文章目录
- 前言
- Knn-LM
- Insight
- Method
- Results
- Domain Adaption
- Tuning Nearest Neighbor Search
- Analysis
- REALM
- Insights
- Method
- Knowledge Retriever
- Knowledge-Augmented Encoder
- Exp
- Result
- Ablation Study
- Case Study
- DPR
- Insight
- Method
- Experiments
- Results
- RAG
- Insight
- RAG-Sequence Model
- RAG-Token Model
- Retriever: DPR
- Generator: BART
- Training
- Decoding
- FID
- Insights
- Method
- Results
- COG
- Insight
- Method
- Training
- Results
- Standard language modeling
- Domain adaption
- Enlarged phrase index
- GenRead
- Insights
- Method
- Results
- REPLUG
- 前言
- REPLUG
- REPLUG LSR: Training the Dense Retriever
- Computing Retrieval Likelihood
- Computing LM likelihood
- Training Setup
- Model
- Training data
- Results
- Language Modeling
- MMLU
- Open Domain QA
- Analysis
- When not to trust language models
- Insight
- Evaluation Setup
- Res
- without retrieval
- with retrieval
- Adaptive retrieval
- Summary
前言
- 很久没有发博客了,今天翻到之前对检索增强的总结,觉得比较有意义
- 模型:
Knn-LM->REALM->DPR->RAG->FID->COG->GenRead->REPLUG->Adaptive retrieval
Knn-LM
Insight
- LMs typically solve two subproblems:
- mapping sentence prefixes to fixed-sized representations
- using these representations to predict the next word in the text
- Hypothesis: the representation learning problem may be easier than the prediction problem(use representation to help predict next word)
- Introduce
kNN-LM, an approach that extends a pre-trained LM by linearly interpolating its next word distribution with a k-nearest neighbors (kNN) model.
Method

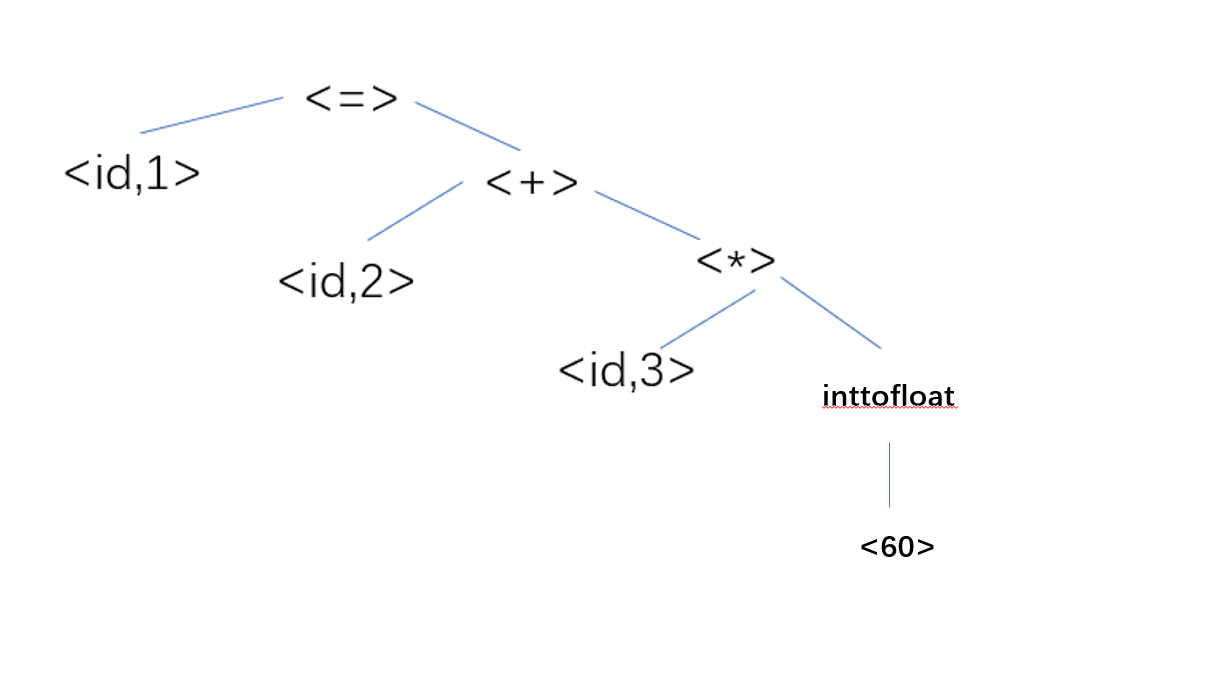
Datastore: ( K , V \mathcal{K,V} K,V), the set of all key-value pairs constructed from all the training examples in D D D

- key-value pair ( k i , v i ) (k_i, v_i) (ki,vi), where the key k i k_i ki is the vector representation of the context f ( c i ) f (c_i) f(ci) and the value v i v_i vi is the target word w i w_i wi
Inference: Interpolate the nearest neighbor distribution p k N N p_{kNN} pkNN with the model distribution p L M p_{LM} pLM using a tuned parameter λ \lambda λ to produce the final k N N − L M kNN-LM kNN−LM distribution(input context x x x)

-
p L M ( y ∣ x ) p_{LM}(y|x) pLM(y∣x): given the input context x x x the model generates the output distribution over next words p L M ( y ∣ x ) p_{LM}(y|x) pLM(y∣x)
-
p k N N ( y ∣ x ) p_{kNN}(y|x) pkNN(y∣x): a distribution over k-nearest neighbors
- compute the probability of each target based on the softmax of the negative distance d ( q , k i ) d(q,k_i) d(q,ki)
- aggregating probability mass for each vocabulary item across all its occurrences in the retrieved targets

Results
Performance on WIKITEXT-03

-
performance on
BOOKS
Can retrieving nearest neighbors from data be a substitute for training on it?

- Training on
WIKI-100Mand retrieving fromWIKI-100Bis better that training onWIKI-3B - rather than training language models on ever larger datasets, we can use smaller datasets to learn representations and augment them with
kNN-LMover a large corpus.
How the amount of data used for kNN retrieval affects performance?

Domain Adaption

- training on
WIKI-3Band preforming onBOOKS
Tuning Nearest Neighbor Search
Key function

Number of neighbors per query(Figure 4) and interpolation parameter(Figure 5)

Analysis


- examples where
kNN-LMis most helpful typically contain rare patterns - necessary to use neural representation rather than n-gram based method
- can LMs remember the training dataset to replace using explicit memory?
- LMs have the ability to remember all the training data(Figure 8) but are not good at generalization
REALM
Insights
预训练语言模型的缺点
- 很难确定在网络中存储哪些知识以及在哪里
- 存储知识的空间受网络大小限制
之前工作的局限
- prior works have demonstrated the benefit of adding a discrete retrieval step to neural networks, but did not apply the framework to language model pre-training and employed non-learned retrievers to handle large-scale document collections
- inspired by the framework
retrieve relevant documents and extract an answer from the docsand extends it to language model pre-training
本文提出REALM,一个retrieve-then-predict方法
- 以更可解释,更模块化的方式捕捉知识
- key: train the retriever using a performance-based signal from unsupervised text

Methods compared with:
- extremely large models that store knowledge implicitly(eg. T5)
- approaches that also use a knowledge retriever to access external knowledge, but implement retrieval in a more heuristic fashion
Method
For both pre-training and fine-tuning, REALM takes some input x and learns a distribution p(y | x) over possible outputs y.
-
pre-training: masked language modeling
-
fine-tuning: Open-QA
-
two-stages:
-
retrieve: sample from distribution p ( z ∣ x ) p(z|x) p(z∣x)
-
predict: p ( y ∣ z , x ) p(y|z,x) p(y∣z,x)
-
overall likelihood of generating y y y

-
Knowledge Retriever

-
implement the embedding functions using BERT-style Transformers

- where

- where
Knowledge-Augmented Encoder

-
pretraining: use MLM loss

- 向量长度不固定,可以用内积吗?是不是都默认归一化了
-
Open-QA fine-tuning: assume that the answer y y y can be found as a contiguous sequence of tokens in some document z z z

-
B E R T S T A R T ( s ) BERT_{START(s)} BERTSTART(s) and B E R T E N D ( s ) BERT_{END(s)} BERTEND(s) denote the Transformer output vectors corresponding to the start and end tokens of span s, respectively
-
正确的分数大,不需要保证错误的分数小吗?
-
do not update E m b e d d o c Embed_{doc} Embeddoc for simplicity
-
Exp
Pretraining: 8 candidate documents, two choices of corpus:(1) Wikipedia (2)CC-News
Finetuning: consider top-5 candidates
Result

Ablation Study

- Exact Match: predicted answer is evaluated via exact match with any reference answer
- Zero-shot Recall@5: how often the gold answer appears in the top-5 retrievals before applying any fine-tuning.
Case Study

DPR
Insight
- Dense retrieval methods have thus never be shown to outperform TF-IDF/BM25 for open-domain QA before ORQA
- two weaknesses of ORQA
- ICT pretraining is computationally intensive and it is not completely clear that regular sentences are good surrogates of questions in the objective function
- the context encoder is not fine-tuned using pairs of questions and answers, the corresponding representations could be suboptimal.
can we train a better dense embedding model using only pairs of questions and passages (or answers), without additional pretraining
- focus on developing the right training scheme using a relatively small number of question and passage pairs(only finetuning)
Propose DPR, a two-stage framework:
- a context retriever
- a machine reader
Method
Encoders: two independent BERT
Training:
-
goal: create a vector space such that relevant pairs of questions and passages will have smaller distance
- In-batch negatives

Experiments
source documents: Wikipedia dump from Dec. 20, 2018(100 words as passages, title + passage)
QA datasets: Natural Question; TriviaQA; WebQuestion; CuratedTREC; SQuAD v1.1
- large:
NQ, TriviaQA, SQuAD - small:
TREC, WQ
Results
Retrieval
**
**
End-to-end QA
Besides the retriever, our QA system consists of a neural reader extracts an answer span from the passages
- using
BERTto predict thestart_tokenand theend_token

- higher retriever accuracy typically leads to better final QA results
RAG
Insight
1.预训练模型存储知识的能力很强,但访问和精准操控知识的能力还受限,所以在knowledge-intensive任务上不如task-specific架构。
- cannot easily expand or revise their memory
- can’t straightforwardly provide insight into their predictions
- may produce “hallucinations”
2.parametric memory with non-parametric (i.e., retrieval-based) memories结合可以解决一些问题
- 知识可以直接修改和扩展,可以检查和解释访问的知识
3.REALM 和 ORQA 利用了这种形式(基于masked language model),但是只探索了 open-domain extractive question answering
因此,本文将这种方式扩展到NLP的主力seq2seq models上
- parametric memory: 预训练的seq2seq transformer
- non-parametric memory: Wikipedia的dense vector index(通过预训练的检索器获取. i.e. DPR)
- 提出两种形式
RAG-Sequence和RAG-Token

RAG-Sequence Model
uses the same retrieved document to generate the complete sequence.

- 检索到的 top-k 中的文档,每个都对生成起一定的作用
- 每个文档都对整个sequence起作用
RAG-Token Model
use a different latent document for each target token.
- 一个输出(sequence)中的每个token可以利用不同的document z z z

Retriever: DPR
We use a pre-trained bi-encoder from DPR to initialize our retriever and to build the document index
- We refer to the document index as the non-parametric memory
Generator: BART
use BART-large and simply concatenate the input
x
x
x and the retrieved content
z
z
z
Training
jointly train the retriever and generator components without any direct supervision on what document should be retrieved.
- Use a fine-tuning training corpus of input/output pairs ( x i , y i ) (x_i, y_i) (xi,yi)
- keep the document encoder(costly and not necessary) fixed, only fine-tuning the query encoder and the generator
Decoding
-
RAG-Token:按beam生成,每个token的概率都知道
-
RAG-Sequence: 对每个文档都生成一个输出 y y y,构成集合 Y Y Y。有些文档生成的 y y y, 另一些文档未必能生成。我们对所有的文档都算一下这样的 y y y 的概率,然后一个 y y y 的概率就能写成 ∑ z ∈ t o p − k p ( z ∣ x ) p ( y ∣ x , z ) \sum_{z\in top-k}p(z|x)p(y|x,z) ∑z∈top−kp(z∣x)p(y∣x,z)。 这叫做Thorough Decoding- 但是这样当生成sequence长了之后,
Y
Y
Y 会很大,要算很多遍。为了效率,将
p
(
y
∣
x
,
z
i
)
p(y|x,z_i)
p(y∣x,zi) 置为0,如果通过
x
,
z
i
x,z_i
x,zi 没有生成
y
y
y,这个叫做
Fast Decoding
- 但是这样当生成sequence长了之后,
Y
Y
Y 会很大,要算很多遍。为了效率,将
p
(
y
∣
x
,
z
i
)
p(y|x,z_i)
p(y∣x,zi) 置为0,如果通过
x
,
z
i
x,z_i
x,zi 没有生成
y
y
y,这个叫做
在四种knowledge-intensive任务上测试RAG。
- 所有实验都用 Wikipedia 作为检索的知识源
- 每个文档都被拆分成100个词的块
- top-k,k是5或10
open-domain QA


-
Abstractive Question Answering(MSMARCO)
- RAG好于BART,接近最优模型
- 最优模型利用了gold passages
- RAG好于BART,接近最优模型
-
Jeopardy QG(Jeopardy)
- why RAG-Token performs the best
- combine content from several documents
- the non-parametric component helps to guide the generation, drawing out specific knowledge stored in the parametric memory.(after the first token of each book is generated, the document posterior flattens)

- why RAG-Token performs the best
-
Fact Verification(FVR3, FVR2)
- 对FVR3(3分类),RAG差的不多,且SOTA方法需要很多设计,训练
- 对FVR2(2分类),RAG差的不多,SOTA方法会利用gold evidence

FID
Insights
之前方法的缺陷:
- Retrieval based approaches were previously considered in the context of open domain question answering with extractive models(including
DPRandREALM)- Aggregating and combining evidence from multiple passages is not straightforward when using extractive models
Propose retrieval + generation.
Method

two steps:
- retrieval:
- BM25/DPR
- reading:
- each question+passage is processed independently from other passages by the encoder
- the decoder performs attention over the concatenation of the resulting representations of all the retrieved passages
- processing passages independently in the encoder, but jointly in the decoder
- implement cross-attention over the concatenation of the resulting representations of all the retrieved passages(personal thinking).
- 但是我看了代码,在生成的时候是将所有passage拼接起来输入到模型的,感觉很诧异
- 更新:没错,就是通过cross-attention。作者更新了encoder的处理部分,将每个passage单独处理完后,组织成一个大序列,给decoder看。这种方式能够一定程度克服输入长度限制,可以借鉴,但是个人认为只适合encoder-decoder架构,且cross-attention计算量会线性增大(没有self-attention上的增加)
- 但是我看了代码,在生成的时候是将所有passage拼接起来输入到模型的,感觉很诧异
- model: T5
Results

- generative models seem to perform well when evidence from multiple passages need to be aggregated, compared to extractive approaches


- training with different numbers of passages, while testing with 100 passages.
COG
Insight
Reformulate text generation by copying text segments from existing text collections
- the next-token predictions in traditional neural language models are replaced by a series of copy-and-paste operations.
改进:动态学习phrase table,对里面的内容进行增删改查,或者将fixed phrase转成dynamic phrase
Method

At each time step, a suitable phrase is selected and appended to the current prefix accordingly
-
For a document D i D^i Di, a phrase k = D s : e i k = D^i_{s:e} k=Ds:ei of length e − s + 1 can be extracted, where s s s and e e e mark the start and end positions of the phrase in the document, respectively.
-
denote all the phrases in the source text collection as P \mathcal{P} P–> { ( k , p k ) ∣ k ∈ P } \{(k,p_k)|k \in \mathcal{P}\} {(k,pk)∣k∈P}
-
p k = P h r a s e E n c o d e r ( s , e , D i ) p_k = PhraseEncoder(s, e, D^i) pk=PhraseEncoder(s,e,Di)
-
fitness score:

- q i q_i qi is the representation of the prefix x < i x_{<i} x<i
-
-
to support the scenarios where no suitable phrases are available, we also add the context-independent token embeddings ( w , v w ) ∣ w ∈ V {(w, v_w)|w ∈ V } (w,vw)∣w∈V in standard LMs to the phrase table
The model consists of three major components:
-
a prefix encoder that maps prefixes to fixed-sized representations
- use the standard Transformer architecture with causal attention(GPT-2)
- use the hidden state of the last token as the prefix representation q i q_i qi
-
a context-dependent phrase encoder that computes the vector representations of the phrases in the source text collection
-
For a document D = D 1 , . . . , D m D = D_1, . . . , D_m D=D1,...,Dm of length m:
-
first apply a deep bidirectional Transformer(BERT-base-cased) to obtain contextualized token representations D m × d t D^{m \times d_t} Dm×dt
-
apply two MLPs models, M L P s t a r t MLP_{start} MLPstart and M L P e n d MLP_{end} MLPend, to convert D D D into start and end token representations respectively:

-
for each phrase D s : e D_{s:e} Ds:e, use the concatenation of the corresponding start and end vectors as the phrase representation

-
-
-
a set of context-independent token embeddings similar to the one used in standard neural language models
- to retain the generalization capability to compose output with standalone tokens
- add the traditional context-independent token embeddings V ∈ R ∣ V ∣ × d V ∈ R^{|V| \times d} V∈R∣V∣×d to our phrase table.
- useful when there is no suitable phrase in the source text collection
为什么用GPT-2生成的表示,与BERT生成的表示算匹配,二者在一个表达空间内吗?
Training
a document D has been split into n phrases D = p 1 , . . . , p n D = p_1, . . . , p_n D=p1,...,pn
-
the training loss for next-phrase predictions(next-phrase prediction)

- P k \mathcal{P_k} Pk consists of all the phrases in the source document D k D^k Dk
-
to retain the capability of token-level generation, we also train COG with the standard token-level autoregressive loss(next-token prediction)

The training loss is the sum of these two losses.
Results
Standard language modeling

Inference Speed

- the encoding time cost is not included
- achieves comparable inference efficiency with the standard Transformer baseline
- the inference latency of
kNN-LMis much higher than Transformer, andCOG
- the inference latency of
Case Study

Domain adaption

COGallows a single model to be specialized in different domains, by simply switching the source text collection
Enlarged phrase index

Idea
Levenshtein Transformer: 这个模型在生成时,可以对生成的结果进行增删改(NeurIPS 2019)

GenRead
Insights
ICLR 2023: 8 8 8 10
Three drawbacks of retrieve-then-read pipeline
- candidate documents for retrieval are chunked (e.g., 100 words) and fixed, so the retrieved documents might contain noisy information that is irrelevant to the question
- 可以按语义截断,按语义分块
- the representations of questions and documents are typically obtained independently in modern two-tower dense retrieval models, leading to only shallow interactions captured between them
- 可以深层交互,比如question编码完,在编码doc的时候,每一层都看到question的编码,最后算分
- 有必要深层交互吗?浅层与深层的影响是什么?
- document retrieval over a large corpus requires the retriever model to first encode all candidate documents and store representations for each document
- 但是用大模型,不用检索,一样会受限于模型大小,因为知识量与参数量有关,且更难解释
- 生成式检索能否用来解决这个问题?
Propose to leverage LLMs to directly generate contextual documents for a given question,two advantages
-
generated contextual documents contain the correct answer more often than the top retrieved documents
- large language models generate contextual documents by performing deep token-level cross-attention between all the question and document contents
-
our approach significantly outperforms directly generating answers from large language models despite not incorporating any new external information
-
mainly because the task of generating document-level contexts is close to the objective of causal language modeling pre-training, so the world knowledge stored in the model parameters can be better utilized
-
生成文档的真实性能保证吗?逻辑能保证吗?会加剧幻象吗?(会出现幻象)

-
Method
Two steps:
-
first prompts a LLM to generate contextual documents with respect to a given query
-
reads the generated documents to predict the final answer(a large model like
InstructGPTfor zero-shot or a smaller model likeFIDfor finetuning)
Zero setting:
- first prompt a large language model (
InstructGPT) to generate documents based on the given question with greedy decoding strategy - use generated sentence along with the input question to produce the final answer from the large language model
Supervised setting:
Explore how the generated documents from large language models can benefit the supervised setting.
- leverage a small reader model such as
FiDto peruse the generated documents under the supervised setting(finetune the reader) - scaling the size of retrieved documents can lead to better performance(for retrieval model)
- But it is hard to generate diverse documents
Clustering-based prompts:

- step1: get one initial document per question
- now have a question-document pair set { q i , d i } i = 1 ∣ Q ∣ \{q_i,d_i\}_{i=1}^{|Q|} {qi,di}i=1∣Q∣( Q Q Q is the set of questions in the training split)
- step2: encode each question-document pair, do k-means clustering
- step3: sample and generate k documents
- sample n(hyperparameter = 5) question-document pairs from each cluster c, denoted as
{
q
c
1
,
d
c
1
;
q
c
2
,
d
c
2
;
.
.
.
;
q
c
n
,
d
c
n
}
\{qc1, dc1; qc2, dc2; ...; qcn, dcn\}
{qc1,dc1;qc2,dc2;...;qcn,dcn}
- 一个cluster能代表一种 q 与 d 之间的关系吗?
- input: { q c 1 } { d c 1 } . . . { q c n } { d c n } { i n p u t q u e s t i o n } \{qc1\} \{dc1\} ... \{qcn\} \{dcn\} \{input question\} {qc1}{dc1}...{qcn}{dcn}{inputquestion}
- output: a document
- K clusters -> K generated documents
- 这样好吗?使用的 <q,d> pairs 都是question-independent,对一个question中的所有question来说都是相同的。对不同question来说,生成的document可能都是与question某个特定方面相关的,因为prompt里面<q,d>的关系是相同的
- sample n(hyperparameter = 5) question-document pairs from each cluster c, denoted as
{
q
c
1
,
d
c
1
;
q
c
2
,
d
c
2
;
.
.
.
;
q
c
n
,
d
c
n
}
\{qc1, dc1; qc2, dc2; ...; qcn, dcn\}
{qc1,dc1;qc2,dc2;...;qcn,dcn}
Results
Zero-shot

Supervised setting
InstructGPT + FiD(FiD is fine-tuned on the training split of target datasets)


Other tasks

- Fact checking: there is a smaller semantic gap between the given factual statement and contextual documents
Case Study

- 揭示了检索的问题,检索回来的doc与question并不是紧密联系的,可能因为其中一些词发挥作用导致similarity比较高
- 生成一般是顺着prompt说,联系会比较紧密一些
REPLUG
前言
- 本文提出
REPLUG,一个将语言模型视为黑盒检索增强的语言模型架构。在REPLUG中,仅将检索得到的文档拼接到原有输入前面即可,不需要像以前一样更新语言模型参数。该架构中可以通过更新检索器进一步提升性能。

REPLUG

- 给一个输入上下文
- REPLUG会首先从外部资源
D
=
{
d
1
,
…
,
d
m
}
D=\{d_1,\dots,d_m\}
D={d1,…,dm}中检索出一些相关文档
- 使用基于双塔encoder(共享参数)的dense retrieval来检索文档,一个encoder用来编码输入 x x x和文档 d d d
- 文档与输入的embedding都是对其中每个token最后一个隐藏层表达的平均值
- 通过cos similarity计算 x x x与 d d d的相关性: s ( d , x ) = c o s ( E ( d ) , E ( x ) ) s(d,x) = cos(E(d),E(x)) s(d,x)=cos(E(d),E(x))
- 预先计算文档的embedding,并利用
FAISS来快速找到top-k文档
- 之后我们将每个检索到的文档与输入上下文进行拼接,并行输入到大模型中
- 由于模型输入限制,无法将所有检索文档与输入 x x x进行拼接
- 采用聚合策略,拼接时,将每个top-k文档分别拼接在 x x x前面,并将拼接结果分别输入到语言模型中。
- 最后聚合每个并行输入得到的预测概率
- 对上面分别计算的结果进行聚合
- 给定上下文输入
x
x
x 和 top-k 相关文档集合
D
′
D^{'}
D′,下一个token
y
y
y 的生成概率由加权平均决定
-
p
(
y
∣
x
,
D
′
)
=
∑
d
∈
D
′
p
(
y
∣
d
∘
x
)
⋅
λ
(
d
,
x
)
p(y|x,D^{'}) = \sum_{d \in D^{'}}p(y|d \circ x) \cdot \lambda(d,x)
p(y∣x,D′)=∑d∈D′p(y∣d∘x)⋅λ(d,x)
- 其中
λ
(
d
,
x
)
\lambda(d,x)
λ(d,x)是
d
d
d 与
x
x
x 相似度
s
(
d
,
x
)
s(d,x)
s(d,x) 进行
softmax的结果
- 其中
λ
(
d
,
x
)
\lambda(d,x)
λ(d,x)是
d
d
d 与
x
x
x 相似度
s
(
d
,
x
)
s(d,x)
s(d,x) 进行
-
p
(
y
∣
x
,
D
′
)
=
∑
d
∈
D
′
p
(
y
∣
d
∘
x
)
⋅
λ
(
d
,
x
)
p(y|x,D^{'}) = \sum_{d \in D^{'}}p(y|d \circ x) \cdot \lambda(d,x)
p(y∣x,D′)=∑d∈D′p(y∣d∘x)⋅λ(d,x)
- 给定上下文输入
x
x
x 和 top-k 相关文档集合
D
′
D^{'}
D′,下一个token
y
y
y 的生成概率由加权平均决定
- 对上面分别计算的结果进行聚合
REPLUG LSR: Training the Dense Retriever

REPLUG LSR 可以看做 REPLUG的一个增强版本。在REPLUG中,我们使用的检索器可能不够适配语言模型,因此这里利用语言模型本身反馈的监督信号,来调整REPLUG中的检索器。
- 这里的监督信号可以告诉我们,什么样的文档应该被检索回来
核心思想:our approach can be seen as adjusting the probabilities of the retrieved documents to match the probabilities of the output sequence perplexities of the language model
- 其实就是匹配检索文档的概率与语言模型输出序列的概率
- 输出序列的概率就是语言模型提供的监督信号
- 这样做的理由
- 如果模型输出的
ground truth序列的概率更大,那么我们认为模型的效果越好 - 我们认为,如果一个文档对模型的输出更有帮助,那么我们就认为这个文档更应该被检索回来,其检索的概率也应该更大。
- 所以说,一个文档被检索回来的概率应该与使用这个文档得到输出序列的概率是正相关的,因此我们想要匹配检索文档的概率与语言模型输出序列的概率
- 如果模型输出的
这部分介绍如何计算检索文档概率分布与输出序列概率分布
Computing Retrieval Likelihood
给定输入 x x x,我们检索回来概率最大的top-k个文档,为 D ′ ⊂ D D^{'} \subset D D′⊂D,文档 d d d的检索概率(likelihood)为
P R ( d ∣ x ) = e s ( d , x ) / γ ∑ d ∈ D ′ e s ( d , x ) / γ P_R(d \mid x)=\frac{e^{s(d, x) / \gamma}}{\sum_{d \in \mathcal{D}^{\prime}} e^{s(d, x) / \gamma}} PR(d∣x)=∑d∈D′es(d,x)/γes(d,x)/γ
-
γ \gamma γ是用来控制
softmax温度的超参 -
按理应该在整个 D D D 上进行,但是那样计算量太大,因此在 D ′ D^{'} D′ 上近似计算
Computing LM likelihood
将语言模型用来评估每个文档对语言模型困惑度的提升程度,首先计算
P
L
M
(
y
∣
d
,
x
)
P_{LM}(y|d,x)
PLM(y∣d,x),这是给定
x
x
x 和文档
d
d
d 时,ground truth
y
y
y 的生成概率。如果这个概率越大,则说明当前文档对困惑度的提升程度越大。然后计算分布:
Q ( d ∣ x , y ) = e P L M ( y ∣ d , x ) / β ∑ d ∈ D ′ e P L M ( y ∣ d , x ) / β Q(d \mid x, y)=\frac{e^{P_{L M}(y \mid d, x) / \beta}}{\sum_{d \in \mathcal{D}^{\prime}} e^{P_{L M}(y \mid d, x) / \beta}} Q(d∣x,y)=∑d∈D′ePLM(y∣d,x)/βePLM(y∣d,x)/β
- β \beta β是超参
有了两个分布之后,用loss function 对二者进行匹配
在给定 x x x 和 y y y 时,计算检索概率分布和语言模型概率分布,我们利用KL divergence来匹配两个分布,并用来优化dense retriever
L = 1 ∣ B ∣ ∑ x ∈ B K L ( P R ( d ∣ x ) ∥ Q L M ( d ∣ x , y ) ) \mathcal{L}=\frac{1}{|\mathcal{B}|} \sum_{x \in \mathcal{B}} K L\left(P_R(d \mid x) \| Q_{\mathrm{LM}}(d \mid x, y)\right) L=∣B∣1∑x∈BKL(PR(d∣x)∥QLM(d∣x,y))
- B B B 是输入 x x x 的集合
- 我们最小化损失函数来优化检索器,LM保持不动
因为检索器参数在训练过程中更新,参数更新后document embedding会变化,因此每隔 T T T步就重新算一次document embedding,并重复上述过程
Training Setup
Model
- LM: GPT-3(for REPLUG LSR)
- Retriever:Contriver(2022新模型)
Training data
-
所有训练数据都来自
Pile training data(包含不同领域文本的language model benchmark) -
800K 个 256 token长的序列作为训练queries
- 每个query分成两部分,前128token作为 input context x x x,后一半作为需要续写的ground truth y y y
-
外部语料库 D D D, 采样36M 128 token长的文档
Results
Language Modeling

- randomly subsampled
Pile training data(367M documents of 128 tokens) and use them as the retrieval corpus for all models
MMLU

Atlastrains both the retriever and the language model, which we consider a white-box retrieval LM setting.- 对于检索增强的版本,我们将test question作为query,从Wikipedia中检索10个文档,与question拼接成10个输入,最后的结果是10个输出的聚合
Open Domain QA

-
dataset:
Natural QuestionandTriviaQA- For evaluation, we consider the
few-shot(use a few training data) andfull data(use all training data)
- For evaluation, we consider the
-
RETRO,R2-D2,Atlasare finetuned on the training data, either in a few-shot setting or with full training data
Analysis

- 性能的提升不止源于聚合不同的输出结果,聚合相关的文档是成功的关键
- 随着聚合文档数目的提升,
REPLUG和REPLUG LSR的性能单点提升,不过 a small number of documents(e.g., 10)就可以做的不错

REPLUG带来的性能增益与模型大小保持一致, 且能够应用到不同模型上

REPLUGis more helpful when texts contain rare entities
it is unclear when the model relies on retrieved knowledge or parametric knowledge
When not to trust language models
Insight
- LMs have been shown to have limited memorization for less frequent entities, are prone to hallucinations, and suffer from temporal degradation
- it is unclear whether it(incorporating non-parametric knowledge) is strictly superior or complementary to parametric knowledge
target: understand when we should and should not rely on LMs’ parametric knowledge, and how scaling and non-parametric memories can help
Evaluation Setup

- focus: factual knowledge
- task format: open-domain QA
Dimensions of Analysis:
- Previous research often uses the term frequency of object entities in pretraining corpora to understand memorization
- focus on the other two variables in a factual knowledge triple: the subject entity and the relationship type.
- subject entity: use the popularity of the entities measured by Wikipedia monthly page views
- relationship type:
Dataset:
PopQA: randomly sample knowledge triples of 16 relationship types from Wikidata
EntityQuestions: use Wikipedia hyperlink counts as a proxy of the frequency of entities and sample knowledge triples from WikiData, from the frequency distributions
Res
without retrieval

- there is a positive correlation between subject entity popularity and models’ accuracy for almost all relationship types
- factual knowledge of some relationship types are more easily memorized than others

- Scaling may not help with tail knowledge
with retrieval
run an off-the-shelf retrieval system off-line to retrieve context from Wikipedia relevant to a question and concatenate the retrieved context(top one for simplicity) with the original question
- use
BM25/Contriever

- Retrieval largely improves performance

- Non-parametric memories are effective for less popular facts

- Non-parametric memories can mislead LMs
Adaptive retrieval
we use retrieval for questions whose popularity is lower than a threshold
- determine the popularity threshold independently for each relationship type.(maximize the adaptive accuracy on a development set)


Summary
-
LMs’ memorization (RQ1) is often limited to the popular factual knowledge and even
GPT-3 davinci-003fails to answer the majority of the long-tail questions- scaling up models does not significantly improve the performance for long-tail questions
-
Non-parametric memories largely improve performance on long-tail distributions across models.
- retrieval augmentation can hurt the performance of large LMs on questions about popular entities as the retrieved context can be misleading
-
Devise a simple-yet-effective retrieval-augmented LM method,
Adaptive Retrieval, which adaptively combines parametric and non-parametric memories based on popularity