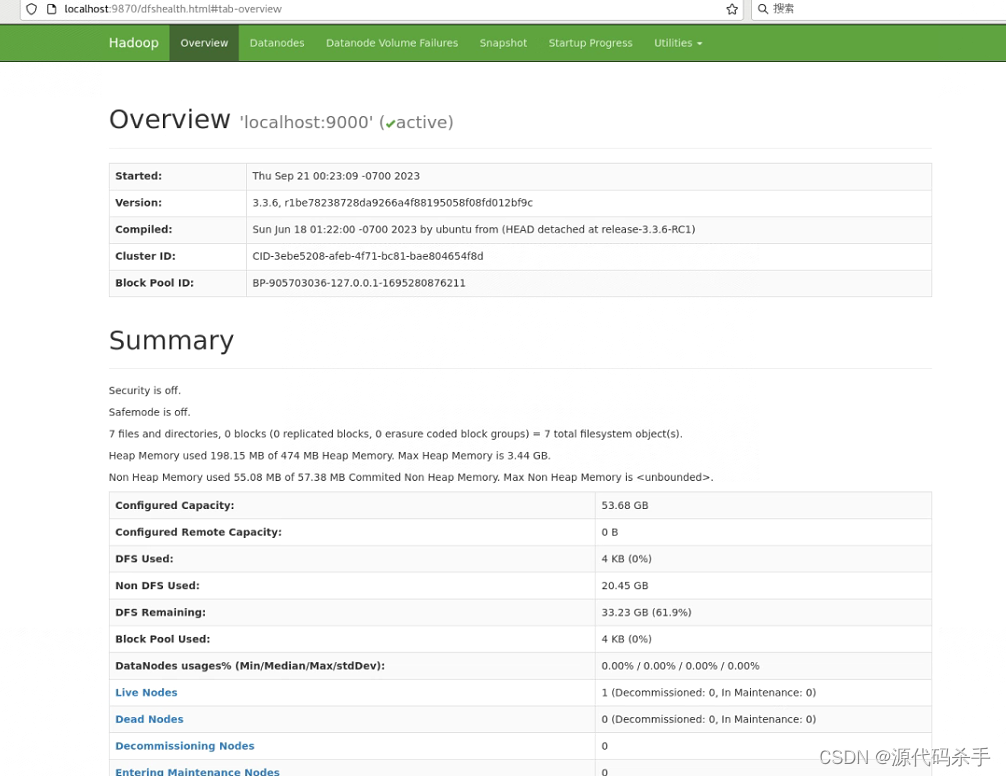
HDFS Web界面:http://localhost:9870/
HDFS Web界面是Hadoop分布式文件系统(HDFS)的管理和监视工具。通过此界面,您可以:
浏览文件系统:查看HDFS中的文件和目录,以及它们的大小和权限。
查看块报告:了解每个数据块的状态,包括块的副本数量和位置。
查看节点报告:监视HDFS集群中的各个数据节点的状态、容量和使用情况。
上传和下载文件:通过界面上传文件到HDFS或从HDFS下载文件。
查看HDFS用量和健康状况:获取HDFS的容量、使用情况、剩余空间和数据块相关信息。
HDFS Web界面有助于管理员和开发人员了解HDFS的状态和文件系统的结构,并帮助排查任何潜在的问题。
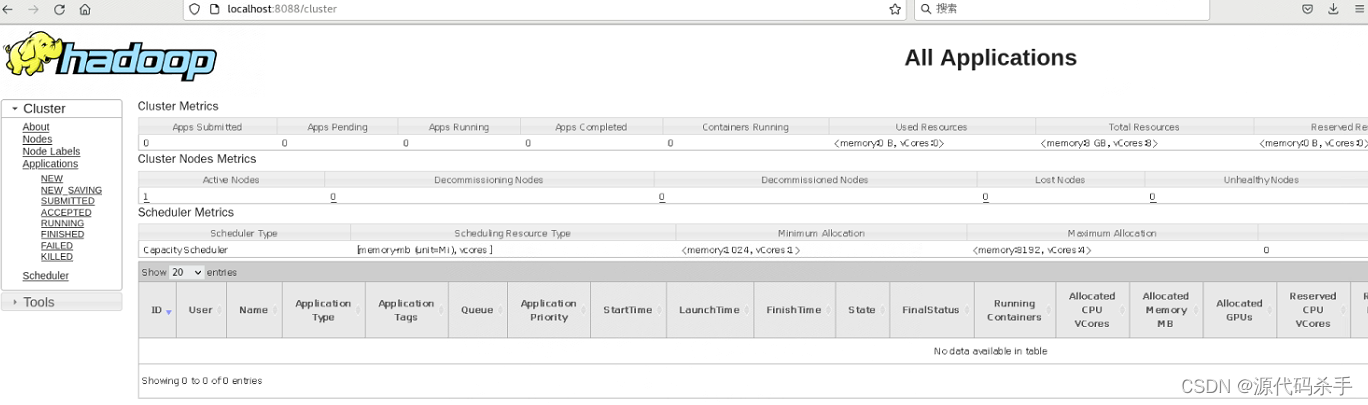
YARN ResourceManager Web界面:http://localhost:8088/
YARN ResourceManager Web界面用于管理和监视YARN资源管理器,它是Hadoop的资源管理和作业调度组件。通过此界面,您可以:
查看集群概览:了解集群中各个节点的资源使用情况、分配情况和容量。
查看应用程序列表:监视当前运行的YARN应用程序,包括作业的状态、队列分配等信息。
查看节点列表:查看YARN集群中的各个节点,包括节点的资源、状态和运行容器。
查看调度器信息:了解YARN调度器的队列分配和容量配置。
ResourceManager Web界面有助于集群管理员和作业调度员了解YARN集群的资源使用情况和应用程序状态,以便进行资源优化和作业管理。
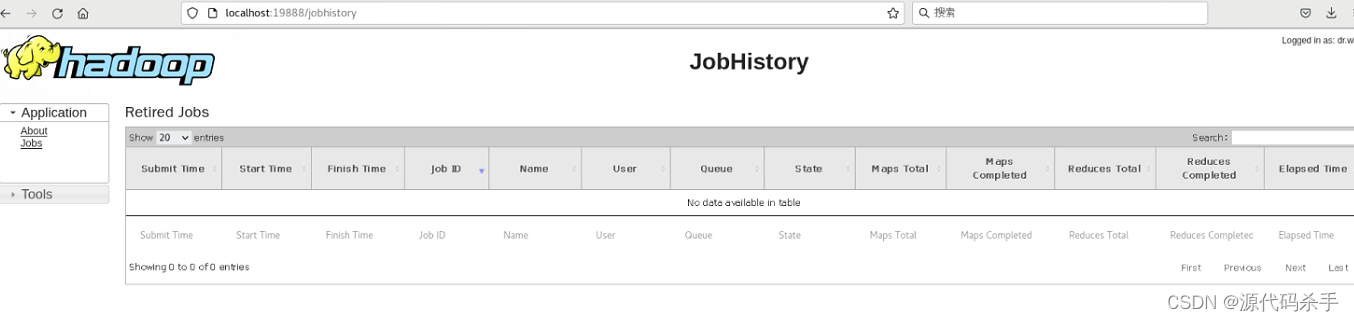
MapReduce JobHistoryServer Web界面(如果使用MapReduce):http://localhost:19888/
MapReduce JobHistoryServer Web界面用于监视和管理MapReduce作业的历史信息,如果您在集群上运行MapReduce作业,这个界面会很有用。通过此界面,您可以:
查看已完成作业:了解以前运行的MapReduce作业的状态、持续时间和输入/输出信息。
查看作业计数器:查看作业的计数器信息,这些信息包括Map任务和Reduce任务的计数器。
查看作业详情:获取有关每个已完成作业的详细信息,包括任务的状态和历史记录。
JobHistoryServer Web界面允许您在作业完成后查看其历史信息,有助于性能分析和故障排除。
最后记录系统操作的所有历史命令:
1 ls
2 pwd
3 cd ..
4 ls
5 cd home/mycentos
6 cd home/
7 ls
8 cd mycentos7
9 ls
10 cd ..
11 ls
12 cd mycentos-`
13 cd mycentos-7
14 ls
15 cd my_project/
16 ls
17 bash Anaconda3-2023.07-2-Linux-x86_64.sh -p /opt/conda/ -u
18 conda
19 source ~/.bashrc
20 ls
21 apt install vim
22 yum install vim
23 vim
24 vim ~/.bashrc
25 source ~/.bashrc
26 conda
27 vim ~/.bashrc
28 source ~/.bashrc
29 exit
30 conda
31 conda --version
32 vim /etc/profile
33 source /etc/profile
34 exit
35 ls
36 python
37 conda activate
38 source activate
39 python
40 sudo mv hadoop-3.3.6 /opt/hadoop
41 sudo
42 vim ~/.bashrc
43 source ~/.bashrc
44 cd /opt/hadoop/etc/hadoop
45 pwd
46 ls
47 yum install gedit
48 gedit core-site.xml
49 gedit hdfs-site.xml
50 gedit mapred-site.xml
51 gedit yarn-site.xml
52 hdfs namenode -format
53 java
54 hdfs namenode -format
55 java -version
56 cd # hdfs namenode -format
57 ERROR: JAVA_HOME is not set and could not be found.
58 [root@localhost hadoop]# java -version
59 openjdk version "1.8.0_382"
60 OpenJDK Runtime Environment (build 1.8.0_382-b05)
61 OpenJDK 64-Bit Server VM (build 25.382-b05, mixed mode)
62 which java
63 readlink -f $(which java)
64 vim ~/.bashrc
65 source ~/.bashrc
66 hdfs namenode -format
67 vim ~/.bashrc
68 source ~/.bashrc
参考资料
https://developer.aliyun.com/article/676221
https://developer.aliyun.com/article/66204
https://cloud.tencent.com/developer/article/1121838
https://blog.csdn.net/klnsGenesis/article/details/124171236
https://zhuanlan.zhihu.com/p/33978941