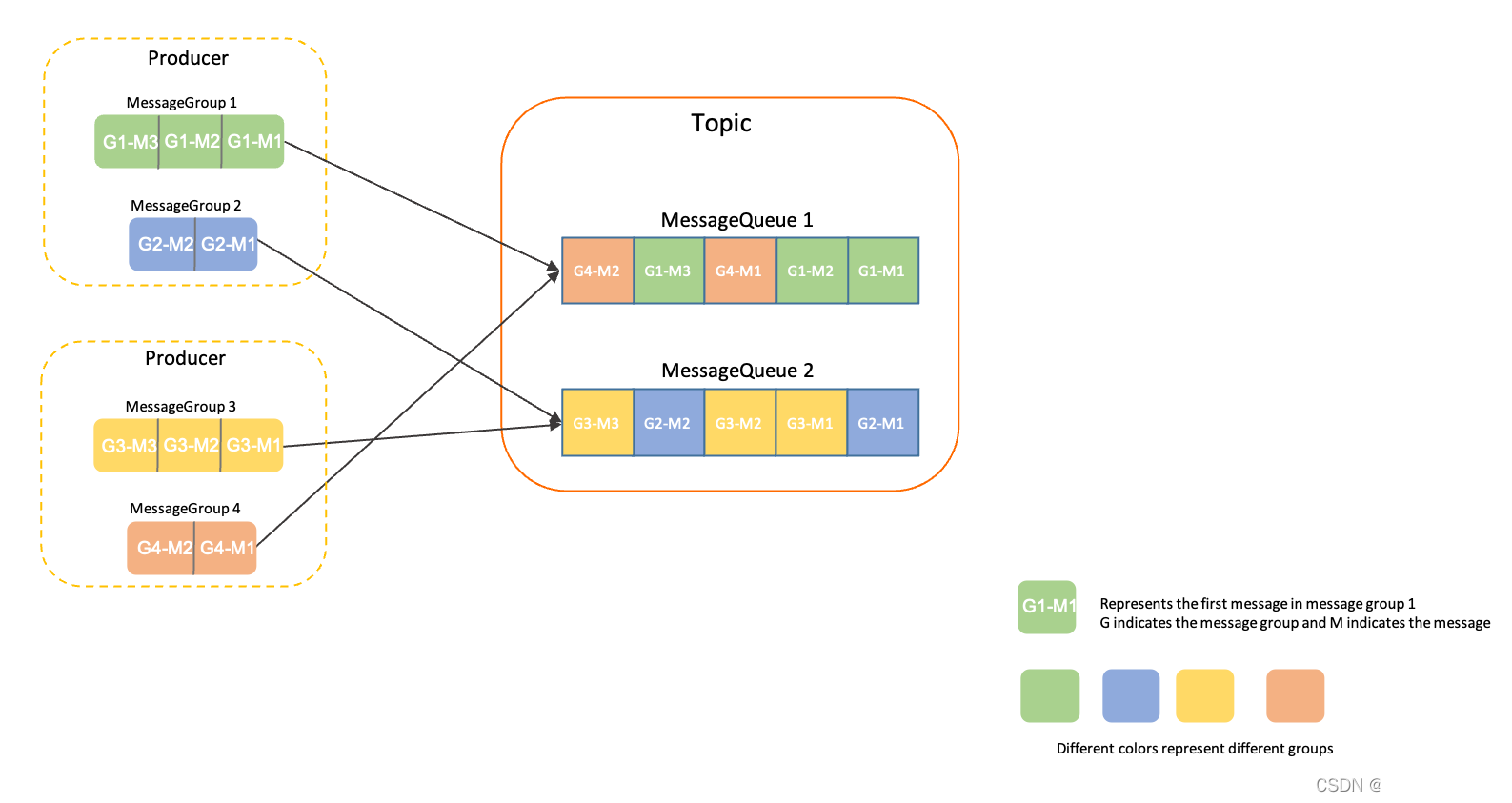
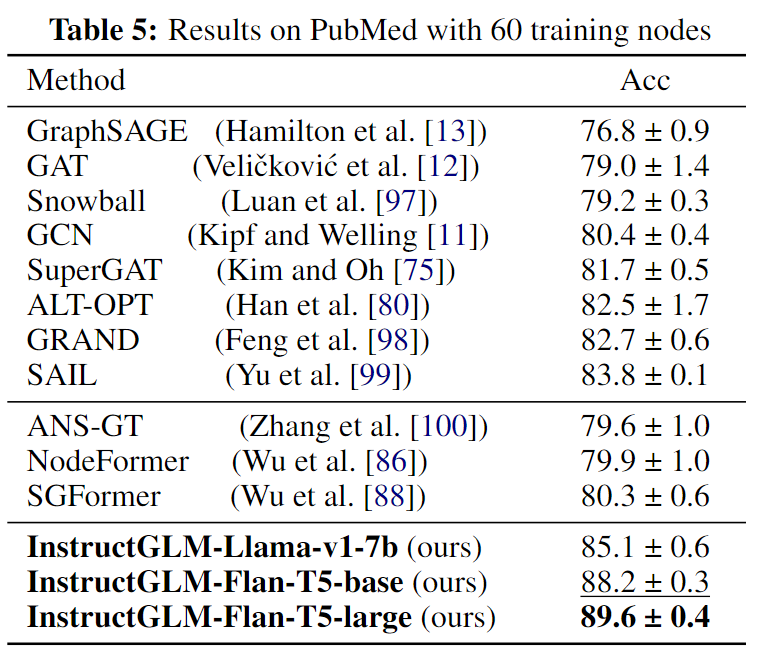
下面是一些参数高效的微调大模型方法:
Adapter
模型总览

Adapter作为一个插件加入到大模型内,微调下游任务时,固定大模型参数,只训练Adapter参数。
LoRA
LoRA名为大语言模型的低阶适应,最初设计用于微调LLM,但却在文生图领域大放异彩,并逐渐被人数知。其思想跟ResNet非常相似,通过在大模型旁侧添加一路分支,冻结大模型参数,学习分支参数(也即残差),达到微调效果。
模型总览


如果 Δ W \Delta W ΔW 跟 W 0 W_0 W0 一样,也是 R d × d \mathbb{R}^{d \times d} Rd×d,那么残差学习同样需要训练大量的参数,并没有达到参数高效的目标。而在我们学习中,常用的减少矩阵参数大小方法就是矩阵分解,因此作者对输入先降采样,再上采样,实现输入与输出维度一致。
Prefix-Tuning
该方法主要用来做NLG任务(Table-to-text Generation、 Summarization),在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而大模型参数冻结。
模型总览

Prefix tokens初始化如下:

需要注意的是,在低资源场景下,用任务相关的单词来初始化prefix tokens,效果更好:

Prompt-tuning
Prompt-Tunning算是prefix-Tunning的简化版本,面向NLU任务,进行了更全面的效果对比,并且在大模型上成功打平了LM微调的效果。
模型总览

- 初始化:Prompt-tuning在输入层前置多个可训练的tokens,固定住大模型参数。实验结果表明用类标签来初始化prompts效果最好。
- prompt ensembling:针对同一个任务,构造多个不同的prompts,就相当于训练了多个模型。

Prompt-tuning 与 Prefix-Tuning 不同
- 两者的基座模型不同,一个是T5,一个是BART和GPT2
- 前者关注NLU,后者关注NLG
- 前者参数更少,只需微调embeding层;后者需要微调所有层embedding,以及需要在输入层之后接一个MLP来稳定训练
P-tuning V1 & P-tuning V2
P-tuning主要用GPT来做NLU任务,达到甚至超过BERT同等水平。
模型总览

v1做了如下两点优化:
- 考虑到预训练模型本身的embedding就比较离散了(随机初始化+梯度传回来小,最后只是小范围优化),同时prompt本身也是互相关联的,所以作者先用LSTM对prompt进行编码。
- 在prompt模板中,加入一些anchor tokens效果会更好。
v2主要是在大模型的每一层加入可训练prompts:

参考
- 解密Prompt系列3. 冻结LM微调Prompt: Prefix-Tuning & Prompt-Tuning & P-Tuning
- Prompt范式第二阶段|Prefix-tuning、P-tuning、Prompt-tuning
- 大模型参数高效微调技术原理综述(四)-Adapter Tuning及其变体