在linux系统上进行多gpu卡的深度学习任务
- 确保已安装最新的 TensorFlow GPU 版本。
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
- 1、确保你已经正确安装了tensorflow和相关的GPU驱动,这里可以通过在命令行输入
nvidia-smi来查看:
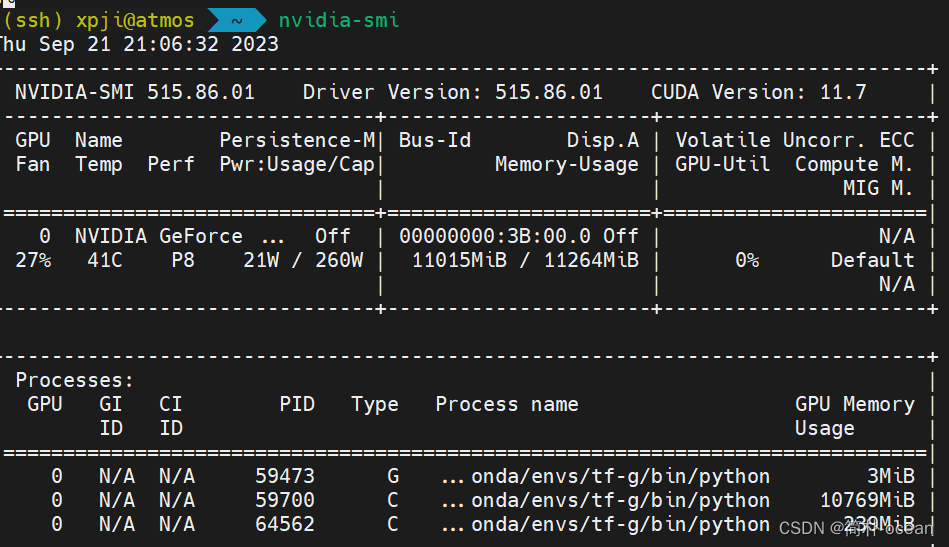
如果成功显示了类似上述的GPU信息和驱动版本信息,则说明NVIDIA驱动已经正确安装。
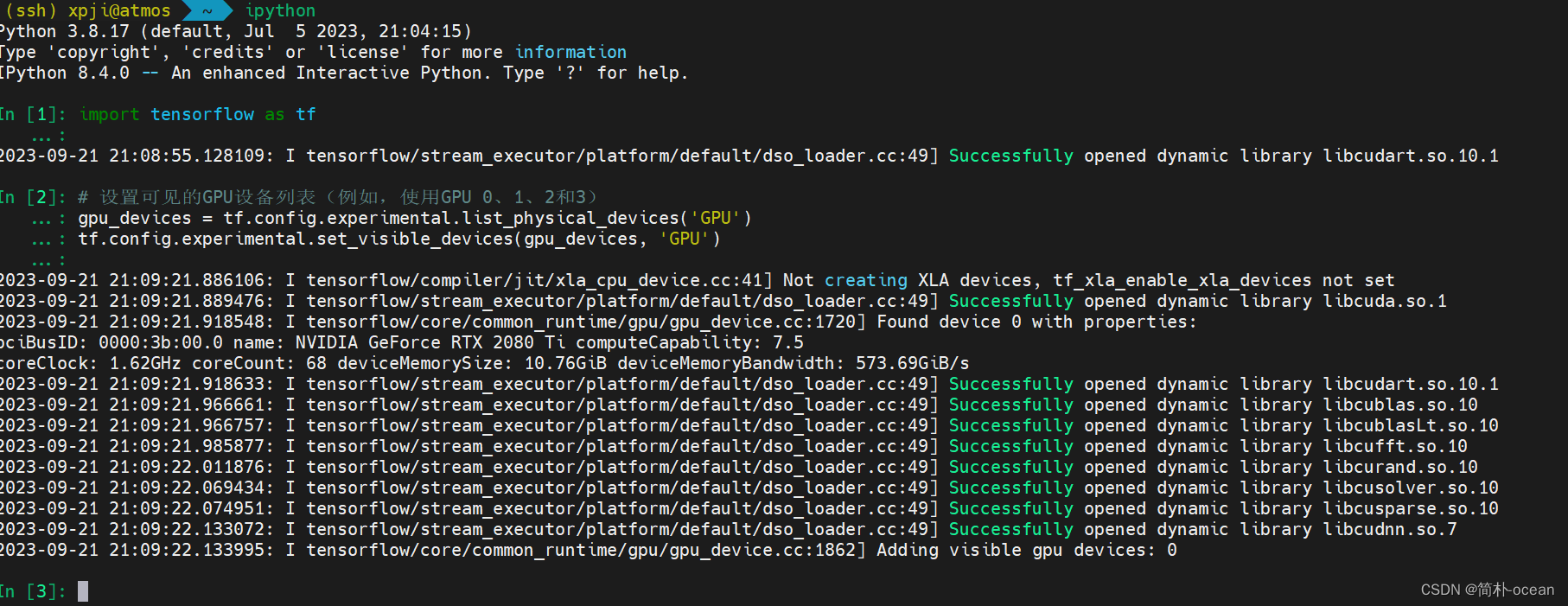
2、导入必要的库,设置可见的gpu设备列表:
import tensorflow as tf
# 设置可见的GPU设备列表(例如,使用GPU 0、1、2和3)
gpu_devices = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_visible_devices(gpu_devices, 'GPU')
- 3、创建一个
MirroredStrategy对象,该对象将自动复制模型和数据到每个可见的GPU卡上:
strategy = tf.distribute.MirroredStrategy()
- 4、在
strategy范围内创建和训练模型:
with strategy.scope():
# 创建和编译模型
model = create_model()
model.compile(...)
# 加载数据
train_dataset = load_train_data()
test_dataset = load_test_data()
# 训练模型
model.fit(train_dataset, validation_data=test_dataset, ...)
以上,在MirroredStrategy范围内创建的模型将自动复制并分布到每个可见的GPU卡上,每个卡都将处理一部分数据。
使用多个 GPU 的最佳做法是使用 tf.distribute.Strategy
以下给出一个官网的简单示例:
tf.debugging.set_log_device_placement(True)
gpus = tf.config.list_logical_devices('GPU')
strategy = tf.distribute.MirroredStrategy(gpus)
with strategy.scope():
inputs = tf.keras.layers.Input(shape=(1,))
predictions = tf.keras.layers.Dense(1)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=predictions)
model.compile(loss='mse',
optimizer=tf.keras.optimizers.SGD(learning_rate=0.2))
当然,也有手动的放置方法:
tf.debugging.set_log_device_placement(True)
gpus = tf.config.list_logical_devices('GPU')
if gpus:
# Replicate your computation on multiple GPUs
c = []
for gpu in gpus:
with tf.device(gpu.name):
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
c.append(tf.matmul(a, b))
with tf.device('/CPU:0'):
matmul_sum = tf.add_n(c)
print(matmul_sum)
在tensorflow上使用gpu:https://www.tensorflow.org/guide/gpu?hl=zh-cn