文章目录
- 一、语义分割介绍
- 1.1 语义分割和实例分割的区别
- 1.2 DeepLab系列对比
- 二、代码下载
- 2.1 代码测试
- 2.2 视频学习
- 三、数据集准备
- 3.1 Json转png
- 3.2 数据集划分
- 四、模型训练
- 五、模型测试
- 六、模型评估
一、语义分割介绍
语义分割是计算机视觉中的一项技术,旨在将图像中的每个像素分配给特定的类别。它与目标检测不同,目标检测是在图像中定位物体的位置和大小,而语义分割则进一步将这些物体划分为不同的类别。
语义分割的目标是生成一张与原始图像相同大小的分割掩膜,其中每个像素都被分配到正确的类别中。这对于许多应用非常重要,例如自动驾驶、医学影像分析和机器人导航等。
近年来,随着深度学习技术的发展,语义分割已经取得了很大的进展。现在有许多优秀的语义分割算法可供选择,包括FCN、U-Net、DeepLabv3+等。这些算法可以处理不同类型的图像数据,并且可以在实时应用中使用。
1.1 语义分割和实例分割的区别
通常我们说的图像分割是指的语义分割。简单来说分割出来的同一类用一种颜色叫做语义分割,同一类用不同颜色表示个体表示实例分割。如下图所示(左:语义;右:实例)。

1.2 DeepLab系列对比
DeepLab V1:
- 使用全卷积网络(Fully Convolutional Network)来进行语义分割。
- 引入了空洞卷积(Atrous Convolution)以扩大感受野,捕获更多上下文信息。
- 使用条件随机场(Conditional Random Field,CRF)来改善分割结果的平滑性。
- V1是DeepLab系列的第一个版本,提出了许多语义分割的基本思想。
DeepLab V2:
- 引入了空洞空间金字塔池化(ASPP)模块,用于捕获多尺度的特征信息。
- 使用了深度可分离卷积(Depthwise Separable Convolution)来减少模型的参数量。提高了分割性能和计算效率。
- V2构建在V1的基础上,引入了更多的创新来改进性能。
DeepLab V3:
- 进一步改进了ASPP模块,引入了多尺度ASPP,以处理不同尺寸目标物体。
- 使用编码器-解码器结构,以提高分割的准确性。
- 引入了多尺度输入策略,可以处理不同尺寸的输入图像。提高了性能和鲁棒性。
DeepLab V3+:
- 在DeepLab V3的基础上进一步改进,引入了改进的解码器结构。
- 引入了空洞空间金字塔池化(ASPP)模块,用于更好地处理多尺度特征信息。
- 允许多尺度输入,提高了模型的鲁棒性。
- 总体性能更优越,尤其在处理不同尺寸目标物体时表现更好。
综上所述,DeepLab V1是DeepLab系列的原始版本,后续的版本(V2、V3、V3+)引入了一系列创新来改进性能,包括更好的多尺度特征捕获、更高效的模型结构和更好的鲁棒性,使得这些模型在语义分割任务中取得了显著的进展。
二、代码下载
https://github.com/bubbliiiing/deeplabv3-plus-pytorch
2.1 代码测试
下载之后里面自带预训练模型
这时候我们直接运行predict.py即可(路径都是写好了的)
2.2 视频学习
https://www.bilibili.com/video/BV173411q7xF/?spm_id_from=333.999.0.0
三、数据集准备
我们通过labelImg对数据进行标注,标注的格式选择json,将标注的json文件写到和图片一个文件夹下。
json格式如下(shapes里面存储了单张图片所有的标注信息):
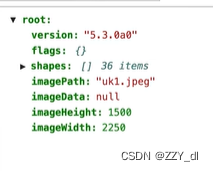
接下来我们将得到的所有json和jpg文件转换成mask的png文件,也就是图片语义分割的标签文件。
3.1 Json转png
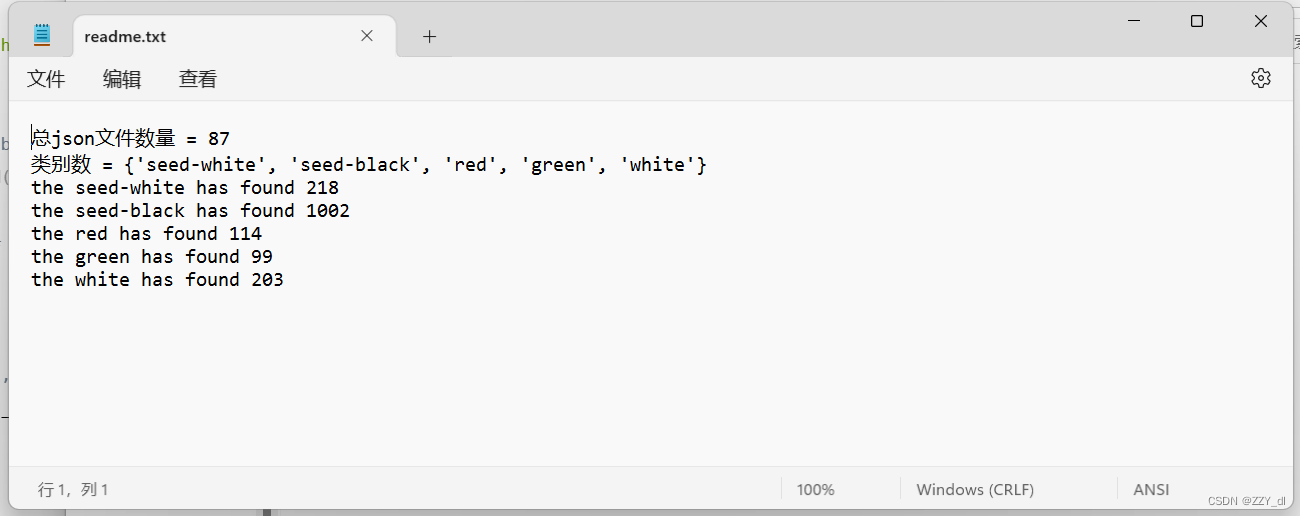
查看json标签的所有类别信息和类别数量
# -*- coding: utf-8 -*-
# 将 json格式的 class进行统一标签
# 可以直接批量读取json文件,并修改内容
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import json
import os
import scipy.misc
import sys
path = "D:\Python\company\Semantic_segmentation\datasets\la" \
"bel_json_files\Watermelon_Semantic_Seg_Labelme\labelme_jsons_images"
parent_path = os.path.dirname(path)
files = os.listdir(path)
label_list = []
total_num=0
for json_file in files:
if json_file.endswith('.json'):
total_num += 1
json_path= os.path.join(path, json_file)
print(json_path)
json_ann = json.load(open(json_path))
objects = json_ann['shapes']
for item in objects:
# 打印 label
# print (item['label'])
label_list.append(item['label'])
print(label_list)
category = set(label_list) # myset是另外一个列表,里面的内容是mylist里面的无重复 项
# readme_path =
# with open(path+'readme.txt','w') as f:
with open(os.path.join(parent_path, 'readme.txt'), 'w') as f:
'''
保存信息
'''
f.write('总json文件数量 = %d'% total_num)
f.write('\n类别数 = %s' % category)
for label in category:
print("the %s has found %d" % (label, label_list.count(label)))
f.write("\nthe %s has found %d" % (label, label_list.count(label)))
将json转换png代码:
import base64
import json
import os
import os.path as osp
import numpy as np
import PIL.Image
from labelme import utils
'''
制作自己的语义分割数据集需要注意以下几点:
1、我使用的labelme版本是3.16.7,建议使用该版本的labelme,有些版本的labelme会发生错误,
具体错误为:Too many dimensions: 3 > 2
安装方式为命令行pip install labelme==3.16.7
2、此处生成的标签图是8位彩色图,与视频中看起来的数据集格式不太一样。
虽然看起来是彩图,但事实上只有8位,此时每个像素点的值就是这个像素点所属的种类。
所以其实和视频中VOC数据集的格式一样。因此这样制作出来的数据集是可以正常使用的。也是正常的。
'''
if __name__ == '__main__':
#######################################修改几个变量##########################################################
jpgs_path = "D:\Python\company\Semantic_segmentation\datasets\Watermelon_Semantic_Seg_Labelme/JPEGImages"
pngs_path = "D:\Python\company\Semantic_segmentation\datasets\Watermelon_Semantic_Seg_Labelme/SegmentationClass"
# classes = ["_background_","aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
json_images_files = "D:\Python\company\Semantic_segmentation\datasets\Watermelon_Semantic_Seg_Labelme\label_json_files\labelme_jsons_images"
classes = ["_background_", 'seed-white', 'seed-black', 'red', 'green', 'white']
count = os.listdir(json_images_files)
###########################################################################################################
for i in range(0, len(count)):
path = os.path.join(json_images_files, count[i])
if os.path.isfile(path) and path.endswith('json'):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
PIL.Image.fromarray(img).save(osp.join(jpgs_path, count[i].split(".")[0] + '.jpg'))
new = np.zeros([np.shape(img)[0], np.shape(img)[1]])
for name in label_names:
index_json = label_names.index(name)
index_all = classes.index(name)
new = new + index_all * (np.array(lbl) == index_json)
utils.lblsave(osp.join(pngs_path, count[i].split(".")[0] + '.png'), new)
print('Saved ' + count[i].split(".")[0] + '.jpg and ' + count[i].split(".")[0] + '.png')
3.2 数据集划分
得到原图文件夹和png的掩码图像文件夹之后,即可开始数据集的划分,划分代码如下。
import os
import random
import numpy as np
from PIL import Image
from tqdm import tqdm
#-------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# 修改train_percent用于改变验证集的比例 9:1
#
# 当前该库将测试集当作验证集使用,不单独划分测试集
#-------------------------------------------------------#
trainval_percent = 1 # 1 代表不生成test.txt 如果是0.9 那么就划分0.1给test.txt
train_percent = 0.9 # 在train.txt的基础上,train.txt:train_percent = 9:1 1份为验证级
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
VOCdevkit_path = 'D:\Python\company\Semantic_segmentation\datasets\Watermelon_Semantic_Seg_Labelme'
if __name__ == "__main__":
random.seed(0)
print("Generate txt in ImageSets.")
segfilepath = os.path.join(VOCdevkit_path, 'SegmentationClass')
saveBasePath = os.path.join(VOCdevkit_path, 'ImageSets/Segmentation')
temp_seg = os.listdir(segfilepath)
total_seg = []
for seg in temp_seg:
if seg.endswith(".png"):
total_seg.append(seg)
num = len(total_seg)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval= random.sample(list,tv)
train = random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
if not os.path.exists(saveBasePath):
os.makedirs(saveBasePath)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name = total_seg[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("Generate txt in ImageSets done.")
print("Check datasets format, this may take a while.")
print("检查数据集格式是否符合要求,这可能需要一段时间。")
classes_nums = np.zeros([256], np.int)
for i in tqdm(list):
name = total_seg[i]
png_file_name = os.path.join(segfilepath, name)
if not os.path.exists(png_file_name):
raise ValueError("未检测到标签图片%s,请查看具体路径下文件是否存在以及后缀是否为png。"%(png_file_name))
png = np.array(Image.open(png_file_name), np.uint8)
if len(np.shape(png)) > 2:
print("标签图片%s的shape为%s,不属于灰度图或者八位彩图,请仔细检查数据集格式。"%(name, str(np.shape(png))))
print("标签图片需要为灰度图或者八位彩图,标签的每个像素点的值就是这个像素点所属的种类。"%(name, str(np.shape(png))))
classes_nums += np.bincount(np.reshape(png, [-1]), minlength=256)
print("打印像素点的值与数量。")
print('-' * 37)
print("| %15s | %15s |"%("Key", "Value"))
print('-' * 37)
for i in range(256):
if classes_nums[i] > 0:
print("| %15s | %15s |"%(str(i), str(classes_nums[i])))
print('-' * 37)
if classes_nums[255] > 0 and classes_nums[0] > 0 and np.sum(classes_nums[1:255]) == 0:
print("检测到标签中像素点的值仅包含0与255,数据格式有误。")
print("二分类问题需要将标签修改为背景的像素点值为0,目标的像素点值为1。")
elif classes_nums[0] > 0 and np.sum(classes_nums[1:]) == 0:
print("检测到标签中仅仅包含背景像素点,数据格式有误,请仔细检查数据集格式。")
print("JPEGImages中的图片应当为.jpg文件、SegmentationClass中的图片应当为.png文件。")
print("如果格式有误,参考:")
print("https://github.com/bubbliiiing/segmentation-format-fix")
四、模型训练
修改预训练模型文件和num_classes,选择合适的batchsize、epochs和numwork,是否使用cuda。修改之后即可运行python train.py。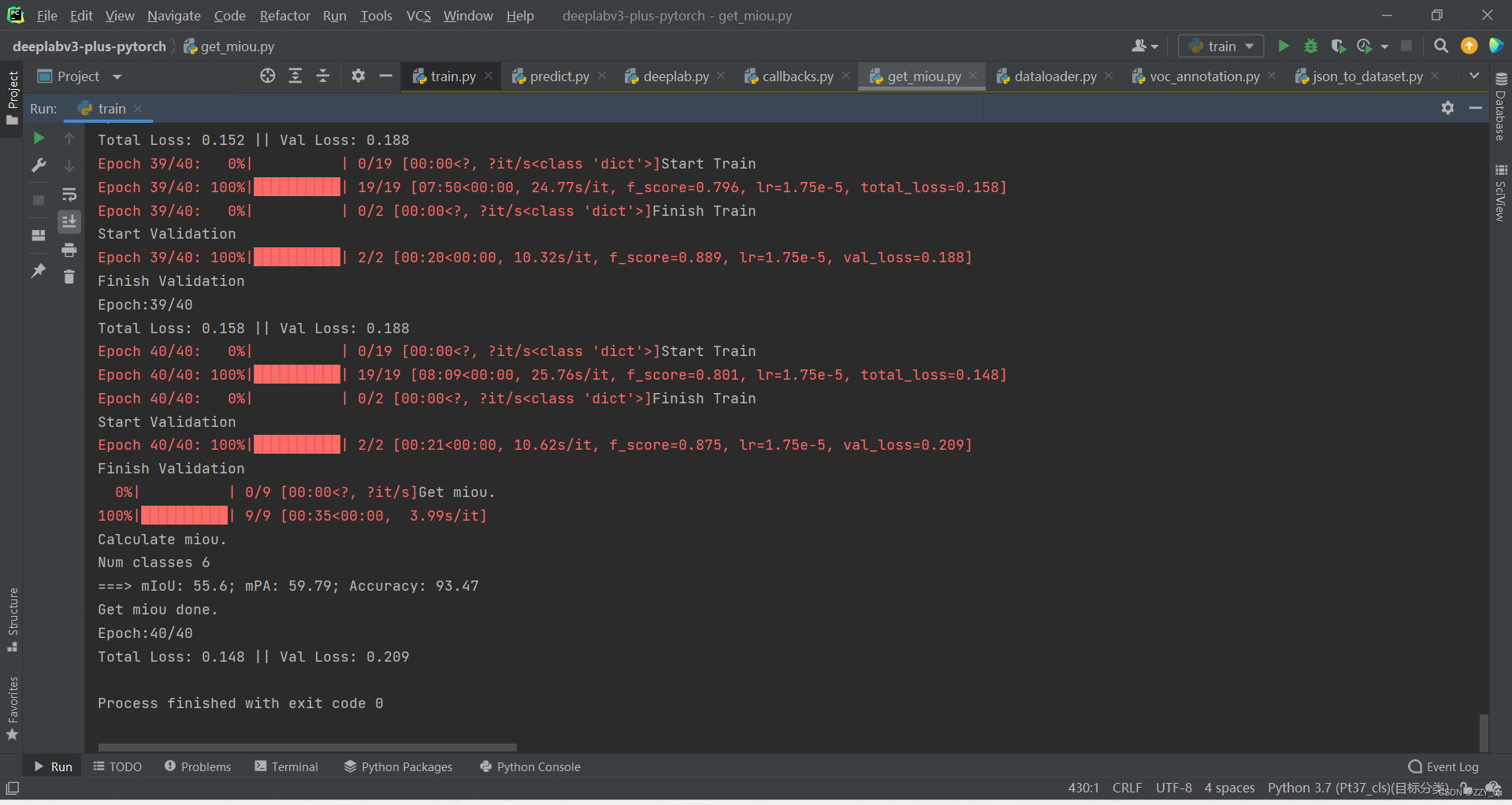
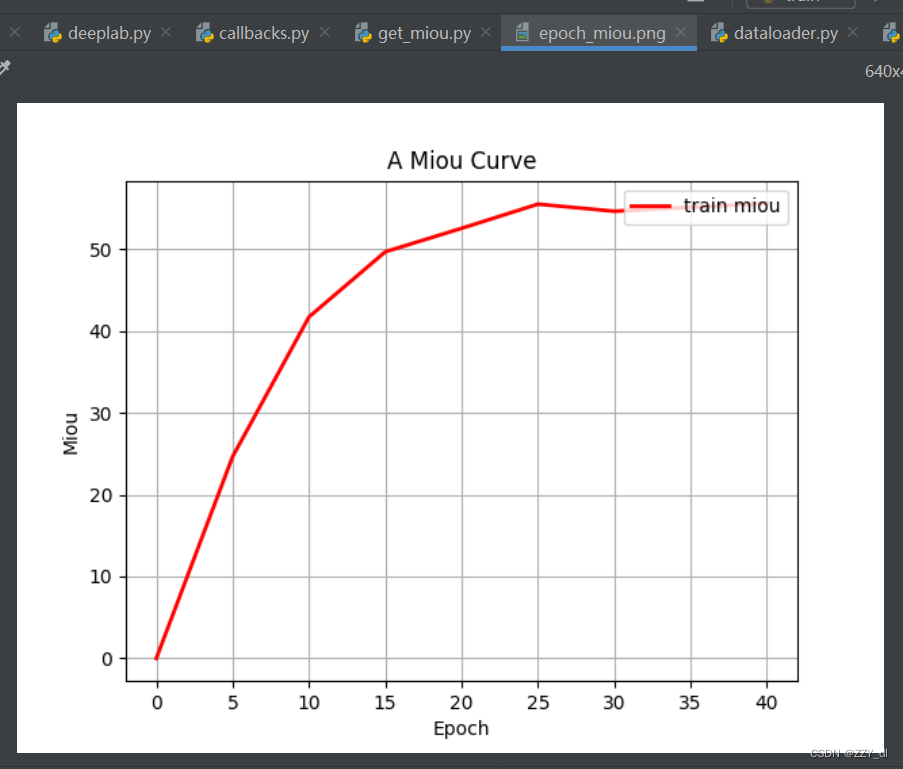
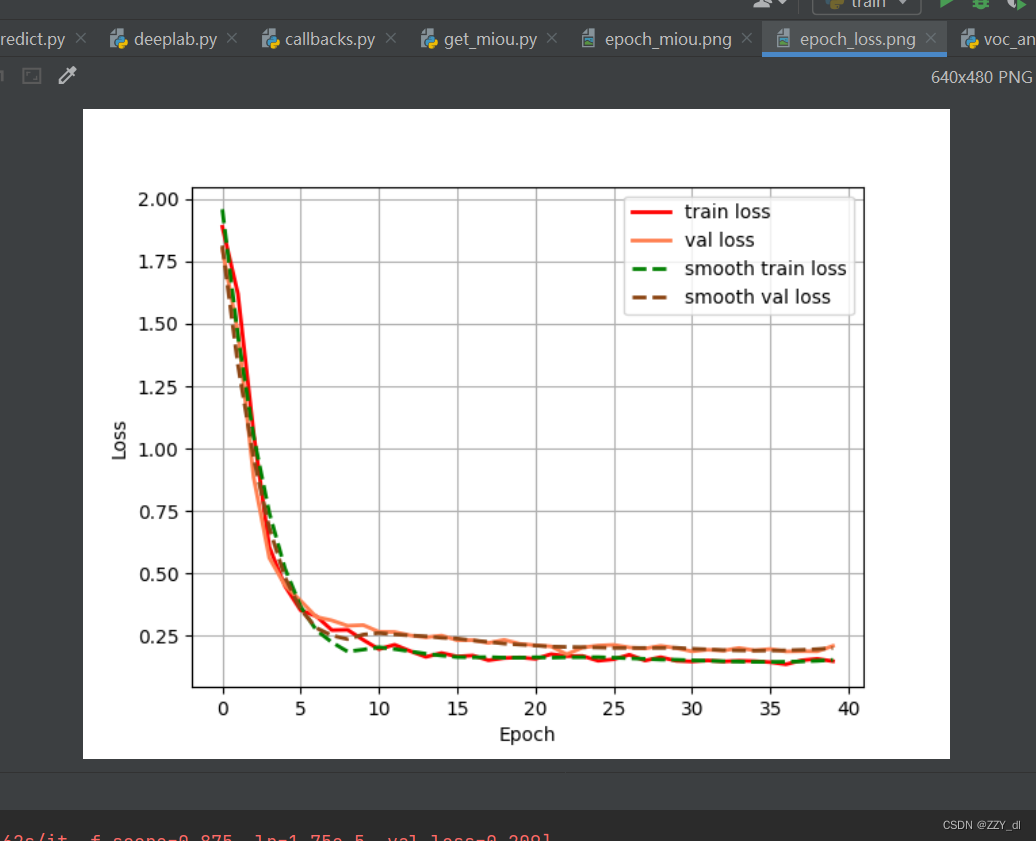
训练的日志和模型文件和相关训练图片写入到log文件夹下。
五、模型测试
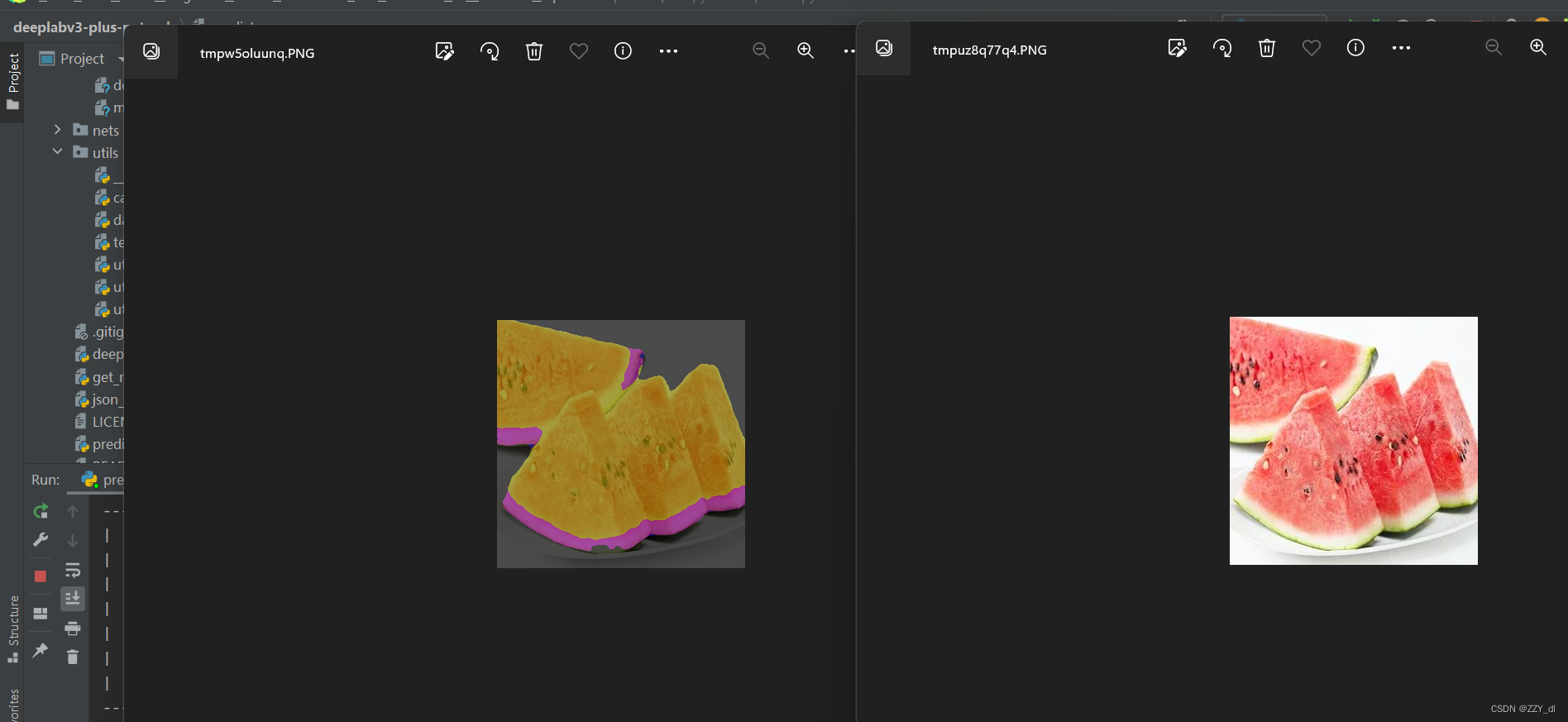
修改predict.py的name_classes;修改deeplab.py的num_classes和model_path为自己的。
然后执行predict.py即可选择我们图片完成分割操作。
六、模型评估
评估指标mIoU、mPA、Accuracy。
- mIoU(mean Intersection over Union):是一种常用于图像分割任务的评价指标,用于量化预测结果与真实结果之间的相似度。
- mPA(mean pixel accuracy):是平均像素准确率,用于衡量模型在像素级别的分类准确性。
- Accuracy:是准确率,用于衡量模型整体的分类准确性。
修改get_miou.py的name_classes、num_classes、VOCdevkit_path;修改deeplab.py的num_classes和model_path为自己的;修改部分数据集的路径位置(因为我这里没有使用2007的文件夹,所以很多地方都做了小的修改)。
然后运行get_miou.py,即可在主目录上生成miou_out的结果文件夹。