//checkpoint :
sc.setCheckpointDir("hdfs://Master:9000/ck") // 设置检查点
val rdd = sc.textFile("hdfs://Master:9000/input/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) // 执行wordcount任务的转换
rdd.checkpoint // Mark this RDD for checkpointing.
rdd.isCheckpointed
rdd.count //触发计算,日志显示:ReliableRDDCheckpointData: Done checkpointing RDD 27 to hdfs://hadoop001:9000/ck/fce48fd4-d76f-
4322-8d23-6a48d1aed7b5/rdd-27, new parent is RDD 28
rdd.isCheckpointed // res61: Boolean = true
rdd.getCheckpointFile // Option[String] = Some(hdfs://Master:9000/ck/b9a5add8-18d8-4056-9e8e-271d9522a29c/rdd-4)coalesce :
总所周知,spark的rdd编程中有两个算子repartition和coalesce。公开的资料上定义为,两者都是对spark分区数进行调整的算子。
repartition会经过shuffle,其实际上就是调用的coalesce(shuffle=true)。
coalesce,默认shuffle=false,不会经过shuffle。
当前仅针对coalesce算子考虑,我们看一下官方的定义:
大概意思为:如果你想要从1000个分区到100个分区,并且不经过shuffle,近乎平均分配10个父分区到1个子分区。
首先我说下我个人简单理解:不经过shuffle,就意味着coalesce算子前后都是在一个stage中的。从该stage开始到coalesce算子之前的任务的迭代执行的并行度都是1000,从coalesce算子开始到该stage结束的任务的迭代执行的并行度都是100。
val rdd1 = sc.parallelize(1 to 10, 10)
// 重新分区,分为两个2 ,不产生shuffle
val rdd2 = rdd1.coalesce(2, false)
// 获取新的RDD分区数
rdd2.partitions.length
def func1(index:Int,iter:Iterator[Int]):Iterator[String] = {
iter.toList.map(x=>"[PartID:"+index + ",value=" + x +"]").iterator
}
// 查看分区后的结果:
rdd2.mapPartitionsWithIndex(func1).collect
repartition:
val rdd1 = sc.parallelize(1 to 10, 4)
val rdd2 = rdd1.repartition(5)collect、toArray
将RDD转换为Scala的数组。
collectAsMap
与collect、toArray相似。collectAsMap将key-value型的RDD转换为Scala的map。
注意:map中如果有相同的key,其value只保存最后一个值。
# 创建一个2分区的RDD
scala> var z = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
z: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[129] at parallelize at <console>:21
# 输出所有分区的数据
scala> z.collect
res44: Array[(String, Int)] = Array((cat,2), (cat,5), (mouse,4), (cat,12), (dog,12), (mouse,2))
# 转化为字典
scala> z.collectAsMap
res45: scala.collection.Map[String,Int] = Map(dog -> 12, cat -> 12, mouse -> 2)
scala>
collectAsMap
val rdd = sc.parallelize(List(("a", 1), ("b", 2)))
rdd.collectAsMap
//res2: scala.collection.Map[String,Int] = Map(b -> 2, a -> 1)combineByKey与aggregateByKey相比较:
-
1.相同点:
-
两者都能映射key值分别进行分区内计算和分区间计算。
2. 不同点:
-
combineByKey有三个参数列表而且不需要初始值,而aggregateByKey只有两个参数列表且需要初始值。
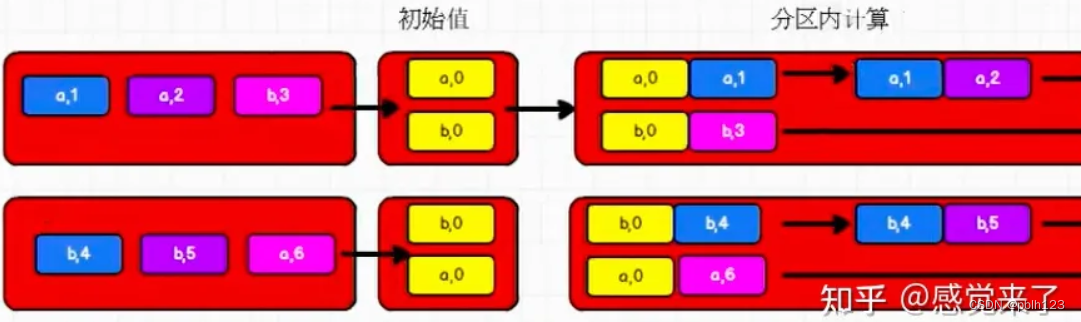
aggregateByKey分区内计算示意图
//aggregateByKey存在函数颗粒化,有两个参数列表
//第一个参数列表,需要传递一个参数,表示为初始值
// 主要当碰见第一个key时候,和value进行分区内计算
//第二个参数列表,需要传递2个参数
// 第一个参数表示分区内计算
// 第二个参数表示分区间计算
rdd.aggregateByKey(zeroValue = 0)(
(x, y) => math.max(x, y),
(x, y) => x + y
).collect().foreach(println)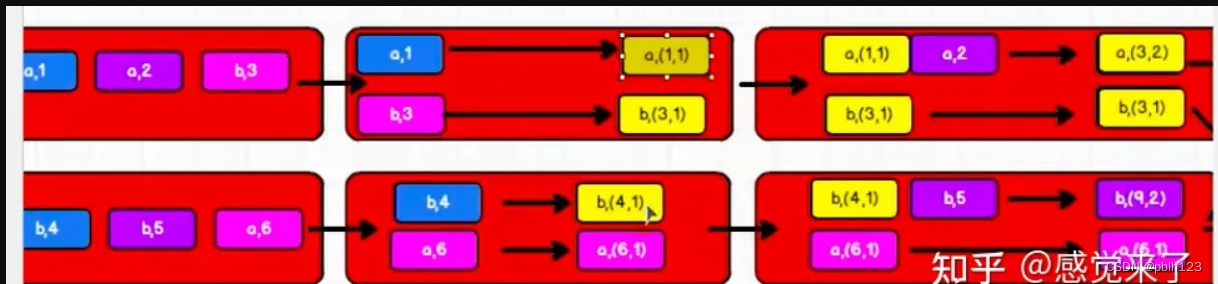
combineByKey分区内计算示意图
//combineByKey方法需要三个参数:
//第一个参数表示:将相同key的第一个数据进行结构转换,实现操作
//第二个参数:分区内的计算规则
//第三个参数:分区间的计算规则
val newRDD: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1 Int: , t2: Int) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
combineByKey与aggregateByKey两者的核心区别,就是在组内初始计算时少许不同。
combineByKey // 是在这个PairRDDFunctions类下的方法
val rdd1 = sc.textFile("hdfs://Master:9000/input/word.txt").flatMap(_.split(" ")).map((_, 1))
val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) // 等价与reduceByKey(_ + _),结果:Array[(String, Int)] =
Array((is,1), (Giuyang,1), (love,2), (capital,1), (Guiyang,1), (I,2), (of,1), (Guizhou,2), (the,1))
rdd2.collect
val rdd3 = rdd1.combineByKey(x => x + 10, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) // 将每个key的value各自加10,结果:Array[(String, Int)]
rdd3.collect
val rdd4 = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val rdd5 = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
val rdd6 = rdd5.zip(rdd4)
一、Rdd行动算子
1、【countByKey】统计存储在rdd中元组的key的个数,key是相同的就会进行计数+1。通过这个key 会生成一个Map Map中的key是原有中的key,value是原有key的个数;
2、【countByValue】统计在Rdd中存储元素的个数。会将rdd中每一个元组看作为一个value,若这个元组中元素是相同的,此时就会将生成Map中的value+1;
3、【filterByRange】对rdd中的元素过滤,并返回指定内容的数据。该函数作用于键值对RDD,对RDD中的元素进行过滤,返回键在指定范围中的元素;
4、【flatMapValues】主要是对存在元组中的value进行扁平化处理;
countByKey // 计算每个键出现的次数
val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))
rdd1.countByKey
rdd1.countByValue // countByValue返回每个值的出现次数filterByRange // 【filterByRange】对rdd中的元素过滤,并返回指定范围的内容数据
val rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1)))
val rdd2 = rdd1.filterByRange("b", "d")
rdd2.collectflatMapValues
val rdd3 = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))
rdd3.flatMapValues(_.split(" "))foldByKey
函数原型:
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
def foldByKey(zeroValue: V, numPartitions: Int)(func: (V, V) => V): RDD[(K, V)]
def foldByKey(zeroValue: V, partitioner: Partitioner)(func: (V, V) => V): RDD[(K, V)]作用:将RDD[K,V]根据K将V做折叠、合并处理,zeroValue作为初始参数,调用func得到V,
再根据Key按照func对V进行调用。
例子:
scala> var rdd1 = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[7] at makeRDD at <console>:27
scala> rdd1.foldByKey(0)(_+_).collect
res3: Array[(String, Int)] = Array((A,2), (B,3))说明: 将0应用到_+_上,Array(("A",0+0),("A",2+0)) 再进一步处理得到Array(("A",0+2))最终得到Array(("A",2))
foldByKey
函数原型:
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
def foldByKey(zeroValue: V, numPartitions: Int)(func: (V, V) => V): RDD[(K, V)]
def foldByKey(zeroValue: V, partitioner: Partitioner)(func: (V, V) => V): RDD[(K, V)]作用:将RDD[K,V]根据K将V做折叠、合并处理,zeroValue作为初始参数,调用func得到V,
再根据Key按照func对V进行调用。
例子:
scala> var rdd1 = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[7] at makeRDD at <console>:27
scala> rdd1.foldByKey(0)(_+_).collect
res3: Array[(String, Int)] = Array((A,2), (B,3))说明: 将0应用到_+_上,Array(("A",0+0),("A",2+0)) 再进一步处理得到Array(("A",0+2))最终得到Array(("A",2))
foldByKey
val rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
val rdd3 = rdd2.foldByKey("")(_+_)
val rdd = sc.textFile("hdfs://Master:9000/input/word.txt").flatMap(_.split(" ")).map((_, 1))
rdd.foldByKey(0)(_+_)foreachPartition // foreachPartition是spark-core的action算子,该算子源码中的注释是:Applies a function func to each parition of this RDD.(将函数func应用于此RDD的每个分区)
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.foreachPartition(x => println(x.reduce(_ + _)))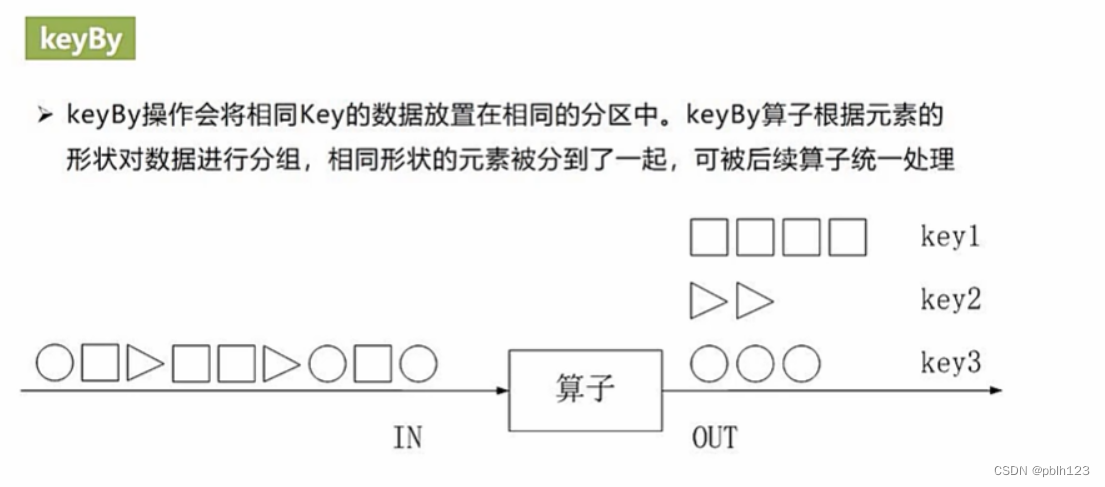
keyBy
val rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val rdd2 = rdd1.keyBy(_.length)
rdd2.collectkeys values
val rdd1 = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
rdd2.keys.collect
rdd2.values.collect