文章目录
系列文章索引
Python爬虫基础(一):urllib库的使用详解
Python爬虫基础(二):使用xpath与jsonpath解析爬取的数据
Python爬虫基础(三):使用Selenium动态加载网页
Python爬虫基础(四):使用更方便的requests库
Python爬虫基础(五):使用scrapy框架
一、Selenium简介
1、什么是selenium?
(1)Selenium是一个用于Web应用程序测试的工具。
(2)Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
(3)支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器完成测试。
(4)selenium也是支持无界面浏览器操作的。
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
2、为什么使用selenium
我们打开京东,看到有一个秒杀的模块,从网页源码中也可以定位到:
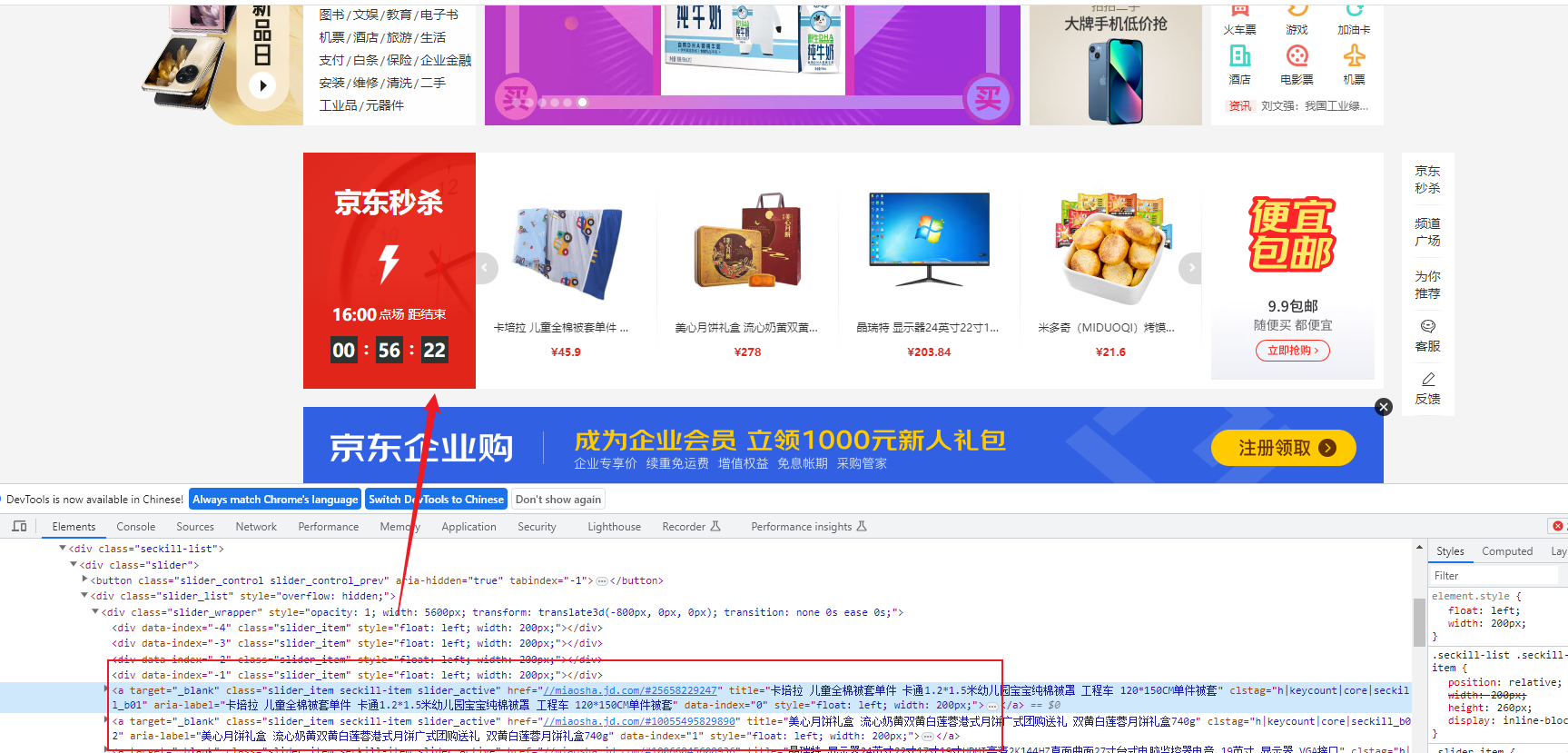
但是我们使用urllib爬取:
import urllib.request
url = 'https://www.jd.com/'
urllib.request.urlretrieve(url,'jd.html')
爬取的网页,我们全局搜索发现,并没有秒杀这部分内容。
因为秒杀这部分内容,是在js中动态加载的,而selenium就可以模拟浏览器功能,自动执行网页中的js代码,实现动态加载。
3、安装selenium
(1)谷歌浏览器驱动下载安装
查看谷歌浏览器的版本:帮助->关于google chrome,查看版本。
根据版本查找对应的chromedriver,大版本对应就可以,小版本不需要关心,下载地址(第一个网速比较慢),32位和64位都能用:
http://chromedriver.storage.googleapis.com/index.html
https://registry.npmmirror.com/binary.html?path=chromedriver/
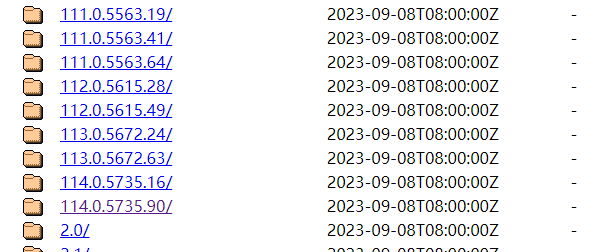
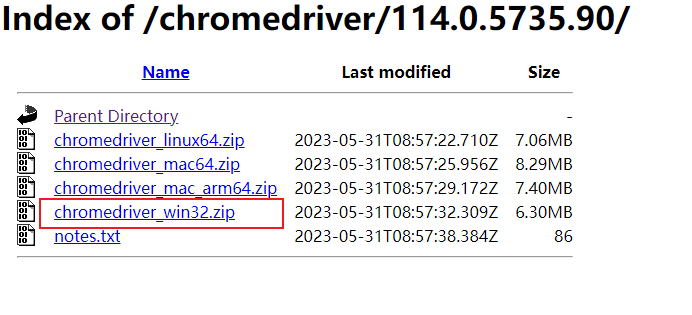
如果是最新版的谷歌浏览器,以上可能没有同步更新,试试下面的网站:
https://googlechromelabs.github.io/chrome-for-testing/
下载之后是一个压缩文件。

将解压出来的exe文件,放到python项目的根目录下(为了方便使用,不这样做的话,使用时指定路径也可)。
(2)安装selenium
# 进入到python安装目录的Scripts目录
d:
cd D:\python\Scripts
# 安装
pip install selenium -i https://pypi.douban.com/simple
二、Selenium使用
1、简单使用
简单三步,轻松使用,获取网页的全部内容(网页完全加载完毕之后的)。
# (1)导入selenium
from selenium import webdriver
# (2) 创建浏览器操作对象,就是指定我们驱动的路径
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# (3)访问网站
url = 'https://www.jd.com/'
browser.get(url)
# page_source获取网页源码
content = browser.page_source
with open('jd.html','w',encoding='utf-8') as fp:
fp.write(content)
2、元素定位
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先要找到它们,WebDriver提供很多定位元素的方法。
from selenium import webdriver
from selenium.webdriver.common.by import By
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据id来找到对象 id = su
button = browser.find_element(by = By.ID, value = 'su')
print(button)
# 根据标签属性的属性值来获取对象的 name = wd
button = browser.find_element(by = By.NAME, value = 'wd')
print(button)
# 根据xpath语句来获取对象 xpath语法
button = browser.find_element(by = By.XPATH, value = '//input[@id="su"]')
print(button)
# 根据标签的名字来获取对象
button = browser.find_element(by = By.TAG_NAME, value = 'input')
print(button)
# 使用的bs4的语法来获取对象
button = browser.find_element(by = By.CSS_SELECTOR, value = '#su')
print(button)
# 获取链接文本
button = browser.find_element(by = By.LINK_TEXT, value = '百度一下')
print(button)
By参数 包含许多可选的选项:

3、获取元素信息
from selenium import webdriver
from selenium.webdriver.common.by import By
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'http://www.baidu.com'
browser.get(url)
input = browser.find_element(by = By.ID, value = 'su')
# 获取标签的属性 获取class属性
print(input.get_attribute('class'))
# 获取标签的名字
print(input.tag_name)
# 获取元素文本
a = browser.find_element(by = By.LINK_TEXT, value = '新闻')
print(a.text)
4、交互
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建浏览器对象
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# url
url = 'https://www.baidu.com'
browser.get(url)
# 休眠2秒
import time
time.sleep(2)
# 获取文本框的对象
input = browser.find_element(by = By.ID, value = 'kw')
# 在文本框中输入周杰伦
input.send_keys('周杰伦')
time.sleep(2)
# 获取百度一下的按钮
button = browser.find_element(by = By.ID, value = 'su')
# 点击按钮
button.click()
time.sleep(2)
# 滑到底部
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element(by = By.XPATH, value = '//a[@class="n"]')
# 点击下一页
next.click()
time.sleep(2)
# 回到上一页
browser.back()
time.sleep(2)
# 回去
browser.forward()
time.sleep(3)
# 退出
browser.quit()
三、Phantomjs使用(停更)
1、什么是Phantomjs
(1)是一个无界面的浏览器
(2)支持页面元素查找,js的执行等
(3)由于不进行css和gui渲染,运行效率要比真实的浏览器要快很多
Phantomjs已经过时了,推荐使用Chrome handless,高版本的Selenium已经不支持Phantomjs了
2、下载
官网:http://wenku.kuryun.com/docs/phantomjs/download.html

将下载的phantomjs.exe文件拷贝到项目目录(为了方便使用,不这样做的话,使用时指定路径也可)。
3、使用Phantomjs
(1)获取PhantomJS.exe文件路径path
(2)browser = webdriver.PhantomJS(path)
(3)browser.get(url)
扩展:保存屏幕快照:browser.save_screenshot(‘baidu.png’)
from selenium import webdriver
path = 'phantomjs.exe'
browser = webdriver.PhantomJS(path)
url = 'https://www.baidu.com'
browser.get(url)
# 保存快照
browser.save_screenshot('baidu.png')
import time
time.sleep(2)
# 最新版selenium不支持该语法
input = browser.find_element_by_id('kw')
input.send_keys('昆凌')
time.sleep(3)
browser.save_screenshot('kunling.png')
四、Chrome handless无界面模式
1、简介
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致,性能更高。
系统要求:
Chrome:Unix\Linux 系统需要 chrome >= 59、Windows 系统需要 chrome >= 60
Python3.6 +
Selenium3.4.* +
ChromeDriver2.31 +
2、基本使用
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def share_browser():
'''
该方法的内容,都不需要动,只需要修改自己的chrome浏览器路径
'''
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path是你自己的chrome浏览器的文件路径
path = r'C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
return browser
browser = share_browser()
url = 'https://www.baidu.com'
browser.get(url)
browser.save_screenshot('baidu.png')