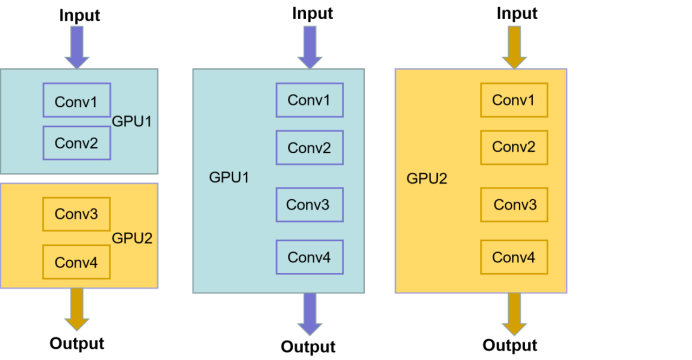
1.为什么要使用多GPU并行训练
简单来说,有两种原因:第一种是模型在一块GPU上放不下,两块或多块GPU上就能运行完整的模型(如早期的AlexNet)。第二种是多块GPU并行计算可以达到加速训练的效果。想要成为“炼丹大师“,多GPU并行训练是不可或缺的技能。
2. 常见的多GPU训练方法
2.1模型并行方式
如果模型特别大,GPU显存不够,无法将一个显存放在GPU上,需要把网络的不同模块放在不同GPU上,这样可以训练比较大的网络。(下图左半部分)
2.2 数据并行方式
将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播。相当于加大了batch_size。(下图右半部分)
在pytorch1.7 + cuda10 + TeslaV100的环境下,使用ResNet34,batch_size=16, SGD对花草数据集训练的情况如下:使用一块GPU需要9s一个epoch,使用两块GPU是5.5s, 8块是2s。这里有一个问题,为什么运行时间不是9/8≈1.1