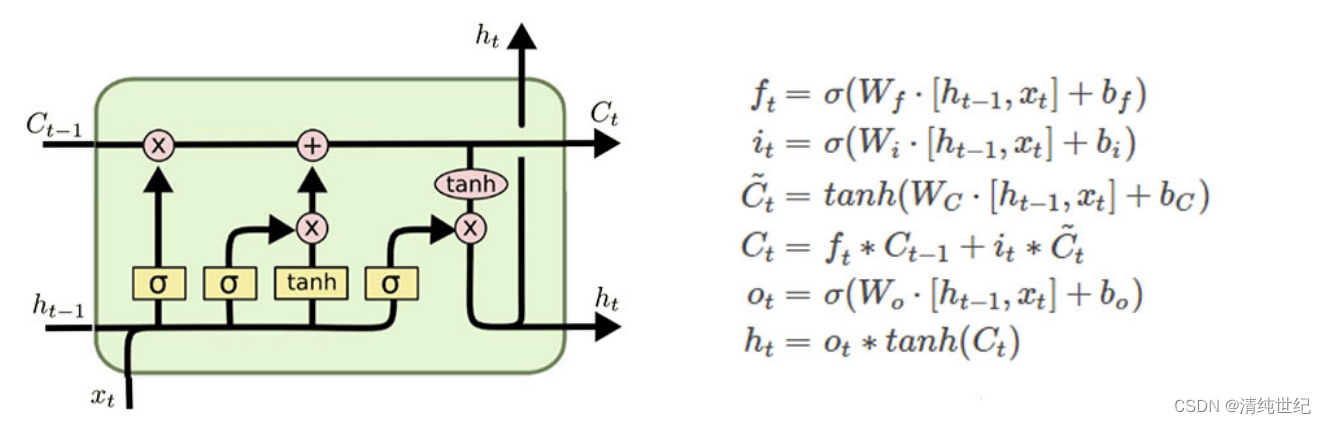
一、LSTM模型
import torch
from torch import nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
torch.manual_seed(1)
# Hyper Parameters
EPOCH = 1 # 训练整批数据多少次, 为了节约时间, 我们只训练一次
BATCH_SIZE = 64
TIME_STEP = 28 # rnn 时间步数 / 图片高度
INPUT_SIZE = 28 # rnn 每步输入值 / 图片每行像素
LR = 0.01 # learning rate
DOWNLOAD_MNIST = True # 如果你已经下载好了mnist数据就写上 Fasle
# Mnist 手写数字
train_data = dsets.MNIST(
root='./mnist/', # 保存或者提取位置
train=True, # this is training data
transform=transforms.ToTensor(), # 转换 PIL.Image or numpy.ndarray 成
# torch.FloatTensor (C x H x W), 训练的时候 normalize 成 [0.0, 1.0] 区间
download=DOWNLOAD_MNIST, # 没下载就下载, 下载了就不用再下了
)
# plot one example
# print(train_data.train_data.size()) # (60000, 28, 28)
# print(train_data.train_labels.size()) # (60000)
# plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# plt.title('%i' % train_data.train_labels[0])
# plt.show()
# 批训练 50samples, 1 channel, 28x28 (50, 1, 28, 28)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# 为了节约时间, 我们测试时只测试前2000个
test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())
test_x = test_data.test_data.type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)
test_y = test_data.test_labels.numpy()[:2000] # covert to numpy array
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM( # LSTM 效果要比 nn.RNN() 好多了
input_size=28, # 图片每行的数据像素点
hidden_size=64, # rnn hidden unit
num_layers=1, # 有几层 RNN layers
batch_first=True, # input & output 会是以 batch size 为第一维度的特征集 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(64, 10) # 输出层
def forward(self, x):
# 输入的input为,(batch, time_step, input_size)
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size) LSTM 有两个 hidden states, h_n 是分线, h_c 是主线
# h_c shape (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
# 选取最后一个时间点的 r_out 输出
# 这里 r_out[:, -1, :] 的值也是 h_n 的值
out = self.out(r_out[:, -1, :])
return out
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data
b_x = b_x.view(-1, 28, 28) # reshape x to (batch, time_step, input_size)
output = rnn(b_x) # rnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output = rnn(test_x) # (samples, time_step, input_size)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
# print 10 predictions from test data
test_output = rnn(test_x[:10].view(-1, 28, 28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')上述中,我们对于h_n, h_c全部以0为输入,此时我们也可以修改为随机参数:
import torch
from torch import nn
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM( # LSTM 效果要比 nn.RNN() 好多了
input_size=28, # 图片每行的数据像素点
hidden_size=64, # rnn hidden unit
num_layers=1, # 有几层 RNN layers
batch_first=True, # input & output 会是以 batch size 为第一维度的特征集 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(64, 10) # 输出层
def forward(self, x):
# 输入的input为,(batch, time_step, input_size)
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size) LSTM 有两个 hidden states, h_n 是分线, h_c 是主线
# h_c shape (n_layers, batch, hidden_size)
# 初始化的隐藏元和记忆元,通常它们的维度是一样的
# 1个LSTM层,batch_size=x.shape[0], 隐藏层的特征维度64
h_0 = torch.randn(1, x.shape[0], 64)
c_0 = torch.randn(1, x.shape[0], 64)
r_out, (h_n, h_c) = self.rnn(x, (h_0, c_0)) # None 表示 hidden state 会用全0的 state
# 选取最后一个时间点的 r_out 输出
# 这里 r_out[:, -1, :] 的值也是 h_n 的值
out = self.out(r_out[:, -1, :])
return out
rnn = RNN()
print(rnn)参数:
class torch.nn.LSTM(*args, **kwargs)
参数有:
input_size:x的特征维度
hidden_size:隐藏层的特征维度
num_layers:lstm隐层的层数,默认为1
bias:False则bihbih=0和bhhbhh=0. 默认为True
batch_first:True则输入输出的数据格式为 (batch, seq, feature)
dropout:除最后一层,每一层的输出都进行dropout,默认为: 0
bidirectional:True则为双向lstm默认为FalseLSTM的另外两个输入是 h0 和 c0,可以理解成网络的初始化参数,用随机数生成即可。
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
参数:
num_layers:隐藏层数
num_directions:如果是单向循环网络,则num_directions=1,双向则num_directions=2
batch:输入数据的batch
hidden_size:隐藏层神经元个数注意,如果我们定义的input格式是:
input(batch, seq_len, input_size)
则H和C的格式也是要变的:
h0(batch, num_layers * num_directions, hidden_size)
c0(batch, num_layers * num_directions, hidden_size)LSTM的输出是一个tuple,如下:
output,(ht, ct) = net(input)
output: 最后一个状态的隐藏层的神经元输出
ht:最后一个状态的隐含层的状态值
ct:最后一个状态的隐含层的遗忘门值output的默认维度是:
output(seq_len, batch, hidden_size * num_directions)
ht(num_layers * num_directions, batch, hidden_size)
ct(num_layers * num_directions, batch, hidden_size)和input的情况类似,如果我们前面定义的input格式是:
input(batch, seq_len, input_size)
则ht和ct的格式也是要变的:
ht(batc,num_layers * num_directions, h, hidden_size)
ct(batc,num_layers * num_directions, h, hidden_size)我们使用线性函数进行构建LSTM:
import torch
import torch.nn as nn
class LSTM_v1(nn.Module):
def __init__(self, input_sz, hidden_sz):
super().__init__()
self.input_size = input_sz
self.hidden_size = hidden_sz
# 遗忘门
self.f_gate = nn.Linear(self.input_size+self.hidden_size, self.hidden_size)
# 输入门
self.i_gate = nn.Linear(self.input_size+self.hidden_size, self.hidden_size)
# 细胞cell
self.c_cell = nn.Linear(self.input_size+self.hidden_size, self.hidden_size)
# 输出门
self.o_gate = nn.Linear(self.input_size+self.hidden_size, self.hidden_size)
self.init_weights()
def init_weights(self):
pass
def forward(self, x, init_states=None):
bs, seq_sz, _ = x.size()
hidden_seq = []
if init_states is None:
h_t, c_t = (
torch.zeros(bs, self.hidden_size).to(x.device),
torch.zeros(bs, self.hidden_size).to(x.device)
)
else:
h_t, c_t = init_states
for t in range(seq_sz):
x_t = x[:, t, :]
input_t = torch.concat([x_t, h_t], dim=-1)
f_t = torch.sigmoid(self.f_gate(input_t))
i_t = torch.sigmoid(self.i_gate(input_t))
c_t_ = torch.tanh(self.c_cell(input_t))
c_t = f_t * c_t + i_t * c_t_
o_t = torch.sigmoid(self.o_gate(input_t))
h_t = o_t * torch.tanh(c_t)
hidden_seq.append(h_t.unsqueeze(0))
hidden_seq = torch.cat(hidden_seq, dim=0)
hidden_seq = hidden_seq.transpose(0, 1).contiguous()
return hidden_seq, (h_t, c_t)二、RNN
import torch
from torch import nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
torch.manual_seed(1)
# Hyper Parameters
EPOCH = 1 # 训练整批数据多少次, 为了节约时间, 我们只训练一次
BATCH_SIZE = 64
TIME_STEP = 28 # rnn 时间步数 / 图片高度
INPUT_SIZE = 28 # rnn 每步输入值 / 图片每行像素
LR = 0.01 # learning rate
DOWNLOAD_MNIST = True # 如果你已经下载好了mnist数据就写上 Fasle
# Mnist 手写数字
train_data = dsets.MNIST(
root='./mnist/', # 保存或者提取位置
train=True, # this is training data
transform=transforms.ToTensor(), # 转换 PIL.Image or numpy.ndarray 成
# torch.FloatTensor (C x H x W), 训练的时候 normalize 成 [0.0, 1.0] 区间
download=DOWNLOAD_MNIST, # 没下载就下载, 下载了就不用再下了
)
# plot one example
# print(train_data.train_data.size()) # (60000, 28, 28)
# print(train_data.train_labels.size()) # (60000)
# plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# plt.title('%i' % train_data.train_labels[0])
# plt.show()
# 批训练 50samples, 1 channel, 28x28 (50, 1, 28, 28)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# 为了节约时间, 我们测试时只测试前2000个
test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())
test_x = test_data.test_data.type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)
test_y = test_data.test_labels.numpy()[:2000] # covert to numpy array
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=28, # 图片每行的数据像素点
hidden_size=64, # rnn hidden unit
num_layers=1, # 有几层 RNN layers
batch_first=True, # input & output 会是以 batch size 为第一维度的特征集 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(64, 10) # 输出层
def forward(self, x):
# 输入的input为,(batch, time_step, input_size)
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size) LSTM 有两个 hidden states, h_n 是分线, h_c 是主线
# h_c shape (n_layers, batch, hidden_size)
r_out, h = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
# 选取最后一个时间点的 r_out 输出
out = self.out(r_out[:, -1, :])
return out
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data
b_x = b_x.view(-1, 28, 28) # reshape x to (batch, time_step, input_size)
output = rnn(b_x) # rnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output = rnn(test_x) # (samples, time_step, input_size)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
# print 10 predictions from test data
test_output = rnn(test_x[:10].view(-1, 28, 28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')上述中,我们对于h全部以0为输入,此时我们也可以修改为随机参数:
import torch
from torch import nn
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=28, # 图片每行的数据像素点
hidden_size=64, # rnn hidden unit
num_layers=1, # 有几层 RNN layers
batch_first=True, # input & output 会是以 batch size 为第一维度的特征集 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(64, 10) # 输出层
def forward(self, x):
# 输入的input为,(batch, time_step, input_size)
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size) LSTM 有两个 hidden states, h_n 是分线, h_c 是主线
# h_c shape (n_layers, batch, hidden_size)
# 初始化的隐藏元
# 1个RNN层,batch_size=x.shape[0], 隐藏层的特征维度64
h_0 = torch.randn(1,x.shape[0], 64)
r_out, h = self.rnn(x, h_0) # None 表示 hidden state 会用全0的 state
# 选取最后一个时间点的 r_out 输出
out = self.out(r_out[:, -1, :])
return out
rnn = RNN()
print(rnn)参数:
nn.RNN是PyTorch中的一个循环神经网络模型。它有几个重要的参数:
input_size:输入的特征维度大小。
hidden_size:隐藏状态的维度大小。
num_layers:RNN层数。
nonlinearity:非线性激活函数,默认为’tanh’。
bias:是否使用偏置,默认为True。
batch_first:如果为True,则输入的维度为(batch_size, seq_length, input_size),否则为(seq_length, batch_size, input_size)。默认为False。
dropout:如果非零,则在输出之间应用丢弃以进行稀疏连接。
bidirectional:如果为True,则使用双向RNN,默认为False。