很多人私信我,说自己是0基础学习Python,但是学爬虫的时候不太理解这个原理,下面我来给大家分享一下我的对Python爬虫的原理。

首先我们要知道什么是Python爬虫?
我们可以把互联网看成是各种信息的站点及网络设备在一起组成的一张蜘蛛网,这张网中什么信息都有,而我们上网就是获取互联网中信息内容的过程。

那么什么是爬虫?爬虫就是一段模拟人们上网的程序,爬虫可以抓取互联网上的信息,Python爬虫就是用Python语言写的一段爬虫程序。
Python爬虫的结构
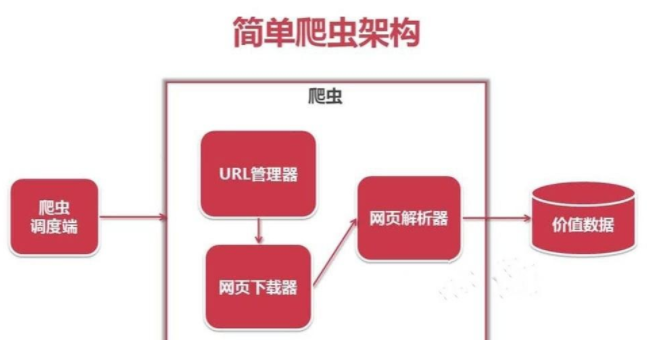
1 度器:相当于人的大脑、电脑的CPU,调度器负责调度URL管理器、下载器、解析器之间的协调工作;
2 URL管理器:爬虫抓取内容的URL地址(网址),URL包括未爬取的URL地址和已爬取的URL址,URL管理器能够防止重复抓取URL和循环抓取URL。实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现;
3 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2,urllib2是Python官方的基础模块;
4 网页解析器:用来解析网页的字符串,网页解析器可以按照我们的要求来提取出对我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式、html.parser(Python自带)、beautifulsoup(第三方插件)、lxml(第三方插件),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
5 应用程序:就是从网页中提取的有用数据组成的一个应用。

如何理解这个过程呢?
想象你自己是一只蜘蛛,现在你被放到了互联“网”上。那么,你需要把今日头条所有的网页都看一遍。怎么办呢?没问题呀,你就随便从某个地方开始,比如打开今日头条首页,你看到那个页面引向的各种链接。于是你很开心地爬到了“热点”那个页面。太好了,这样你就已经爬完了俩页面(首页和热点)!暂且不用管爬下来的页面怎么处理的,你就想象你把这个页面完完整整抄成了个html放到了你身上。突然你发现, 在热点这个页面上,有一个链接链回“首页”。作为一只聪明的蜘蛛,你肯定知道你不用爬回去的吧,因为你已经看过了啊。所以,你需要用你的脑子,存下你已经看过的页面地址。这样,每次看到一个可能需要爬的新链接,你就先查查你脑子里是不是已经去过这个页面地址。如果去过,那就别去了。
大家是不是觉得思路清晰了很多呢,如果觉得文章对自己有帮助就点赞关注小编吧,我会每天跟大家分享我的学习方法。
最后
最后多说一句,小编是一名python开发工程师,这里有我自己整理了一套最新的python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!(文末领取)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。(文末领读者福利)
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)
五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。 (文末领取哦)


这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

![[1]物联网基础知识](https://img-blog.csdnimg.cn/e59c5895ea814ed897deea4a7e5123ec.png)