目录
编辑
一、Hive优化总体思想
二、具体优化措施、策略
2.1 分析问题得手段
2.2 Hive的抓取策略
2.2.1 策略设置
2.2.2 策略对比效果
2.3 Hive本地模式
2.3.1 设置开启Hive本地模式
2.3.2 对比效果
2.3.2.1 开启前
2.3.2.2 开启后
2.4 Hive并行模式
2.5 Hive严格模式
2.5.1 严格模式实现
2.5.2 严格模式下的限制
2.5.2.1 分区表查询限制
2.5.2.1.1 举证
2.5.2.1.2 查询对比
2.5.2.2 Order by 查询限制
2.5.2.2.1 查询对比
2.5.3 笛卡尔乘积查询限制
2.5.3.1 举证
2.5.3.2 查询对比
2.6 Hive排序
2.6.1 Order By
2.6.2 Sort By
2.6.3 Distribute By
2.6.4 Cluster By
2.7 Hive join
2.7.1 自动JOIN
2.7.1.1 自动JOIN设置
2.7.2 手动JOIN
2.7.2.1 手动JOIN语法
2.7.3 大表join大表
2.7.3.1 空key过滤
2.7.3.2 空key转换
2.8 Map-Side聚合
2.8.1 hive.map.aggr
2.8.2 聚合相关配置参数
2.8.2.1 hive.groupby.mapaggr.checkinterval
2.8.2.2 hive.map.aggr.hash.min.reduction
2.8.2.3 hive.map.aggr.hash.percentmemory
2.8.2.4 hive.groupby.skewindata
2.9 合并小文件
2.9.1 设置合并属性
2.9.1.1 hive.merge.mapfiles
2.9.1.2 hive.merge.mapredfiles
2.9.1.3 hive.merge.size.per.task
2.10 合理设置Map以及Reduce的数量
2.10.1 Map数量相关的参数
2.10.1.1 mapred.max.split.size
2.10.1.2 mapred.min.split.size.per.node
2.10.1.3 mapred.min.split.size.per.rack
2.10.2 Reduce数量相关的参数
2.10.2.1 mapred.reduce.tasks
2.10.2.2 hive.exec.reducers.bytes.per.reducer
2.10.2.3 hive.exec.reducers.max
2.11 JVM重用
2.11.1实现方式
2.11.2 适合场景
2.11.3 缺点
一、Hive优化总体思想
Hive的存储层依托于HDFS,Hive的计算层依托于MapReduce,一般Hive的执行效率主要取决于SQL语句的执行效率,因此,Hive的优化的核心思想是MapReduce的优化。
二、具体优化措施、策略
2.1 分析问题得手段
Hive的SQL语句在执行之前需要将SQL语句转换成MapReduce任务,因此需要了解具体的转换过程,可以在SQL语句中输入如下命令查看具体的执行计划。
语法为:
explain [extended] query例如:
explain extended select * from psn8;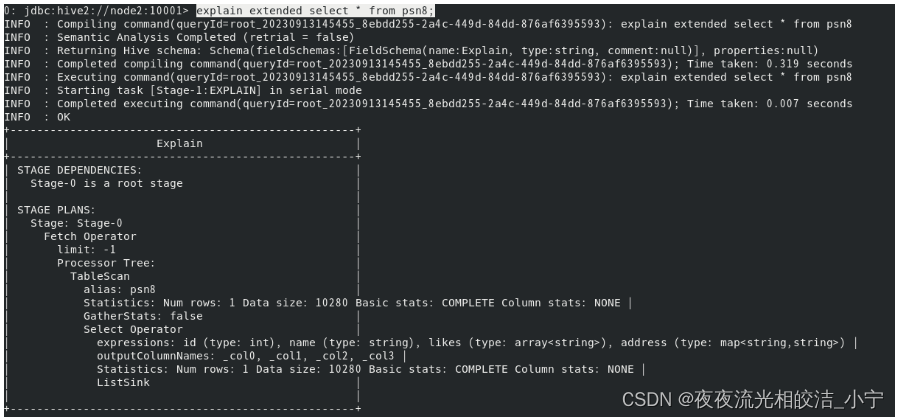
2.2 Hive的抓取策略
Hive的某些SQL语句需要转换成MapReduce的操作,某些SQL语句就不需要转换成MapReduce操作,但是需要注意,理论上来说,所有的SQL语句都需要转换成MapReduce操作,只不过Hive在转换SQL语句的过程中会做部分优化,使某些简单的操作不再需要转换成MapReduce。
2.2.1 策略设置
我们可以通过使用sql语句设置Hive的抓取策略:
set hive.fetch.task.conversion=none/more;或者可以在hive-site.xml配置文件中设置:
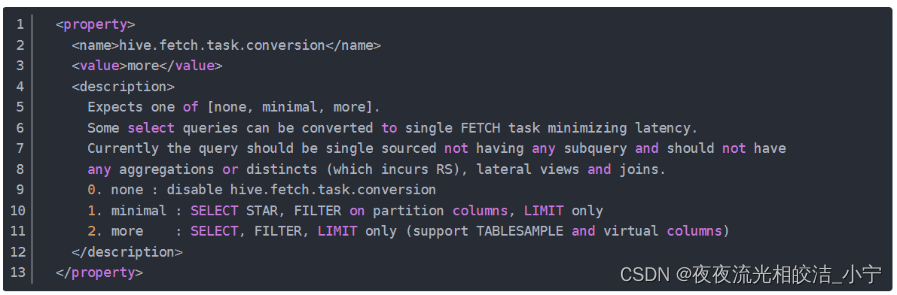
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
</property>该配置候选值有三个,分别为:
1)none:disable hive.fetch.task.conversion
2)minimal : SELECT STAR, FILTER on partition columns, LIMIT only
3)more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
2.2.2 策略对比效果
我们来看下对比效果:
开启抓取策略前:
关闭一下抓取策略:
set hive.fetch.task.conversion=none;执行查询语句:
select * from psn8;查看执行效果:
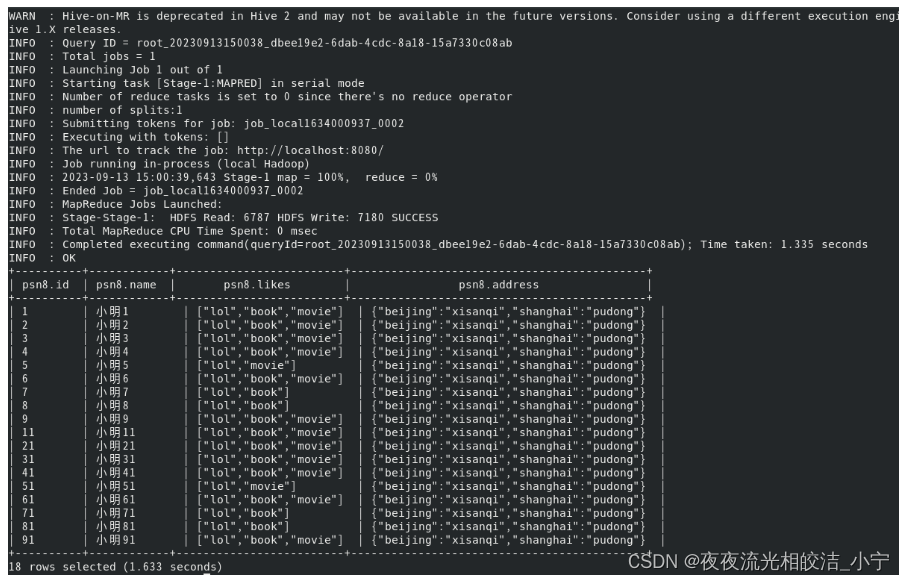
开启抓取策略后:
开启抓取策略:
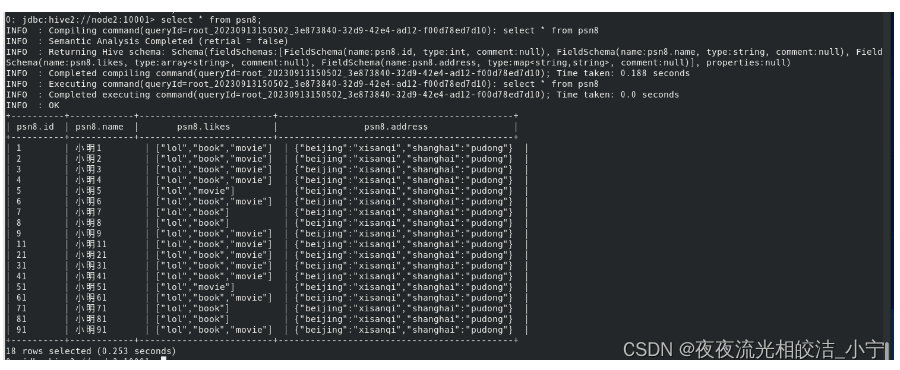
set hive.fetch.task.conversion=more;执行查询语句:
select * from psn8;执行效果:
2.3 Hive本地模式
类似于MapReduce的操作,Hive的运行也分为本地模式和集群模式,在开发阶段可以选择使用本地执行,提高SQL语句的执行效率,验证SQL语句是否正确。
假设你正在运行一些复杂的 Hive 查询,我们都知道这会在后台触发 MapReduce 作业并为你提供输出。如果 Hive 中的数据比较大,这种方法比较有效,但如果Hive 表中的数据比较少,这样会有一些问题。出现此问题的主要原因是 MapReduce 作业被触发,它是在服务器/集群上触发,因此每次运行查询时,它都会上传到服务器并在那里启动 MapReduce,然后输出。因此,为查询触发执行任务的时间消耗可能会比实际作业的执行时间要多的多。
2.3.1 设置开启Hive本地模式
需要满足如下三个配置条件,才能在本地模式下运行 Hive 查询:

| 参数 | 默认值 | 描述 |
| hive.exec.mode.local.auto | false | 让Hive确定是否自动启动本地模式运行 |
| hive.exec.mode.local.auto.inputbytes.max | 134217728(128MB) | 当第一个参数为true时,输入字节小于此值时才能启动本地模式 |
| hive.exec.mode.local.auto.input.files.max | 4 | 当一个参数为true时,任务个数小于此值时才能启动本地模式 |
2.3.2 对比效果
2.3.2.1 开启前
通过命令设置配置:
set hive.exec.mode.local.auto=false;
set hive.exec.mode.local.auto.inputbytes.max=134217728;
set hive.exec.mode.local.auto.input.files.max=5;执行统计命令:
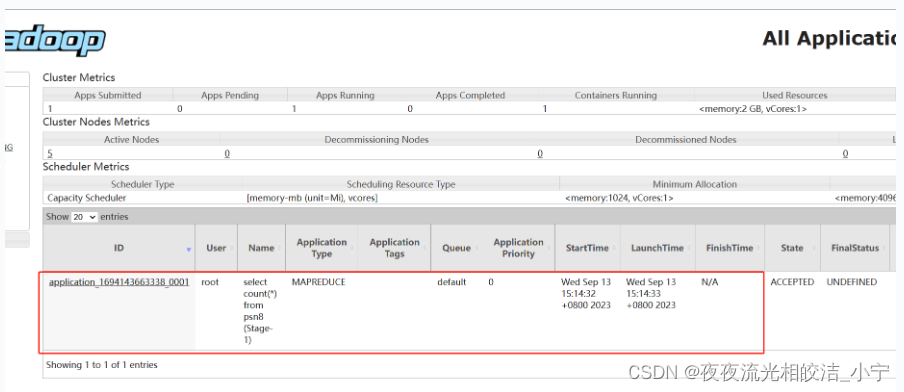
select count(*) from psn8;查看效果:
我们发现yarn上提交了一个计算任务:
任务执行时间:

我们发现,统计完成花费了54.211秒
2.3.2.2 开启后
通过命令设置配置:
set hive.exec.mode.local.auto=true;执行统计命令:
select count(*) from psn8;查看效果:
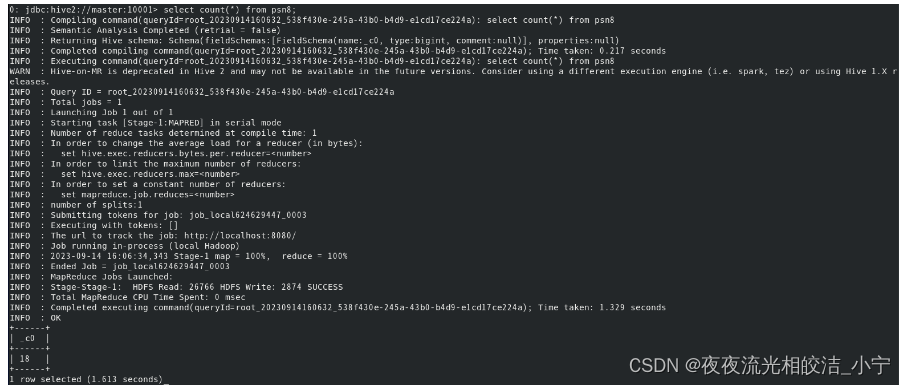
可以看到,设置成本地模式后,耗时1.513秒
2.4 Hive并行模式
在SQL语句足够复杂的情况下,可能在一个SQL语句中包含多个子查询语句,且多个子查询语句之间没有任何依赖关系,此时,可以Hive运行的并行度。
设置命令:
set hive.exec.parallel=true;注意:Hive的并行度并不是无限增加的,在一次SQL计算中,可以通过以下参数来设置并行的job的个数。
设置一次SQL计算允许并行执行的job个数的最大值
设置命令:
set hive.exec.parallel.thread.number2.5 Hive严格模式
Hive中为了提高SQL语句的执行效率,可以设置严格模式,充分利用Hive的某些特点。
2.5.1 严格模式实现
实现命令:
查看当前模式:
set hive.mapred.mode;严格模式:
set hive.mapred.mode=strict;非严格模式:
set hive.mapred.mode=nostrict;2.5.2 严格模式下的限制
2.5.2.1 分区表查询限制
如果在一个分区表执行hive,除非where语句中包含分区字段过滤条件来显示数据范围,否则不允许执行。换句话说, 就是用户不允许扫描所有的分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。
2.5.2.1.1 举证
例子:比如我这里有一张分区表,设置了分区字段age,具体如下:
创建表语句:
create external table psn11
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/ning';在hdfs创建目录并上传文件:
hdfs dfs -mkdir /ning
hdfs dfs -mkdir /ning/age=10
hdfs dfs -mkdir /ning/age=20
hdfs dfs -put /root/data/data /ning/age=10
hdfs dfs -put /root/data/data /ning/age=20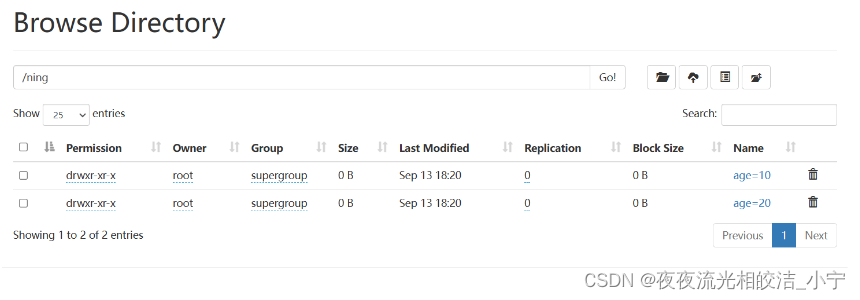
2.5.2.1.2 查询对比
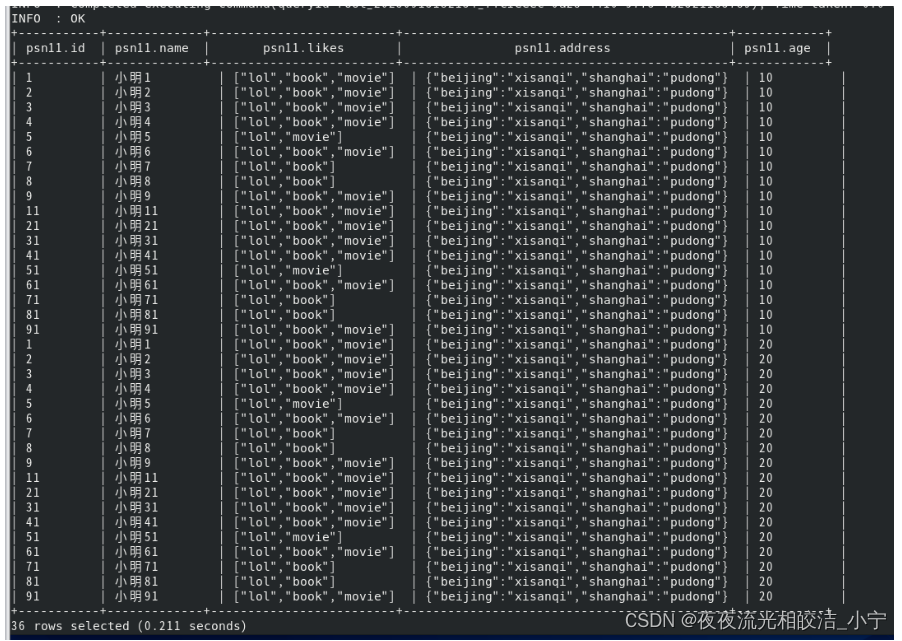
设置严格模式前:
执行命令:
select * from psn11;查询结果:
设置严格模式后:
执行命令:
select * from psn11;查询结果:

直接报错了,因为严格模式下,不允许扫描所有的分区。
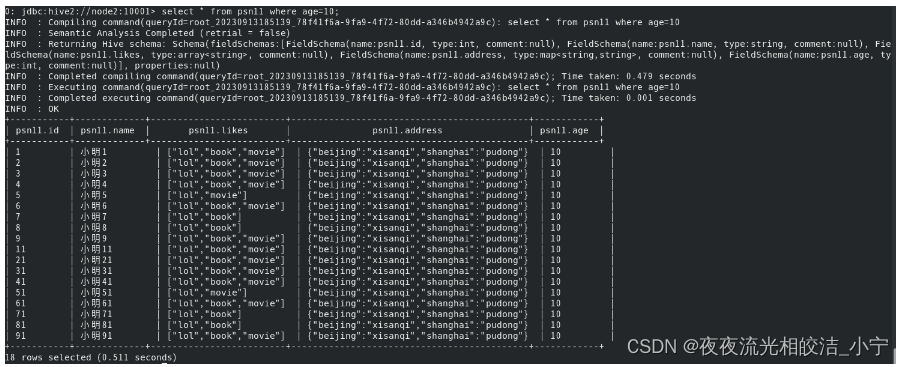
修改后命令:
select * from psn11where age=10;查询结果:
2.5.2.2 Order by 查询限制
对于使用了order by的查询,要求必须有limit语句。因为order by为了执行排序过程会将所有的结果分发到同一个reducer中进行处理,强烈要求用户增加这个limit语句可以防止reducer额外执行很长一段时间。
2.5.2.2.1 查询对比
我们还拿上一小节创建的psn11这张分区表做例子。
在开启严格模式前
执行命令:
select * from psn11 where age=10 order by id;查询效果:
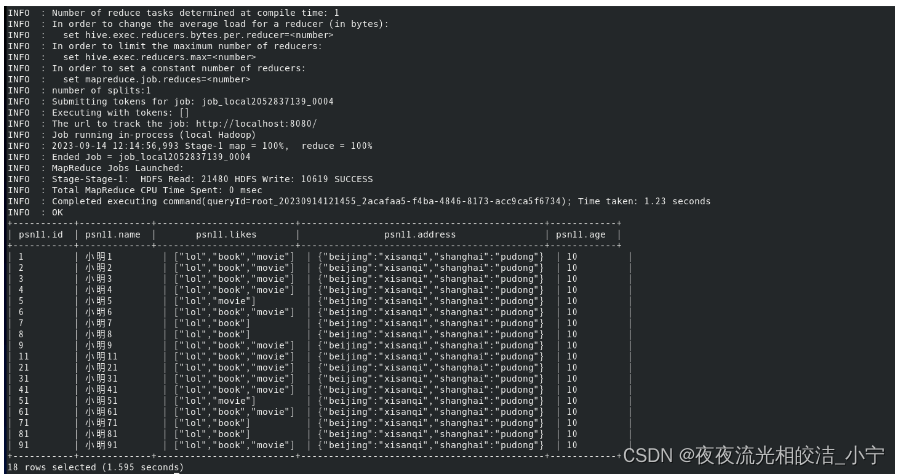
发现查询出了数据。
开启严格模式后:
执行命令:
select * from psn11 where age=10 order by id;查询效果:

开启严格模式后,同样的sql 语句,查询报错了,提示我们需要限制查询数据条数。
修改后指令:
select * from psn11 where age=10 order by id limit 10;查询效果:
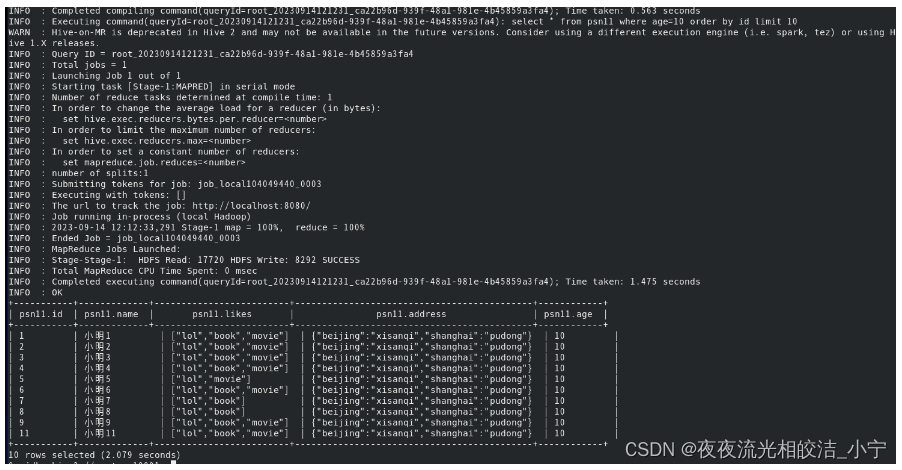
我们加上limit限制查询条数后,发现执行成功了。
2.5.3 笛卡尔乘积查询限制
对关系型数据库非常了解的用户可能期望在执行join查询的时候不使用on语句而是使用where语句,这样关系数据库的执行优化器就可以高效的将where语句转换成那个on语句。but,hive不会执行这种优化,所以如果表足够大,那么这个查询就会出现不可控的情况。
2.5.3.1 举证
我们创建两张表,一张人员表,一张人员课程表
建表语句:
create external table psn14
(
id int,
p_id int,
create_time string,
name string,
number int,
learn_time string,
)
row format delimited
fields terminated by ','
location '/data/couses';
create external table psn15
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/ning/data';创建目录:
hdfs dfs -mkdir /data/couses
hdfs dfs -mkdir /ning/data上传文件:
hdfs dfs -put /opt/hadoop/data/courses1.txt /data/couses
hdfs dfs -put /opt/hadoop/data/data1.txt /ning/data2.5.3.2 查询对比
执行笛卡尔乘积
未设置严格模式前:
执行命令:
select * from psn15 JOIN psn14 where1=1;查询结果:
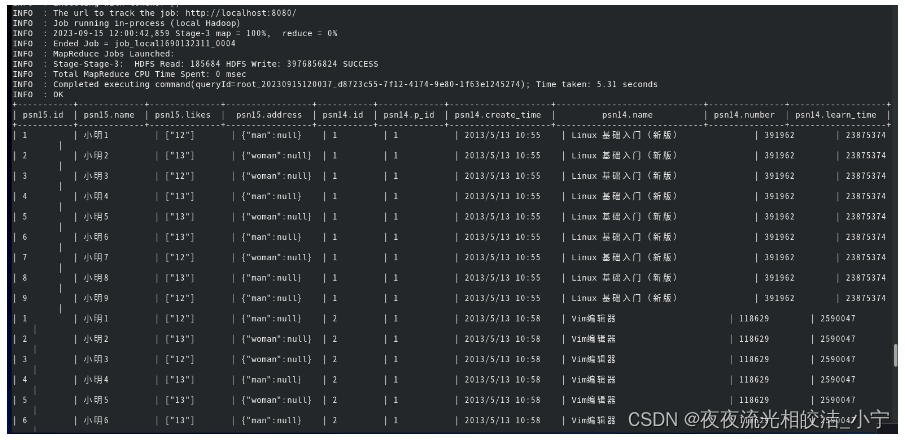
我们发现,查询成功,并且成功关联了数据。
设置严格模式后:
执行命令:
select * from psn15 JOIN psn14 where1=1;查询结果:

开启严格模式后,同样的查询语句,查询报错了。
改进查询语句:
select * from psn15 JOIN psn14 ON (psn15.id =psn14.p_id);查询结果:
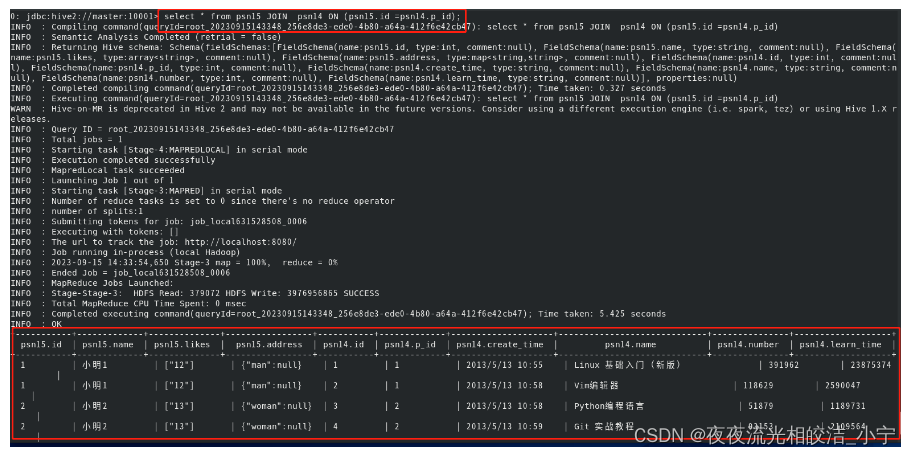
2.6 Hive排序
在编写SQL语句的过程中,很多情况下需要对数据进行排序操作,Hive中支持多种排序操作适合不同的应用场景。
2.6.1 Order By
Order By - 对于查询结果做全排序,只允许有一个reduce处理(当数据量较大时,应慎用。严格模式下,必须结合limit来使用)
我们来验证下:
执行如下语句:
select * from psn14 order by id limit 10;执行结果:
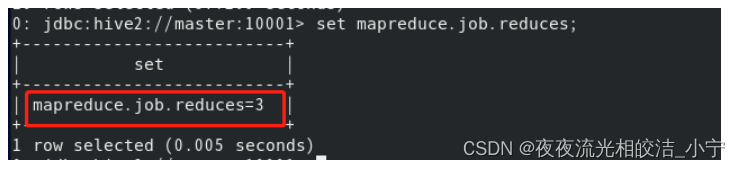
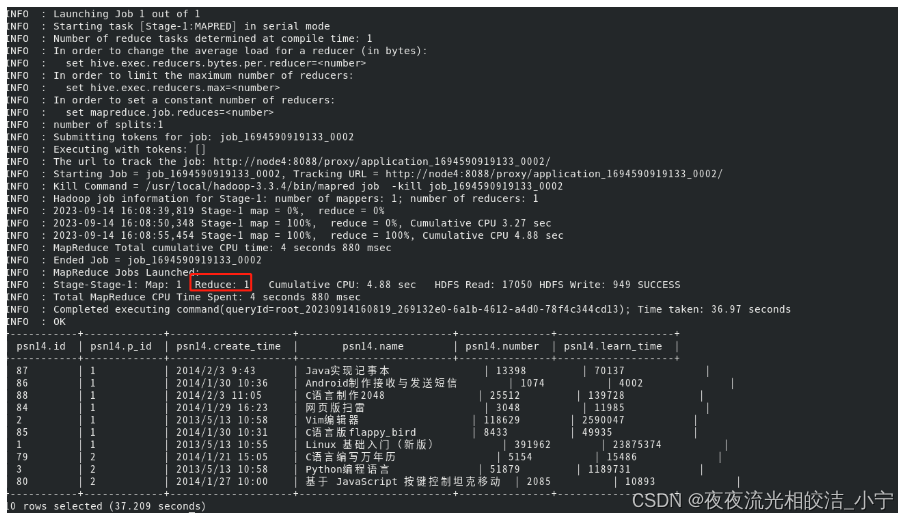
我们可以看到,实际上我们设置了三个reduce,但是order by只是使用了一个reduce计算。
2.6.2 Sort By
对于单个reduce的数据进行排序
我们执行如下语句:
select * from psn14 sort by id;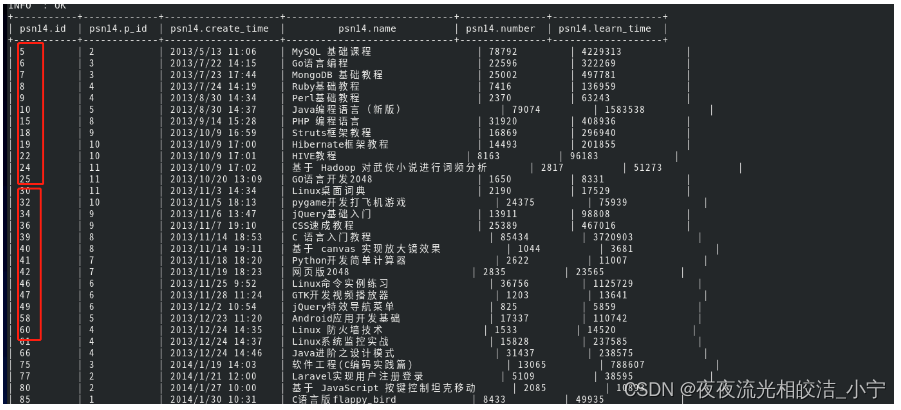
我们可以看到,返回的数据在reduce job中分别进行排序。
2.6.3 Distribute By
有些场景我们需要控制某些特定行应该到同一reducer,做一些聚集操作。
distribute by 类似 MR 中 partition(自定义分区),进行分区,经常结合 sort by 使用。
分区逻辑:根据distribute by 后的字段hash码与reduce 的个数进行模数后,决定分区路由。
我们执行如下语句:
select * from psn14 distribute by p_id sort by number;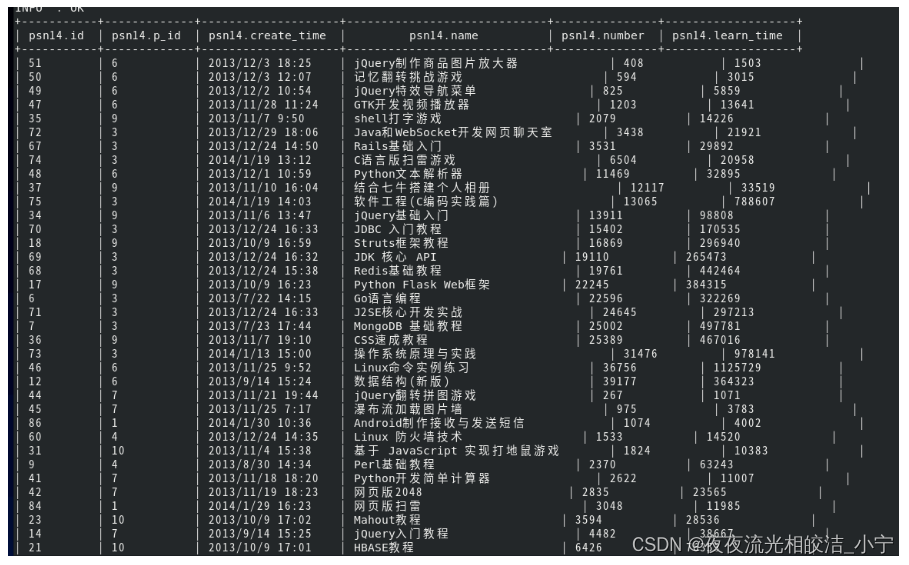
2.6.4 Cluster By
相当于 Sort By + Distribute By(Cluster By不能通过asc、desc的方式指定排序规则;可通过 distribute by column sort by column asc|desc 的方式)。
select * from psn14 cluster by number;执行效果:
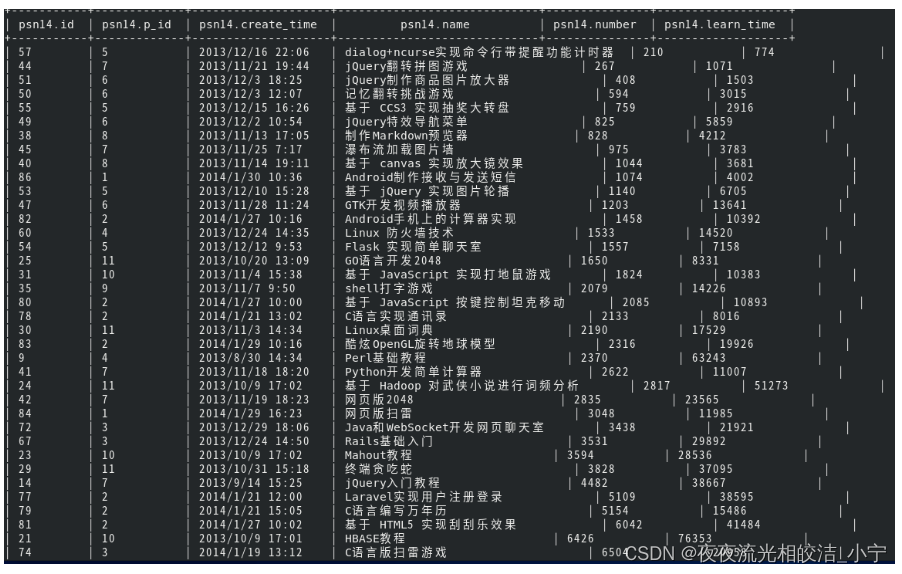
select * from psn14 distribute by number sort by number;执行效果:
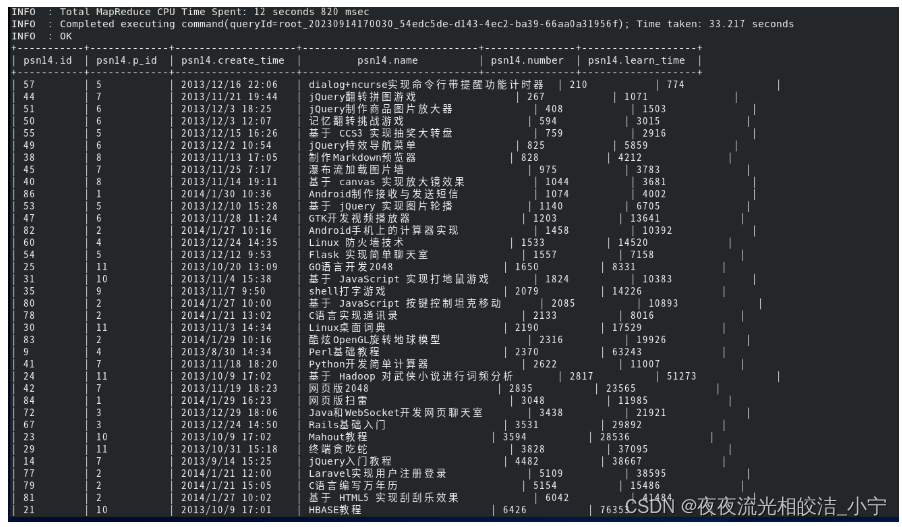
可以看出,两条语句查询的结果是一致的。cluster by 等价于distribute by 和 sort by 字段的升序排序。
2.7 Hive join
小表进行mapjoin,如果在join的表中,有一张表数据量较小,可以存于内存中,这样该表在和其他表join时可以直接在map端进行,省掉reduce过程,效率高。设置方式主要分两种:自动JOIN和手动JOIN。
2.7.1 自动JOIN
2.7.1.1 自动JOIN设置
设置开启自动JOIN:
set hive.auto.convert.join=true;提示:该参数为true时,Hive自动对左边的表统计量,如果是小表就加入内存,即对小表使用Map join。
设置Map JOIN的表的大小(默认为25M):
set hive.mapjoin.smalltable.filesize提示:该参数是大表小表判断的阈值,如果表的大小小于该值则会被加载到内存中运行。
设置是否忽略mapjoin标记:
set hive.ignore.mapjoin.hint=true;提示:默认值:true;是否忽略mapjoin hint 即mapjoin标记
例子:
select p15.*, p14.* from psn15 p15 JOIN psn14 p14 ON (p15.id =p14.p_id);
2.7.2 手动JOIN
手动Map join在map端完成join操作。
2.7.2.1 手动JOIN语法
SELECT /*+ MAPJOIN(smallTable) */ smallTable.key, bigTable.value
FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key;通过SQL方式,在SQL语句中添加MapJoin标记(mapjoin hint)。
例如:
select /*+ MAPJOIN(p15) */ p15.*,p14.* from psn15 p15 JOIN psn14 p14 ON (p15.id =p14.p_id);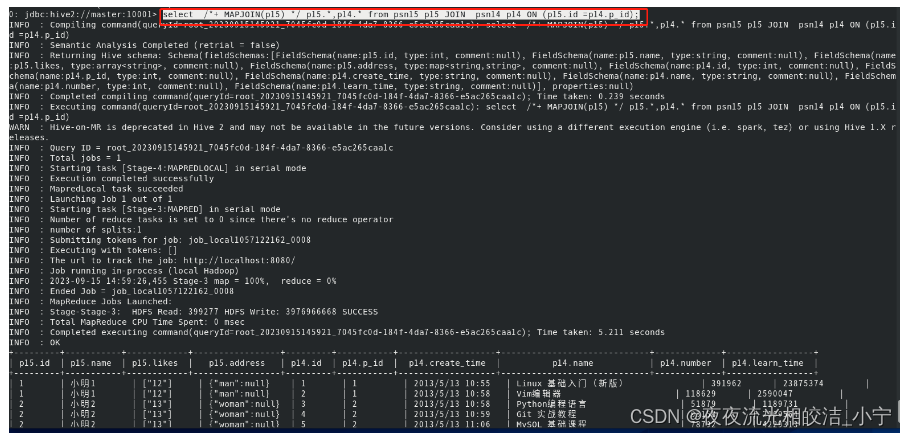
2.7.3 大表join大表
2.7.3.1 空key过滤
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。
2.7.3.2 空key转换
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。
2.8 Map-Side聚合
Hive的某些SQL操作可以实现map端的聚合,类似于MR的combine操作。
2.8.1 hive.map.aggr
通过设置以下参数开启在Map端的聚合:
set hive.map.aggr=true;2.8.2 聚合相关配置参数
2.8.2.1 hive.groupby.mapaggr.checkinterval
map端group by执行聚合时处理的多少行数据(默认:100000,可根据实际情况修改)
设置命令:
set hive.groupby.mapaggr.checkinterval=100000;2.8.2.2 hive.map.aggr.hash.min.reduction
进行聚合的最小比例(预先对100000条数据做聚合,若聚合之后的数据量/100000的值大于该配置0.5,则不会聚合)
设置命令:
set hive.map.aggr.hash.min.reduction=0.5;2.8.2.3 hive.map.aggr.hash.percentmemory
map端聚合使用的内存的最大值(默认值0.5,可根据实际情况修改)
设置命令:
set hive.map.aggr.hash.percentmemory=0.5;2.8.2.4 hive.groupby.skewindata
是否对GroupBy产生的数据倾斜做优化,默认为false
设置命令:
set hive.groupby.skewindata=false;2.9 合并小文件
Hive在操作的时候,如果文件数目小,容易在文件存储端造成压力,给hdfs造成压力,影响效率。
2.9.1 设置合并属性
2.9.1.1 hive.merge.mapfiles
是否合并map输出文件:
set hive.merge.mapfiles=true2.9.1.2 hive.merge.mapredfiles
是否合并reduce输出文件:
set hive.merge.mapredfiles=true;2.9.1.3 hive.merge.size.per.task
合并文件的大小:
set hive.merge.size.per.task=256*1000*10002.10 合理设置Map以及Reduce的数量
2.10.1 Map数量相关的参数
2.10.1.1 mapred.max.split.size
一个split的最大值,即每个map处理文件的最大值
设置命令:
set mapred.max.split.size2.10.1.2 mapred.min.split.size.per.node
一个节点上split的最小值
设置命令:
set mapred.min.split.size.per.node2.10.1.3 mapred.min.split.size.per.rack
一个机架上split的最小值
设置命令:
set mapred.min.split.size.per.rack2.10.2 Reduce数量相关的参数
2.10.2.1 mapred.reduce.tasks
强制指定reduce任务的数量
设置命令:
set mapred.reduce.tasks2.10.2.2 hive.exec.reducers.bytes.per.reducer
每个reduce任务处理的数据量
设置命令:
set hive.exec.reducers.bytes.per.reducer2.10.2.3 hive.exec.reducers.max
每个任务最大的reduce数
设置命令:
set hive.exec.reducers.max2.11 JVM重用
Hadoop的默认配置通常是使用派生JVM来执行map和Reduce任务的。这时JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成百上千task任务的情况。JVM重用可以使得JVM实例在同一个job中重新使用N次。
2.11.1实现方式
执行命令:
set mapred.job.reuse.jvm.num.tasks=n;(n为task插槽个数)2.11.2 适合场景
1)小文件个数过多
2)task个数过多
2.11.3 缺点
开启JVM重用将一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。如果某个“不平衡的”job中有某几个reduce task执行的时间要比其他Reduce task消耗的时间多的多的话,那么保留的插槽就会一直空闲着却无法被其他的job使用,直到所有的task都结束了才会释放。
好了,今天Hive调优的相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!