Arravlist底层是内存空间连续的数组,可以根据下标进行随机访问,效率比较高,因为在根据下标访问某一个元素时,并不是一个一个去查,而是算出来这个下标的地址,直接根据这个地址的指向去获取的,因为数组是一个连续的内存空间,在创建时指定了类型和长度,知道每一个元素的类型也就知道每个元素长度,然后算出访问的这个元素的地址值(比如创建一个int类型数组长度10,因为int占4字节,获取第5个元素时,4x5=20,就直接通过下标找到第五个元素的地址值)
但是一旦需要增删的话,如果增加元素后长度大于现有长度,就要重新创建一个ArrayList,再把原数组里面的数据拷贝过来,再添加新元素。
而LinkedList底层是内存空间不连续的链表,是游离在内存空间中的一个个节点,每个节点有头结点和尾结点的地址信息以此来依次关联,虽然增删时只需要断链再重新接链,不影响其他节点,总体效率高,但是访问时需要一个一个进行遍历来确定是不是所需要的元素。一般使用场景是对首位元素操作频繁的场景,使用到的方法有 addFirst()和addLast() / offerFirst()和 offerLast() / offer()
getFirst() / peek() / element() / peekFirst() 和 getLast() / peekLast
removeFirst()和removeLast()
演示:
LinkedList虽然也有下标,但它经常做的是首尾相关的操作,所以他的专属方法有非常明显的特点:如 addFirst()和addLast() / offerFirst()和 offerLast() / offer()
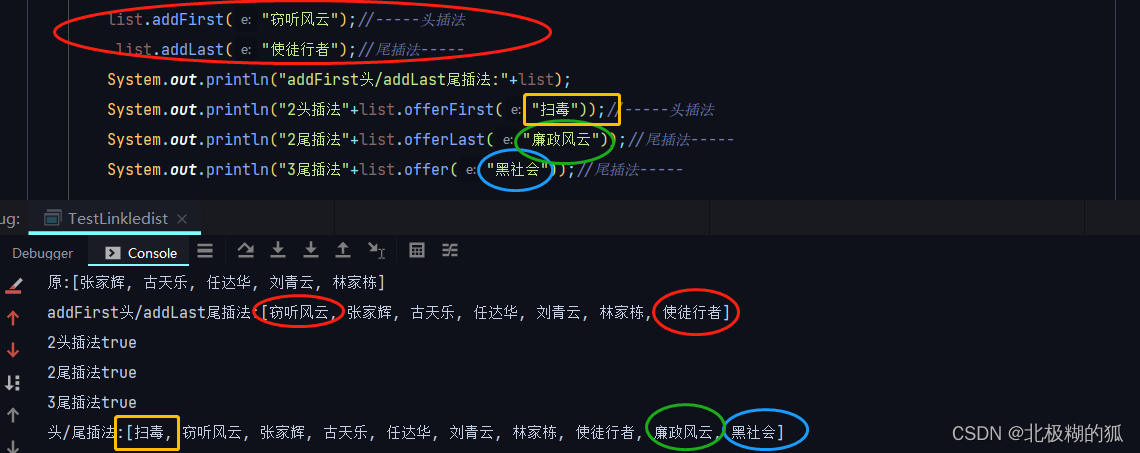
getFirst() / peek() / element() / peekFirst() 和 getLast() / peekLast
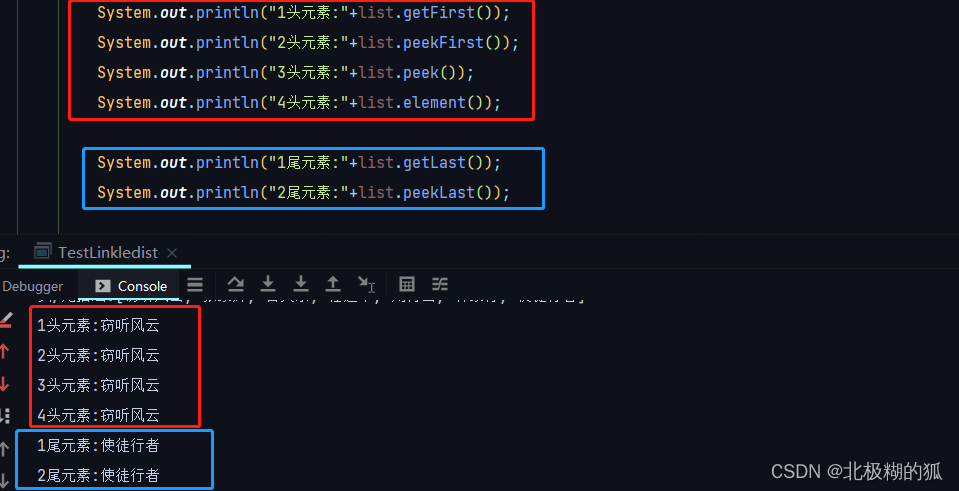
removeFirst()和removeLast() pollFirst() 和 pollLast() / poll()
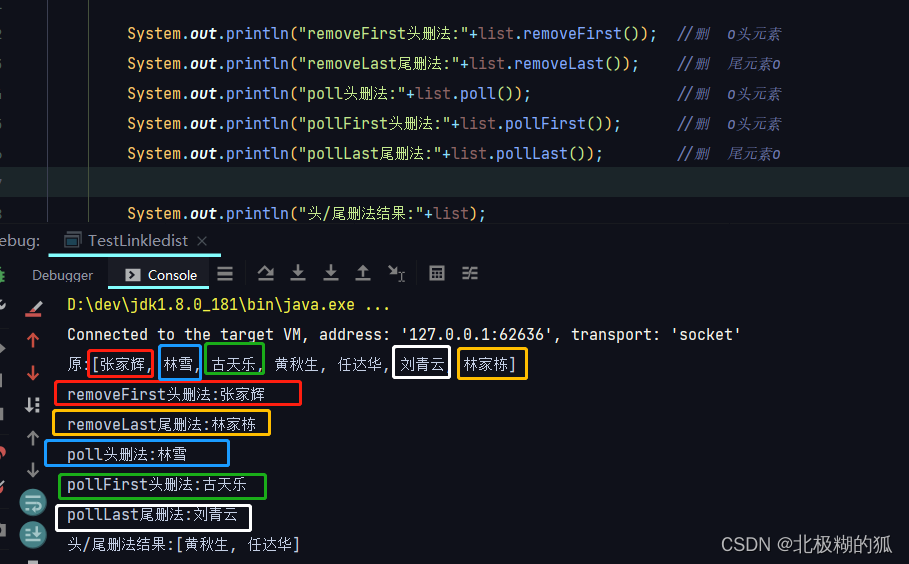
查询
注意点:Arravlist 和 LinkedList 都是List的实现类,所以其元素都是有下标的,都可以根据元素下标访问及各种操作,只不过LinkedList 常用的是首尾操作而已
性能优化:
一般来说,在数据量非常大的情况下:
Arravlist 增删效率慢,查询操作比较快,
LinkedList 增删效率高,查询操作比较慢,
但是如果可以熟练使用ArrayList,效率并不会比在创LinkedList低,这里可以从两个方面进行优化:
1、在数据长度不是特别大并且长度基本能控制的情况下,创建ArrayList时就可以预估好需要的长度,使用那个可以定义初始长度的构造方法,创建ArrayList,并且长度不能太大,不然创建时多长就会占用多大的内存,这样后期可以尽可大能的避免频繁的扩容。
2,在添加元素的时候使用尾插法而不是插入到数组中间。
如果这样合理的使用ArrayList,甚至可以让ArravList的增删效率超过LinkedList,因为LinkedList每次创建或删除链表都会对应的新建或销毁链表对象,大量的数据增删相对于正确使用的ArrayList还是比较消耗内存,浪费时间的




![[C++ 网络协议] 多播与广播](https://img-blog.csdnimg.cn/78273144c82d4bacb97429bc68c2b0d4.png)