摘要:
像Stable diffusion[31]这样的大规模扩散模型非常强大,可以找到各种真实世界的应用程序,而通过微调来定制这样的模型会降低内存和时间的效率。受自然语言处理最新进展的推动,我们通过插入小型可学习模块adapters(称为适配器)来研究大型扩散模型中的参数高效调优。具体来说,我们将适配器的设计空间分解为正交因素——输入位置、输出位置以及函数形式,并执行方差分析(ANOVA),这是一种分析离散变量(设计选项)和连续变量(评估指标)之间相关性的经典统计方法。我们的分析表明,适配器的输入位置是影响下游任务性能的关键因素。然后,我们仔细研究了输入位置的选择,发现将输入位置放在交叉注意块之后可以获得最佳的性能,并通过其他可视化分析进行了验证。最后,我们提供了一个在扩散模型中参数有效调整的方法,如果不能优于完全微调的基线(如DreamBooth),也可以与各种定制任务相比,只额外增加0.75%的参数。我们的代码可以在 https://github.com/Xiang-cd/unet-finetune上找到
介绍:
扩散模型由于能够生成高质量和多样化的图像,最近变得流行起来。扩散模型在迭代生成过程中通过与条件信息的交互,在条件生成任务中具有出色的性能,这激发了其在下游任务中的应用,如文本到图像的生成,图像到图像的平移,图像恢复。
有了从海量数据中获得的知识,大规模扩散模型在下游任务中表现出了很强的先验能力。其中,DreamBooth在大规模扩散模型中调整所有参数,生成用户想要的特定对象。然而,对整个模型进行微调在计算、内存和存储成本方面效率低下。另一种方法是参数高效迁移学习方法(本文),起源于自然语言处理(NLP)领域。这些方法将可训练的小模块(称为适配器)插入到模型中,并冻结原始模型。然而,参数有效迁移学习在扩散模型领域还没有得到深入的研究。与NLP中基于变压器的语言模型相比,扩散模型中广泛使用的U-Net体系结构包含了更多的成分,如带有下/上采样算子的残差块、自注意和交叉注意。这使得参数高效迁移学习的设计空间比基于变压器的语言模型更大。
本文首次系统地研究了大规模扩散模型中参数有效调谐的设计空间。我们将Stable Diffusion作为具体情况,因为它是目前唯一的开源大规模扩散模型。特别地,我们将适配器的设计空间分解为正交因子—输入位置、输出位置和函数形式。通过在实验研究中使用方差分析,对这些因素进行组间差异分析,我们发现输入位置是影响下游任务绩效的关键因素。然后,我们仔细研究了输入位置的选择,发现将输入位置放置在交叉注意块之后,可以最大限度地鼓励网络感知输入提示的变化(见图11),从而获得最佳性能。
基于我们的研究,我们的最佳设置可以达到与完全微调方法相比(反正就是我们的最佳设置的效果与Dreambooth差不多)
2.相关介绍:
2.1扩散模型:

2.2稳定扩散中的结构:
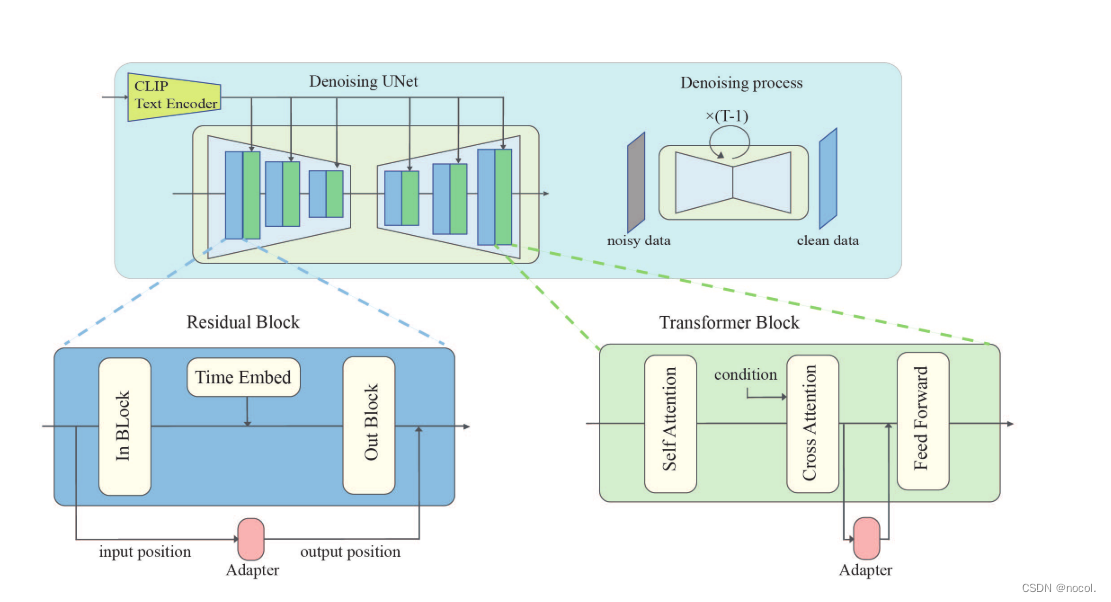
图3。背景。左上角的图显示了基于unet的扩散模型的总体架构。右上方显示了扩散模型如何通过T - 1步骤从有噪声的数据中去除噪声。图的下半部分为残差块和变压器块的结构。适配器(图中红色的块)是插入模型中参数较少的模块,用于参数高效迁移学习。
目前,最流行的扩散模型体系结构是基于u - net的体系结构。具体来说,Stable Diffusion中基于u - net的架构如图3所示。U-Net由堆叠的基本块组成,每个基本块包含一个变压器块和一个剩余块。在变压器块中,有三种子层:自注意层、交叉注意层和全连接前馈网络。注意层对查询Q∈Rn×dk,键值对K∈Rm×dk,V∈Rm×dv进行操作

其中n为查询次数,m为键值对的个数,dk为键的维数,dv为值的维数。在自我注意层中,x∈Rn×dx是唯一的输入。在条件扩散模型的交叉注意层中,有两个输入x∈Rn×dx, c∈Rm×dc,其中x为先验块的输出,c表示条件信息。全连接前馈网络,由两个具有ReLU激活函数的线性变换组成:
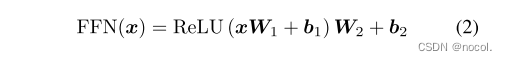
其中,W1∈Rd×dm,W2∈Rdm×d为可学权值,b1∈Rdm, b2∈Rd为可学偏差。剩余块由一系列卷积层和激活组成,其中时间嵌入通过加法操作注入到剩余块中
2.3参数高效迁移学习:
迁移学习是一种利用从一个任务中学习到的知识来提高相关任务绩效的技术。对下游任务进行预训练再进行迁移学习的方法被广泛采用。然而,传统的迁移学习方法需要大量的参数,这是昂贵的计算和内存密集型。
参数高效迁移学习是在自然语言处理领域中首次提出的。参数高效迁移学习的关键思想是减少更新参数的数量。这可以通过更新模型的一部分或添加额外的小模块来实现。一些参数有效的迁移学习方法(如适配器[16]、LoRA[17])选择向模型添加名为适配器的额外小模块。相反,其他方法(前缀调优[22]、提示调优[21])将一些可学习的向量置于激活或输入之前。大量的研究已经证明,在自然语言处理领域中,这种高效的参数微调方法可以在参数较少的情况下取得可观的效果。
3.扩散模型中参数高效学习的设计空间
尽管参数高效迁移学习在自然语言处理中取得了成功,但由于残余块和交叉注意等成分的存在,该技术在扩散模型中还没有得到充分的理解。在分析扩散模型中的参数高效调整之前,我们将适配器的设计空间分解为三个正交因子——输入位置、输出位置和函数形式。本工作考虑了Stable Diffusion[31],因为它是目前唯一的开源大规模扩散模型(其基于u - net的架构见图3)。
下面我们详细说明了输入位置、输出位置以及基于稳定扩散体系结构的函数形式。
3.1输入位置和输出位置:
输入位置是适配器输入的来源,输出位置是适配器输出的位置。为了便于理解,如图4所示,位置是根据相邻层命名的。例如,SAin表示位置对应自注意层的输入,Transout表示变压器块的输出,CAc表示交叉注意层的条件输入。

图4。激活位置说明。通常,激活位置的主名是模型中特定块的别名,激活位置的下标解释了激活和块之间的关系。
在我们的框架中,输入位置可以是图4中描述的任何一个激活位置。因此,总共有10个不同的输入位置选项。至于输出,由于加法是可交换的,所以有些位置是等价的。例如,将输出放到SAout相当于将输出放到CAin。因此,输出位置的选项总共减少到7个。另一个约束是输出位置必须放置在输入位置之后。
3.2adapter模型架构:
函数形式描述了适配器如何将输入转换为输出。我们分别给出了变压器块和残差块中适配器的函数形式(见图5),其中两者都包含一个下采样算子、一个激活函数、一个上采样算子和一个缩放因子。下采样算子减小输入的维数,上采样算子增大输入的维数,以保证输出与输入具有相同的维数。输出进一步乘以缩放因子s,以控制其对原始网络的影响强度。
其中,变压器块适配器使用低秩矩阵Wdown和Wup分别作为下采样和上采样算子,残差块适配器使用3×3卷积层Convdown和Convup分别作为下采样和上采样算子。注意,这些卷积层只改变通道的数量,而不改变空间大小。此外,剩余块适配器还使用组归一化[38]运算符处理其输入。
在我们的设计选择中,我们包括了不同的激活函数和比例因子。激活函数包括ReLU、Sigmoid、SiLU和标识符作为我们的设计选择,尺度因子包括0.5、1.0、2.0、4.0。

图5。变压器块和剩余块中适配器的模型架构。
4.用方差分析发现关键因素
如前所述,在如此大的离散搜索空间中找到最优解是一个挑战。为了发现设计空间中哪个因素对绩效的影响最大,我们利用单向方差分析(ANOVA)方法量化模型绩效与因素之间的相关性,该方法被广泛应用于许多领域,包括心理学、教育、生物学和经济学。
方差分析背后的主要思想是将数据中的总变异分成两部分:组内变异(MSE)和组间变异(MSB)。MSB测量组间均值的差异,而组内的变异测量个体观察值与各自组间均值的差异。 方差分析中使用的统计检验基于f -分布,它比较组间变异与组内变异的比率(f -统计量)。如果f统计量足够大,它表明组之间的均值有显著差异,这表明有很强的相关性。

图6.DreamBooth任务中适配器的性能(即CLIP
similarity↑)和输入输出位置之间的关系。

图7。微调任务中性能(即FID↓)与适配器输入输出位置的关系(我所关注的重点)。
5.实验
我们首先在第5.1节介绍了我们的实验设置。然后我们在第5.2节中分析设计空间中哪个因素是最关键的。在发现输入位置的重要性后,我们在第5.3节对其进行了详细的消融研究。最后,我们在5.4节对我们的最佳设置和DreamBooth(即微调所有参数)进行了全面的比较。
5.1 设置
任务和数据集。在扩散模型中,我们考虑了两个迁移学习任务。
DreamBooth任务。第一个任务是对少于10个输入图像的扩散模型进行个性化,正如在DreamBooth[32]中提出的那样。为了简单起见,我们称之为DreamBooth任务。DreamBooth的培训数据集由两组数据组成:个性化数据和正则化数据。(也就是使用DreamBooth方法进行微调?)个性化数据是用户提供的特定对象(例如,一只白狗)的图像。正则化数据是类似于个性化数据的一般对象的图像(例如,不同颜色的狗)。个性化数据大小小于10,模型可以收集或生成正则化数据。DreamBooth使用稀有标记[V]和类字Cclass来区分正则化数据和个性化数据。特别是,对于正则化数据,提示符将是“Cclass的照片”;有了个性化数据,提示将是“[V] class的照片”。其中Cclass是描述数据的一般类别(如dog)的一个词。我们从互联网和实景摄影中收集个性化数据,也从DreamBooth(总共33个)收集数据。我们使用稳定扩散本身来生成相应的正则化数据,条件是提示“a photo of class”。
微调任务。另一项任务是对一小组文本图像对进行微调。为了简单起见,我们称之为微调任务。在[39]之后,我们考虑对花卉数据集[27]和8189张图像进行微调,并使用相同的设置。我们用提示符“a photo of Fname”为每张图片加标题,其中Fname是图片类的花名。
我们使用AdamW[23]优化器。对于DreamBooth任务,我们将学习速率设置为1e-4,这可以让DreamBooth和我们的方法在1k步左右收敛。将适配器大小固定为1.5M (UNet模型的0.17%),并使用2.5k步进行训练。对于在一小组文本图像对上进行微调的任务,我们将学习速率设置为1e-5,将适配器大小固定为6.4M (UNet模型的0.72%),并训练60k步。
为了提高采样效率,我们选择了DPM-Solver[24]作为采样算法,采样步长为25步,分级器自由引导(cfg)[15]尺度为7.0。在某些情况下,我们使用5.0的cfg尺度以获得更好的图像质量。
对于DreamBooth任务,我们使用[10]中提出的CLIP空间中的图像距离来评估真实性。具体来说,对于每个个性化目标,我们使用提示符“A photo of [V] Cclass”生成32张图像。度量是生成的图像与个性化训练集的图像之间的平均成对的CLIP-space余弦相似度(CLIP相似度)
对于对一小组文本图像对进行微调的任务,我们使用FID评分[13]来评估训练图像和生成图像之间的相似性。我们从训练集中随机抽取5k条提示,使用这些提示生成图像,然后将生成的图像与训练图像进行比较,计算出FID。
5.2 设计空间的方差分析(ANOVA)
回想一下,我们将设计空间分解为输入位置、输出位置和功能形式等因素。我们对这些设计维度执行方差分析方法(详见第4节)。我们考虑DreamBooth任务的效率,因为它需要更少的培训步骤。如图8所示,按输入位置分组时,f统计量较大,说明输入位置是影响模型性能的关键因素。当按输出位置分组时,其相关性较弱。 当按函数形式分组时(两个激活函数 和比例因子),其f统计量在1左右,说明组间的变异性与组内的变异性相似,说明组均值之间没有显著差异。我们进一步可视化了不同输入位置和输出位置下的性能。图6 是DreamBooth任务的结果。图7显示了微调任务的FID结果。

图8。通过分组输入位置、输出位置、激活函数和比例因子对方差分析进行f统计。按输入位置分组时f统计量较大,说明与输入位置有显著关系。
如上所述,我们得出结论,适配器的输入位置是影响参数高效迁移学习性能的关键因素。
5.3输入位置的消融实验
如图6和图7所示,我们发现输入位置为CAc或CAout的适配器在这两个任务上都有很好的性能。在图9中,我们给出了不同适配器输入位置的个性化扩散模型中生成的样本。输入位置在CAc或CAout的适配器能够生成与微调所有参数相当的个性化图像,而输入位置在其他地方的适配器则不能。

图9。生成了不同适配器输入位置的个性化扩散模型样本。所有的样本都以“a photo of [V] class”为条件,值得注意的是,成功的方法会生成正确的图像,而失败的方法很可能生成类似于正则化数据的图像。
我们进一步计算给出提示“a photo of [V] Cclass”和“a photo ofCclass”的噪声预测的差值。管道如图10所示,在这个管道中,我们首先从正则化数据中对一幅图像添加噪声,在给定这两种提示时,使用U-Net预测噪声,并将两种预测噪声的差值可视化。如图11所示,输入位置为CAc或CAout的适配器与噪声预测之间存在显著差异。

图10。实验管道的噪声预测差异可视化。
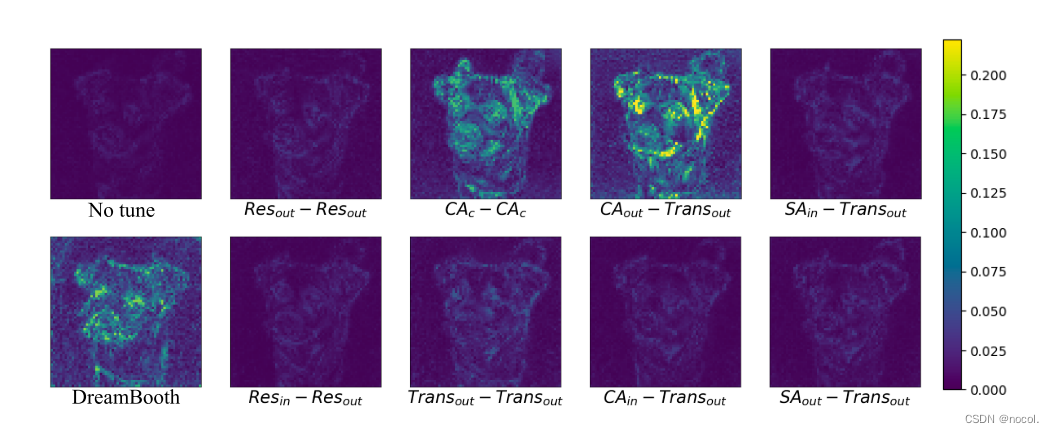
图11。不同设定的噪声预测差异。“无调”方法使用原始的稳定扩散模型,没有任何微调。所有的适配器方法都以输入-输出的形式记录下来。我们发现输入位置为CAout和CAc的适配器对提示符的变化反应较好。
5.4与DreamBooth相比
我们在图12中显示了DreamBooth任务中每种情况的结果,这表明我们的方法在大多数情况下更好。
我们还在花卉数据集上的微调任务中比较了我们的最佳设置和完全微调的方法。该方法的FID为24.49,优于完全调优法的28.15。
6.相关工作
个性化。基于web数据训练的大规模文本-图像扩散模型可以生成高分辨率和多样化的图像,图像内容由输入文本控制,但往往缺乏针对用户希望的特定对象进行个性化生成的能力。
最近的工作,如文本反演[10]和DreamBooth[32],旨在通过微调对象的一小组图像上的扩散模型来解决这个问题。文本反演只调整了一个词的嵌入。为了获得更强的性能,DreamBooth用正则化损失调优所有参数,以防止过拟合。
参数高效迁移学习。参数高效迁移学习起源于nlp领域,如适配器[16]、前缀调优[22]、提示调优[21]和LoRA[17]。 具体来说,适配器[16]在变压器块之间插入具有非线性激活函数f(·)的小型低秩多层感知器(MLP);前缀调优[22]将可调前缀向量添加到每个注意层的键和值;提示调优[21]通过添加可调的输入词嵌入简化了前缀调优;LoRA[17]将可调的低秩矩阵注入到变压器块的查询和值投影矩阵中。
虽然这些参数高效迁移学习方法的形式和动机各不相同,但最近的工作[12]通过指定一组因子来描述纯变压器[37]中参数高效迁移学习的设计空间,对这些方法提出了统一的观点。这些因素包括修改的表示方式、插入形式、函数形式,复合函数。相比之下,我们的方法侧重于U-Net,其组件比纯变压器多,因此设计空间更大。此外,我们使用一种更简单的方法将设计空间分解为正交因子,即输入位置、输出位置和函数形式。

图12。性能与DreamBooth相比。我们的方法在大多数情况下执行得更好。
扩散模型的迁移学习。有一些方法可以通过传递扩散模型来识别特定的对象,或者通过调整整个模型来进行语义编辑[19,32]。之前的工作[39]试图将大型扩散模型转换为小数据集上的图像到图像模型,但调优的参数总数几乎是原始模型的一半。 使扩散模型接受新的条件,并引入比我们的模型更多的参数。并行工作[1]也在Stable Diffusion上进行参数高效迁移学习,他们的方法在DreamBooth[32]任务上可以达到与完全微调方法相当的结果,而他们的方法是基于同时在多个位置添加适配器,导致设计空间更加复杂。
7. 结论
本文通过在扩散模型中插入适配器,对参数高效迁移学习的设计空间进行了系统的研究。将适配器的设计空间分解为输入位置、输出位置和函数形式三个正交因子。。通过方差分析(ANOVA)发现,适配器的输入位置是影响下游任务性能的关键因素。然后,我们仔细研究了输入位置的选择,发现将输入位置放在交叉注意块之后可以获得最佳的性能,并通过其他可视化分析进行了验证。最后,我们提供了一个在扩散模型中参数有效调整的方法,如果不能优于完全微调的基线(如DreamBooth),也可以与各种定制任务相比,只额外增加0.75%的参数。









![计算机视觉与深度学习-全连接神经网络-详解梯度下降从BGD到ADAM - [北邮鲁鹏]](https://img-blog.csdnimg.cn/043591377130437e907be8d9fc18275d.gif)