对于前5篇进程相关知识的补充
- 前言
- 正式开始
- 页表讲解
- 缺页中断
- 页表是如何映射的
- 页表的真正面目
- vm_area_struct
- mm_struct
- vm_area_stuct

前言
前面我的博客中讲了很多关于进程的知识,但是有一些内容需要做一点补充,补充完后我的下一篇博客就开始讲线程相关的知识了。
主要讲两个,一个是vm_area_struct,一个是页表的讲解。
如果各位对于进程不太熟悉,可以看看我前面的博客:
- 进程概念
- 进程控制
- 文件IO
- 进程间通信
- 信号详解
正式开始
首先来总结一下我前面对于进程的讲解。
进程是一大批的数据结构加上其所加载的代码和数据所形成的整体集合。
这一大批数据结构有哪些呢?
PCB、虚拟地址空间、页表、文件描述符相关结构、通信相关结构、信号相关结构…等等。这些结构都是因为os想要对进程和进程想要访问的资源进行管理而必须形成的,这样才能够管理好进程,这样进程对某种资源的访问关系就能变成某种数据结构上的关系。
再下来就是进程的代码和数据通过页表来映射,而页表又可分为用户级页表和内核级页表、内核级页表所有进程共享、用户级页表每个进程独一份。
故每个进程可以将自己的代码和数据的地址加载到虚拟地址的特定位置,虚拟地址再经过页表的映射就可以映射到内存的不同区域。
本篇博客基于这张图:
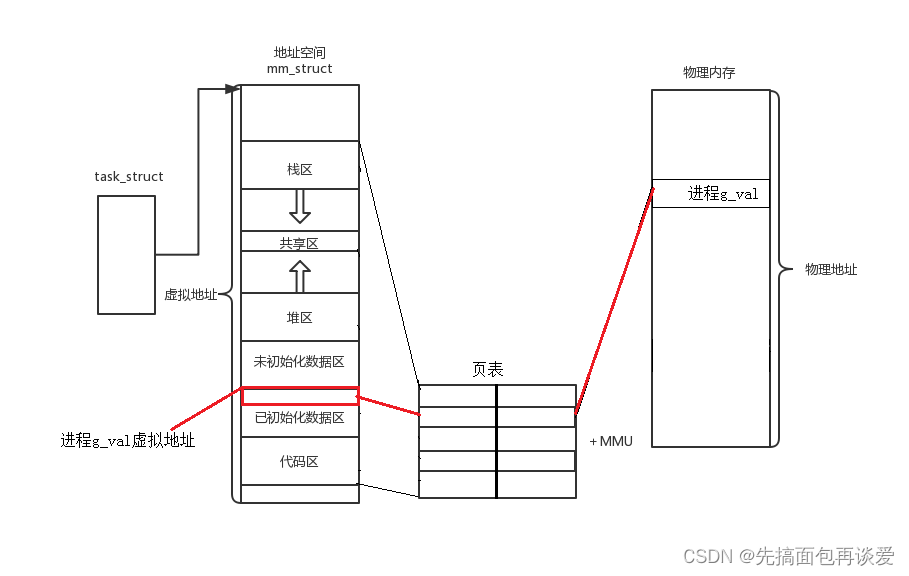
如果屏幕前的你不太懂,建议重点看看进程概念那篇博客。
页表讲解
我们存放在磁盘上的可执行文件,其地址空间就是按照0 ~ 4G的方式进行编译的,而且按照区域,也已经被划分成了以4KB为单位的各区间段(比如说代码段,由很多个4KB的空间组成)。拿我们生活这种的例子来说,一间房子,可以说它是多少平的方,比如说40平、60平、80平等等。这里的划分是对于磁盘上的文件而言的。
而我们实际的物理内存也被划分为了4KB大小的空间。
所以这就是为什么os在进行IO的时候是以4KB为单位进行的。
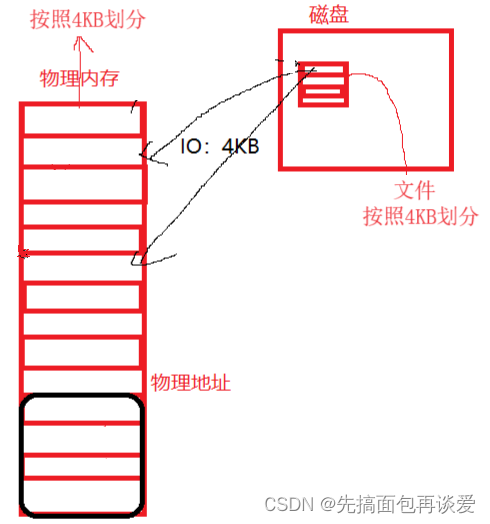
现在拿出4G物理内存,如果按照4kb划分的话,能够分出多少个4kb呢?
(4 * 1024 * 1024)kb / 4 kb,答案是
2
20
2^{20}
220 个,也就是说有一百多万个4KB,这么多4KB,os也得是要管理起来的,还是先描述再组织,os选择用struct page这个结构体来描述这4kb(下面的page代码不用细看):
struct page {
/* First double word block */
/* 标志位,每个bit代表不同的含义 */
unsigned long flags; /* Atomic flags, some possibly updated asynchronously */
union {
/*
* 如果mapping = 0,说明该page属于交换缓存(swap cache);当需要使用地址空间时会指定交换分区的地址空间swapper_space
* 如果mapping != 0,bit[0] = 0,说明该page属于页缓存或文件映射,mapping指向文件的地址空间address_space
* 如果mapping != 0,bit[0] != 0,说明该page为匿名映射,mapping指向struct anon_vma对象
*/
struct address_space *mapping;
void *s_mem; /* slab first object */
};
/* Second double word */
struct {
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
bool pfmemalloc;
};
union {
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
/* Used for cmpxchg_double in slub */
unsigned long counters;
#else
/*
* Keep _count separate from slub cmpxchg_double data.
* As the rest of the double word is protected by
* slab_lock but _count is not.
*/
unsigned counters;
#endif
struct {
union {
/*
* 被页表映射的次数,也就是说该page同时被多少个进程共享。初始值为-1,如果只被一个进程的页表映射了,该值为0 。
* 如果该page处于伙伴系统中,该值为PAGE_BUDDY_MAPCOUNT_VALUE(-128),
* 内核通过判断该值是否为PAGE_BUDDY_MAPCOUNT_VALUE来确定该page是否属于伙伴系统。
*/
atomic_t _mapcount;
struct { /* SLUB */
unsigned inuse:16;/* 这个inuse表示这个page已经使用了多少个object */
unsigned objects:15;
unsigned frozen:1;/* frozen代表slab在cpu_slub,unfroze代表在partial队列或者full队列 */
};
int units; /* SLOB */
};
/*
* 引用计数,表示内核中引用该page的次数,如果要操作该page,引用计数会+1,操作完成-1。
* 当该值为0时,表示没有引用该page的位置,所以该page可以被解除映射,这往往在内存回收时是有用的
*/
atomic_t _count; /* Usage count, see below. */
};
unsigned int active; /* SLAB */
};
};
/* Third double word block */
union {
/*
* page处于伙伴系统中时,用于链接相同阶的伙伴(只使用伙伴中的第一个page的lru即可达到目的)
* 设置PG_slab, 则page属于slab,page->lru.next指向page驻留的的缓存的管理结构,page->lru.prec指向保存该page的slab的管理结构
* page被用户态使用或被当做页缓存使用时,用于将该page连入zone中相应的lru链表,供内存回收时使用
*/
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
* Can be used as a generic list
* by the page owner.
*/
/* 用作per cpu partial的链表使用 */
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
/* */
short int pages;
short int pobjects;
#endif
};
struct slab *slab_page; /* slab fields */
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
/* First tail page of compound page */
struct {
compound_page_dtor *compound_dtor;
unsigned long compound_order;
};
};
/* Remainder is not double word aligned */
union {
/*
* 如果设置了PG_private标志,则private字段指向struct buffer_head
* 如果设置了PG_compound,则指向struct page
* 如果设置了PG_swapcache标志,private存储了该page在交换分区中对应的位置信息swp_entry_t
* 如果_mapcount = PAGE_BUDDY_MAPCOUNT_VALUE,说明该page位于伙伴系统,private存储该伙伴的阶
*/
unsigned long private;
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
#ifdef CONFIG_MEMCG
struct mem_cgroup *mem_cgroup;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
}
其中有一个成员flag,可以表示该4kb空间是否被占用、异常等状态。
想要把这么多page组织起来的话,os选择直接用数组,也就是struct page[100w+]这个数组来表示。当然,光是4G就100多万个元素,而这100多万个元素都要被放到物理内存中,肯定得省着用,所以page中有很多联合体,目的就是节省节省空间。
磁盘中的4kb叫做页帧,而物理内存中的一个4kb叫做页框,IO的时候就是一页帧对一页框,从磁盘中往物理内存中写入,哪怕是写入1bit,都得占用一对页帧和页框。
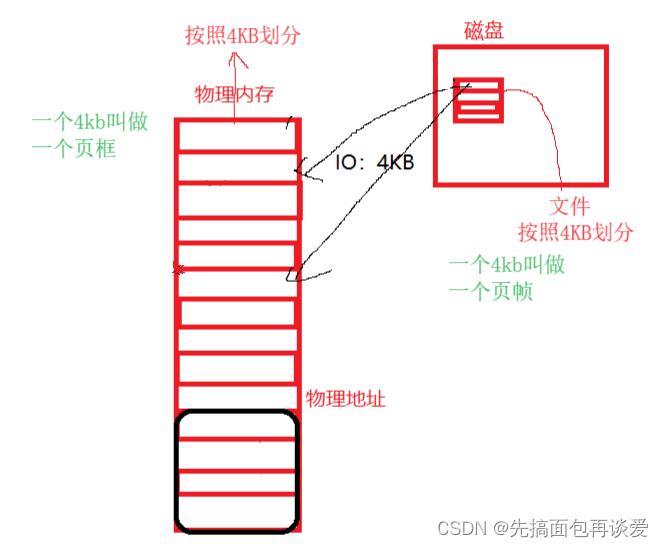
当进程刚创建的时候,并不会把虚拟内存中对应位置的数据和代码直接拷贝到物理内存中,只是先建立好虚拟内存和磁盘之间的映射,而这个映射就是通过页表来实现的,当真正使用到某一块数据和代码时才会将这些数据和代码按页加载到内存中并通过页表映射到虚拟内存,页表中专门有一个标记位来表示此时虚拟内存的映射是映射到磁盘中还是映射到了物理内存中。
当使用到某些数据和代码时,只需要看一下这个映射的标记位是磁盘还是物理内存,如果是磁盘,就先通过IO加载到物理内存中,然后再让虚拟地址与物理内存建立映射,并将标记位改为物理内存;如果是物理内存就直接用就行。而这里第一步的操作就叫做缺页中断(Page fault)。
还有一种较为官方的说法
进程创建时,并不会立刻将程序中的代码和数据直接拷贝到物理内存中。相反,操作系统会先为新创建的进程分配一块称为虚拟内存空间的内存区域。这个虚拟内存空间包括代码段、数据段和堆栈段等区域。
.
在进程运行时,当需要访问代码或数据时,操作系统会根据需要将对应的页面从磁盘加载到物理内存中。这个过程是按需加载的,也就是说只有当进程真正需要访问某个页面时,操作系统才会将该页面加载到物理内存中。
.
这种按需加载的机制有助于节省内存空间,并且允许操作系统更灵活地管理进程的内存使用。
缺页中断
再简单叙述一下整个过程:
- 先在物理内存中申请一个page
- 到磁盘中找到要执行的内容并将内容加载到申请的page中
- 将物理地址重新填入页表的映射关系中
- 返回给用户让用户继续访问
这个操作用户是感受不到的,唯一的感受就是第一次访问的时候慢一些,后面访问快一些。
页表是如何映射的
以32位的系统来讲,虚拟地址空间共有 2 32 2^{32} 232个地址,这样的话,如果页表想要构建出 2 32 2^{32} 232个映射关系,是不可能的。
假如说这是一个页表:
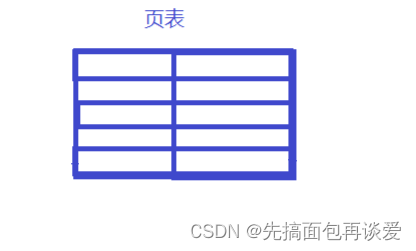
其中的一行叫做条目。假如说左边是虚拟地址,用K来表示,右边是物理地址,用V来表示,这样建立起KV映射,其中还有一个标志位表示虚拟地址的映射是在磁盘还是物理内存,这样的话,假设一个条目4字节。如果建立起 2 32 2^{32} 232 个映射,那就得 2 32 2^{32} 232 个条目,也就是 2 32 2^{32} 232乘以4Byte,1G是 2 30 2^{30} 230个字节, 那这么算下来的话就得16G的空间,这样物理内存想要放下整个这样的页表的话,怕是非常困难。
页表的真正面目
实际上,32位下的虚拟内存通过页表映射的时候是要分一级页表和二级页表来映射的。
假设一个条目还是4Byte,通过一级页表和二级页表的处理,也是没有任何问题的。
真正映射的时候,32位,不会全部用来映射。看图:
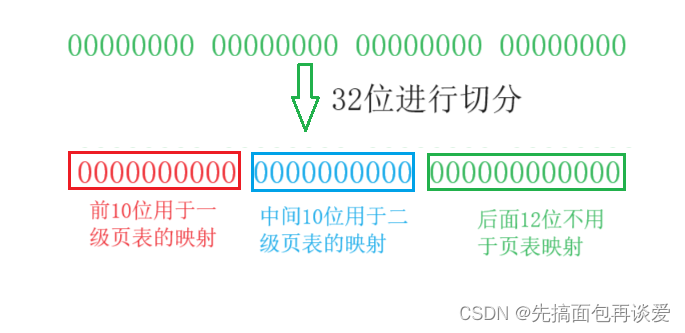
什么意思呢,再看图:
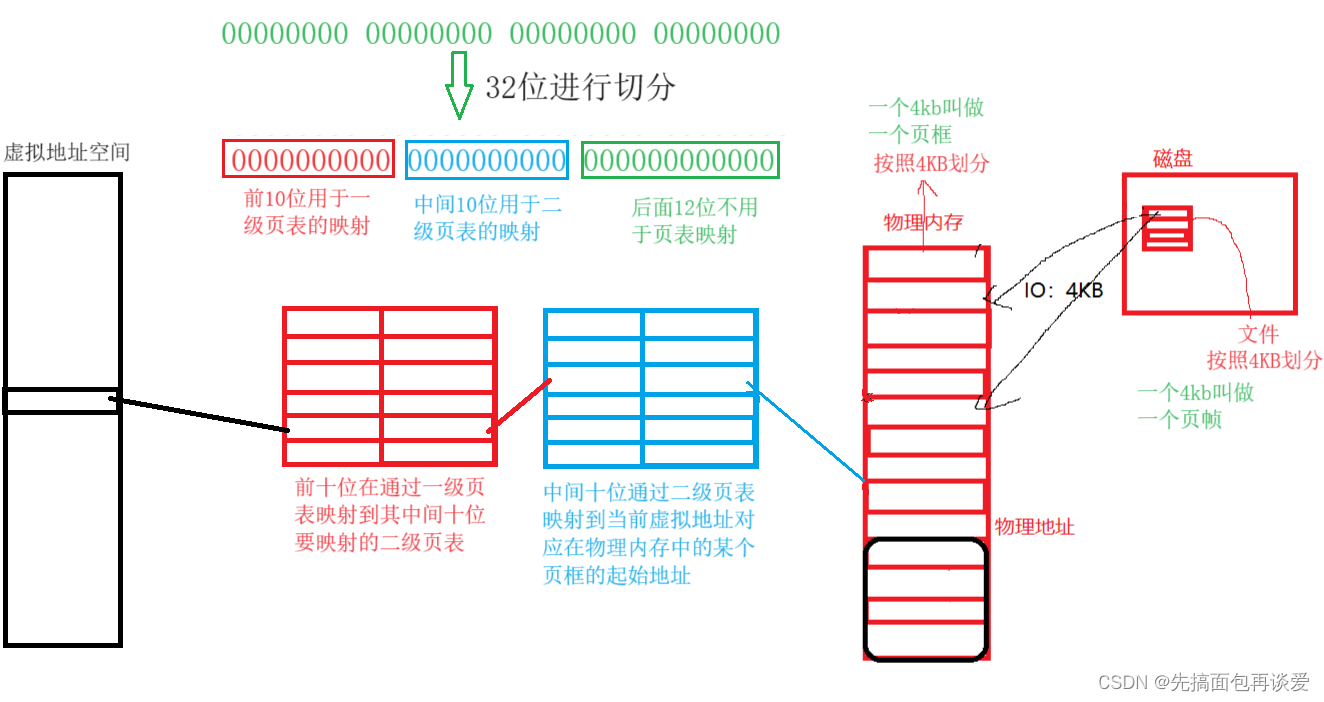
不知各位能看懂我画的图不,我再口头说一下,意思就是32位的地址映射时,会有两个页表(一级和二级)。
一级页表是用来让32位的前10位来映射的,这样算一下,10位,能够表示的数有 2 10 2^{10} 210个,也就是有1024个“地址”,那么一级页表就要产生1024个映射关系,也就是有1024个条目,如果一个条目4字节,那么就得4* 2 10 2^{10} 210个字节,也就是4kb。
一级页表有1024个条目,那么就会对每个虚拟地址产生对应的二级页表,也就是说如果一级页表的1024个条目都会产生映射的话,就要产生1024个二级页表,每个二级页表对应一个地址的中间10位的映射。
一级页表对某个虚拟地址前10位映射完了后就找到了对应的二级页表,然后二级页表再对每个地址的中间十位进行映射,会将某地址的中间10位映射到物理内存的特定页框的起始地址处。
同理,一个二级页表的大小也是4kb,但是如果一级页表将所有的虚拟地址全映射了,就会产生1024个二级页表,那么这样二级页表总共就是1024*4kb,也就是4MB。
- 为哈要映射到特定页框上呢?
记不记得我前面说的,一个页框4kb(4096Byte),32位中是不是还有后12位没有用到, 2 12 2^{12} 212不就是4096么,页框的初始位置加上32位地址中后十二位的数,不就能访问到一个页框中的所有字节了么。而这里后12位专业术语叫做页内偏移。由名字就可知其就是用来在每一页内进行地址偏移的。这样后面12位就不需要搞什么三级页表了(注意我一直在强调32位)。
再来算算这里页表的大小,一级页表4KB,二级页表撑死10MB,这样的话一级加二级也就是10MB+10KB,和前面的那个16GB可差的太多了,这样内存中也就完全能放的下了。
现在再看这张图是不是就能看懂了:
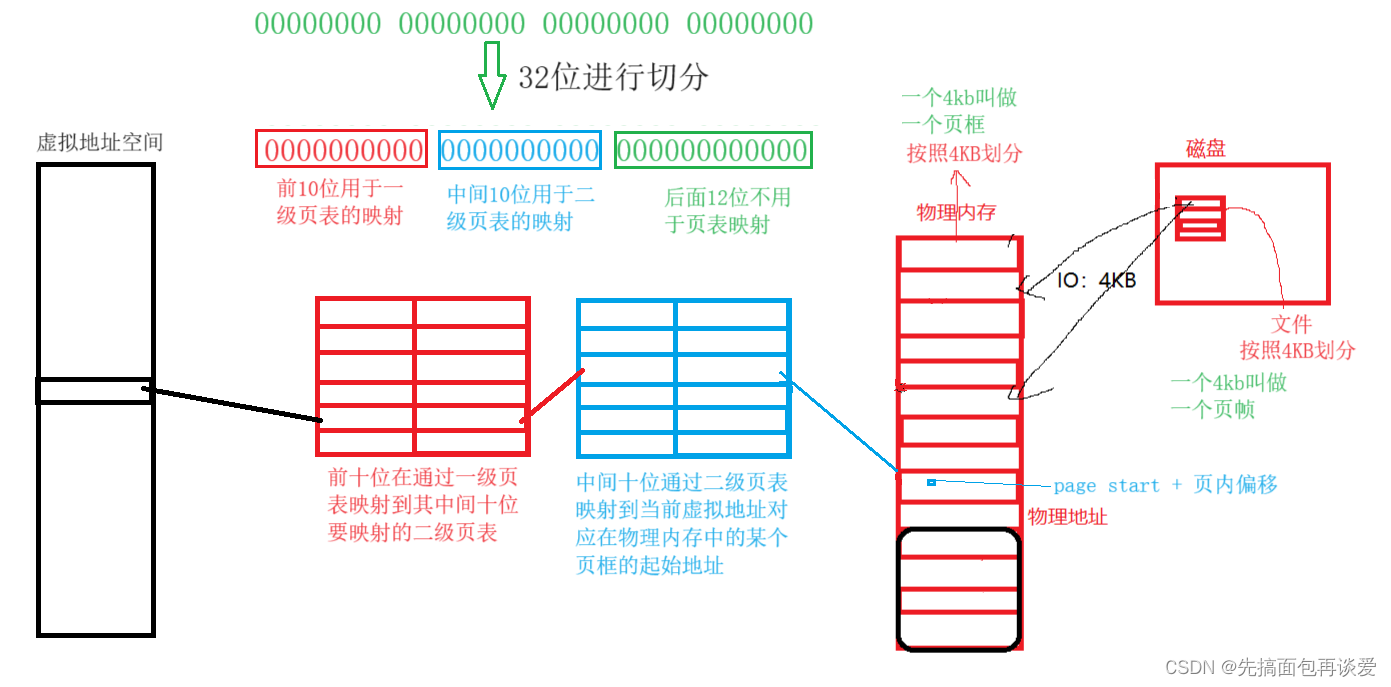
但是一个进程是不可能将其所有的虚拟地址全部映射到物理内存的,有的地址是用不上的。我前面的博客中也说过,os为每一个进程发了一张饼,都是4G大小,进程想要吃这张饼的话,得一口一口吃,有可能一张饼还吃不完,吃饱了撑的才回去全负荷式的将所有地址映射,4G空间全占用了,一个进程用不完,不如分给别的进程一块用。
那么这样的话,一个进程就不可能将二级页表打满,一级页表只需要一个,二级页表七八个就够用了,所以这样算下来页表的体积就变得更小了,二级页表按10个来算,总共也就44KB,这样就完全不需要考虑页表占用空间太大了。
所以说32位下,将地址按照10、10、12这样划分,通过一级页表 + 二级页表 + 页内偏移即可,而这里的页表严格意义上讲并不是建立虚拟地址空间与物理地址空间的映射,更准确的说法是这个页表建立的是虚拟地址到特定页的映射,找到page的起始地址,再通过page起始地址加上后面的页内偏移来找到对应的物理内存。
64位下,核心思路相同,也是先找到page,再page起始地址 + 页内偏移,不过是页表层级更多一点罢了。
vm_area_struct
一个进程的虚拟地址空间主要由两个数据结来描述。
- 一个是最高层次的:mm_struct。
- 一个是较高层次的:vm_area_structs。
mm_struct
最高层次的mm_struct结构描述了一个进程的整个虚拟地址空间。
较高层次的结构vm_area_truct描述了虚拟地址空间的一个区间(对虚拟地址中每个不同的区的描述)。
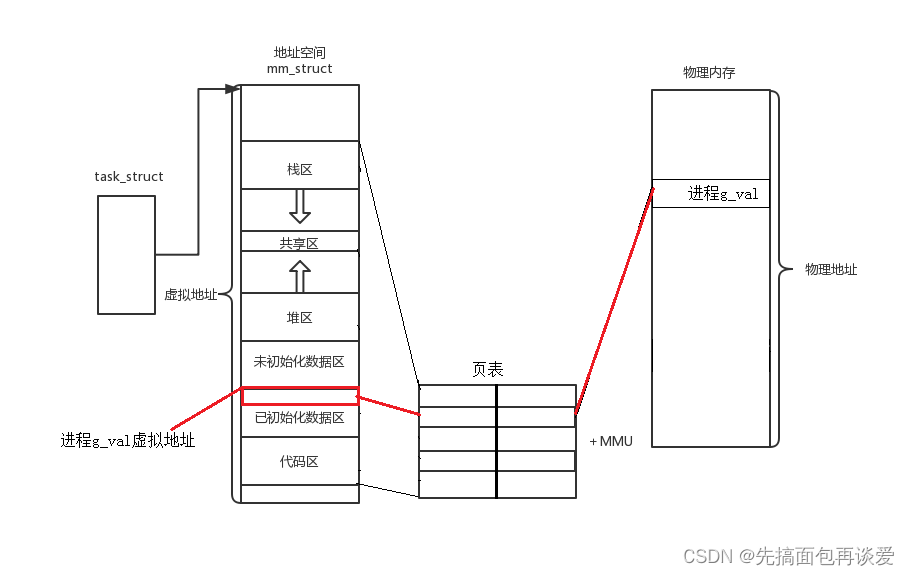
每个进程只有一个mm_struct结构,在每个进程的task_struct结构中,有一个指向该进程的结构。可以说,mm_struct结构是对整个用户空间的描述。
也就是这张图:
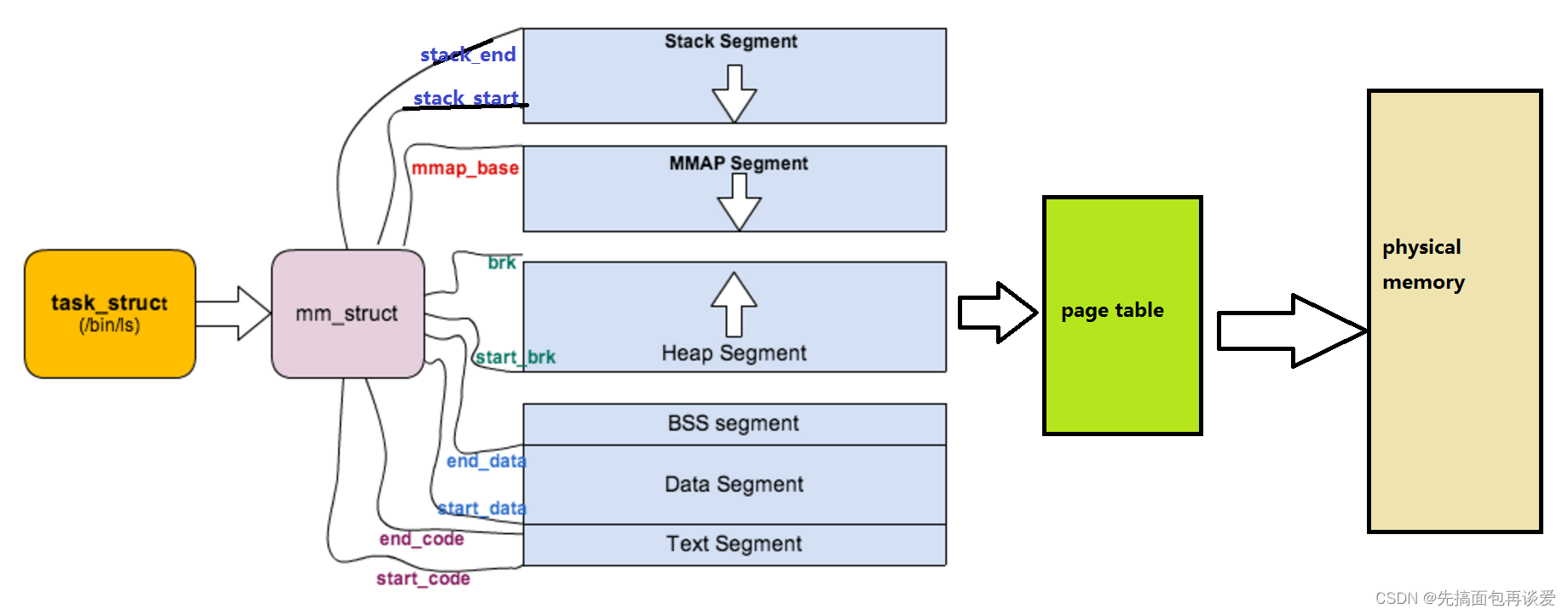
其中对于蓝色部分的,就是这张:
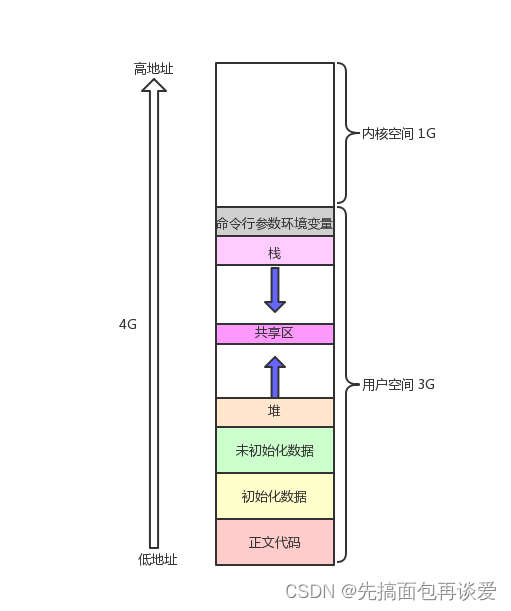
mm_struct是对整个的虚拟地址空间的描述。其中用整数保存了各个区的起始地和终止地址,也就是这样:

也就是刚刚的这张图:
vm_area_stuct
vm_area_struct维护的是整个虚拟地址中的小区间,一个vm_area_struct对象维护一个小区间。
而且对于每个小区间的维护就可看作是一个节点,vm_area_struct中也有prev和next指针,这样每个区间用一个vm_area_struct对象来维护,就可以把每个vm_area_struct对象连起来,就形成了双向链表:
struct vm_area_struct
{
unsigned long vm_start; // 每个区的开始地址
unsigned long vm_end; // 每个区的结束地址
struct vm_area_struct *vm_next, *vm_prev; // 前后指针
...
}
下图是一个老版本vm_area_struct的结构,老版本下实现的是一个单链表,如下图:
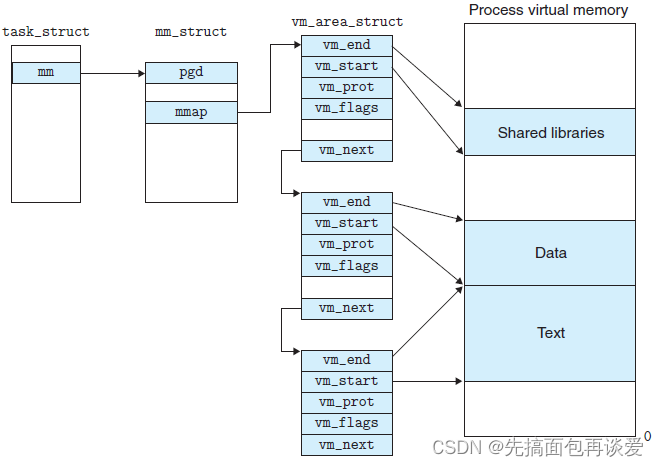
可以看到mm_struct中有一个指针指向vm_area_struct队列的头结点:
//指向链表头
struct vm_area_struct * mmap; /* list of VMAs */
还有一个比较好的图:
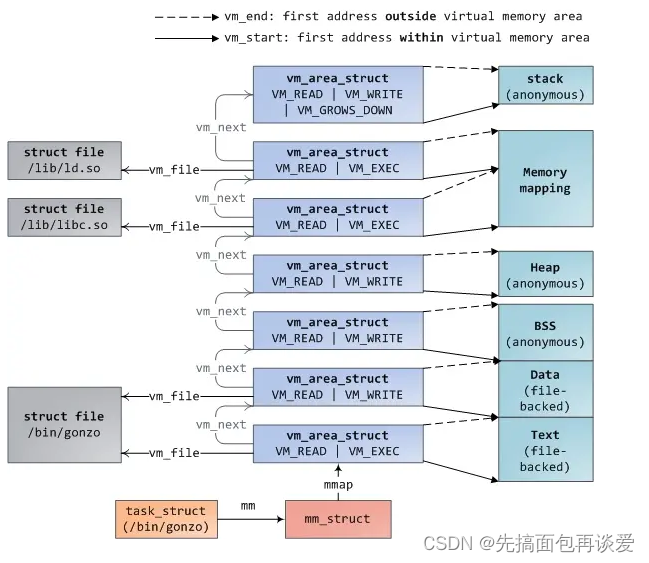
在用户空间可通过"/proc/PID/maps"接口来查看一个进程的所有vma在虚拟地址空间的分布情况,其内部实现靠的就是对这个链表的遍历:
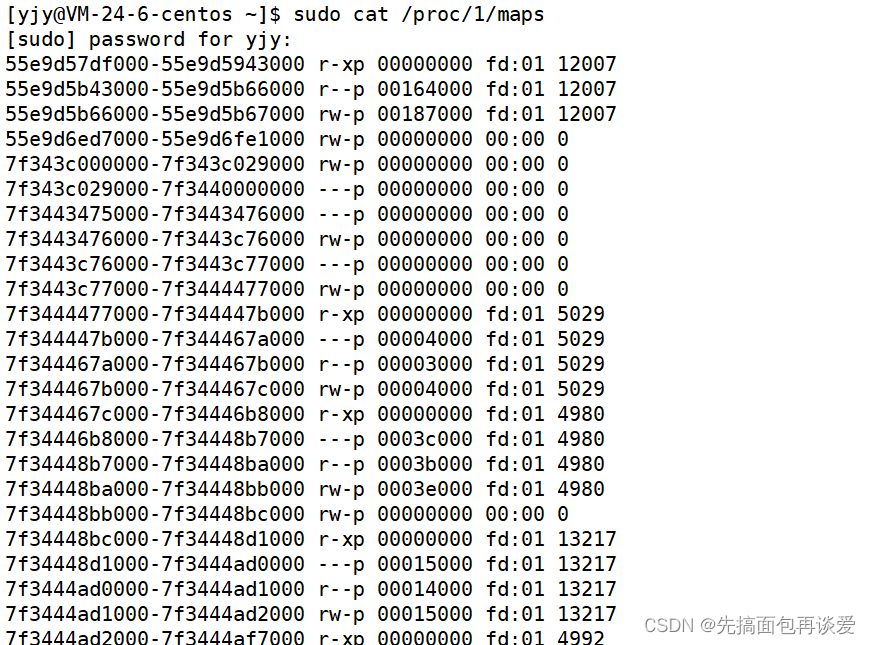
而vm_area_struct中还有一个红黑树节点:
rb_node_t vm_rb; // 红黑树节点
这里是为了更快速的查找某一块空间而搞的。使用链表管理固然简单方便,但是通过查找链表找到与特定地址关联的vm_area_struct,其时间复杂度是O(N),而现实应用中,在进程地址空间中查找vm_area_struct又是非常频繁的操作,用红黑树就可以达到O( l o g 2 N log_2N log2N)。
同样的mm_struct中也有一个红黑树节点用来指向这棵vm_area_struct红黑树:
//指向红黑树
struct rb_root mm_rb;
也就如下图所示:
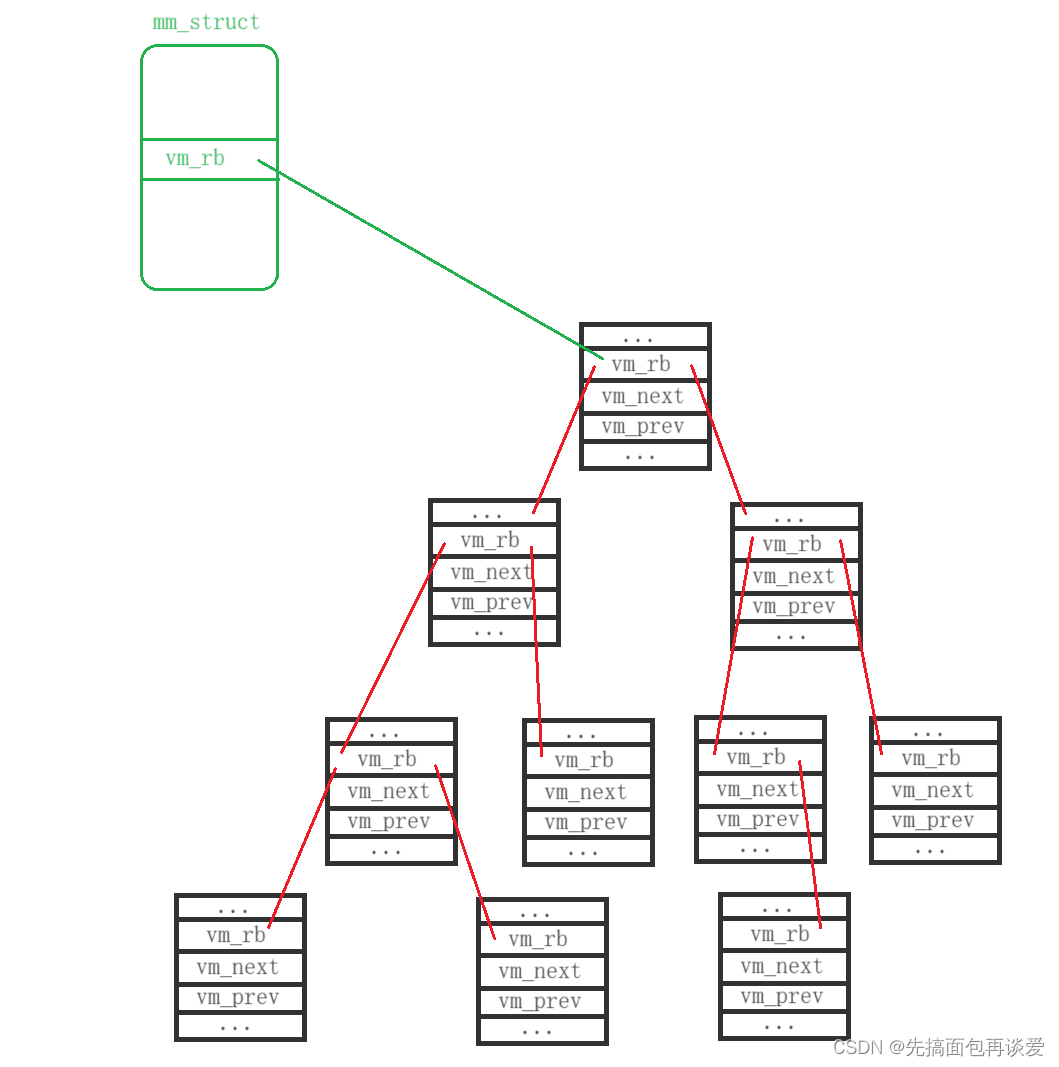
vm_area_struct中还有一个字段需要了解一下:
unsigned long vm_flags;
vm_flags描述的是vma的属性,flag可以是VM_READ、VM_WRITE、VM_EXEC、VM_SHARED,分别指定vma的内容是否可以读、写、执行,或者由几个进程共享。
os可以对进程资源进行更为细粒度的划分,前面博客的mm_struct中所描述的空间是比较粗略的,os可通过设计一些数据结构来实现对其再次划分,vm_area_struct就是。
能力有限,就讲这么多。
到此结束。。。