视觉Transfomer的基本原理
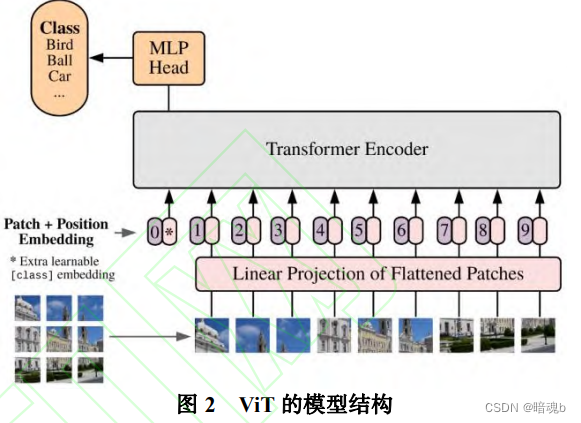
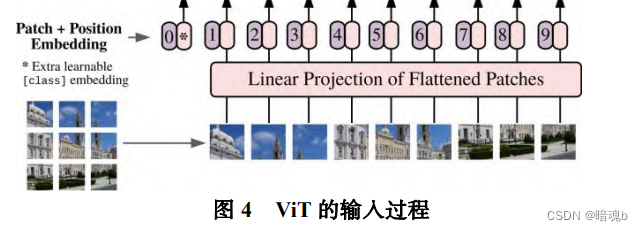
在图像处理过程中,ViT首先将输入的图片分成块,对其进行线性的编码映射后排列成一堆的向量作为编码器的输入,在分类任务中会在这个一维向量加入了一个可学习的嵌入向量用作分类的类别预测结果表示,最后通过一个全连接层输出结果
注意力机制
注意力机制让网络更聚焦于输入中相关信息的方法,从而减少对无关信息的关注程度
计算步骤:
- 将输入X通过函数f(x)将其分成若干个[a1,a2…at ]节点,这些节点分别通过三个权重矩阵Wq、Wk和Wv,得到对应的qt^ 、kt 和 vt
qi = aiWq ki=aiWk vi=aiWv
其中qi 代表查询向量,后续会去和每一个ki进行匹配
ki代表被查询向量,后续会被每个qi匹配,vi代表从ai中提取得到的信息向量 - 计算qi和ki之间的相似性来获得权重
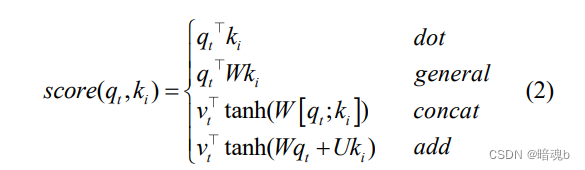
- 对相似度权重进行归一化处理。常使用softmax函数将相似度矩阵归一化为注意力权重矩阵。
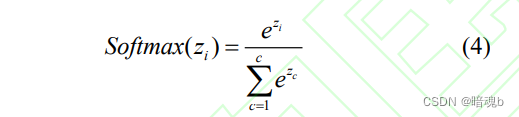
通过softMax函数就可以将多分类的输出值转换为范围在[0,1]和为1的概率分布 - 根据权重对信息向量进行求和得到注意力:
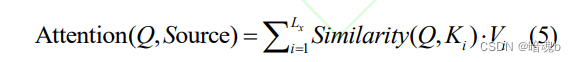
其中,Lx表示输入序列的长度,Similarity表示相似度计算,Q、K和V分别表示查询向量、被查询向量和信息向量
图像序列化和位置编码
Transfomer的输入是一个序列,要能够对图像进行处理则要使得二维的图像变成一个一维的序列。
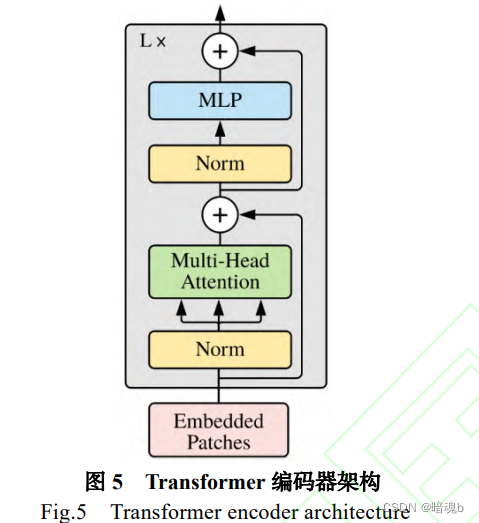
Transformer模块
Transfomer模块上是基于编码器和解码器架构,而编码器和解码器是由多个层构成。编码器负责提取特征,解码器负责将提取到的特征转化为结果。编码器由注意力层和全连接层构成。
视觉Transformer的优势和缺点
优点
- 多模态融合能力强
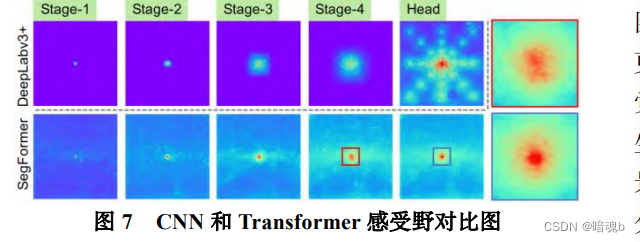
- 更宽广的感受野
缺点
- VIT有着庞大的计算量、参数量和算法复杂度。
- 数据需求量大

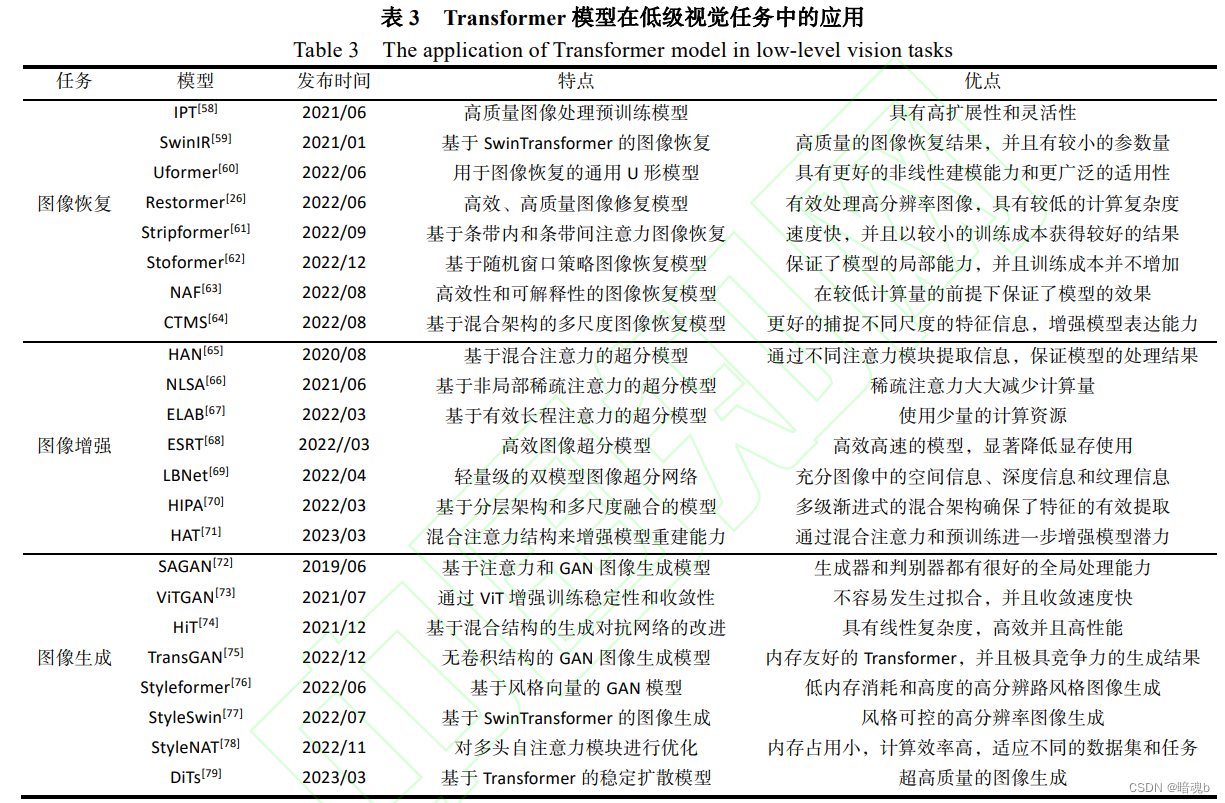
Transformer在低级视觉任务中的应用
低级视觉任务常用数据集