目录
1、什么是增强聚合和多维分析函数?
2、grouping sets - 指定维度组合
3、with rollup - 上卷维度组合
4、with cube - 全维度组合
5、Grouping__ID、grouping() 的使用场景
6、使用 增强聚合 会不会对查询性能有提升呢?
7、对grouping sets、with cube、with rollup 的优化
1、什么是增强聚合和多维分析函数?
增强聚合指的是:
在SQL中使用分组聚合查询时,使用 grouping sets、rollup、cube 语句进行操作
在常见的数据引擎中都支持这种语法,比如hive、spark、presto、ck、flinkSQL
使用增强聚合不仅可以简化SQL代码,而且还能对SQL语句的性能有所提升
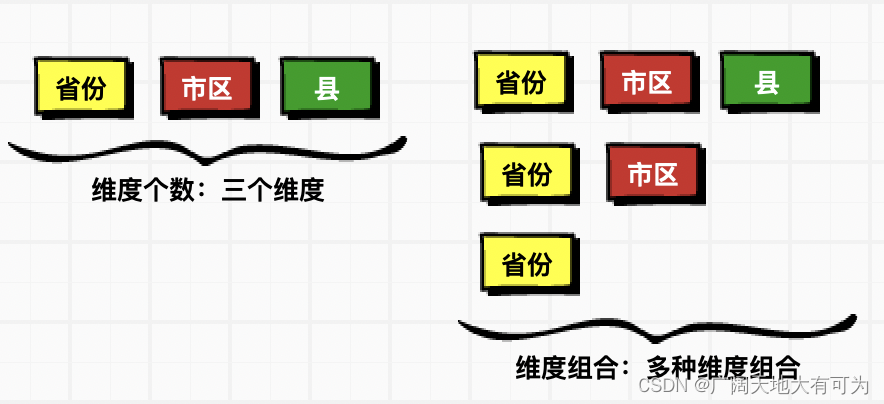
多维分析指的是:
SQL语法中的多维分析指的是 多种维度组合的分析,而不是多种维度的分析
hive官网链接:hive官网
2、grouping sets - 指定维度组合
功能说明:
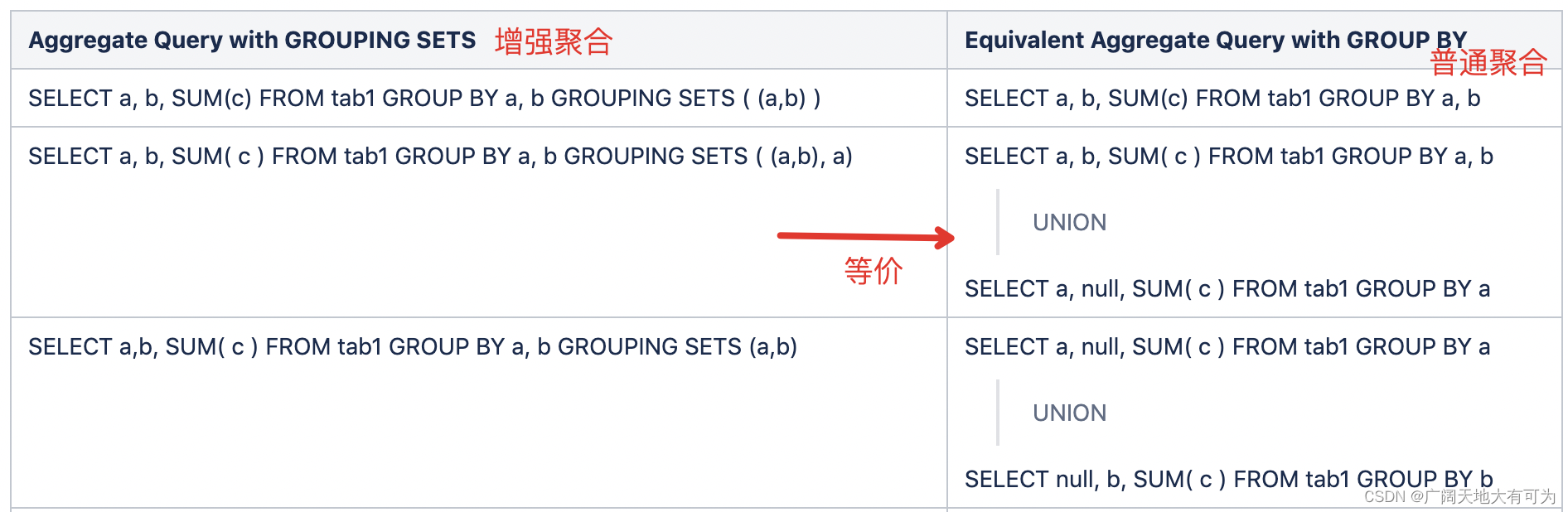
对指定的分组字段进行多种维度组合的聚合计算
hive-语法:
-- TODO 必须开区map端合并
select
维度A
,维度B
,维度C
,聚合函数(度量字段)
,grouping__id
from 表名 [where ]
group by A,B,C
grouping sets( (A),(A,B),(A,B,C),..维度组合 )
presto、FlinkSQL、SparkSQL-语法:
select
维度A
,维度B
,维度C
,聚合函数(度量字段)
,grouping(A,B,C) as grouping_id
from 表名 [where ]
group by
grouping sets( (A),(A,B),(A,B,C),..维度组合 )语法区别:
1、hiveSQL中 group by 后面必须添加分组的字段
presto、flinksql、sparksql group by 后面不需要指定分组字段
2、hiveSQL中 可以使用 grouping__id字段
presto、flinksql、sparksql 中并没有提供 grouping__id字段,需要使用grouping(a,b,c) 函数来计算
代码示例(HiveSQL):
-- TODO 必须开区map端合并
set hive.map.aggr=true;
SELECT prov,city,area,count(1),grouping__id
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all
select '河北省','石家庄市','新华区','张2' union all
select '河南省','郑州市','高开区','张3' union all
select '河南省','郑州市','高开区','张4' union all
select '河南省','郑州市','高开区','张5' union all
select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city,area grouping sets (
(prov,city,area),
(prov)
)
;代码示例(presto、flinkSQL、sparkSQL):
SELECT prov,city,area,count(1),grouping(prov,city,area) as grouping_id
FROM (VALUES ('河北省','石家庄市','新华区','张1'),
('河北省','石家庄市','新华区','张2'),
('河南省','郑州市','高开区','张3'),
('河南省','郑州市','高开区','张4'),
('河南省','郑州市','高开区','张5'),
('河南省','新乡市','中华区','张6')) AS person_info_df (prov,city,area,name)
group by grouping sets (
(prov,city,area),
(prov)
)
;3、with rollup - 上卷维度组合
功能说明:
上卷维度组合,较grouping sets相比,不需要指定维度组合
GROUP BY a, b, c, WITH ROLLUP 等价于
GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (a), ( ))
hive-语法:
-- TODO 必须开区map端合并
select
维度A
,维度B
,维度C
,聚合函数(度量字段)
,grouping__id
from 表名 [where ]
group by A,B,C
with rollup
presto、FlinkSQL、SparkSQL-语法:
select
维度A
,维度B
,维度C
,聚合函数(度量字段)
,grouping(A,B,C) as grouping_id
from 表名 [where ]
group by
rollup(A,B,C) 代码示例(HiveSQL):
-- 1.必须开区map端合并
set hive.map.aggr=true;
SELECT prov,city,area,count(1),grouping__id
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all
select '河北省','石家庄市','新华区','张2' union all
select '河南省','郑州市','高开区','张3' union all
select '河南省','郑州市','高开区','张4' union all
select '河南省','郑州市','高开区','张5' union all
select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city,area with rollup
;代码示例(presto、flinkSQL、sparkSQL):
SELECT prov,city,area,count(1),grouping(prov,city,area) as grouping_id
FROM (VALUES ('河北省','石家庄市','新华区','张1'),
('河北省','石家庄市','新华区','张2'),
('河南省','郑州市','高开区','张3'),
('河南省','郑州市','高开区','张4'),
('河南省','郑州市','高开区','张5'),
('河南省','新乡市','中华区','张6')) AS person_info_df (prov,city,area,name)
group by rollup(prov,city,area)
;4、with cube - 全维度组合
功能说明:
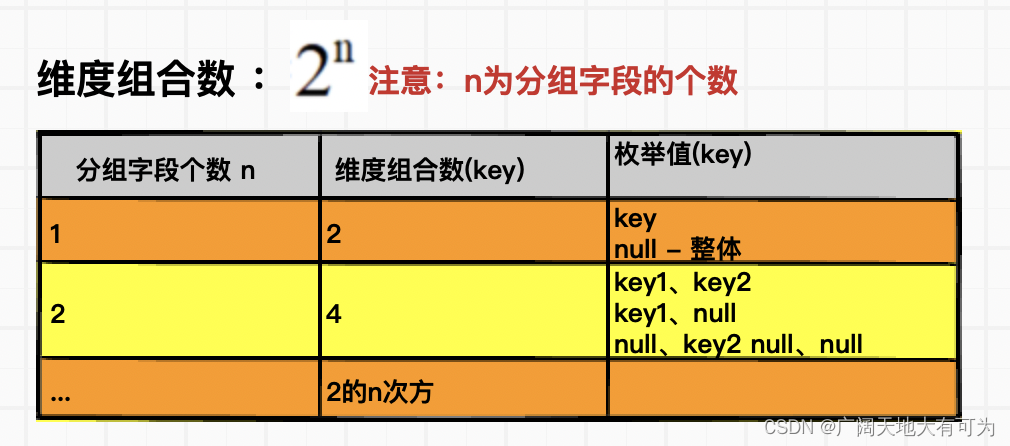
多维度组合,会计算所有分组字段的维度组合,较grouping sets相比,不需要指定维度组合
GROUP BY a, b, c, WITH CUBE 等价于
GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (b, c), (a, c), (a), (b), (c), ( ))
cube(key1,key2...) 维度组合数:
 hive-语法:
hive-语法:
-- TODO 必须开区map端合并
select
维度A
,维度B
,维度C
,聚合函数(度量字段)
,grouping__id
from 表名 [where ]
group by A,B,C
with cube
presto、FlinkSQL、SparkSQL-语法:
select
维度A
,维度B
,维度C
,聚合函数(度量字段)
,grouping(A,B,C) as grouping_id
from 表名 [where ]
group by
cube(A,B,C) 代码示例(HiveSQL):
-- 1.必须开区map端合并
set hive.map.aggr=true;
SELECT prov,city,area,count(1),grouping__id
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all
select '河北省','石家庄市','新华区','张2' union all
select '河南省','郑州市','高开区','张3' union all
select '河南省','郑州市','高开区','张4' union all
select '河南省','郑州市','高开区','张5' union all
select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city,area with cube
;代码示例(presto、flinkSQL、sparkSQL):
SELECT prov,city,area,count(1),grouping(prov,city,area) as grouping_id
FROM (VALUES ('河北省','石家庄市','新华区','张1'),
('河北省','石家庄市','新华区','张2'),
('河南省','郑州市','高开区','张3'),
('河南省','郑州市','高开区','张4'),
('河南省','郑州市','高开区','张5'),
('河南省','新乡市','中华区','张6')) AS person_info_df (prov,city,area,name)
group by cube(prov,city,area)
;5、Grouping__ID、grouping() 的使用场景
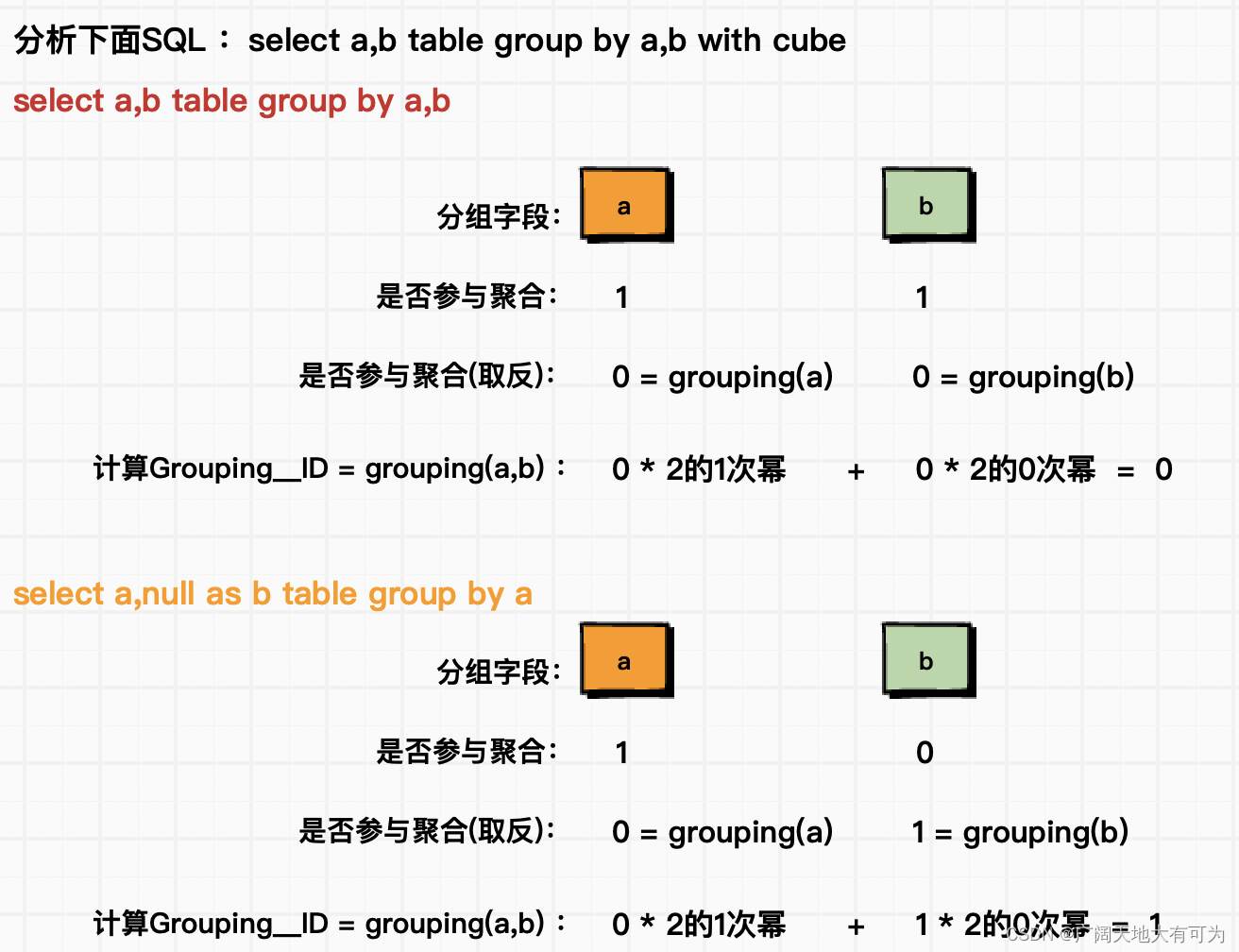
功能说明:
可以用来判断分组字段是否参与聚合,下面为 Grouping__ID 、grouping() 计算逻辑

使用场景:
当使用 grouping sets、with rollup、with cube进行聚合时,对不参与聚合的字段会使用null进行填充,这就导致查询结果中分组字段为null时,无法区分是填充的null还是分组字段本身的null
遇到上述情况,可以使用下面两种解决方式
1、将分组字段中的null进行替换处理,比如9999、other、其他
2、使用 Grouping__ID 或者 grouping() 进行区分

6、使用 增强聚合 会不会对查询性能有提升呢?
测试用例-grouping sets:
-- TODO 必须开区map端合并
set hive.map.aggr=true;
SELECT prov,city,area,count(1),grouping__id
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all
select '河北省','石家庄市','新华区','张2' union all
select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city,area grouping sets (
(prov,city,area),
(prov,city),
(prov)
)
;测试用例-group by + union all:
set hive.map.aggr=true;
SELECT prov,city,area,count(1)
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all
select '河北省','石家庄市','新华区','张2' union all
select '河南省','新乡市','中华区','张6'
) AS person_info_df
group by prov,city,area
union all
SELECT prov,city,null as area,count(1)
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all
select '河北省','石家庄市','新华区','张2' union all
select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov,city
union all
SELECT prov,null as city,null as area,count(1)
FROM (select '河北省' as prov,'石家庄市' as city,'新华区' as area,'张1' as name union all
select '河北省','石家庄市','新华区','张2' union all
select '河南省','新乡市','中华区','张6') AS person_info_df
group by prov对比执行计划:
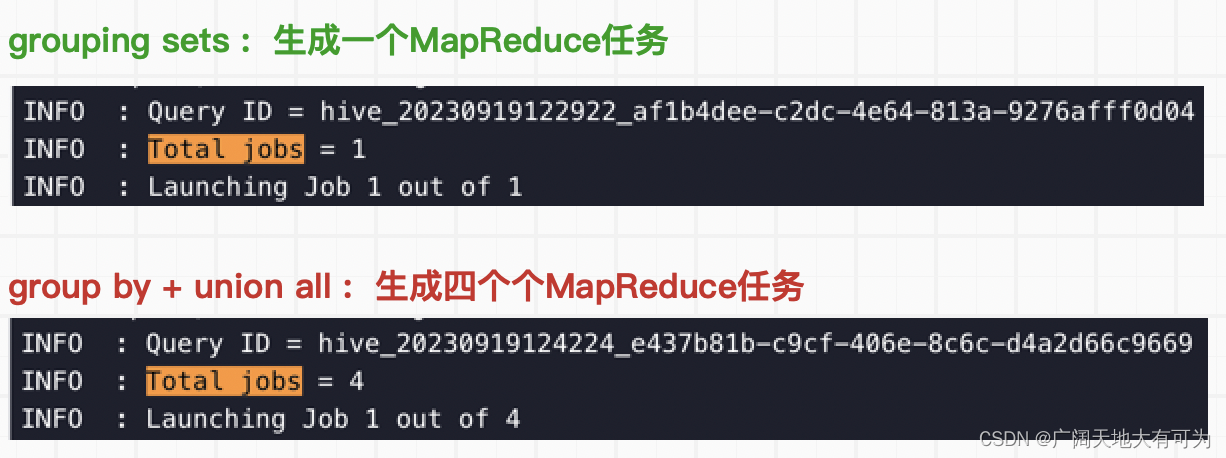
对比运行时长:
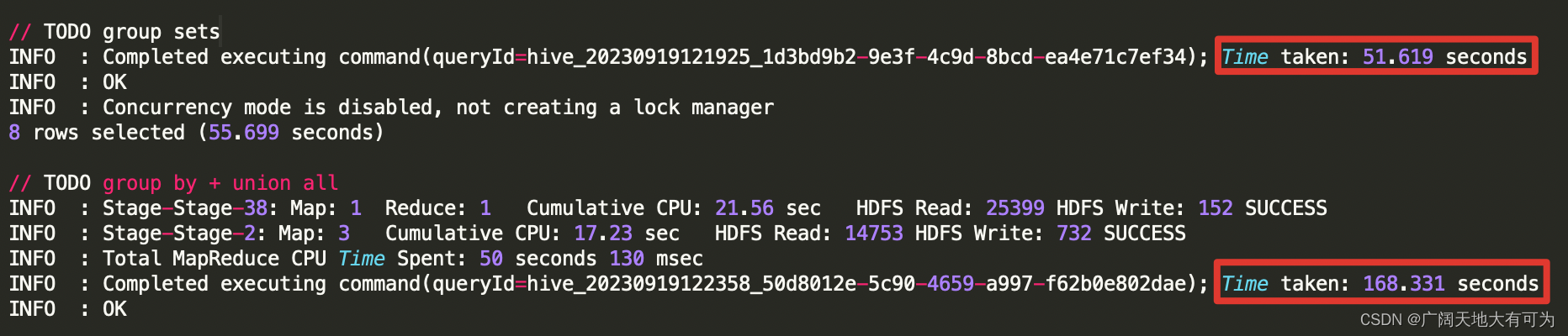
结论:
通过上面执行计划和运行时长的对比,使用 grouping sets、with cube、with rollup 确实比
group by + union all 方式的性能要好,因为 增强group by避免了多次读取底表,降低生成
job的个数,从而减轻了磁盘和网络I/O时的压力。
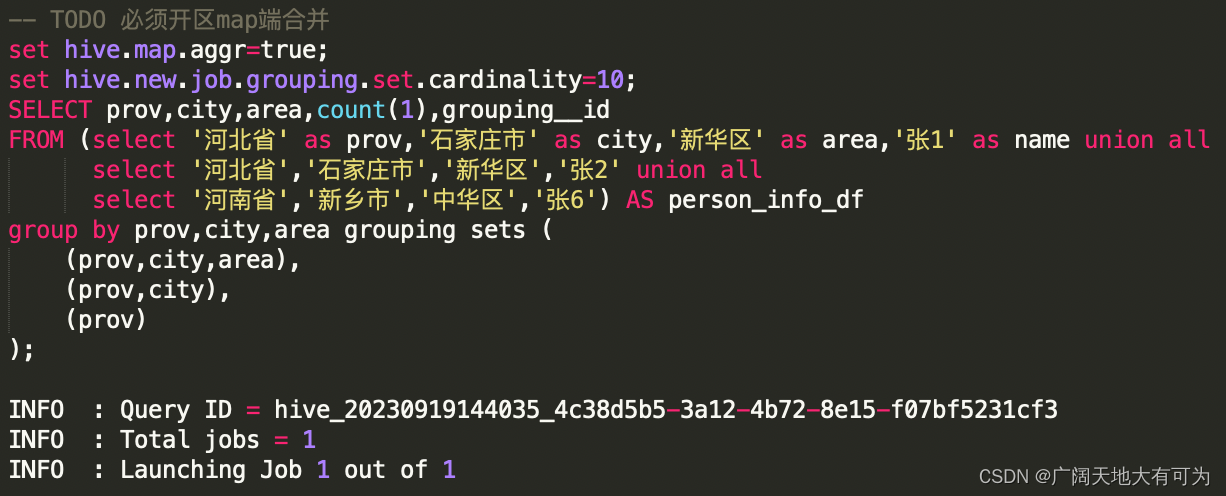
7、对grouping sets、with cube、with rollup 的优化
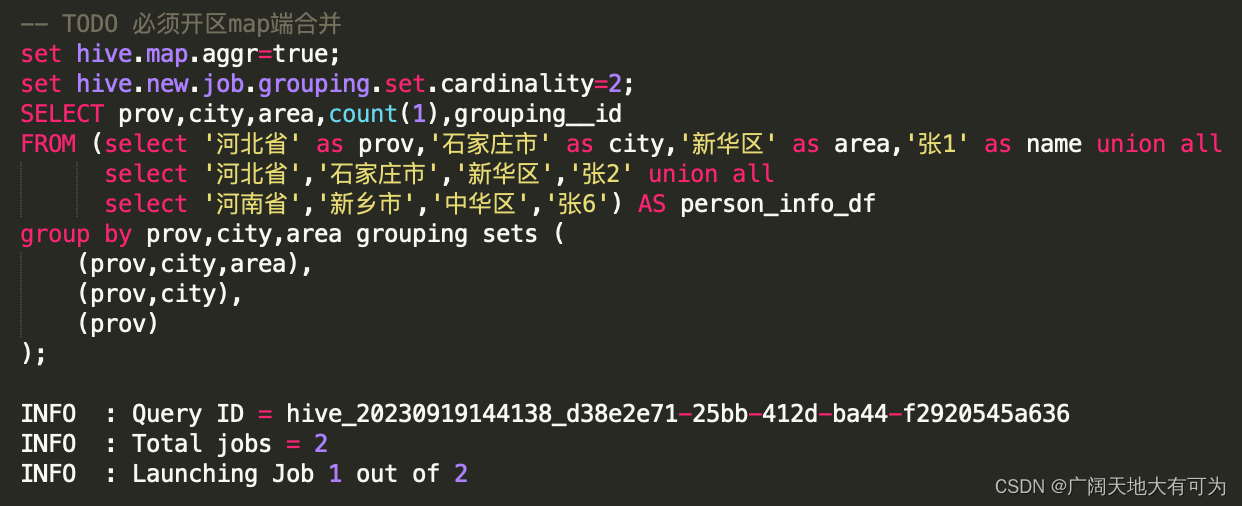
由于在使用增强group by时,会在同一个job中完成多种维度组合的聚合(2的N次方),当底表数据量太大 或 维度过多时,可能造成计算资源不够而导致任务失败。
在 Hive中可以使用 set hive.new.job.grouping.set.cardinality=30 来对job进行拆分。
参数说明:

验证SQL-实验组:
验证SQL-对照组: