https://zhuanlan.zhihu.com/p/651380539
https://github.com/ninehills/blog/issues/97
1. 检索增强生成 RAG
在问答和对话的场景下,通常可以通过检索和生成两种方式得到一个回复。检索式回复是在外部知识库中检索出满意的回复,较为可靠和可控,但回复缺乏多样性;而生成式回复则依赖于强大的语言模型中储存的内部知识,不可控,解释性差,但能生成更丰富的回复。把检索和生成结合起来,Facebook AI research 联合 UCL 和纽约大学于 2020 年提出:外部知识检索加持下的生成模型,Retrieval-Augmented Generation (RAG) 检索增强生成。
- 检索:这是指系统搜索庞大的数据库或存储库以查找相关信息的过程。
- 生成:检索后,系统生成类似人类的文本,整合获取的数据。
检索增强方法来克服大型语言模型(Large Language Models, llm)的局限性,比如幻觉问题(胡言乱语)和知识有限问题(常用于补充最新知识、公司内部知识)。检索增强方法背后的思想是维护一个外部知识库,在提问时检索外部数据,并将其提供给LLM,以增强其生成准确和相关答案的能力。
原理
RAG 由两部分组成:
- 第一部分负责在知识库中,根据 q u e r y x query_x queryx 检索出 top-k 个匹配的文档 z i z _i zi ;
- 第二部分将 query 和k个文档拼接起来作为QA的prompt,送入 seq2seq 模型,生成回复
y
y
y。
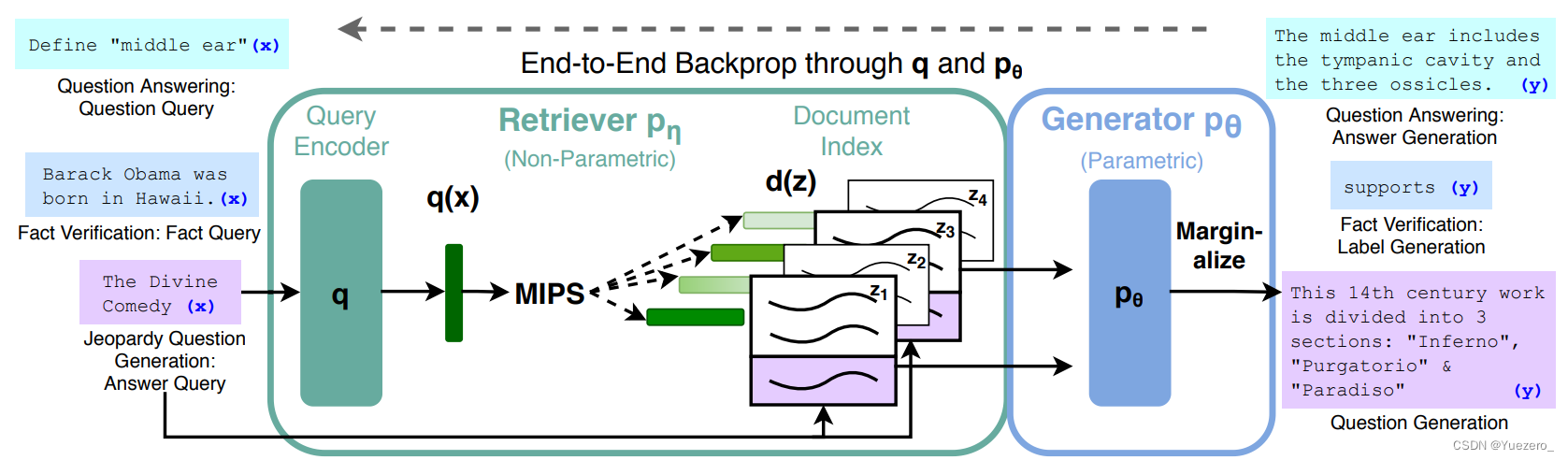
第一部分:Retriever
在第一部分 Retriver 中,RAG 通过两个不同的 BERT 把 外部知识 和 query 嵌入为稠密向量,做内积得到内积最大的 k 个文档。将 query 和 k个文档 拼接起来组成 k 个输入,作为第二部分的输入。
第二部分:Generator
Generator 中有两种使用文档的方式。
-
第一种称为 RAG-Sequence model:使用同一个文档生成每个词,先确定一个文档 z i z_i zi ,然后计算 p ( y ∣ x , z i ) p(y|x,z_i) p(y∣x,zi);
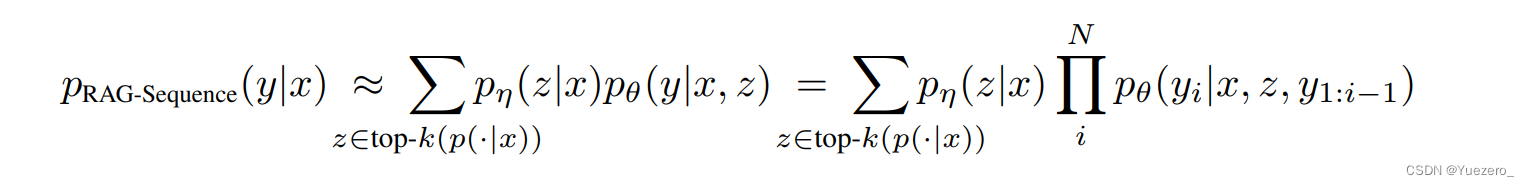
-
第二种称为 RAG-Token model:使用不同的文档生成每个词,对于第 i 个位置,候选词的概率等于所有文档的条件概率之和,即计算候选词对文档的边际概率。
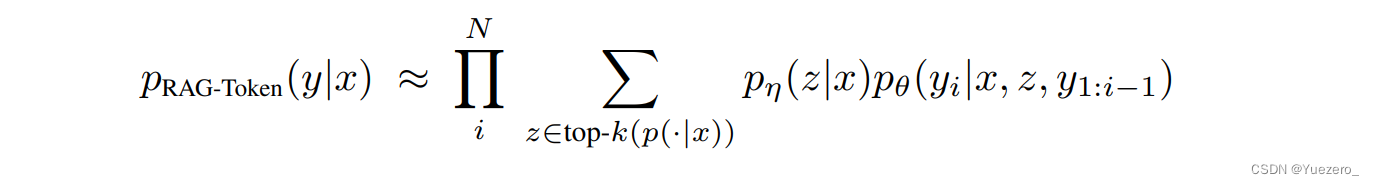
BART 是一个基于完整的 transformer 预训练模型,使用去噪作为预训练任务。作者选用 BART-large 作为 RAG 的生成器。
在训练过程中,只有负责嵌入 query 的 BERT 和负责生成的 BART 参与微调更新参数,负责嵌入外部知识的 BERT 不用更新参数。在测试过程中,RAG-Token model 在计算当前词的概率时,前面位置候选词的概率已经完成计算了。因此,RAG-Token model 如同朴素的生成模型一样使用 beam search 解码。而 RAG-Sequence model 要遍历完所有文档才能得到每个位置候选词的概率。因此需要对每个文档使用 beam search 解码,然后再整合。
8大挑战
数据源加载与处理
各种数据加载、解析过程中,如何尽可能保留原始数据的逻辑和语义关系是一个需要注意的问题。可以多尝试不同的加载与解析方式,对比不同的py库。也可预定于好prompt便于LLM理解。

一个好的prompt可以通过补充相关材料实现:背景知识、互联网检索结果、RAG检索结果、in-context QA实例。

数据切分难
- chunk_size: 对输入文本序列进行切分的最大长度。大语言模型一般会限制最大输入序列长度,比如GPT-3的最大输入长度是2048个token。为了处理更长的文本,需要切分成多个chunk,chunk_size控制每个chunk的最大长度。
- chunk_overlap: 相邻两个chunk之间的重叠token数量。为了保证文本语义的连贯性,相邻chunk会有一定的重叠。chunk_overlap控制这个重叠区域的大小。
举例来说,如果chunk_size设为1024,chunk_overlap设为128,则对一个长度为2560的文本序列,会切分成3个chunk:
chunk 1: 第1-1024个token
chunk 2: 第897-1920个token (与chunk 1重叠128个)
chunk 3: 第1793-2560个token (与chunk 2重叠128个)
这样的切分方式既满足了最大长度限制,也保证了相邻chunk间语义的衔接。适当的chunk大小和重叠可以提升大语言模型处理长文本的流畅性和连贯性。

如何对原始文本进行切分(如何选择 chunk size),影响很大,需要根据业务具体需求判断:
- 实验改超参数,不断测试
- 解耦 index 时和 generation时的 chunk size,这里也有两种方式:
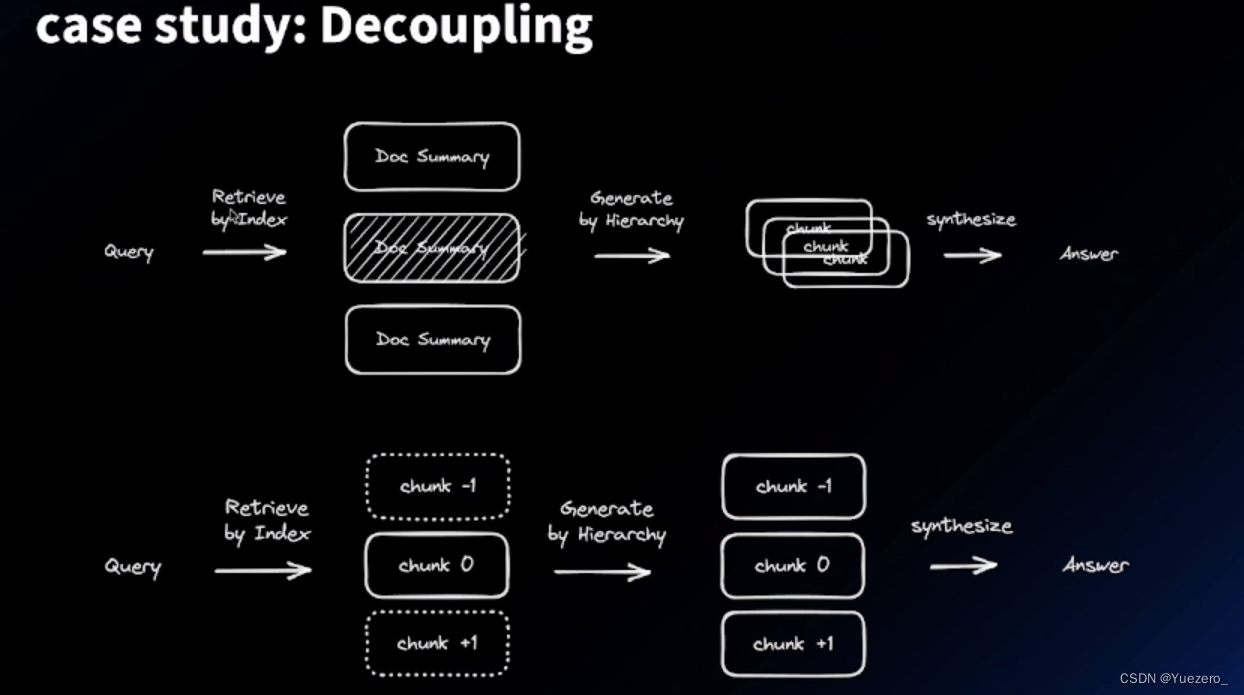
- 在检索时,文档如果可以构建为文档树结构,比如 段1段2,则可以先让 LMM 分别进行摘要,在搜索时首先根据摘要定位段落(也是使用相似度 ann 的方式 ),然后在段落内部 ann 检索。
- 将文档分的很小很小,这样每一个 chunk 内部的语义 已经很清晰了,然后检索到 chunk k 之后,我们取 chunk k-1, k, k+1 ,即相邻的 chunk 作为上下文。
检索效果不好

无法检索到有效的chunk (模型问题,切分问题) ; chunk 内部有无效信息 (先进行摘要,相关性过滤)。
提升方法:
- 可以使用 混合搜索 Hybrid Search ,即混合其他相似度评价指标,比如 Bm25,Keyword,Vector
- 混合其他的搜索字段,比如 元数据 meta-data,同时也可以考虑让 LLM 去抽取chunk 的大义,关键词;也可以结合上下文摘要
检索结果过多或过长

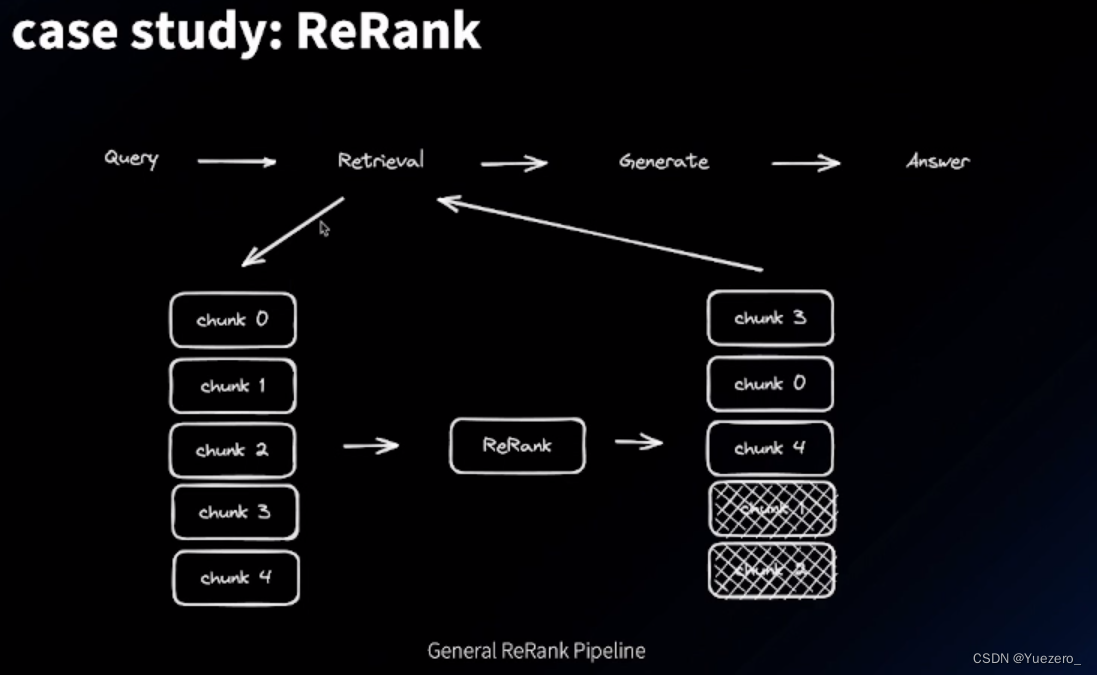
检索结果的过滤:后处理,其实就是一个重排的过程
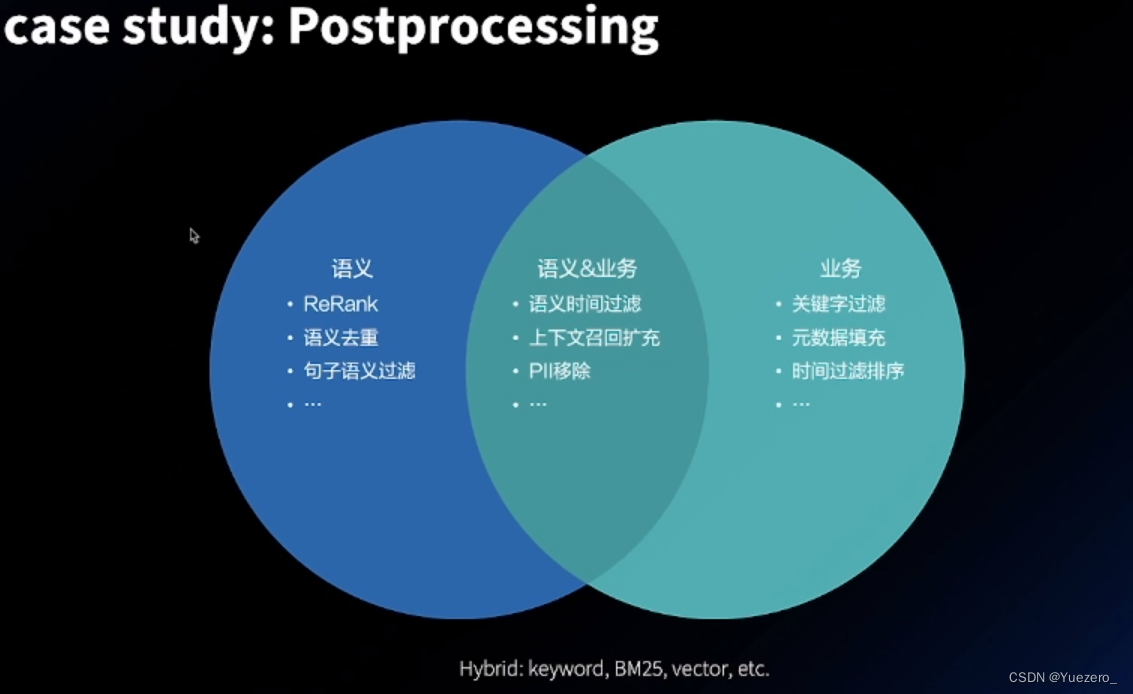
告诉模型 原始query 和 metadata 中类型的集合,让模型帮助我们得到子集合,从而进行筛选。
Re-rank 的问题 :需要真实业务 domain 的数据来微调;这里可以 尝试使用 LLM 来 rerank (给LLM写好prompt)。
答案合成策略:
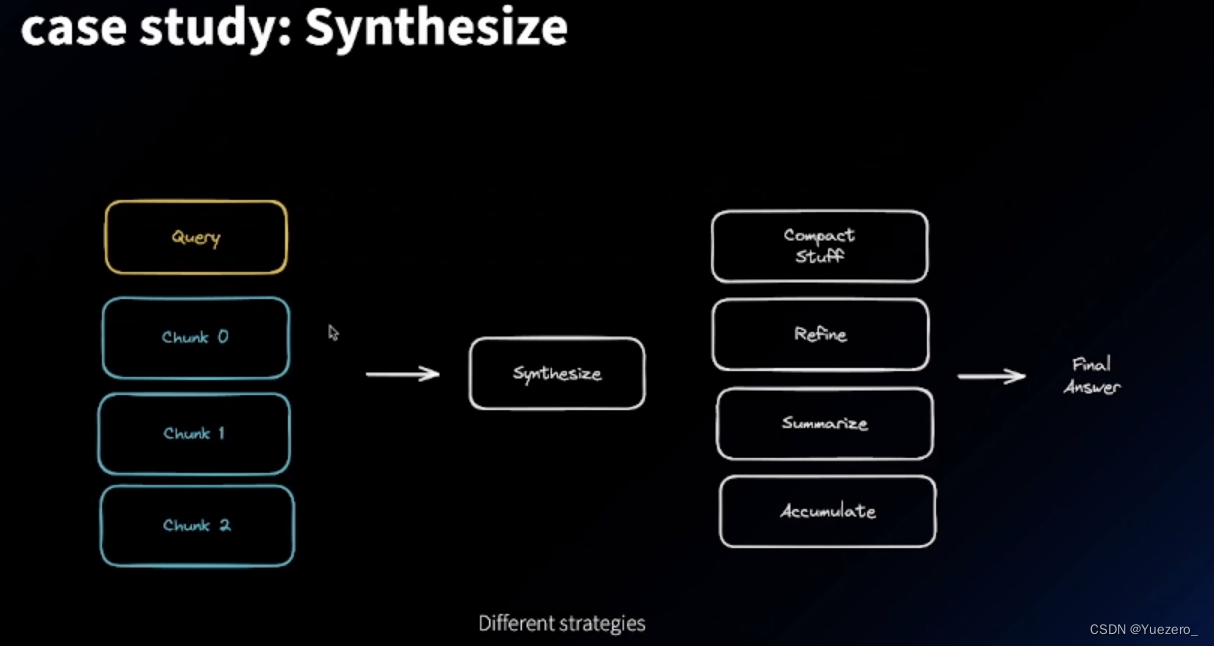
Default 版本:
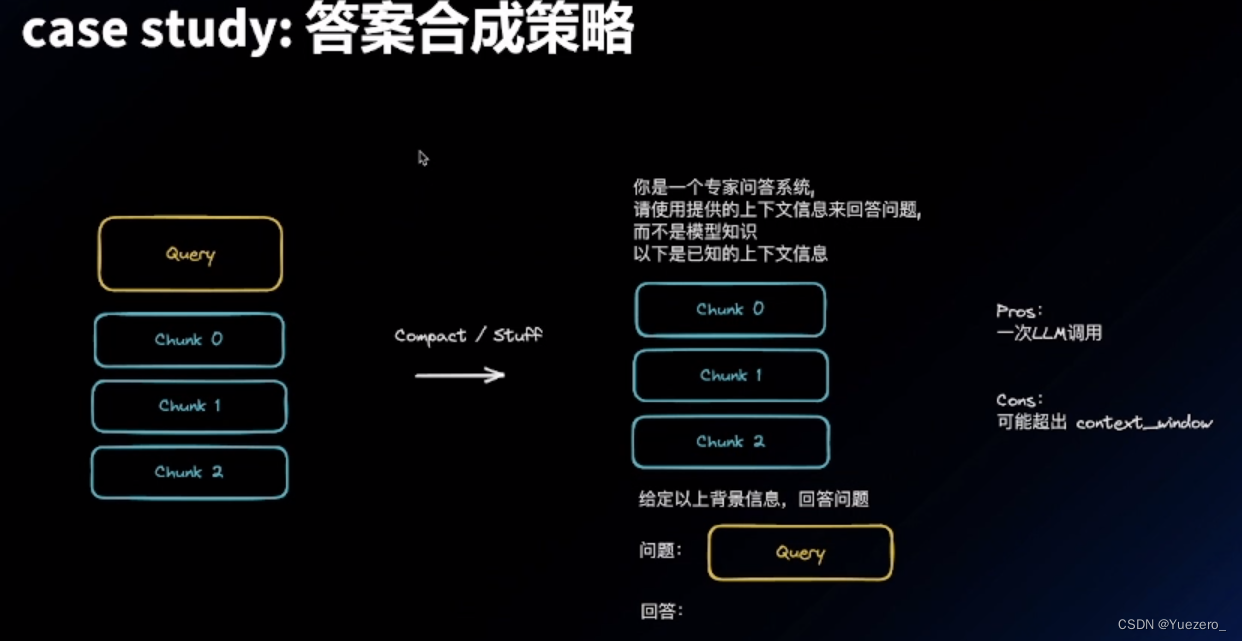
迭代式 refine 版本:一条 一条 chunk 输入,不断让模型修改更新原答案

可解释性与鲁棒性

复杂query的处理
Prompt → Sub-query , 不断拆分成子问题 → 直到可以回复

2. Atlas
Atlas: Few-shot Learning with Retrieval Augmented Language Models
Atlas :用检索增强的语言模型进行few-shot学习
Atlas 拥有两个子模型,一个检索器与一个语言模型。当面对一个任务时,Atlas 依据输入的问题使用检索器从大量语料中生成出最相关的 top-k 个文档,之后将这些文档与问题 query 一同放入语言模型之中,进而产生出所需的输出。
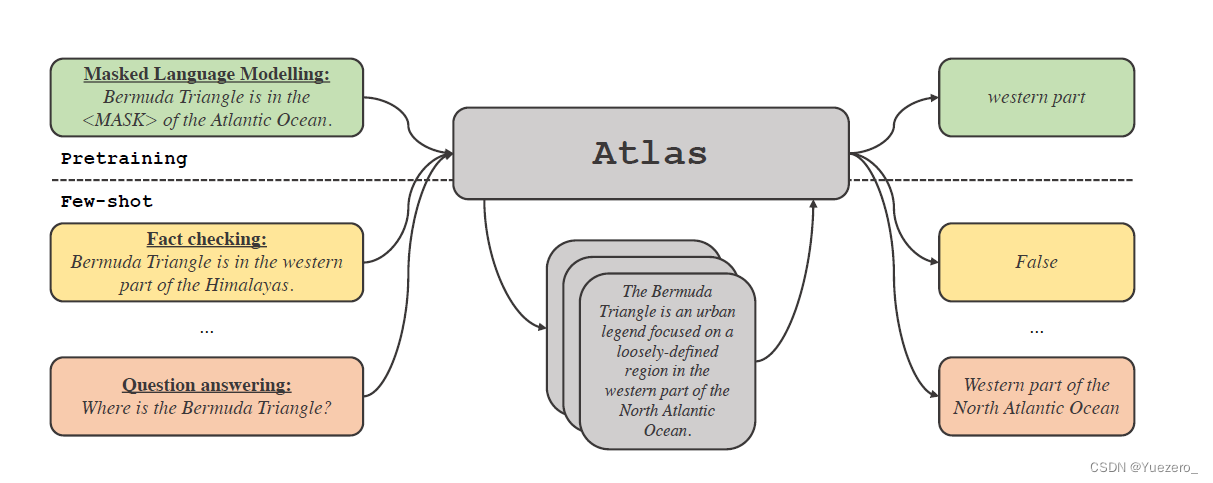
Atlas 模型的基本训练策略在于,将检索器与语言模型使用同一损失函数共同训练。检索器与语言模型都基于预训练的 Transformer 网络,其中:
- 检索器基于 Contriever 设计,Contriever 通过无监督数据进行预训练,使用两层编码器,query 与 document 被独立的编码入编码器中,并通过相应输出的点乘获得 query 与 document 的相似度。这种设计使得 Atlas 可以在没有文档标注的情况下训练检索器,从而显著降低内存需求。
- 语言模型基于 T5 进行训练,将不同文档与 query 相互拼接,由编码器分别独立处理,最后,解码器对于所有检索的段落串联进行 Cross-Attention 得到最后的输出。这种 Fusion-in-Decoder 的方法有利于 Atlas 有效的适应文档数量的扩展。
检索增强的优势
- 可解释性:大模型的黑箱属性,使得研究者很难以利用大模型对模型运行机理进行分析,而检索增强模型可以直接提取其检索到的文档,从而通过分析检索器所检索出的文章,可以获得对 Atlas 工作更好的理解。
- 可控性:我们往往会认为大模型存在训练数据“泄露”的风险,即有时大模型针对测试问题的回答并非基于模型的学习能力而是基于大模型的记忆能力,也就是说在大模型学习的大量语料中泄露了测试问题的答案,而在这篇论文中,作者通过人为剔除可能会发生泄露的语料信息后,模型正确率从56.4%下降到了55.8%,仅仅下降0.6%,可以看出检索增强的方法可以有效的规避模型作弊的风险。
- 可更新性:检索增强模型可以无需重新训练而只需更新或替换其依托的语料库实现模型的时时更新。
https://www.51cto.com/article/717069.html
https://zhuanlan.zhihu.com/p/595258642
https://zhuanlan.zhihu.com/p/563129454
3. REPLUG
REPLUG: Retrieval-Augmented Black-Box Language Models
这篇工作所提出的REPLUG模型可以说是“黑盒”式检索增强的代表。在这种新范式下,语言模型是一个黑盒子(它的参数被冻结了,不会被更新优化),检索组件才是可微调的部分。
RERLUG(Retrieve and Plug) 其实就是在语言模型上额外加了一个检索组件,利用检索组件获得一些相关信息,与原始输入一起作为语言模型的新输入,检索组件和语言模型都不需要训练。(个人认为某种程度上检索出来的加到原始输入即用户query上的这些文本有点像prompt)。
RERLUG LST(RERLUG with LM-Supervised Retrieval)可以看作是 RERLUG 的升级版,它利用语言模型产生监督信号,从而去优化检索组件,让检索组件倾向于挑选出能够降低语言模型所生成文本的困惑度。
https://blog.csdn.net/qq_27590277/article/details/129414851








![[hive]搭建hive3.1.2hiveserver2高可用可hive metastore高可用](https://img-blog.csdnimg.cn/b36e0643ebb545ff875c8a963c960f3e.png)