1、什么是混淆矩阵
混淆矩阵(Confusion Matrix)是深度学习和机器学习领域中的一个重要工具,用于评估分类模型的性能。它提供了一个清晰的视觉方式来展示模型的预测结果与真实标签之间的关系,尤其在分类任务中,帮助我们了解模型的强项和弱点。
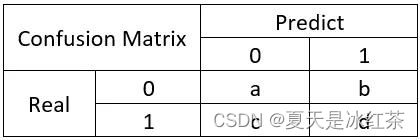
混淆矩阵通常是一个二维矩阵,其中包含四个关键的指标:
| 预测值=正例 | 预测值=反例 | |
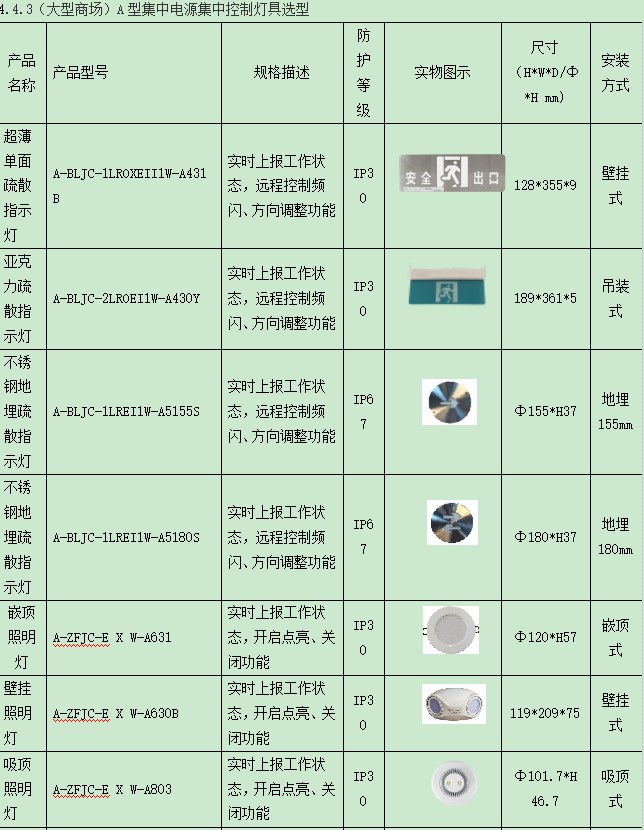
| 真实值=正例 | TP | FN |
| 真实值=反例 | FP | TN |
-
真正例(True Positives,TP): 模型正确地预测了正类别的样本数量。
-
真负例(True Negatives,TN): 模型正确地预测了负类别的样本数量。
-
假正例(False Positives,FP): 模型错误地将负类别的样本预测为正类别的数量。
-
假负例(False Negatives,FN): 模型错误地将正类别的样本预测为负类别的数量。
你可以选择看我之前写过的这一篇博客。其实很好理解,比如TP,它就是正确的预测了正确的样本,FP就是错误的预测为了正确的样本。同理,TN就是正确的预测了错误的样本,FN就是错误的预测了错误的样本。
2、从混淆矩阵得到分类指标
然后我们来看上图,这里就能够得到一些指标运算的公式:
准确率(Accuracy):它是分类正确的样本数与总样本数的比率。准确率通常用来衡量模型在整个数据集上的性能,但在不平衡类别的情况下可能不太适用。
准确率 = (TP + TN) / (TP + TN + FP + FN)
精确率(Precision):精确率是指被模型正确预测为正类别的样本数占所有预测为正类别的样本数的比率。它用于衡量模型在正类别预测中的准确性。
精确率 = TP / (TP + FP)
召回率(Recall):召回率是指被模型正确预测为正类别的样本数占所有真实正类别的样本数的比率。它用于衡量模型在识别正类别样本中的能力。
召回率 = TP / (TP + FN)
F1 分数:F1 分数是精确率和召回率的调和平均值,用于综合评估模型的性能。它对精确率和召回率都进行了考虑,特别适用于不平衡类别的情况。
F1 分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
IoU(Intersection over Union):IoU 用于语义分割等任务,它是真实正类别区域与模型预测正类别区域的交集与并集之比。
IoU = TP / (TP + FP + FN)
3、使用pytorch构建混淆矩阵
最初要写的目的也是为了回顾一下之前所学的,并且想要在训练过程中能写一个类方便调用。先说一下思路。
首先,这个是针对标签的,我需要一个num_classes,也就是分类数,以便我先创建一个分类数大小的矩阵。
然后在不计算梯度的情况下,我们需要筛选出合适的像素点,这里简单来说就是一行代码:
k = (t >= 0) & (t < n)- t是真实类别的张量,其中包含了每个像素的真实类别标签。
- n是类别总数,表示模型可以进行分类的类别数量。
然后,通过t[k]与p[k]就可以确定正确的像素范围。将每个选定像素的真实类别标签乘以总类别数n,以获得一个在混淆矩阵中的行索引,然后再加上p[k],就是我们混淆矩阵的索引。
inds = n * t[k].to(torch.int64) + p[k]torch.bincount是用于统计 inds 中每个索引出现的次数。minlength 参数指定了输出张量的长度,这里设置为 n**2,以确保输出张量的长度足够容纳混淆矩阵的所有元素。
以上就是我的思路,这里大家可以自己打印出来看看每个步骤是怎么实现的:
import torch
num_classes = n = 3
mat = torch.zeros((n, n), dtype=torch.int64)
true_labels = t = torch.tensor([0, 1, 2, 0, 1, 2]) # 真实标签
predicted_labels = p = torch.tensor([0, 1, 1, 0, 2, 1]) # 预测结果
with torch.no_grad():
k = (t >= 0) & (t < n)
inds = n * t[k].to(torch.int64) + p[k]
print(inds)
mat += torch.bincount(inds, minlength=n ** 2).reshape(n, n)
print(mat)打印出来的值:
tensor([0, 4, 7, 0, 5, 7])
tensor([[2, 0, 0],
[0, 1, 1],
[0, 2, 0]])
这个混淆矩阵解释如下:
- 第一行表示真实标签为类别0的样本,模型将其分为类别0的次数为2次。
- 第二行表示真实标签为类别1的样本,模型将其中一个分为类别1,另一个分为类别2。
- 第三行表示真实标签为类别2的样本,模型将其都分为类别1。
然后对照我们原本设定的数据也是完全符合的。
4、使用pytorch构建分类指标
将混淆矩阵 mat 转换为浮点数张量 h ,以便进行后续计算
h = mat.float()全局预测准确率,混淆矩阵的对角线表示的是真实和预测相对应的个数
acc_global = torch.diag(h).sum()/h.sum()计算每个类别的准确率
acc = torch.diag(h)/h.sum(1)计算每个类别预测与真实目标的iou,IoU = TP / (TP + FP + FN)
iu = torch.diag(h) / (h.sum(1) + h.sum(0) - torch.diag(h))
我们打印出来,大家可以对照着公式进行对比即可:
tensor(0.5000) tensor([1.0000, 0.5000, 0.0000]) tensor([1.0000, 0.2500, 0.0000])
其他的指标以后在补充,我想的是在评估的时候使用,所以这里的指标最好还是写一个类定义。
我也将其放进了pyzjr当中,欢迎大家pip安装使用。
class ConfusionMatrix(object):
def __init__(self, num_classes):
self.num_classes = num_classes
self.mat = None
def update(self, t, p):
n = self.num_classes
if self.mat is None:
# 创建混淆矩阵
self.mat = torch.zeros((n, n), dtype=torch.int64, device=t.device)
with torch.no_grad():
# 寻找GT中为目标的像素索引
k = (t >= 0) & (t < n)
# 统计像素真实类别t[k]被预测成类别p[k]的个数
inds = n * t[k].to(torch.int64) + p[k]
self.mat += torch.bincount(inds, minlength=n**2).reshape(n, n)
def reset(self):
if self.mat is not None:
self.mat.zero_()
def compute(self):
"""
计算全局预测准确率(混淆矩阵的对角线为预测正确的个数)
计算每个类别的准确率
计算每个类别预测与真实目标的iou,IoU = TP / (TP + FP + FN)
"""
h = self.mat.float()
acc_global = torch.diag(h).sum() / h.sum()
acc = torch.diag(h) / h.sum(1)
iu = torch.diag(h) / (h.sum(1) + h.sum(0) - torch.diag(h))
return acc_global, acc, iu
def __str__(self):
acc_global, acc, iu = self.compute()
return (
'global correct: {:.1f}\n'
'average row correct: {}\n'
'IoU: {}\n'
'mean IoU: {:.1f}').format(
acc_global.item() * 100,
['{:.1f}'.format(i) for i in (acc * 100).tolist()],
['{:.1f}'.format(i) for i in (iu * 100).tolist()],
iu.mean().item() * 100)
if __name__=="__main__":
num_classes = 3
confusion_matrixs = ConfusionMatrix(num_classes)
# 模拟一些真实标签和预测结果
true_labels = torch.tensor([0, 1, 2, 0, 1, 2]) # 真实标签
predicted_labels = torch.tensor([0, 1, 1, 0, 2, 1]) # 预测结果
# 更新混淆矩阵
confusion_matrixs.update(true_labels, predicted_labels)
# 打印混淆矩阵及评估指标报告
print("Confusion Matrix:")
print(confusion_matrixs.mat)
print("\nEvaluation Report:")
print(confusion_matrixs)打印的信息:
Confusion Matrix:
tensor([[2, 0, 0],
[0, 1, 1],
[0, 2, 0]])Evaluation Report:
global correct: 50.0
average row correct: ['100.0', '50.0', '0.0']
IoU: ['100.0', '25.0', '0.0']
mean IoU: 41.7
5、与sklearn的官方实现进行比较
同样的数据,我们放入到sklearn中看看是否正确呢?
from sklearn.metrics import confusion_matrix
confusion_matrix_result = confusion_matrix(true_labels, predicted_labels)
print(confusion_matrix_result)[[2 0 0]
[0 1 1]
[0 2 0]]
不看数据类型,元素都是一一对应的,说明我们的实现是正确的。