目录
- 一、哈希概念
- 二、 哈希冲突
- 三、 哈希函数
- 四、 减少哈希冲突常用的方法
- 4.1 闭散列
- 4.1.1 闭散列的开放定址法的增容
- 4.1.2 闭散列的开放定址法的哈希结构的实现
- 4.3 开散列
- 4.3.1 开散列概念
- 4.3.2 插入元素
- 4.3.2 删除元素
- 4.3.3 开散列的哈希桶的增容
- 4.3.4 开散列的哈希桶(拉链法)代码实现
- 4.3.5 关于开散列的思考
- 4.3.6 开散列与闭散列比较
一、哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(
l
o
g
2
N
log_2 N
log2N),而搜索的效率取决于搜索过程中元素的比较次数。
所以理想的搜索方法是:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素 :根据待插入元素的关键码,按照此函数计算出该元素的存储位置并按此位置进行存放
搜索元素 :对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
以上方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
例如插入:11,3,4,25

用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快。
那上述的哈希表中再插入一个1呢?通过计算hash(1)%10=1,也就是说1应该插入到下标为1的位置中,但是hash[1]已经插入了11了。
二、 哈希冲突
对于两个数据元素的关键字
k
i
k_i
ki和
k
j
k_j
kj(i != j),有
k
i
k_i
ki !=
k
j
k_j
kj,但有:Hash(
k
i
k_i
ki) ==Hash(
k
j
k_j
kj),即:不同关键字通过相同哈希算法计算出相同的哈希地址,该种现象称为哈希冲突
或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。那么发生哈希冲突该如何处理呢?
三、 哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
1、哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间。
2、哈希函数计算出来的地址能均匀分布在整个空间中。
3、哈希函数应该比较简单。
常见哈希函数:
-
直接定址法–(常用)
取关键字的某个线性函数为散列地址:
Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况 -
除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址 -
平方取中法–(了解)
假设关键字为2345,对它平方就是5499025,抽取中间的3位990作为哈希地址;
再比如关键字为5432,对它平方就是29506624,抽取中间的3位506作为哈希地址
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况 -
折叠法–(了解一下即可)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况 -
随机数法–(了解一下即可)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。
通常应用于关键字长度不等时采用此法 -
数学分析法–(了解一下)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。例如:
假设要存储班级学生的登记表,如果用手机号作为关键字,那么极有可能前7位都是相同的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现冲突,还可以对抽取出来的数字进行反转(如5678改成8765)、右环位移(如5678改成8567)、左环移位、前两数与后两数叠加(如5678改成56+78=134)等方法。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况
值得注意的是:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
我们在以下的内容中是使用除留余数法实现哈希表的。
四、 减少哈希冲突常用的方法
闭散列和开散列。
4.1 闭散列
闭散列,也称开放定址法。当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置
呢?
1、线性探测
插入元素:
如果计算出来的位置已经有元素,那么就通过线性探测往后找到一个空位置插入即可。
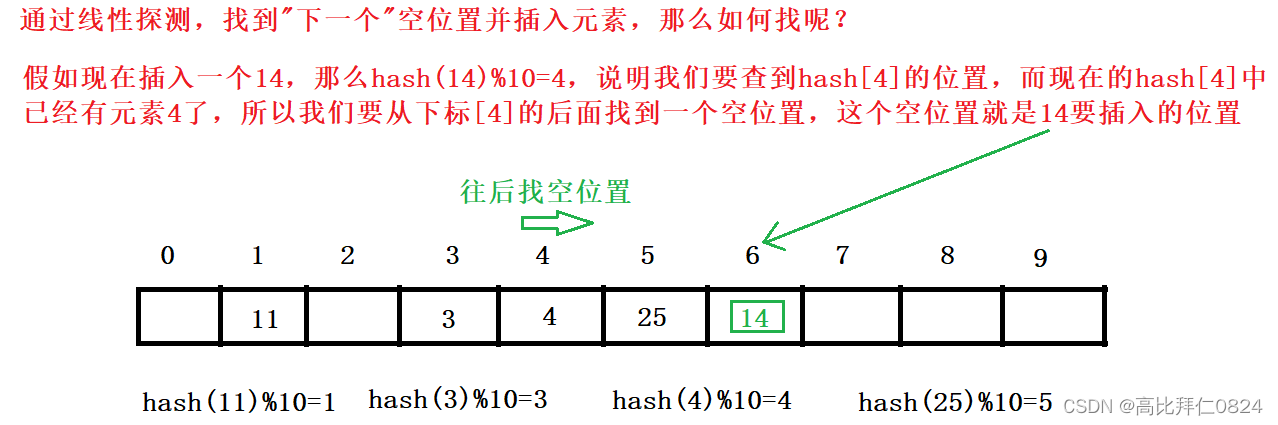

删除元素:
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
所以对于闭散列的哈希表的存放的数据中应该包含一个标志状态的变量,新插入的节点的状态标志位是EXIST,被删除的节点的标志位设置为DELETE,没插入的节点的标志位默认设置为EMPTY。
线性探测优点:实现非常简单。
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。那么这种情况该如何缓解呢?
2、二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:
H
i
H_i
Hi = (
H
0
H_0
H0 +
i
2
i^2
i2 )% m, 或者:
H
i
H_i
Hi = (
H
0
H_0
H0 -
i
2
i^2
i2 )% m。其中:i =1,2,3…,
H
0
H_0
H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。简单来说就是在往后找空位置的时候不是直接找下一个位置,而是找下一个位置平方对应的位置。这样就能更好地缓解冲突的数据全部堆积在一块的问题了。
研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
因此:闭散列最大的缺陷就是空间利用率比较低,基本上浪费了50%的空间,同时这也是哈希的缺陷。
4.1.1 闭散列的开放定址法的增容
哈希表会在什么情况下扩容?如何扩容?

//负载因子(有效数据在哈希表中的占比)超过70%就进行扩容
if (_n * 10 / _table.size() >= 7)
{
//扩容
size_t newSize = _table.size() * 2;
//这里直接定义一个新的哈希表对象,好处是能够直接复用这个Insert函数,
//最后进行指针的交换,为什么这里适合复用Insert函数,因为闭散列的开
//放定址法的核心就是线性探测,如果这里不复用Insert自己写的话,跟下面
//线性探测的逻辑是一模一样的,所以没必要重新写
HashTable<K, V, HashFunc> newHT;
newHT._table.resize(newSize);
for (size_t i = 0; i < _table.size(); i++)
{
//把旧表中的存在的数据插入到新的哈希表
if (_table[i]._state == EXIST)
{
newHT.Insert(_table[i]._kv);
}
}
//两个vector交换,本质是交换vector的_start,_finish,_endofstorage指针,刚好还把
//旧哈希表中_start,_finish,_endofstorage指针交换给newTable,newTable是局部对象,
//出了作用域自动销毁,刚好满足我们的需求
_table.swap(newHT._table);
}
4.1.2 闭散列的开放定址法的哈希结构的实现
#include <iostream>
using namespace std;
#include <vector>
//仿函数
template <class K>
struct DefaultHashFunc
{
size_t operator()(const K& key)
{
//这里强转可以解决负数的映射问题
return (size_t)key;
}
};
//针对string类型的特化的仿函数,所有字符的ASCII值结合起来
template<>
struct DefaultHashFunc<string>
{
size_t operator()(const string& s)
{
size_t ret = 0;
for (const auto& ch : s)
{
//这个131是别人经过研究计算出来的一个值
//*=131目的是想尽可能地减少哈希冲突(哈希碰撞)
ret *= 131;
ret += ch;
}
return ret;
}
};
//闭散列的开放定址法
namespace open_address
{
enum State
{
//有效值
EXIST,
//无效值
DELETE,
//空
EMPTY
};
//闭散列存放的数据是一个pair和这个位置的pair的状态,因为删除的时候不能把这个值去掉,所以
//任何操作都是改变这个数据的状态而已
template <class K,class V>
struct HashData
{
pair<K, V> _kv;
State _state = EMPTY;//节点的默认状态应该是EMPTY的,当插入或者删除值的时候再修改
};
template <class K,class V,class HashFunc= DefaultHashFunc<K>>
class HashTable
{
public:
//构造函数
HashTable()
{
//提前开辟10个空间
_table.resize(10);
}
//防止外面通过指针修改key值,所以HashData<const K, V>*加上const
HashData<const K, V>* Find(const K& key)
{
HashFunc hf;
//先到key映射的下标中找,如果找到了就直接返回,如果没找到就往后找
//找到最后没找到就绕回来前面找,直到找到EMPTY还没有找到就说明这个
//节点不存在了
//这里的key不一定是整形,而只有整形的数才能取模,所以我们要通过仿函数
//把这个数据的key值变成整形然后取出来,这样才能支持取模
size_t hashi = hf(key) % _table.size();
//遇到删除状态为DELETE的也要继续找,因为DELETE的节点的后面(或者前面)还有值
while (_table[hashi]._state != EMPTY)
{
//找到了就返回地址
if (_table[hashi]._state == EXIST && _table[hashi]._kv.first == key)
{
//这里需要强转一下,因为&_table[hashi]的类型是HashData<K,V>*
return (HashData<const K, V>*)&_table[hashi];
}
hashi++;
//取模一下可以从最后一个位置绕回来到第一个位置
hashi %= _table.size();
}
//走到这里说明找不到这个key了,返回空
return nullptr;
}
bool Erase(const K& key)
{
HashData<const K, V>* ret = Find(key);
if (ret)
{
//删除操作就是把该节点的状态改成DELETE即可,无需修改它的值,因为你也不知道该改成什么值
ret->_state = DELETE;
_n--;
return true;
}
else
{
return false;
}
}
bool Insert(const pair<K, V>& kv)
{
HashFunc hf;
//如果插入的节点存在,那么就不用插入了
if (Find(kv.first) != nullptr)
{
return false;
}
//负载因子(有效数据在哈希表中的占比)超过70%就进行扩容
if (_n * 10 / _table.size() >= 7)
{
//扩容
size_t newSize = _table.size() * 2;
//这里直接定义一个新的哈希表对象,好处是能够直接复用这个Insert函数,
//最后进行指针的交换,为什么这里适合复用Insert函数,因为闭散列的开
//放定址法的核心就是线性探测,如果这里不复用Insert自己写的话,跟下面
//线性探测的逻辑是一模一样的,所以没必要重新写
HashTable<K, V, HashFunc> newHT;
newHT._table.resize(newSize);
for (size_t i = 0; i < _table.size(); i++)
{
//把旧表中的存在的数据插入到新的哈希表
if (_table[i]._state == EXIST)
{
newHT.Insert(_table[i]._kv);
}
}
//两个vector交换,本质是交换vector的_start,_finish,_endofstorage指针,刚好还把
//旧哈希表中_start,_finish,_endofstorage指针交换给newTable,newTable是局部对象,
//出了作用域自动销毁,刚好满足我们的需求
_table.swap(newHT._table);
}
//计算映射的位置(下标)
//这里模的必须是_table.size(),因为_table是vector结构,有效的访问的区间是[0,_table.size()),
//如果这里模的是_table.capacity(),那么得到的值可能大于_table.size(),被看作为越界访问
size_t hashi = hf(kv.first) % _table.size();
//线性探测
//找到下一个被删除的或者为空的位置(可能是hashi本身,如果不是就往后找)
while (_table[hashi]._state == EXIST)
{
hashi++;
//取模一下可以从最后一个位置绕回来到第一个位置继续找,我们的结构的设计保证了这里一定能够
//找到一个空(或者被删除了的)位置,因为有效值的占比超过70%就会扩容了,所以这个数组不可能被填满的
hashi %= _table.size();
}
//走到这里说明一定找到了一个空(或者被删除了的)位置,因为数组的元素本身已经初始化成了HashData<K,V>的默认值,
//所以我们修改这个节点的pair和状态即可
_table[hashi]._kv = kv;
//把这个位置的节点的状态值标志位EXIST,表示这是一个有效值
_table[hashi]._state = EXIST;
_n++;
return true;
}
//打印函数
void Print()
{
for (size_t i = 0; i < _table.size(); i++)
{
if (_table[i]._state == EXIST)
{
cout << _table[i]._kv.first << ":" << _table[i]._kv.second << endl;
}
}
cout << endl;
}
private:
vector<HashData<K, V>> _table;
//记录插入的有效数据的个数
size_t _n = 0;
};
}
4.3 开散列
4.3.1 开散列概念
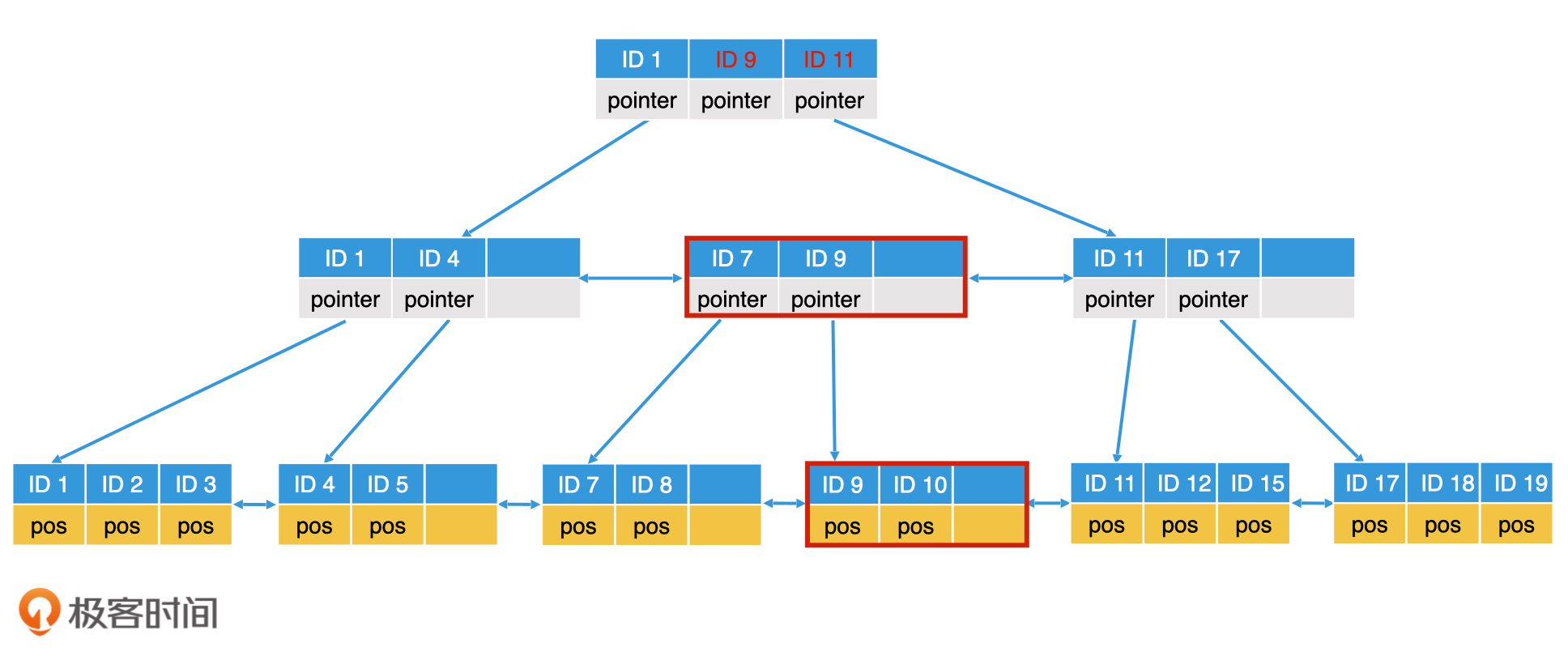
开散列法又叫链地址法(拉链法或者哈希桶),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
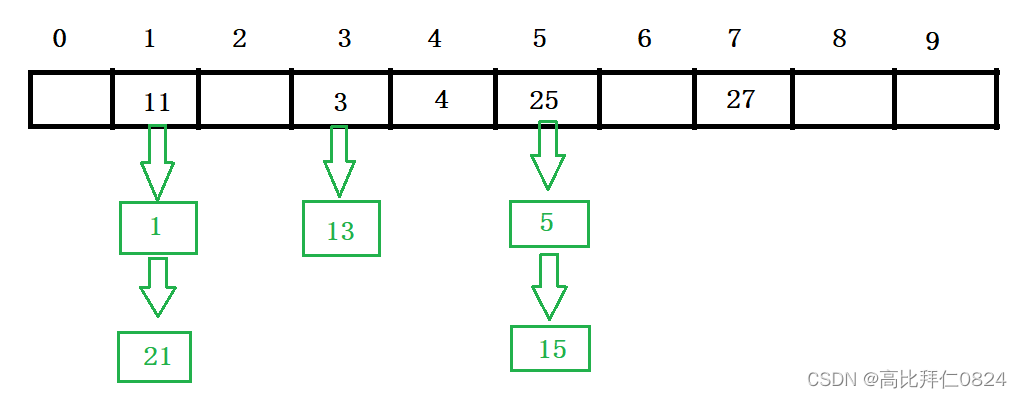
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
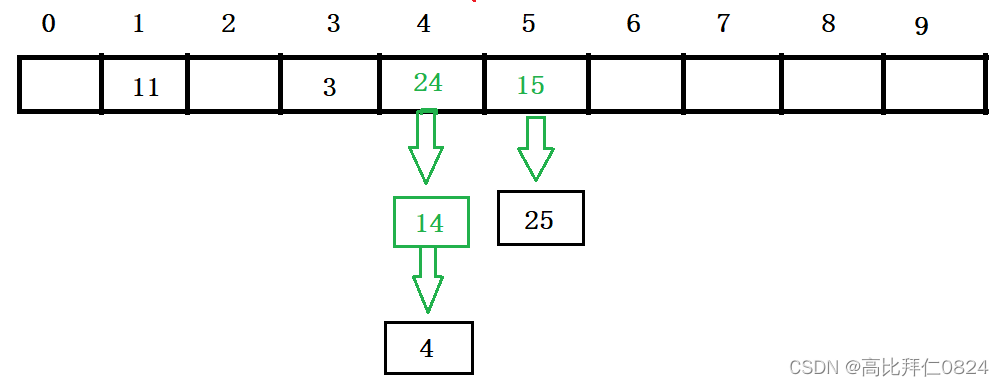
4.3.2 插入元素
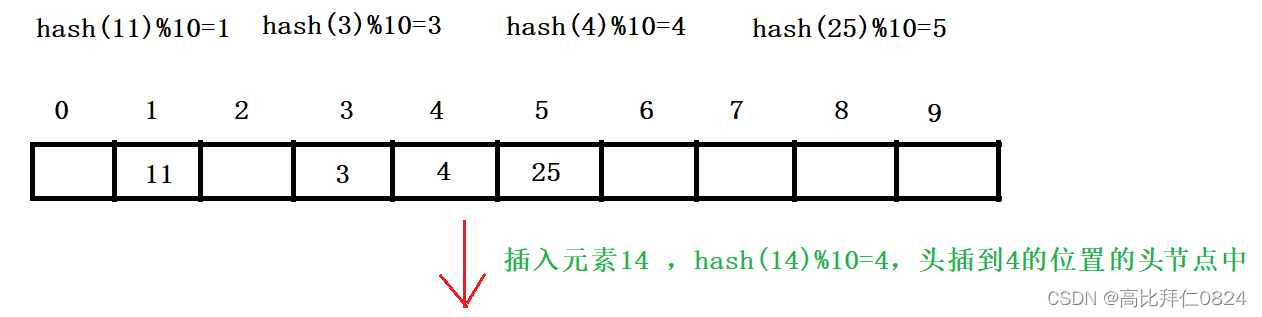
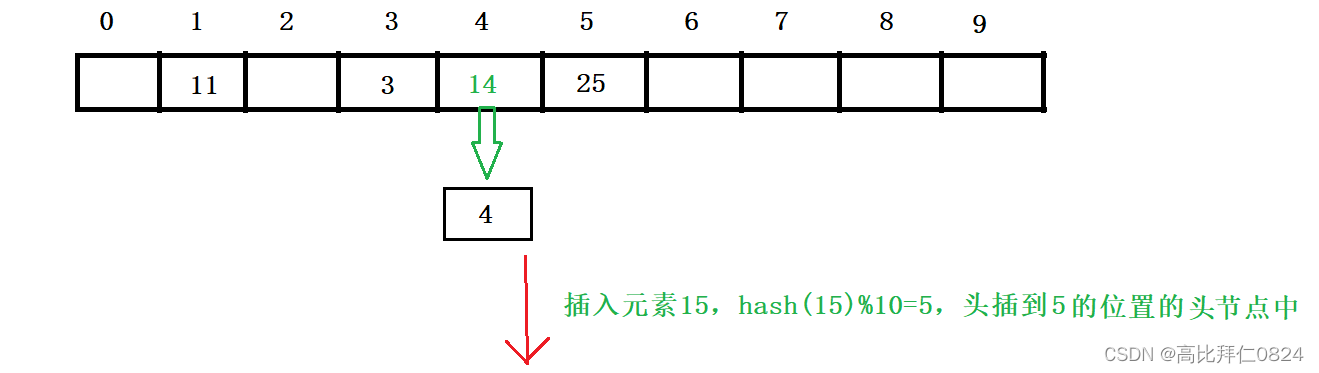
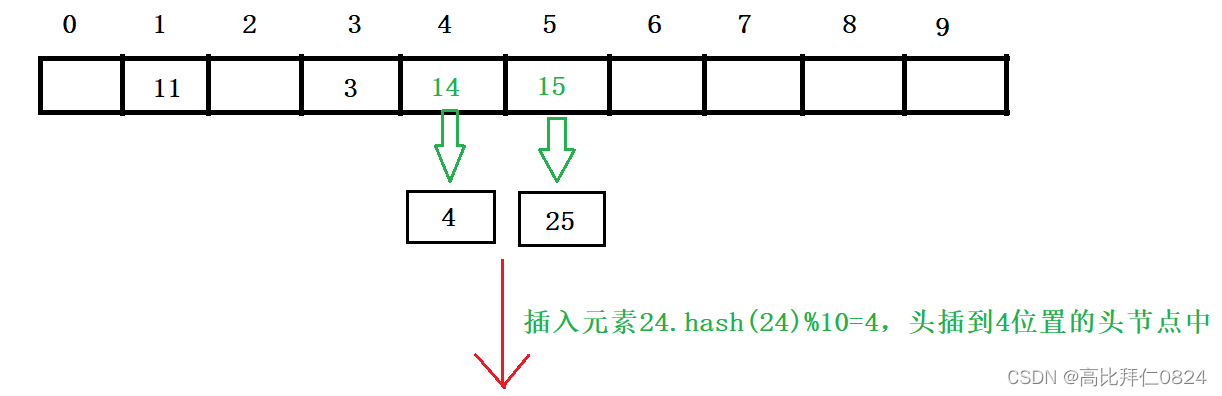
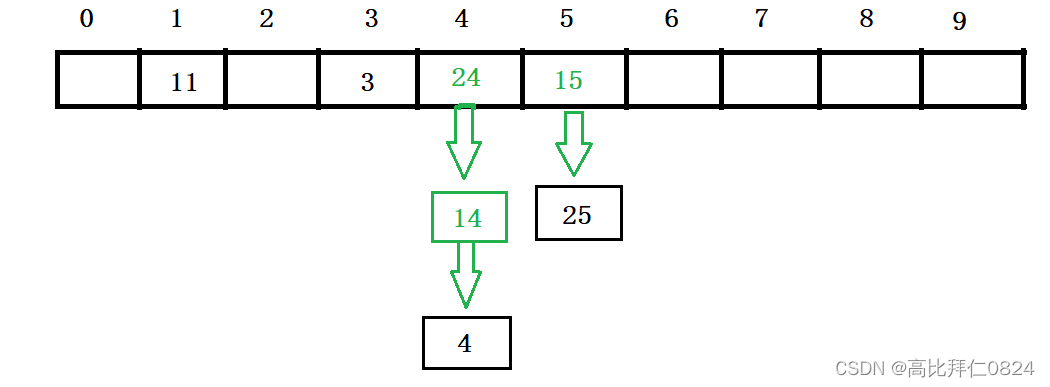
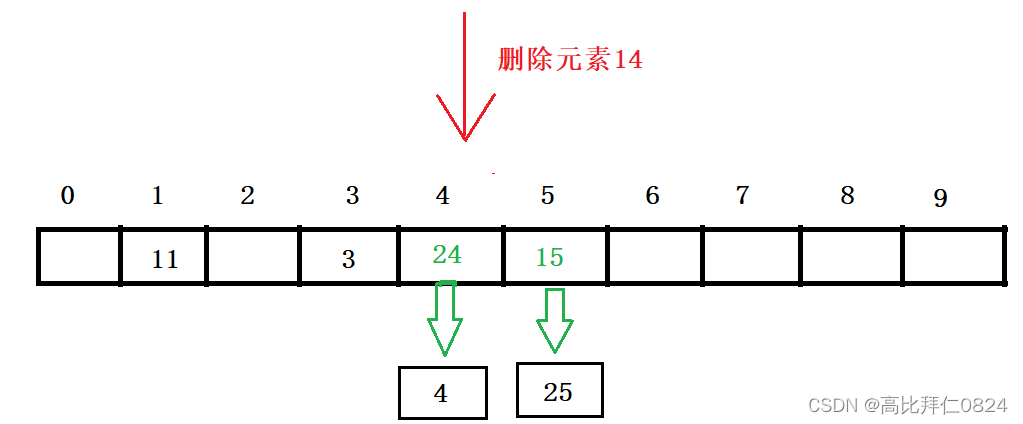
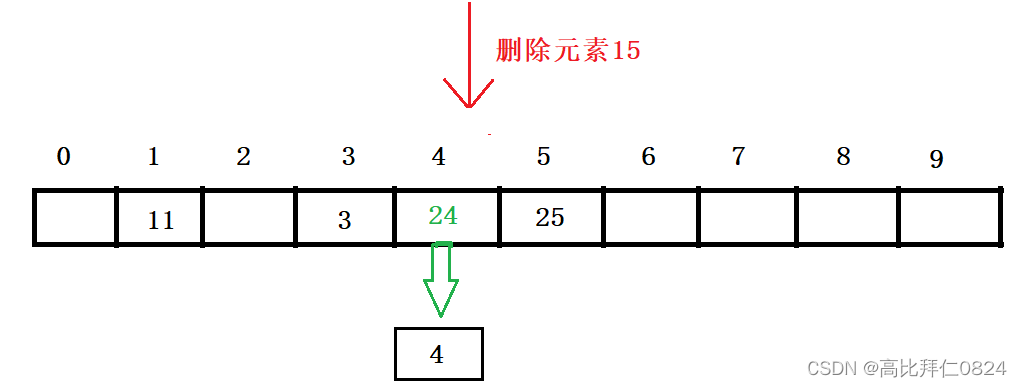
4.3.2 删除元素
就是先计算要删除的元素在数组中的哪一个位置,再在这个位置对应的单链表中查找要删除的元素并删除即可,本质还是单链表的删除。
4.3.3 开散列的哈希桶的增容
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可以给哈希表增容。
//扩容,插入的有效节点数等于数组的大小就扩容
if (_n == _table.size())
{
size_t newSize = _table.size() * 2;
//这里还适合定义一个新的对象,然后复用这个Insert函数插入旧表中的所有值吗?
//这里就不适合了,为什么呢?
// 1、因为这里数组中存放的是节点的指针,如果复用这个
//Insert函数,在Insert的逻辑中就会重新开辟出所有的节点插入到这个新对象,
// 然后还要自己把旧表中的所有的节点释放掉,反而变得麻烦了。
// 2、并且这里的插入并不需要线性探测找位置,直接头插到数组对应的位置就行了,所以
//这里可以选择直接开辟一个vector数组,然后把旧表中的所有节点都直接转移到这个vector
//这样新的vector和旧的vector交换就可以了,因为这里是转移节点,所以旧的vector中已
//经没有节点了,此时无需再自己手动释放掉旧的节点
vector<Node*> newTable;
newTable.resize(newSize, nullptr);
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
//计算旧节点在新的vector中的位置
size_t hashi = hf(cur->_kv.first) % newTable.size();
//把节点从旧表中转移头插到新表
cur->_next = newTable[hashi];
newTable[hashi] = cur;
cur = next;
}
//最后记得把旧表的该位置置空,免得后面非法访问
_table[i] = nullptr;
}
//最后交换两个vector表即可
_table.swap(newTable);
}
4.3.4 开散列的哈希桶(拉链法)代码实现
//仿函数
template <class K>
struct DefaultHashFunc
{
size_t operator()(const K& key)
{
//这里强转可以解决负数的映射问题
return (size_t)key;
}
};
//针对string类型的特化的仿函数,所有字符的ASCII值结合起来
template<>
struct DefaultHashFunc<string>
{
size_t operator()(const string& s)
{
size_t ret = 0;
for (const auto& ch : s)
{
//这个131是别人经过研究计算出来的一个值
//*=131目的是想尽可能地减少哈希冲突(哈希碰撞)
ret *= 131;
ret += ch;
}
return ret;
}
};
//拉链法,哈希桶
namespace hash_bucket
{
//拉链法中数组存放的是一个pair和_next指针的节点
template <class K,class V>
struct HashNode
{
pair<const K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<const K,V>& kv)
:_kv(kv)
,_next(nullptr)
{}
};
template <class K,class V,class HashFunc= DefaultHashFunc<K>>
class HashTable
{
//节点
typedef HashNode<K, V> Node;
public:
//构造函数
HashTable()
{
//初始化数组,因为数组就是插入节点的指针的,所以可以先把整个数组初始化成空指针即可
_table.resize(10, nullptr);
}
//析构函数
~HashTable()
{
//需要把整个数组中所有位置的链表的所有节点全部释放
//等于是遍历一遍这个指针数组
for (size_t i = 0; i < _table.size(); i++)
{
//把数组中所有不为空的位置的链表的节点遍历释放
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
//释放完某个位置后记得置空一下,免得后面非法访问
_table[i] = nullptr;
}
}
Node* Find(const K& key)
{
//利用仿函数把key变成可以取模的值,因为key可能是string等本身不能取模的类型
HashFunc hf;
//像函数一样使用这个仿函数,利用的一定的规则把key转换成某个整形,以便取模求出
//key值应该存储的位置的下标
size_t hashi = hf(key) % _table.size();
//遍历这个下标对应位置的链表,如果key存在,则一定在这个链表中
Node* cur = _table[hashi];
//遍历该key映射的数组位置的链表查找key值的节点
while (cur)
{
//找到了直接返回这个节点指针
if (cur->_kv.first == key)
{
return cur;
}
cur = cur->_next;
}
//找不到返回空
return nullptr;
}
bool Insert(const pair<K, V>& kv)
{
//如果该kv已经存在,就不再插入了,直接返回
if (Find(kv.first)!=nullptr)
{
return false;
}
HashFunc hf;
//扩容,插入的有效节点数等于数组的大小就扩容
if (_n == _table.size())
{
size_t newSize = _table.size() * 2;
//这里还适合定义一个新的对象,然后复用这个Insert函数插入旧表中的所有值吗?
//这里就不适合了,为什么呢?
// 1、因为这里数组中存放的是节点的指针,如果复用这个
//Insert函数,在Insert的逻辑中就会重新开辟出所有的节点插入到这个新对象,
// 然后还要自己把旧表中的所有的节点释放掉,反而变得麻烦了。
// 2、并且这里的插入并不需要线性探测找位置,直接头插到数组对应的位置就行了,所以
//这里可以选择直接开辟一个vector数组,然后把旧表中的所有节点都直接转移到这个vector
//这样新的vector和旧的vector交换就可以了,因为这里是转移节点,所以旧的vector中已
//经没有节点了,此时无需再自己手动释放掉旧的节点
vector<Node*> newTable;
newTable.resize(newSize, nullptr);
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
//计算旧节点在新的vector中的位置
size_t hashi = hf(cur->_kv.first) % newTable.size();
//把节点从旧表中转移头插到新表
cur->_next = newTable[hashi];
newTable[hashi] = cur;
cur = next;
}
//最后记得把旧表的该位置置空,免得后面非法访问
_table[i] = nullptr;
}
//最后交换两个vector表即可
_table.swap(newTable);
}
//计算新插入节点在表中的位置
size_t hashi = hf(kv.first) % _table.size();
Node* newNode = new Node(kv);
//头插到对应位置的单链表中
newNode->_next = _table[hashi];
_table[hashi] = newNode;
_n++;
return true;
}
bool Erase(const K& key)
{
HashFunc hf;
//计算删除元素在表中的位置
size_t hashi = hf(key) % _table.size();
//遍历表中对应下标位置的单链表找删除元素
Node* cur = _table[hashi];
Node* prev = nullptr;
while (cur)
{
//找到删除元素
if (cur->_kv.first == key)
{
//头删
if (prev == nullptr)
{
_table[hashi] = cur->_next;
}
//中间删除
else
{
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
void Print()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
printf("[%d]->", i);
while (cur)
{
cout << "(" << cur->_kv.first << ":" << cur->_kv.second << ")" << "->";
cur = cur->_next;
}
cout << "nullptr" << endl;
}
}
private:
vector<Node*> _table;//哈希表数组存放的是节点的指针,这个节点是一个链表的头节点
size_t _n = 0;//记录插入的有效节点的个数
};
}
4.3.5 关于开散列的思考
1、只能存储key为整形的元素,其他类型怎么解决?
因为我们计算元素在数组中存储的位置是通过除留余数法计算的,即用key模数组的大小得到的余数就是该元素在数组中的存储位置,也就意味着我们的key必须要是整形,因为只有整形才能取模,那么如果我们存储的key是一个字符串呢,字符串是不能取模的,这个时候我们该怎么处理呢?
如果我们要继续采用除留余数法计算key值对应的位置,我们就要想办法把这个字符串按照一定的规则转化成整形,再进行取模,这样就能得到这个字符串在数组中对应的存储位置了。
那么我们该如何把这个string转化成一个整形呢?
这个时候仿函数就要登场了,仿函数的作用在这种场景的就非常的好用,无论插入元素的key是什么类型的值我们都可以通过仿函数把它转化成整形,进而通过除留余数法计算出它在数组中的存储位置了。
//仿函数
template <class K>
struct DefaultHashFunc
{
//针对于存储元素的key值是int类型的仿函数,返回值就是这个key本身
size_t operator()(const K& key)
{
//这里强转可以解决负数的映射问题
return (size_t)key;
}
};
//针对string类型的特化的仿函数,所有字符的ASCII值结合起来
template<>
struct DefaultHashFunc<string>
{
//如果存储元素的key值是string,那么就把这个字符串的所有字符结合起来,算出一个整形
size_t operator()(const string& s)
{
size_t ret = 0;
for (const auto& ch : s)
{
//这个131是别人经过研究计算出来的一个值
//*=131目的是想尽可能地减少哈希冲突(哈希碰撞)
ret *= 131;
ret += ch;
}
return ret;
}
};
2、除留余数法,最好模一个素数,如何每次快速取一个类似两倍关系的素数?
以下是别人通过测试计算出来的哈希冲突较小的哈希函数:
size_t GetNextPrime(size_t prime)
{
const int PRIMECOUNT = 28;
static const size_t primeList[PRIMECOUNT] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
size_t i = 0;
for (; i < PRIMECOUNT; ++i)
{
if (primeList[i] > prime)
return primeList[i];
}
return primeList[i];
}
4.3.6 开散列与闭散列比较
拉链法(哈希桶)处理溢出,需要增设链接指针,似乎增加了存储开销。事实上:由于闭散列的开放地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <=0.7,而表项所占空间又比指针大的多,所以使用哈希桶反而比开放地址法更节省存储空间。
以上就是今天想要跟大家分享的内容啦,你学会了吗?如果感觉到有所帮助,你就点点赞点点关注呗,后期还会持续更新C++相关的知识哦,我们下期见啦!!!!!