Hadoop NameNode执行命令工作流程
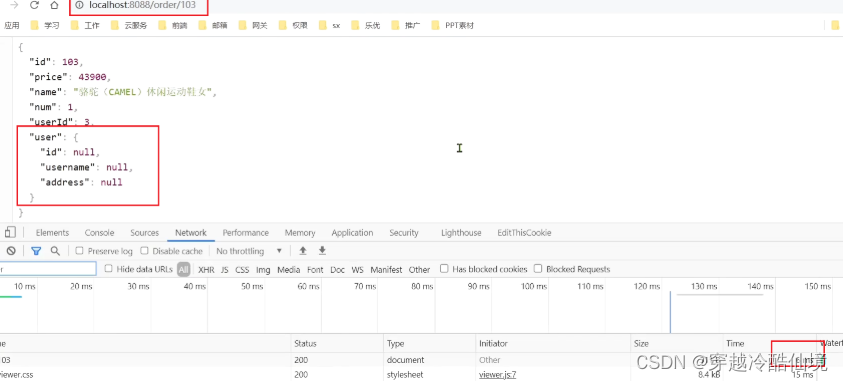
- 客户端API或者CLI与NameNode的交互命令数据的格式
- (1) 预处理流程
- (2) 创建NameNode与NameNodePrcServer流程
- (3) HDFS API以及CLI的命令到NameNode的工作执行流程
- (4) 执行命令的参数流动
客户端API或者CLI与NameNode的交互命令数据的格式
hadoop使用PB协议(protocol buffer)来传输数据与命令
ProtocolBuffer是用于序列化结构数据的灵活、高效、自动的方法,有如XML,不过它更小、更快、也更简单。一旦定义了你自己的数据结构,然后就可以使用特殊生成的源代码轻松的在各种数据流和使用的各种高级语言之间读写你的结构化数据。你甚至可以在不破坏根据“旧”格式编译的已部署程序的情况下更新你的数据结构。
(1) 预处理流程
PB协议使用了proto文件保存交互数据的结构,因此首先hadoop需要将proto编译成为java文件
执行maven命令打包的期间,会执行protoc命令将protopuf文件生成Java类
<plugin>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-maven-plugins</artifactId>
<executions>
<execution>
<id>compile-protoc</id>
<phase>generate-sources</phase>
<goals>
<goal>protoc</goal>
</goals>
<configuration>
<protocVersion>${protobuf.version}</protocVersion>
<protocCommand>${protoc.path}</protocCommand>
<imports>
<param>${basedir}/../../hadoop-common-project/hadoop-common/src/main/proto</param>
<param>${basedir}/src/main/proto</param>
</imports>
<source>
<directory>${basedir}/src/main/proto</directory>
<includes>
<include>ClientDatanodeProtocol.proto</include>
<include>ClientNamenodeProtocol.proto</include>
<include>DatanodeProtocol.proto</include>
<include>HAZKInfo.proto</include>
<include>InterDatanodeProtocol.proto</include>
<include>JournalProtocol.proto</include>
<include>NamenodeProtocol.proto</include>
<include>QJournalProtocol.proto</include>
<include>acl.proto</include>
<include>xattr.proto</include>
<include>datatransfer.proto</include>
<include>fsimage.proto</include>
<include>hdfs.proto</include>
<include>encryption.proto</include>
<include>inotify.proto</include>
</includes>
</source>
<output>${project.build.directory}/generated-sources/java</output>
</configuration>
</execution>
</executions>
</plugin>
(2) 创建NameNode与NameNodePrcServer流程
NameNode.main() —> MainNode.createNameNode()—>new NameNode() —> NameNode.initialize() —> createRpcServer() —> new NameNodeRpcServer(conf, this) —> BlockingService clientNNPbService = ClientNamenodeProtocol.newReflectiveBlockingService(new ClientNamenodeProtocolServerSideTransltatorPB(this)) —> new PRC.Builder(conf).setInstance(clientNNPbService ) —> NameNodePrcServer.start()
- 在NameNode的构建方法中,PRC使用了protopuf来存储所有的协议,其中就包括ClientNamenodeProtocol.proto,其用来设定与namenode的交互数据格式,比如mkdir、delete、rename等命令。
- protopuf协议的目录在\hadoop-hdfs-project\hadoop-hdfs\src\main\proto
- BlockingService便是与namenode交互协议的实现,将其交给NameNodePrcServer实现了对客户端使用该协议的监听,当有相关执行命令被监控到,通过协议版本信息可以适配到相应的BlockingService。
(3) HDFS API以及CLI的命令到NameNode的工作执行流程
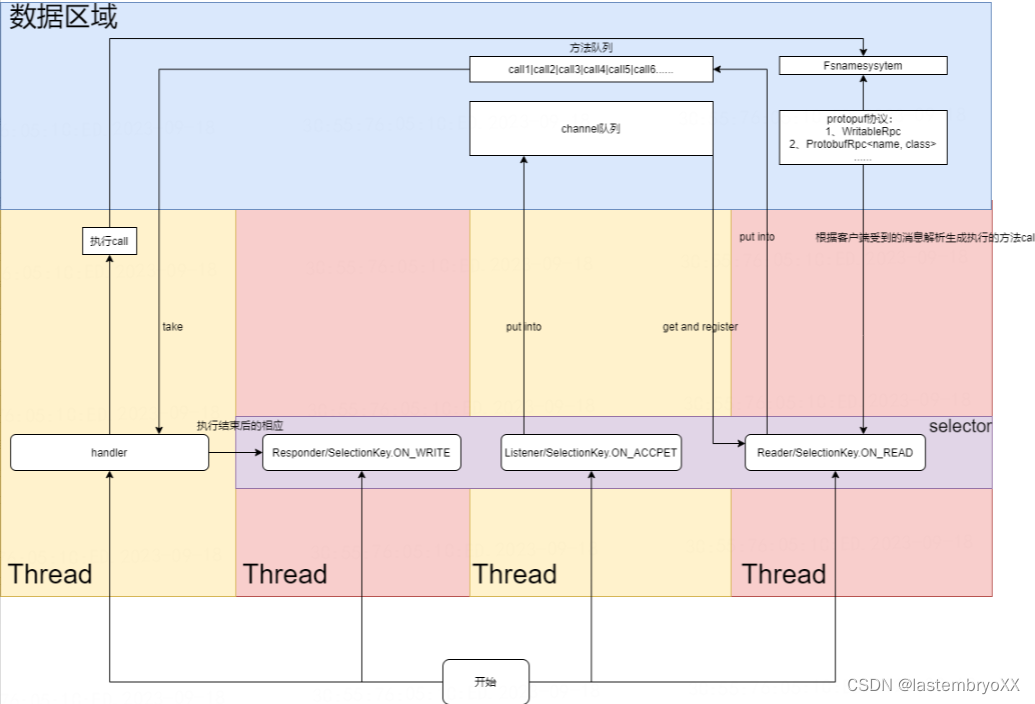
- 为了能够准确的监听与处理客户端的命令,NameNode创建了四种独立的角色,并发执行,Listener、Responder、Reader、Handler,其中Listener、Responder、Reader都是Selector。
- Listener负责监听连接,并创建channel将其引用放置到channel队列。
- Reader负责监听channel队列中发送的ON_READ事件并进行数据的保存、协议的解析,然后创建Call对象,并置于Call队列当中。
- Handler负责处理Call队列,根据Call拿到具体的协议的实现,调用FSNamesystem进行具体的命令,比如mkdir,rename等命令都是在该阶段进行创建的。
- Responder负责Handler处理之后结果的响应。
(4) 执行命令的参数流动
客户端请求执行命令 —> Reader —> Call —> ClientNamenodeProtocolTranslatorPB(implements ProtocolMetaInterface, ClientProtocol, Closeable, ProtocolTranslator)
—> ClientNamenodeProtocolServerSideTranslatorPB(implements
ClientNamenodeProtocolPB).mkdirs() —> NameNodeRpcServer(implements ClientProtocol).mkdirs() —> FSNamesystem.mkdirs() —> FSDirMkdirOp
.mkdirs()