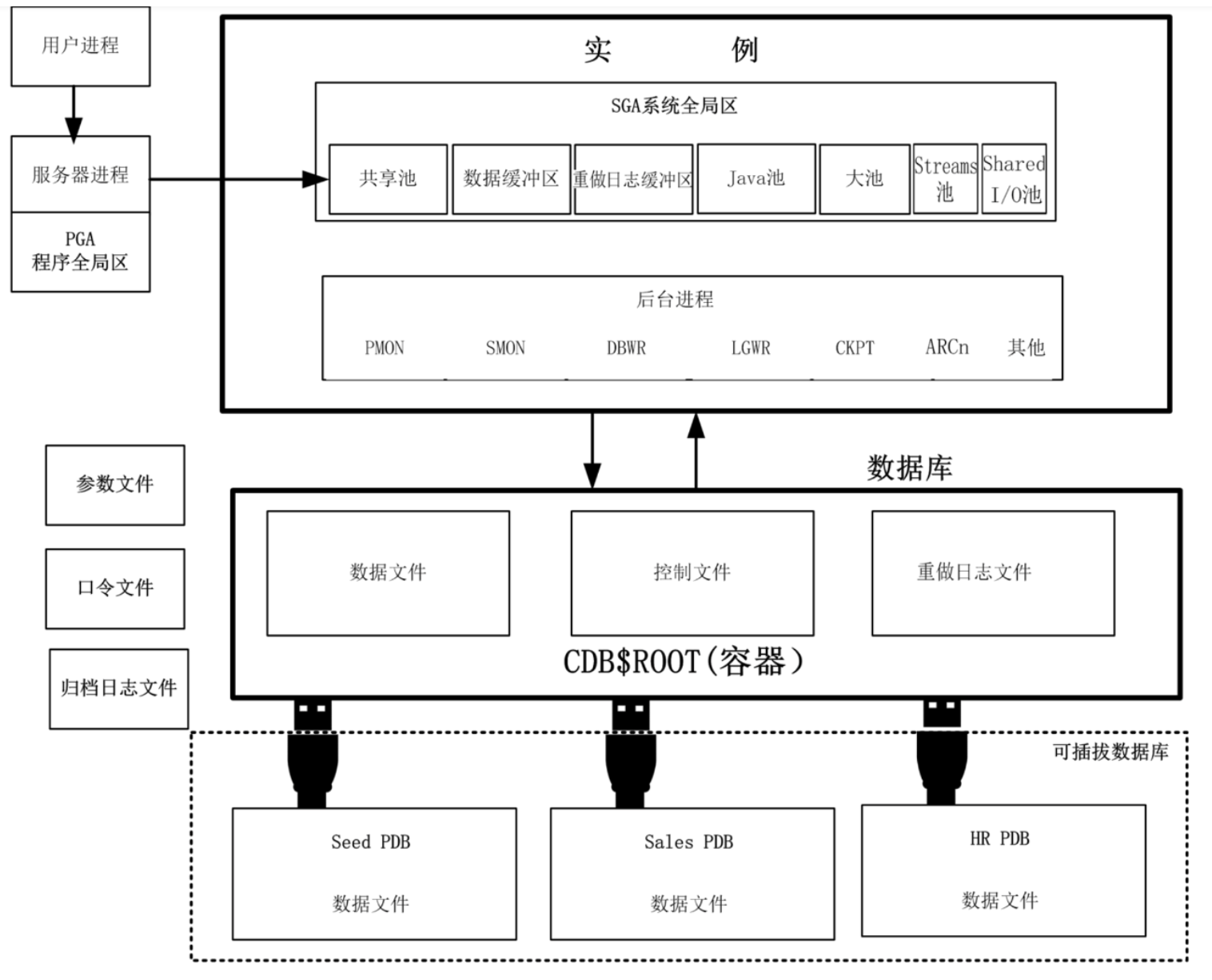
扩散模型的训练时比较简单的

上图可见,unet是epsθ是unet。noise和预测出来的noise做个mse loss。
训练的常规过程:
latents = vae.encode(batch["pixel_values"].to(weight_dtype)).latent_dist_sample()
latents = latents*vae.config.scaling_factor
noise = torch.randn_like(latents)
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
target = noise
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")具体分析:
diffusers/models/autoencoder_kl.py
AutoencoderKL.encode->
h = self.encoder(x)
moments = self.quant_conv(h)
posterior = DiagonalGaussianDistribution(moments)
AutoencoderKLOutput(posterior)diffusers/schedulers/scheduing_ddpm.py
add_noise(original_samples,noise,timesteps)->
noisy_samples = sqrt_alpha_prod*original_samples+sqrt_one_inus_alpha_prod*noise
![]()
transformers/models/clip/modeling_clip.py
CLIPTextModel.forward->
self.text_model()->
hidden_states = self.embedding(input_ids,position_ids)->
causal_attention_mask = self._build_causal_attention_mask(bsz,seq_len,hidden_states)
encoder_outputs = self.encoder(hidden_states,attention_mask,causal_attention_mask,output_attention,output_hidden_states)
last_hidden_state = encoder_outputs[0]
last_hidden_state = self.final_layer_norm(last_hidden_state)
pooled_output = last_hidden_state[torch.arange(last_hidden_state.shape[0], device=last_hidden_state.device), input_ids.argmax(dim=-1)]diffusers/models/unet_2d_condition.py


{
"_class_name": "UNet2DConditionModel",
"_diffusers_version": "0.19.3",
"act_fn": "silu",
"addition_embed_type": null,
"addition_embed_type_num_heads": 64,
"addition_time_embed_dim": null,
"attention_head_dim": 8,
"block_out_channels": [
320,
640,
1280,
1280
],
"center_input_sample": false,
"class_embed_type": null,
"class_embeddings_concat": false,
"conv_in_kernel": 3,
"conv_out_kernel": 3,
"cross_attention_dim": 768,
"cross_attention_norm": null,
"down_block_types": [
"CrossAttnDownBlock2D",
"CrossAttnDownBlock2D",
"CrossAttnDownBlock2D",
"DownBlock2D"
],
"downsample_padding": 1,
"dual_cross_attention": false,
"encoder_hid_dim": null,
"encoder_hid_dim_type": null,
"flip_sin_to_cos": true,
"freq_shift": 0,
"in_channels": 4,
"layers_per_block": 2,
"mid_block_only_cross_attention": null,
"mid_block_scale_factor": 1,
"mid_block_type": "UNetMidBlock2DCrossAttn",
"norm_eps": 1e-05,
"norm_num_groups": 32,
"num_attention_heads": null,
"num_class_embeds": null,
"only_cross_attention": false,
"out_channels": 4,
"projection_class_embeddings_input_dim": null,
"resnet_out_scale_factor": 1.0,
"resnet_skip_time_act": false,
"resnet_time_scale_shift": "default",
"sample_size": 64,
"time_cond_proj_dim": null,
"time_embedding_act_fn": null,
"time_embedding_dim": null,
"time_embedding_type": "positional",
"timestep_post_act": null,
"transformer_layers_per_block": 1,
"up_block_types": [
"UpBlock2D",
"CrossAttnUpBlock2D",
"CrossAttnUpBlock2D",
"CrossAttnUpBlock2D"
],
"upcast_attention": false,
"use_linear_projection": false
}
model_pred = unet(noisy_latents,timesteps,encoder_hidden_states).sample
0.center input
sample = 2*sample-1
1.time
t_emb = self.time_proj(timesteps)
emb = self.time_embedding(t_emb,timestep_cond)
2.pre-process
sample = self.conv_in(sample)
3.down
for downsample_block in self.down_blocks:
sample,res_samples = downsample_block(sample,emb)
down_block_res_samples += res_samples
4.mid
sample = self.mid_block(sample,emb)
5.up
for i,upsample_block in enumerate(self.up_blocks):
sample = upsample_block(hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size)
6.post-process
sample = self.conv_out(sample)扩散模型的推理:
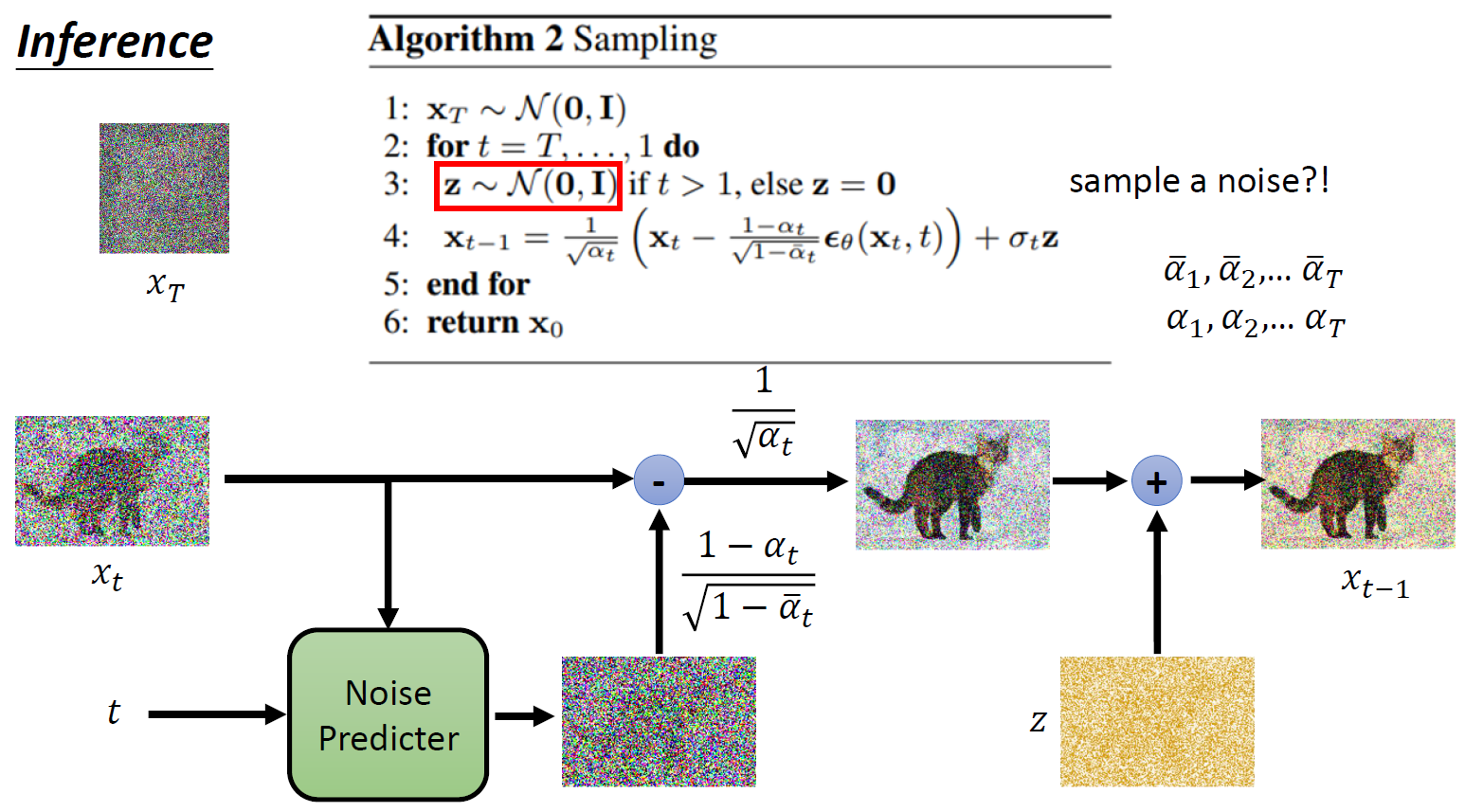
diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
StableDiffusionPipeline->
0.default height and width to unet
1.check inputs.
self.check_inputs(prompt,height,width,callback_steps,negative_prompt,prompt_embeds,negative_embeds)
2.define call parameters
batch
do_classifier_free_guidance
3.encode input prompt
prompt_embeds = self._encode_prompt(prompt,negative_prompt)
4.prepare timesteps
self.scheduler.set_timesteps(num_inference_steps)
timesteps = self.scheduler.timesteps
5.prepare latent variables
latents = self.prepare_latents(batch_size * num_images_per_prompt,num_channels_latents,height,width,prompt_embeds.dtype,device,generator,latents)
6.prepare extra step kwargs
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
7.denosing loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
for i,t in enumerate(timesteps):
latent_model_input = torch.cat([latents]*2)
latent_model_input = self.scheduler.scale_model_input(latent_model_input,t)
# predict the noise residual
noise_pred = self.unet(latent_model_input,t...)[0]
if do_classifer_free_guidance:
noise_pred_uncond,noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale*(noise_pred_text-noise_pred_uncond)
# compute the previous noisy sample x_t->x_t-1
latents = self.scheduler.step(noise_pred,t,latents,..)[0] # xt
image = self.image_processor.postprocess()diffusers/schedulers/scheduling_ddpm.py
step->
t = timesteps
prev_t = self.previous_timestep(t)
- prev_t = timestep-self.config.num_train_timesteps//num_inference_steps
1.compute alpha,betas
# 认为设置超参数beta,满足beta随着t的增大而增大,根据beta计算alpha
alpha_prod_t = self.alphas_cumprod[t]
alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
current_alpha_t = alpha_prod_t / alpha_prod_t_prev
current_beta_t = 1 - current_alpha_t
2.compute predicted original sample from predicted noise also called predicted_x0
pred_original_sample = (sample-beta_prod_t**(0.5)*model_output)/alpha_prod_t**(0.5)
3.clip or threshold predicted x0
pred_original_sample = pred_original_sample.clamp(-self.config.clip_sample_range,self.config.clip_sample_range)
4.compute coefficients for pred_original_sample x0 and current sample xt
pred_original_sample_coeff = (alpha_prod_t_prev**0.5*current_beta_t)/beta_prod_t
current_sample_coeff = current_alpha_t**0.5*beta_prod_t_prev/beta_prod_t
5.compute predicted previous sample
pred_prev_sample = pred_original_sample_coeff*pred_original_sample+current_sample_coeff*sample
6.add noise
variance_noise = randn_tensor()
variance = self._get_variance(t,predicted_variance)*variance_noise
pred_prev_sample = pred_prev_sample+variance
return pred_prev_sample,pred_original_sample

xt = pred_prev_sample,x0 = pred_original_sample,xt这个式子化简一下就是下面预测结果