第二章 Hugging Face简介
本章无有效内容
第三章 从零开始搭建扩散模型
有时候,只考虑事情最简单的情况反而更有助于理解其工作原理。本章尝试从零开始搭建廓庵模型,我们将从一个简单的扩散模型讲起,了解其不同部分的工作原理,并对比它们与更复杂的结构之间的不同。
首先,本章涵盖的知识点:
1、退化过程
2、什么是UNET模型以及如何从零开始实现一个简单的UNet模型。
3、扩散模型训练。
4、采样理论。
然后,本章将介绍我们所展示的模型版本与Diffusers库中DDPM版本实现过程的区别,涵盖的知识点如下。
1、小型UNet模型的改进方法。
2、DDPM噪声计划。
3、训练目标的差异。
4、调节时间步。
5、采样方法。
值得注意的是,书中的大多数示例代码在说明与讲解,因此不建议直接将它用在工作中(除非你只是为了学习而尝试改进本书展示的示例代码)。
3.1 环境准备
3.1.1 本地环境
pip install -q diffusers
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDIMScheduler, UNet2DModel
from matplotlib import pyplot as plt
device = torch.device("cpu")#cpu专用
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#GPU
print(f'Using device:{device}')
3.1.2 数据集测试
书中使用的是经典数据集MNIST进行测试。
dataset = torchvision.datasets.MNIST(
root='mnist/',
train=True,
download=True,
transform=torchvision.transforms.ToTensor()
)
train_dataloader = DataLoader(dataset, batch_size=1,shuffle=True)
x,y = next(iter(train_dataloader))
print('Input size:', x.shape)
print("Labels:", y)
plt.imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
plt.show()
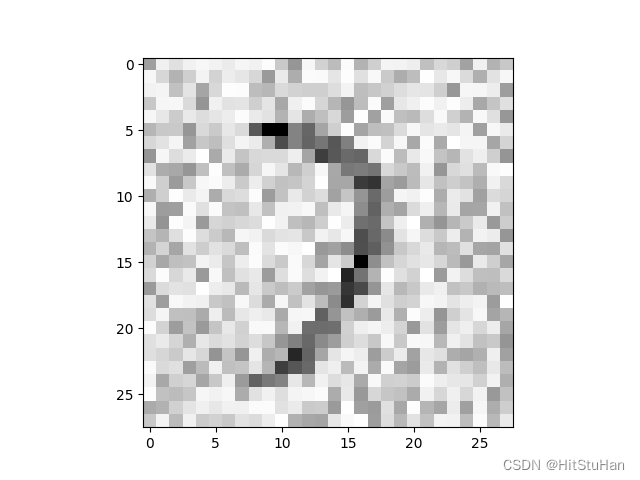
MNIST数据集中的每张图都是一个阿拉伯数字的28×28像素的灰度图像,每个像素的取值区间是[0,1].

noise = torch.rand_like(x)
noisy_x = (1-amount)*x +amount*noise
其中,amount=0,则返回输入,不做任何更改;如果amount=1,我们将得到一个纯粹的噪声。通过这种方式,我们可以将输入内容与噪声混合,并把混合后的结果保持在相同的范围(0~1)。下图使用的amount=0.5的效果。
我们可以很容易地做到这一点(但要注意张量的形状,以免受到广播机制不正确的影响),代码如下:
def corrupt(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1,1,1,1)#整理形状,以保证广播机制不会出错
return x*(1-amount) + noise*amount
3.2 扩散模型之退化过程
如果你没有读到过任何与扩散模型相关的论文,但知道在扩散模型过程中需要为内容加入噪声,应该怎么实现呢?
你可能想要通过一个简单的方法来控制内容损坏程度。如果需要引入一个参数来控制输入的“噪声量”,那么我们可以在配置好的环境中输入如下代码:
fig, axs = plt.subplots(2,1,figsize=(12,5))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0], cmap="Greys")
amount = torch.linspace(0,1,x.shape[0])
noised_x = corrupt(x, amount)
axs[1].set_title("Corrupted data (-- amount increases -->)")
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0], cmap="Greys")
plt.show()
3.3 扩散模型之训练
3.3.1 UNet网络
在进行训练之前,我们需要一个模型,要求它能够接收28×28像素的噪声图像,并输出相同大小图像的预测结果。业界比较流行的选择是UNet网络,UNet网络最初被发明用于完成医学图像的分割任务。UNet网络由一条“压缩路径”和一个“扩展路径”组成。“压缩路径”会使通过该路径的数据维度被压缩,而“扩散模型”则会将数据扩展回原始维度(类似自动编码器)。UNet网络中的残差连接允许信息和梯度在不同层级之间流动。
新建文件UNet.py(这里和书中有所不同,书中激活函数用的是nn.n(),我不知道是我版本问题还是什么原因,我并没有听说还有一个nn.n()的激活函数,而且代码这里也报错,所以我用nn.Sigmoid()替换了)
import torch.nn
import torch.nn as nn
class BasicUNet(nn.Module):
def __init__(self,in_channels=1,out_channels=1):
super().__init__()
self.down_layers = torch.nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32,64, kernel_size=5, padding=2),
nn.Conv2d(64,64,kernel_size=5,padding=2),
])
self.up_layers = torch.nn.ModuleList([
nn.Conv2d(64,64,kernel_size=5,padding=2),
nn.Conv2d(64,32,kernel_size=5,padding=2),
nn.Conv2d(32,out_channels,kernel_size=5,padding=2),
])
self.act = nn.Sigmoid()#激活函数
self.downscalse = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self,x):
h = []
for i,l in enumerate(self.down_layers):
x = self.act(l(x))
if i<2 :
h.append(x)
x = self.downscalse(x)
for i,l in enumerate(self.up_layers):
if i>0:
x = self.upscale(x)
x += h.pop()
x = self.act(l(x))
return x
if __name__ == "__main__":
net = BasicUNet()
x = torch.rand(8,1,28,28)
print(net(x).shape)
3.3.2 开始训练模型
那么,扩散模型到底应该做什么呢?相信很多人对这个问题都有各种不同的看法,但是对于这个演示我们决定选择一个简单的框架。首先,给定一个“带噪”(即加入了噪声)的输入noisy_x,扩散模型应该输入其对原始输入x的最佳预测。我们需要通过均方误差对预测值与真实值进行比较。
现在我们可以尝试开始训练网络了,流程如下。
(1)获取一批数据
(2)添加随机噪声
(3)将对数据输入模型
(4)对模型预测与初始图像进行比较,计算损失更新模型的参数。
在训练过程中,你可以自由修改相关数据,看看怎样才能获得更好的结果。
配置好环境后,我们需要训练代码,代码如下:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDIMScheduler, UNet2DModel
from matplotlib import pyplot as plt
import random
import os
import numpy as np
from UNet import BasicUNet
# device = torch.device("cpu")#cpu专用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#GPU
print(f'Using device:{device}')
def set_seed(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
def corrupt(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1,1,1,1)#整理形状,以保证广播机制不会出错
return x*(1-amount) + noise*amount
if __name__ == "__main__":
dataset = torchvision.datasets.MNIST(
root='mnist/',
train=True,
download=True,
transform=torchvision.transforms.ToTensor()
)
batch_size = 128
train_dataloader = DataLoader(dataset,batch_size=batch_size,shuffle=True)
n_epoch = 2000
net = BasicUNet()
net.to(device)
loss_fn = nn.MSELoss()
opt = torch.optim.Adam(net.parameters(),lr=1e-3)
losses = []
for epoch in range(n_epoch):
for x,y in train_dataloader:
x = x.to(device)
noise_amount = torch.rand(x.shape[0]).to(device)
noisy_x = corrupt(x,noise_amount)
pred = net(noisy_x)
loss = loss_fn(pred,x)
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss.item())
avg_loss = sum(losses[-len(train_dataloader):])/(len(train_dataloader))
print(f'Finished epoch {epoch} . Average loss for this epoch:{avg_loss:05f}')
plt.plot(losses)
plt.ylim(0,0.1)
plt.show()
训练输出:

3.4 扩散模型之采样过程
3.4.1 采样过程
思考一下,如果扩散模型(后文简称模型)在高噪声量下的预测结果不是很好,那么应该如果进行优化呢?
如果我们从完全随机的噪声开始,就应该先检查一下模型的预测结果,然后只朝着预测方向移动一小部分,比如20%。例如,假设我们有一幅夹杂了很多噪声的图像,其中可能隐藏了一些有关输入数据结构的提示,我们可以通过将它输入输入模型来获得新的预测结果。如果新的预测结果比上一次的预测结果稍微好一点(这一次的输入稍微减少了一些噪声),我们就可以根据这个新的、更好一点的预测结果继续往前迈出一步。代码如下:
n_step = 5
x = torch.rand(8,1,28,28).to(device)
step_history = [x.detach().cpu()]
pred_output_history = []
for i in range(n_steps):
with torch.no_grad():
pred = net(x)
pred_output_history.append(pred.detach().cpu())
min_factor = 1/(n_steps -i)
x = x*(1-mix_factor) + pred*mix-factor
step_history.append(x.detach().cpu())
fix, axs = plt.subplots(n_steps,2,figsize(9,4),sharex=True)
axs[0,0].set_title('x (model input)')
axs[0,1].set_title('model prediction')
for i in range(n_steps):
axs[i,0].imshow(torchvision.utils.make_grid(step_history[i])[0].clip(0,1),cmap='Greys')
axs[i,1].imshow(torchvision.utils.make_grid(pred_output_history[i])[0].clip(0,1),cmap='Greys')
如果一些顺利,重复以上过程几次后,我们就能得到一副全新的图像。
3.4.2 与DDPM的区别
下面我们将介绍所展示的模型版本与Diffusers库中DDPM版本实现过程的区别,知识点如下。
UNet2DModel模型结构相比BasciUNet模型结构更先进。
退化过程的处理方式不同。
训练目标不同,旨在预测噪声而不是“去噪”图像。
UNet2DModel模型通过调节时间步来调节噪声量,t作为额外的参数被传入前向过程。
有更多种类的采样策略可供选择,相比我们之前使用的简单版本更好。
自从DDPM论文问世以来,已经有人提出了许多改进建议,我们所创建的示例对于不同目标的设计与决策具有指导意义。你可能还需要深入了解论文“Elucidating the Design Space of Diffusion-Based Generative Models”,这篇论文对使用到的组件进行了详细的探讨,并就如何获得最佳性能提出了一些新的建议。
3.4.3 UNet2DModel 模型
Diffusers 库中的UNet2DModel 模型相比前面介绍的BasicUNet模型做了如下改进。
GroupNorm层对每个模块的输入进行了组标准化(Group Normalization)
Dropout层能使训练更加平滑。
每个块有多个ResNet层。
引入了注意力机制。
可以对时间步进行调节。
具有科学系参数的上采样模块和下采样模块。
vit = lambda: UNet(
sample_size=28,
in_channels=1,
out_channels=1,
layers_per_block=2,
block_out_channels=(32, 64, 64),
down_block_types=(
"DownBlock2D",
"AttnDownBlock2D",
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D",
"UpBlock2D",
),)
3.5 扩散模型之退化过程
3.5.2 最终的训练目标
在我们的示例中,我们尝试让模型预测“去噪”后的图像。在DDPM和许多其他扩散模型的实现中,模型会预测退化过程中使用的噪声(预测的是不带缩放系数的噪声,也就是单位正态分布的噪声)。
你可能认为预测噪声(从中可以得出“噪声”图像的样子)等同于直接预测“去噪”图像。但为什么要这么做呢?难道仅仅是为了数学上的方便么?
这里其实还有一些精妙之处。我们在训练过程中会计算不同(随机选择)时间步的损失函数,不同任务目标计算得到的结果会根据损失值向不同的“隐含权重“收敛,而“预测噪声”这个目标会使权重更倾向于预测得到更低的噪声量。你可以通过选择更复杂的目标来改变这种“隐性损失权重”,这样你所选择的噪声调度器就能直接在较高的噪声量下产生更多样本。
你也可以将模型设计成预测噪声,但需要基于一些参数对损失进行缩放。例如,一些可以使用噪声量参数或基于一些探索添加最佳噪声量实验。
综上所述,选择任务目标对模型性能有影响,许多研究人员也正在探索模型的“最佳”选项。虽然预测噪声是当前最流行的方法,但随着时间的推移,我们很有可能看到库中支持的其他任务目标,它们可以在不同情况下调整使用。
3.6 拓展知识
3.6.1 时间步的调节
UNet2DModel 模型以图片和时间步为输入。其中,时间步可转换为嵌入,然后在多个地方被输入模型。
背后的理论支持是这样的:通过向模型提供有关噪声量的信息,模型可以更好地执行任务。虽然在没有时间步的情况下也可以进行训练模型,但在某些情况下,时间步的确有助于模型性能的提升。目前来看,绝大多数模型的实现都使用了时间步。
3.6.2 采样(取样)的关键问题
假设一个模型可以用来预测“带噪”样本的噪声(或者说能预测其“去噪“版本),那么我们怎么用它来生成图像呢?
我们可以输入纯噪声,然后期待模型能一步就输出一副不带噪的图像。但是根据前面我们所学的内容,这显然是行不通的。所以我们应该在模型预测的基础上使用足够多的小步,不断迭代,每次去除一点点噪声。
具体怎么走完这些小步取决于上面的采样方法。我们不会深入讨论太多的理论细节,但你需要思考如下3个问题。
(1)你每一步想走多远?也就是说,你制定了什么样的”噪声计划“?
(2)你只使用模型当前步的预测结果指导下一步的更新方向么(采用DDPM、DDIM或其他什么方法)?你是否想要使用模型多预测几次,以通过估计一个更高阶的梯度来更新得到更准确的结果(更高阶的方法和一些离散的ODE处理器)?抑或保留一些历史的预测值来尝试指导当前步的更新(线性多步或遗传采样器)?
(3)你是否会在采样过程中额外添加一些随机噪声或完全确定的噪声?许多采样器通过提供参数(如DDIM中的‘eta’)来让用户做出选择。
对扩散模型采样器的研究进展迅速,业界已经开发出越来越多可以使用更少步骤就能找到好结果的方法。你可能会在浏览Diffusers库中不同部署方法时感到非常有意思,相关网站上也经常会有一些非常精彩的文章。