python正则表达(06)
文章目录
- python正则表达(06)
- 1 正则表达式概念
- 2 正则的三个基础方法
- 2.1 match、search、findall三个基础方法
- 2.2 re.match() 函数
- 2.2.1 re.match(匹配规则,被匹配字符串)
- 2.2.2验证是否开头匹配,match是匹配开头,后面的是不匹配
- 2.3 re.search()
- 2.3.1 search(匹配规则,被匹配字符串)
- 2.3.2 search整个字符串都找不到,返回None
- 2.4 re.findall(匹配规则,被匹配字符串)
- 2.4.1 匹配到返回值
- 2.4.2找不到返回空list:[]
- 3 元字符匹配
- 3.1 单字符匹配规则:
- 3.2 匹配示例:
- 3.2.1 找出全部数字: \d
- 3.2.2 找出特殊字符: \W
- 3·找出全部英文字母:[a-zA-Z] 或者字母数字[a-zA-Z0-9]
- 3.3 数量匹配
- 3.4 边界匹配
- 3.5 分组匹配
- 3.6 匹配规则组合图
- 3.7 匹配案例
- 3.7.1 匹配账号,只能由字母和数字组成,长度限制6到10位
- 3.7.2 配QQ号,要求纯数字,长度5-11,第一位不为0
参考视频: 黑马保姆级视频
**参考API: **菜鸟教程
1 正则表达式概念
正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符
来检索、替换那些符合某个模式(规则)的文本。
简单来说:通过规则去验证字符串是否匹配。
比如,验证一个字符串是否是符合条件的电子邮箱地址,只需要配置好正则规则,即可匹配任意邮箱。
比如通过正则规则: (^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$) 即可匹配一个字符串是否是标准邮箱格式
2 正则的三个基础方法
2.1 match、search、findall三个基础方法
match 是从头匹配,匹配第一个命中项 ,未匹配返None
search全局搜索,匹配第一个命中项, 未匹配返None
findall 全局匹配,匹配全部命中项,未匹配返回值[]列表,如果正则有(),会每个组结果返回结果
Python正则表达式,使用re模块,并基于re模块中三个基础方法来做正则匹配。
分别是:match、search、findall三个基础方法
从被匹配字符串开头进行匹配,匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空。
2.2 re.match() 函数
2.2.1 re.match(匹配规则,被匹配字符串)
注意:match()尝试从字符串的起始位置匹配一个模式**,如果不是起始位置匹配成功的话**,match() 就返回 none
import re
s = 'python itheima python itheima python itheima'
# 第一个是匹配规则,第二个是被匹配,要筛选的数据,返回匹配的下标span=(0, 6)
result = re.match("python", s )
print(result) # 打印结果: <re.Match object; span=(0, 6), match='python'>
print(result.span()) # 打印为 (0,6)
print(result.group()) # python
2.2.2验证是否开头匹配,match是匹配开头,后面的是不匹配
import re
s='1python itheima python itheima python itheima'
result=re.match('python' s)
print(result) # None
match是匹配开头,后面的是不匹配
2.3 re.search()
2.3.1 search(匹配规则,被匹配字符串)
注意:搜索整个字符串,找出匹配的。从前向后,找到第一个后,就停止,不会继续向后
import re
s='1python666itheima666python666'
result=re.search('python',s)
print(result) # <re.Match object; span=(1, 7), match='python'>
print(result.span()) # (1, 7)
print(result.group()) # python
2.3.2 search整个字符串都找不到,返回None
import re
s='itheima666'
result=re.search('python', s)
print(result) # None
2.4 re.findall(匹配规则,被匹配字符串)
2.4.1 匹配到返回值
注意:匹配整个字符串,找出全部匹配项
import re
s='1python666itheima666python666'
result = re.findall('python', s)
print(result) # ['python','python']
2.4.2找不到返回空list:[]
import re
s='1python666itheima666python666'
result =re.findall('itcast', s)
print(result) # []
3 元字符匹配
基础的字符串匹配,正则最强大的功能在于元字符匹配规则
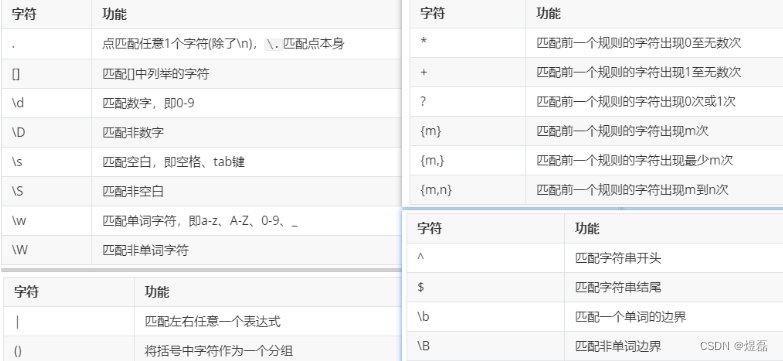
3.1 单字符匹配规则:
| 字符 | 功能 |
|---|---|
| . | 点匹配任意1个字符(除了\n),\.匹配点本身 |
| [] | 匹配[]中列举的字符 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字 |
| \s | 匹配空白,即空格、tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_ |
| \W | 匹配非单词字符 |
3.2 匹配示例:
3.2.1 找出全部数字: \d
import re
s = "itheima1 @@python2 !!666 ##itcast3"
# 字符串前面带上r的标记,表示字符串中转义字符串无效,就是普通字符的意思
result = re.findall(r'\d', s)
print(result) # 打印:['1', '2', '6', '6', '6', '3']
3.2.2 找出特殊字符: \W
import re
s = "itheima1 @@python2 !!666 ##itcast3"
# 字符串前面带上r的标记,表示字符串中转义字符串无效,就是普通字符的意思
result = re.findall(r'\W', s)
print(result) # [' ', '@', '@', ' ', '!', '!', ' ', '#', '#']
3·找出全部英文字母:[a-zA-Z] 或者字母数字[a-zA-Z0-9]
import re
s="itheima1 @@python2 !!666 ##itcast3"
# 字符串前面带上r的标记,表示字符串中转义字符串无效,就是普通字符的意思
result = re.findall(r'[a-zA-Z]', s)
print(result)
# 打印:['i', 't', 'h', 'e', 'i', 'm', 'a', 'p', 'y', 't', 'h', 'o', 'n', 'i', 't', 'c', 'a', 's', 't']
3.3 数量匹配
| 字符 | 功能 |
|---|---|
| * | 匹配前一个规则的字符出现0至无数次 |
| + | 匹配前一个规则的字符出现1至无数次 |
| ? | 匹配前一个规则的字符出现0次或1次 |
| {m} | 匹配前一个规则的字符出现m次 |
| {m,} | 匹配前一个规则的字符出现最少m次 |
| {m,n} | 匹配前一个规则的字符出现m到n次 |
3.4 边界匹配
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
3.5 分组匹配
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| () | 将括号中字符作为一个分组 |
3.6 匹配规则组合图
3.7 匹配案例
注意:正则不要随意加空格
3.7.1 匹配账号,只能由字母和数字组成,长度限制6到10位
规则为:^[0-9a-zA-Z]{6,10}$
import re
r = '^[0-9a-zA-Z]{6,10}$'
s = '123456789a'
print(re.findall(r,s)) # 打印:['123456789a']
3.7.2 配QQ号,要求纯数字,长度5-11,第一位不为0
规则 : ^[1-9][0-9]{4,10}&
import re
r = '^[1-9][0-9]{4,10}$' # 注意:[1-9]匹配第一位,[0-9]匹配后面4到10位
s = '123456789'
print(re.findall(r,s)) #['123456789']
3.7.3 匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
规则为:^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$
import re
r = r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)' # 技巧使用findall整个整体包起来
s = 'a.b.c.d@qq.com.a.z'
print(re.findall(r, s))
打印结果:[('a.b.c.d@qq.com.a.z', '.d', 'qq', '.z')]
优化:使用match
import re
r = r'^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$'
s = 'a.b.c.d@qq.com.a.z'
print(re.match(r, s))
打印结果:<re.Match object; span=(0, 18), match='a.b.c.d@qq.com.a.z'>