文章目录
- 前言知识
- 前后端不分离
- 前后端分离
- RESTful API
- HTTP请求方法详解
- 部分状态码(常见)
- Django补充知识
- 创建多个app
- 安装
- 安装完后的配置
- Drf框架介绍
- 相比于Django的优势
- 基础介绍--快速入门--了解框架的大概实现
- Serializers
- 基础准备
- 编写Serializers.py 以及 上传部分样例数据
- 序列化流程介绍
- 反序列化流程介绍
- 继承 ModelSerializers
- 序列化程序 搭配 常规的 Django 视图
- 模拟发包 及 了解drf的web-api
- Requests and Responses
- 为我们的 URL 添加可选的格式后缀
- Class-based Views
- 使用mixins
- 使用基于类的通用视图
- Authentication & Permissions
- 准备工作
- views当中添加用户权限
- 自定义权限类-对象级权限
- 使用API进行身份验证
- Relationships & Hyperlinked APIs
- 为我们的 API 根创建终端节点
- 为突出显示的代码段创建终结点,只显示ORM对象的部分内容
- 超链接我们的 API
- 全局分页功能
- ViewSets & Routers
- 使用视图集
- 使用路由器
- 视图与视图集之间的权衡
前言知识
前后端不分离
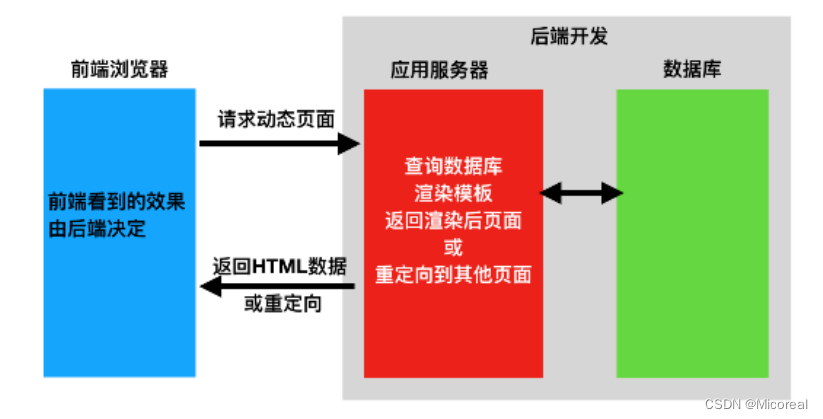
对于前后端不分离的代码,采用模板语言进行书写,详细Django详细介绍,模板语言那一小节。
前后端分离
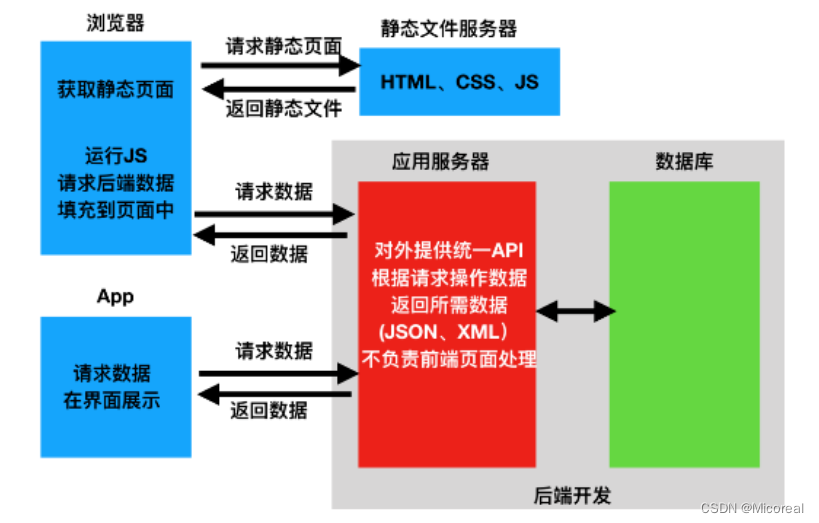
比较基础的见我们上一章写的WSGI微型web服务器。
RESTful API
详细见:链接
这边仅仅进行总结:
- 需要配合和HTTP协议的五种GET(获取),POST(新增),DELETE(删除),PUT(修改全部),PATCH(修改部分),也即CRUD进行命名(将其作为动词进行使用)
- 返回的数据需要按照json格式进行传递
- 不要将url定义的非常长,很多英文代码构成
- 不要定义的url使用动宾结构
- 不要使用资源路径作为url
- 当返回的页面时错误,需要有报错的状态代码
HTTP请求方法详解
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
部分状态码(常见)
| 状态码 | 说明 |
|---|---|
| 200 OK - [GET] | 服务器成功返回用户请求的数据 |
| 201 CREATED - [POST/PUT/PATCH] | 用户新建或修改数据成功。 |
| 202 Accepted - [*] | 表示一个请求已经进入后台排队(异步任务) |
| 204 NO CONTENT - [DELETE] | 用户删除数据成功。 |
| 400 INVALID REQUEST - [POST/PUT/PATCH] | 用户发出的请求有错误,服务器没有进行新建或修改数据的操作. |
| 401 Unauthorized - [*] | 表示用户没有权限(令牌、用户名、密码错误) |
| 403 Forbidden - [*] | 表示用户得到授权(与401错误相对),但是访问是被禁止的。 |
| 404 NOT FOUND - [*] | 用户发出的请求针对的是不存在的记录,服务器没有进行操作 |
| 410 Gone -[GET] | 用户请求的资源被永久删除,且不会再得到的。 |
| 422 Unprocesable entity - [POST/PUT/PATCH] | 当创建一个对象时,发生一个验证错误。 |
| 500 INTERNAL SERVER ERROR - [*] | 服务器发生错误,用户将无法判断发出的请求是否成功。 |
Django补充知识
创建多个app
第一步:
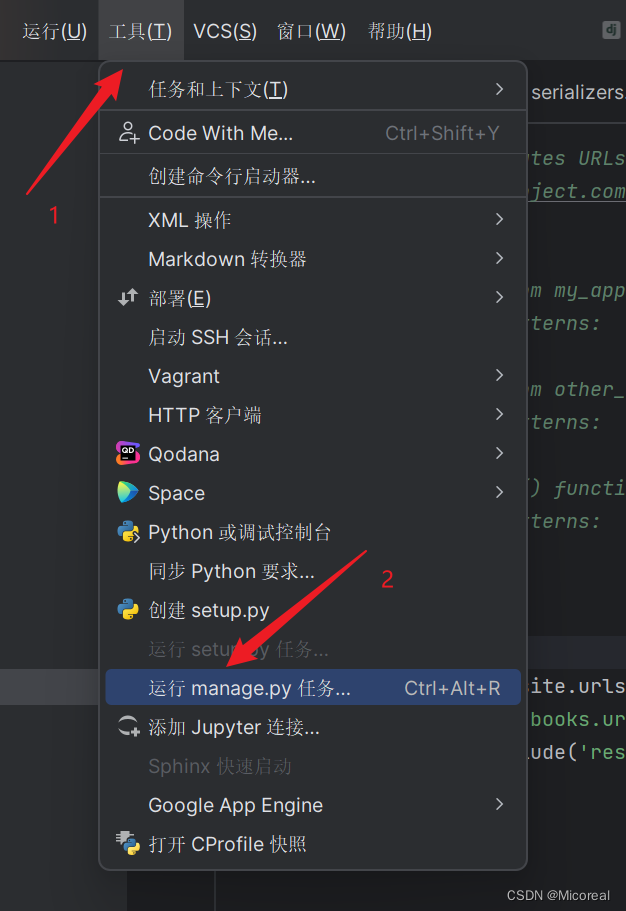
第二步:
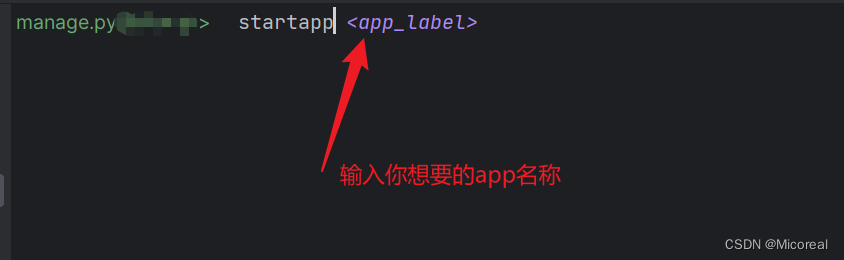
第三步:在setting下注册这个app,这就不需要截图了吧。
第四步:创建相对应的路由
path('自定义个一个名字/', include("对应app的.urls")), #使用自己应用内的路由
安装
首先安装和别的不太一样,需要使用conda-forge源进行安装
链接
conda config --add channels conda-forge
conda install djangorestframework
以及官网:链接
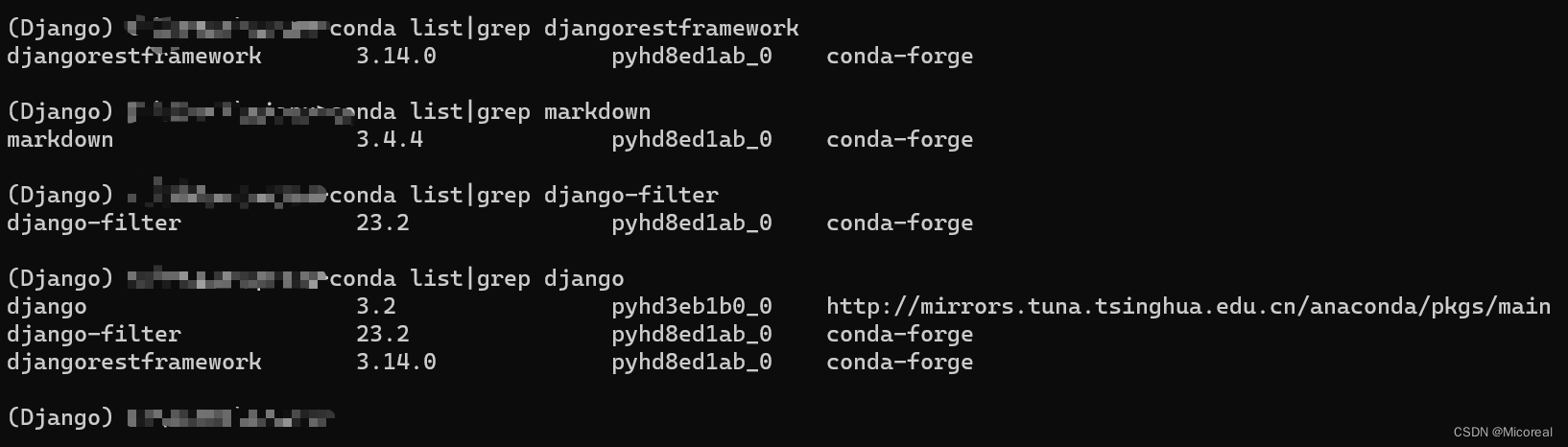
以及根据官网需要再加上两个包
pip install markdown # Markdown support for the browsable API.
pip install django-filter # Filtering support
pip install pygments # 高亮插件
此篇文章按照笔者的这个环境进行使用:
安装完后的配置
-
第一步:
首先创建Drf项目的方式和Django项目的方式一致,详情见我相同专栏的Django(一)的创建。 -
第二步:
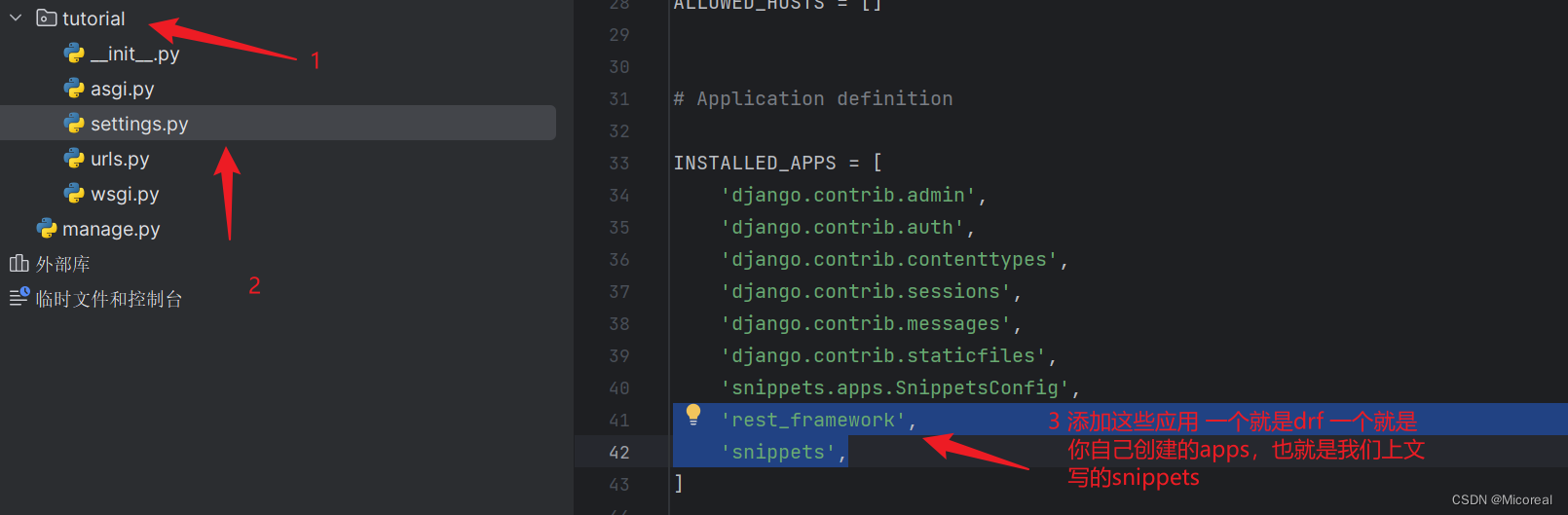
在项目文件夹下的setting.py中添加’rest_framework’这个app,我们写的时候通过联想,如果能联想出来,代表环境就已经创建好了。
INSTALLED_APPS = [
'rest_framework',
]
- 第三步:
如果你想使用基于浏览器的可视化的API目录,并且希望获得一个登录登出功能,那么可以在根路由下添加下面的路由,这个功能类似Django自带的admin后台,可以理解就是Drf版本的登录登出的功能实现。
在urls下导入对应rest_framework的路由
urlpatterns = [
path('admin/', admin.site.urls),
path('api-auth/', include('rest_framework.urls'))
]
- 第四步:
为了登录操作,也许你还要生成数据表,创建超级用户。这个步骤可选
python manage.py makemigrations
python manage.py migrate
python manage.py createsuperuser
就可以访问http://127.0.0.1:8000/api-auth/login/去登陆进行访问了,注意这个格式/api-auth 实际上就划分开了应用,不同的应用之间利用这个进行划分开,login就是对应的app当中的函数。
Drf框架介绍
相比于Django的优势
首先就是实现了前后端分离,在Django中,我们多使用T 模板语言进行是西安后端与前端的数据json的交互,但这明显是很不理智的,这导致后端程序员和前端程序员都需要相关的知识,甚至不断的沟通,效率比较低,所以就迫切需求一个前后端分离的技术。
在前后端分离的设计模式中,后端只负责返回前端需要的数据。后端开发的每个视图都称为一个接口(API),前端通过接口进行数据增删改查。因此,需要将操作数据库将模型类对象转换成响应数据,比如Json(或者xml、yaml)的格式以及请求的数据(如json\xml、yaml格式的数据)转换成模型类对象。
将 Django数据库中的数据(queryset 或者instance )转换为 json/xml/yaml数据格式,返回给前端过程称为序列化,相反过程称为反序列化。而实现这一过程运用的工具称为称为序列化器。Django提供的强大序列化工具叫做serializers(序列化器)。在开发REST API 接口时,视图中要频繁进行序列化和反序列化的编写,因此掌握serializers的使用非常重要的。
serializers的功能实际上就只有三种:序列化 反序列化 校验 后面也会一一解释。
基础介绍–快速入门–了解框架的大概实现
Serializers
首先就是需要到你的应用下创建:一个名为serializers.py的文件(不是刚需,但是业内都这么进行使用),还是重复一遍这个serializers完成的功能就是序列|反序列|校验,随着介绍,后面会有更深的体会。
这边我们先拿官网的入门教学进行展示,让大家脑子里大概有序列化器这么一个概念到底是什么。链接
基础准备
首先就是开始创建,这边就不再次进行介绍了,这边详细的见上面即可,这边给出官方创建的项目的名称,方便有人需要调试进行理解:
然后这边补充一下可视化创建:
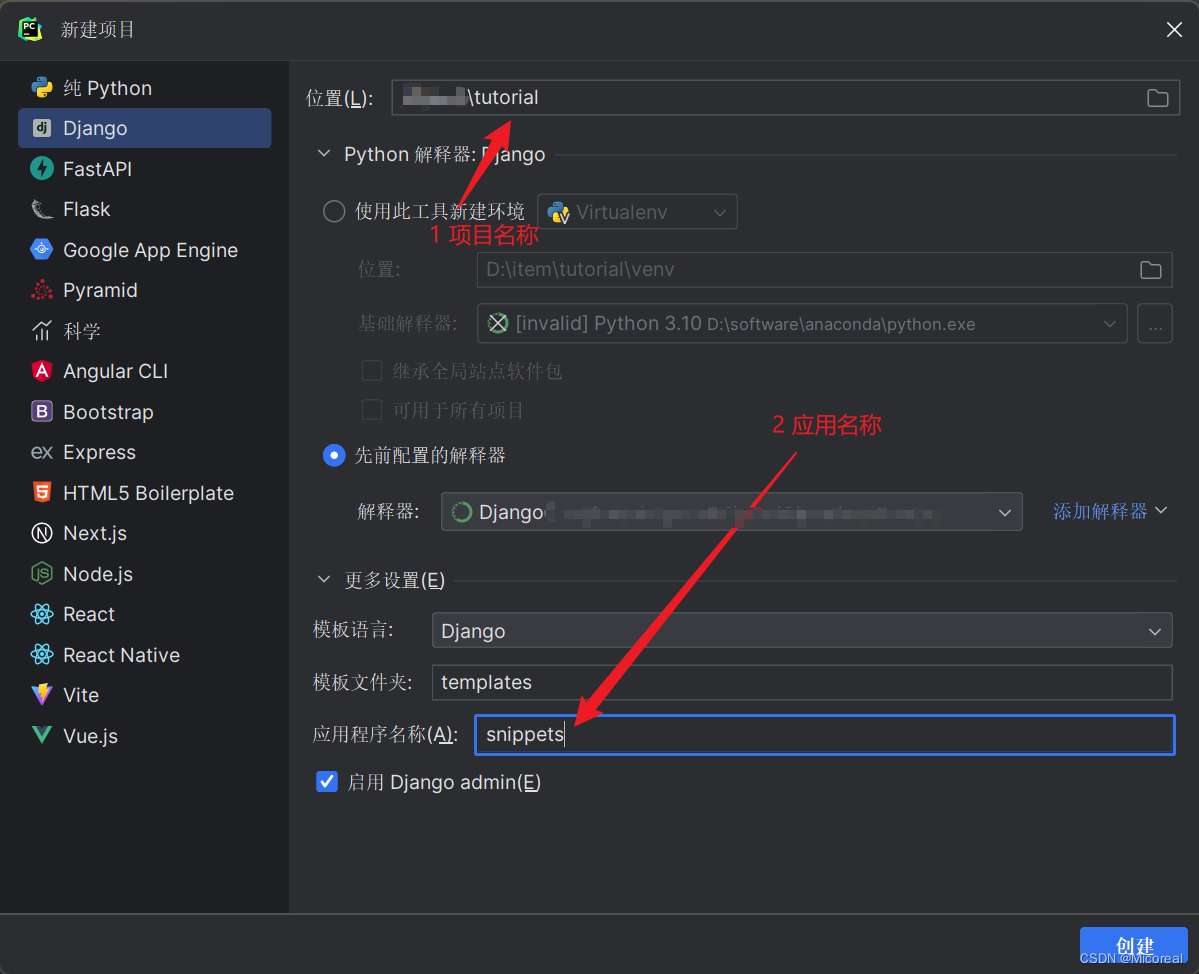
然后再把这个项目进行连接服务器,使用ftp部署上服务器,当然服务器的环境需要先进行配置好,并且在上面的解释器就使用服务器的吧,做一个远程ssh连接。上面的应用似乎多写了一次,这边展示一下可视化创建会自动插入app,这边需要吧snippets去掉,因为看上面已经出现了
第一步:
到snippets/models.py文件夹下:
from django.db import models
from pygments.lexers import get_all_lexers
from pygments.styles import get_all_styles
LEXERS = [item for item in get_all_lexers() if item[1]]
LANGUAGE_CHOICES = sorted([(item[1][0], item[0]) for item in LEXERS])
STYLE_CHOICES = sorted([(item, item) for item in get_all_styles()])
class Snippet(models.Model):
created = models.DateTimeField(auto_now_add=True)
title = models.CharField(max_length=100, blank=True, default='')
code = models.TextField()
linenos = models.BooleanField(default=False)
language = models.CharField(choices=LANGUAGE_CHOICES, default='python', max_length=100)
style = models.CharField(choices=STYLE_CHOICES, default='friendly', max_length=100)
class Meta:
ordering = ['created']
第二步:
model写完之后,对数据进行迁移。
python manage.py makemigrations snippets
python manage.py migrate snippets
编写Serializers.py 以及 上传部分样例数据
第三步:创建序列化程序类
"""
创建snippets的可序列化类,下面导入包就导入模型,还有那两个高亮部分
"""
from rest_framework import serializers
from snippets.models import Snippet, LANGUAGE_CHOICES, STYLE_CHOICES
class SnippetSerializer(serializers.Serializer):
"""
继承Serializer类的话,传送给前端的数据取决于下面的数据,至于参数后面再进行介绍,参数主要用于校验,这边也可以直接继承ModelSerializer类,如果继承这个类,下面的id title什么的都不用写了,但这边为了实现原理,这边采用这种写法。
"""
id = serializers.IntegerField(read_only=True)
title = serializers.CharField(required=False, allow_blank=True, max_length=100)
code = serializers.CharField(style={'base_template': 'textarea.html'})
linenos = serializers.BooleanField(required=False)
language = serializers.ChoiceField(choices=LANGUAGE_CHOICES, default='python')
style = serializers.ChoiceField(choices=STYLE_CHOICES, default='friendly')
def create(self, validated_data):
"""
Create and return a new `Snippet` instance, given the validated data.
"""
return Snippet.objects.create(**validated_data)
def update(self, instance, validated_data):
"""
Update and return an existing `Snippet` instance, given the validated data.
"""
instance.title = validated_data.get('title', instance.title)
instance.code = validated_data.get('code', instance.code)
instance.linenos = validated_data.get('linenos', instance.linenos)
instance.language = validated_data.get('language', instance.language)
instance.style = validated_data.get('style', instance.style)
instance.save()
return instance
第四步:
介绍一下反序列化和序列化的操作,首先序列化就是将python当中的对象(model
数据)转化为json格式,也就是js可读的数据类型,而反序列化就是将前端传回的数据转化为python对象的数据。
在进一步讨论之前,我们将熟悉如何使用新的序列化程序类。让我们进入 Django shell。
python manage.py shell
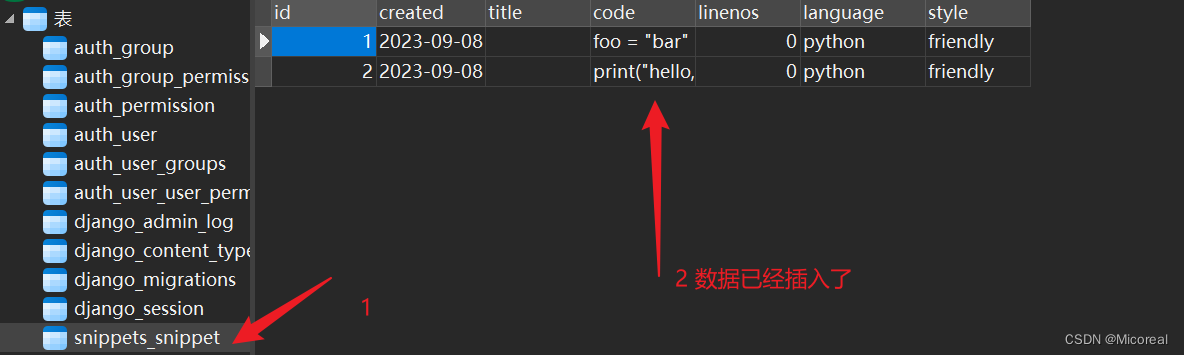
进入shell界面之后我们往数据库当中导入几个数据进行使用:
from snippets.models import Snippet
from snippets.serializers import SnippetSerializer
from rest_framework.renderers import JSONRenderer
from rest_framework.parsers import JSONParser
snippet = Snippet(code='foo = "bar"\n')
snippet.save()
snippet = Snippet(code='print("hello, world")\n')
snippet.save()
序列化流程介绍
序列化需要用到的包:
from snippets.models import Snippet
from snippets.serializers import SnippetSerializer
from rest_framework.renderers import JSONRenderer
上面已经导入过了,这边说明一下,简单说明就是模型类、模型类序列器、以及传递给json的传递器jsonrenderer
记得一句一句复制哈,别一次性运行,了解一下过程
# 先选定一个数据,我们这边可以利用模型类的依赖倒置原则,也就是object对象去数据库当中提出数据,并封装成一个对象。(例如:Snippet.objects.get(id = 5))
s1 = Snippet.objects.get(id = 2)
# 使用SnippetSerializer你自己编写的类,这个类的父类继承了一个对应的方法,也就是切片编程的思想,会帮你实现字典化转化。记得仔细查看这边仅仅传入一个s1,仔细看哈
serializer = SnippetSerializer(s1)
# 查看一下现在转化为了什么,字典化
serializer.data
输出:
{'id': 2, 'title': '', 'code': 'print("hello, world")\n', 'linenos': False, 'language': 'python', 'style': 'friendly'}
# 很明显已经是一个字典了,但是这么看来还不是前端想要的数据,前端js语言的bool值是false,但是在python中是False,很明显不一样,这一步做到的只是字典话,所以需要再次进行转化,实现真正的json化
content = JSONRenderer().render(serializer.data)
# 查看一下数据
content
输出:
b'{"id":2,"title":"","code":"print(\\"hello, world\\")\\n","linenos":false,"language":"python","style":"friendly"}'
# 明显变成了前端喜欢的数据,还是字节流,更高兴了OxO,OwO
反序列化流程介绍
反序列化需要的包:
from snippets.models import Snippet
from snippets.serializers import SnippetSerializer
from rest_framework.parsers import JSONParser
这三个包已经导入了,这边也只是提一嘴
当数据从前端传回的时候,我们想要对其进行反序列化的时候,按照下面的步骤:
# 由于前端传回的数据也是一个字节流的json格式的数据,我们反序列化的时候的相关操作就直接对上文的content进行操作吧,懒得使用前端真实传递一个数据过来了。OwO
# 首先,我们将一个流解析为 Python 原生数据类型
import io
stream = io.BytesIO(content)
# 此时stream 的类型就变成了<_io.BytesIO object at 0x00000244EAB1D2B0>python的原生字节流的类型
# 再使用JSONParser().parse,将python原生字节流转化为字典,也是字典化
data = JSONParser().parse(stream)
# 此时data是:{'id': 2, 'title': '', 'code': 'print("hello, world")\n', 'linenos': False, 'language': 'python', 'style': 'friendly'}
# 然后,我们将这些本机数据类型还原到完全填充的对象实例中。记住是有data=这个键的
serializer = SnippetSerializer(data=data)
# 验证功能,就是将这个数据与我们传入的参数参数做验证,检测数据是否可靠,可靠的话就进行下面的操作
serializer.is_valid()
# True
# 可靠的话就如下执行
serializer.validated_data
# OrderedDict([('title', ''), ('code', 'print("hello, world")\n'), ('linenos', False), ('language', 'python'), ('style', 'friendly')])
#注意这边是新增,采用save的话,是直接新增,看上面的orderedDict就可得,没有id这个属性,原因之后再进行分析吧
serializer.save()
# <Snippet: Snippet object>
也可以序列化查询结果集(querysets)而不是单个模型实例,也就是同时序列化多个对象。只需要为serializer添加一个 标志。(这个功能是比较重要的)
serializer = SnippetSerializer(Snippet.objects.all(), many=True)
这里需要注意的是,我们在save之前不能使用serializer.data去查看内部的值是什么,如果使用save将不会成功(报错:AssertionError: You cannot call .save() after accessing serializer.data.If you need to access data before committing to the database then inspect ‘serializer.validated_data’ instead.
)
继承 ModelSerializers
前面我们写的的 类中重复了很多包含在 模型类(model)中的信息。如果能自动生成这些内容,像Django的 那样就更好了。事实上RESTframework的 类就是这么一个类,它会根据指向的model,自动生成默认的字段和简单的create及update方法。
可以拿这个去替代上文的一大串东西
class SnippetSerializer(serializers.ModelSerializer):
class Meta:
model = Snippet
fields = ['id', 'title', 'code', 'linenos', 'language', 'style']
但实际上更多使用的 确是serialzer,可能就是ModelSerializer做的还是不够好吧,有些些许的鸡肋。
序列化程序 搭配 常规的 Django 视图
打开 snippets/views.py 文件,加入一些新的内容。
包含的包:
from django.http import HttpResponse, JsonResponse
from django.views.decorators.csrf import csrf_exempt
from rest_framework.parsers import JSONParser
from snippets.models import Snippet
from snippets.serializers import SnippetSerializer
并写入下面的代码:
下面这段代码就充分展示了RESTful的设计思想。搭配着路由进行理解理解。
# 这边的csrf装饰器就是为了避免出现跨域问题而进行设置的。
@csrf_exempt
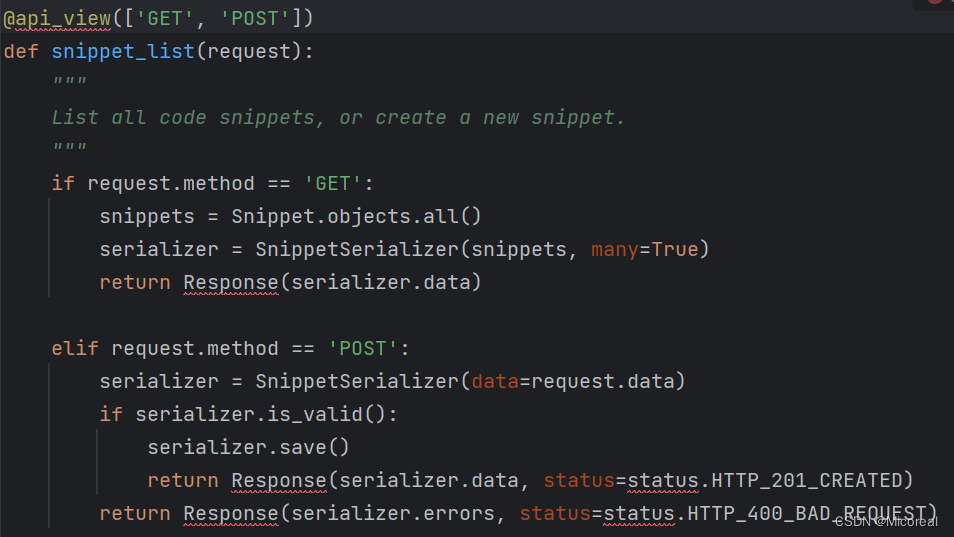
def snippet_list(request):
"""
List all code snippets, or create a new snippet.
"""
if request.method == 'GET':
snippets = Snippet.objects.all()
serializer = SnippetSerializer(snippets, many=True)
return JsonResponse(serializer.data, safe=False)
elif request.method == 'POST':
data = JSONParser().parse(request)
serializer = SnippetSerializer(data=data)
if serializer.is_valid():
serializer.save()
return JsonResponse(serializer.data, status=201)
return JsonResponse(serializer.errors, status=400)
@csrf_exempt
def snippet_detail(request, pk):
"""
Retrieve, update or delete a code snippet.
"""
try:
snippet = Snippet.objects.get(pk=pk)
except Snippet.DoesNotExist:
return HttpResponse(status=404)
if request.method == 'GET':
serializer = SnippetSerializer(snippet)
return JsonResponse(serializer.data)
elif request.method == 'PUT':
data = JSONParser().parse(request)
serializer = SnippetSerializer(snippet, data=data)
if serializer.is_valid():
serializer.save()
return JsonResponse(serializer.data)
return JsonResponse(serializer.errors, status=400)
elif request.method == 'DELETE':
snippet.delete()
return HttpResponse(status=204)
然后,我们需要将这些view方法连接起来。创建 snippets/urls.py 文件。
from django.urls import path
from snippets import views
urlpatterns = [
path('snippets/', views.snippet_list),
path('snippets/<int:pk>/', views.snippet_detail),
]
然后在最外部的 tutorial/urls.py 文件中连接根 urlconf,以包含我们的代码段应用的 URL。
from django.urls import path, include
urlpatterns = [
path('', include('snippets.urls')),
]
值得注意的是,我们目前没有正确处理一些边缘情况。如果我们发送格式错误,或者如果使用视图无法处理的方法发出请求 json ,那么我们最终将得到 500 “服务器错误”响应。不过,方便学习,就这样子了。
模拟发包 及 了解drf的web-api
第一种GET请求:
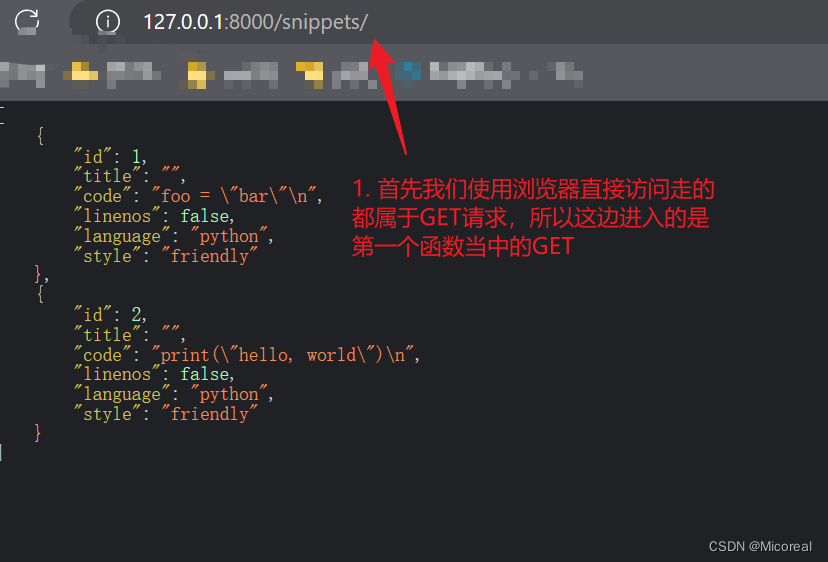
第二种GET请求:
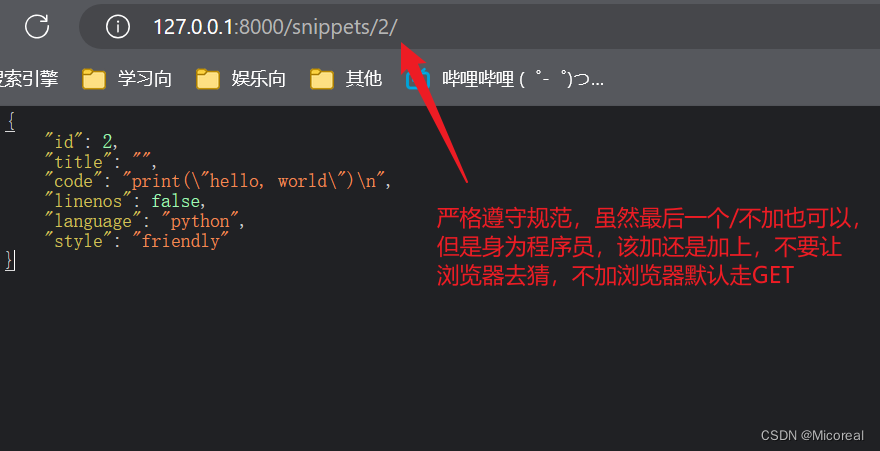
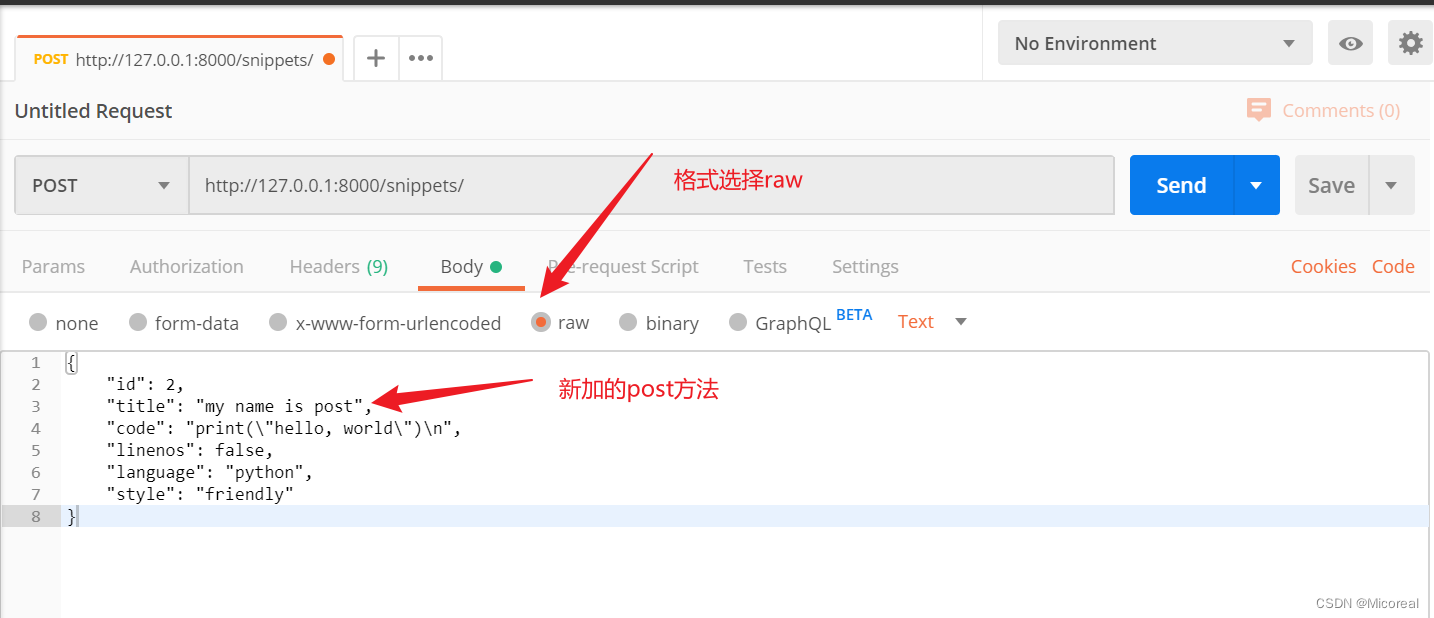
然后模拟发包,这边采用的是Postman软件。这边就不再进行介绍:
post方法(因为前端提交的表单也仅仅只能一个一个提交,所以对应到restful当中就只有一个):
到数据库当中查看:

这边值得关注的是我们不是填写了id为2吗?为什么数据库生成出来的数据id是5呢,这边跟前文说到过的read_only相关,后面再细说,先按下不表。
第三种:PUT请求,也就是想要对数据进行修改,此时需要指定id。
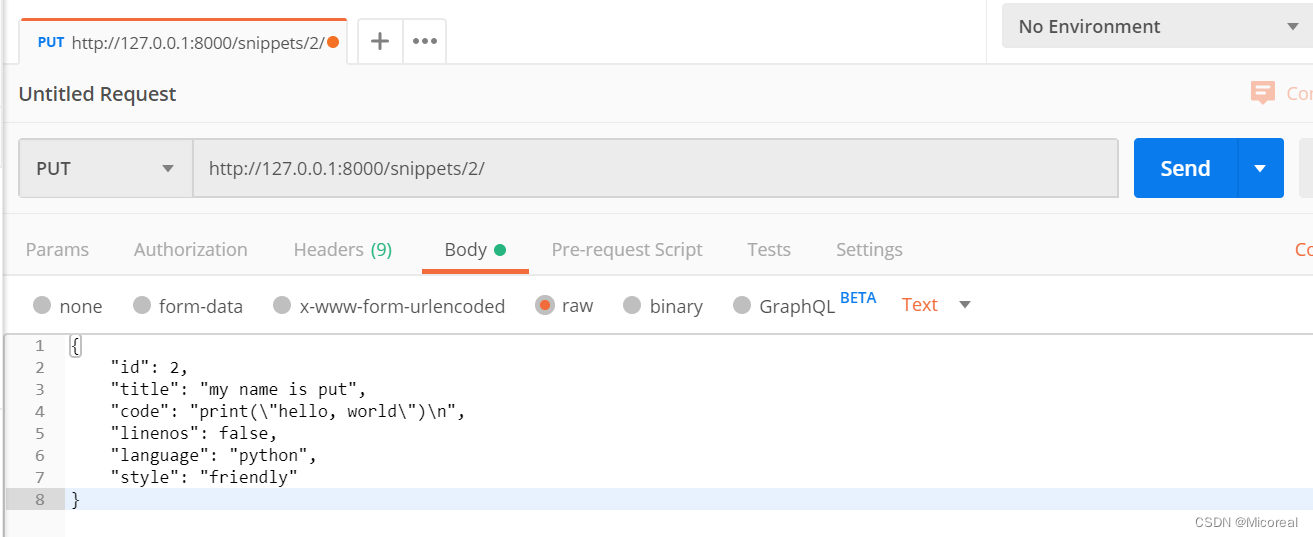
数据库:

第四种:删除操作只需要指定编号即可。
数据库下的内容:

其实这里面还有很多细节,就留在后面讲解,此篇文章,先让大家有个大概的整体框架的思路。
Requests and Responses
前提:
- REST框架引入了一个 Request 扩展常规 HttpRequest 的对象,并提供了更灵活的请求解析。 Request 对象的核心功能是 request.data 属性,它类似于request.POST ,但对于使用 Web API 更有用。
- REST 框架还引入了一个 Response 对象,该对象采用 TemplateResponse 未呈现的内容并使用内容协商来确定要返回给客户端的正确内容类型。(这句话不理解先不用看,记住内容协商,后面再回来看)
- 而对于状态码的要求上:REST 框架为每个状态代码提供了更明确的标识符,例如 HTTP_400_BAD_REQUEST 在 status 模块中。最好始终使用这些标识符,而不是使用数字标识符。
- REST 框架提供了两个可用于编写 API 视图的包装器。基于函数视图的@api_view 装饰器 ,以及基于类视图的 APIView 类。这个类实现了一部分可视化前端的模拟GET PUT POST DELETE的操作以及 在适当时返回 405 Method Not Allowed 响应,以及处理使用格式错误的输入进行访问 request.data 时发生的任何 ParseError 异常。
经过上面的部分简介后,我们就可以将view的代码进行相关的修改,变成:
from rest_framework import status
from rest_framework.decorators import api_view
from rest_framework.response import Response
from snippets.models import Snippet
from snippets.serializers import SnippetSerializer
# Create your views here.
@api_view(['GET', 'POST'])
def snippet_list(request):
"""
List all code snippets, or create a new snippet.
"""
if request.method == 'GET':
snippets = Snippet.objects.all()
serializer = SnippetSerializer(snippets, many=True)
return Response(serializer.data)
elif request.method == 'POST':
serializer = SnippetSerializer(data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
@api_view(['GET', 'PUT', 'DELETE'])
def snippet_detail(request, pk):
"""
Retrieve, update or delete a code snippet.
"""
try:
snippet = Snippet.objects.get(pk=pk)
except Snippet.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
if request.method == 'GET':
serializer = SnippetSerializer(snippet)
return Response(serializer.data)
elif request.method == 'PUT':
serializer = SnippetSerializer(snippet, data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
elif request.method == 'DELETE':
snippet.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
这边通过红线给大家稍微看看修改了什么?实际上也就是基于上面说的那些前提的
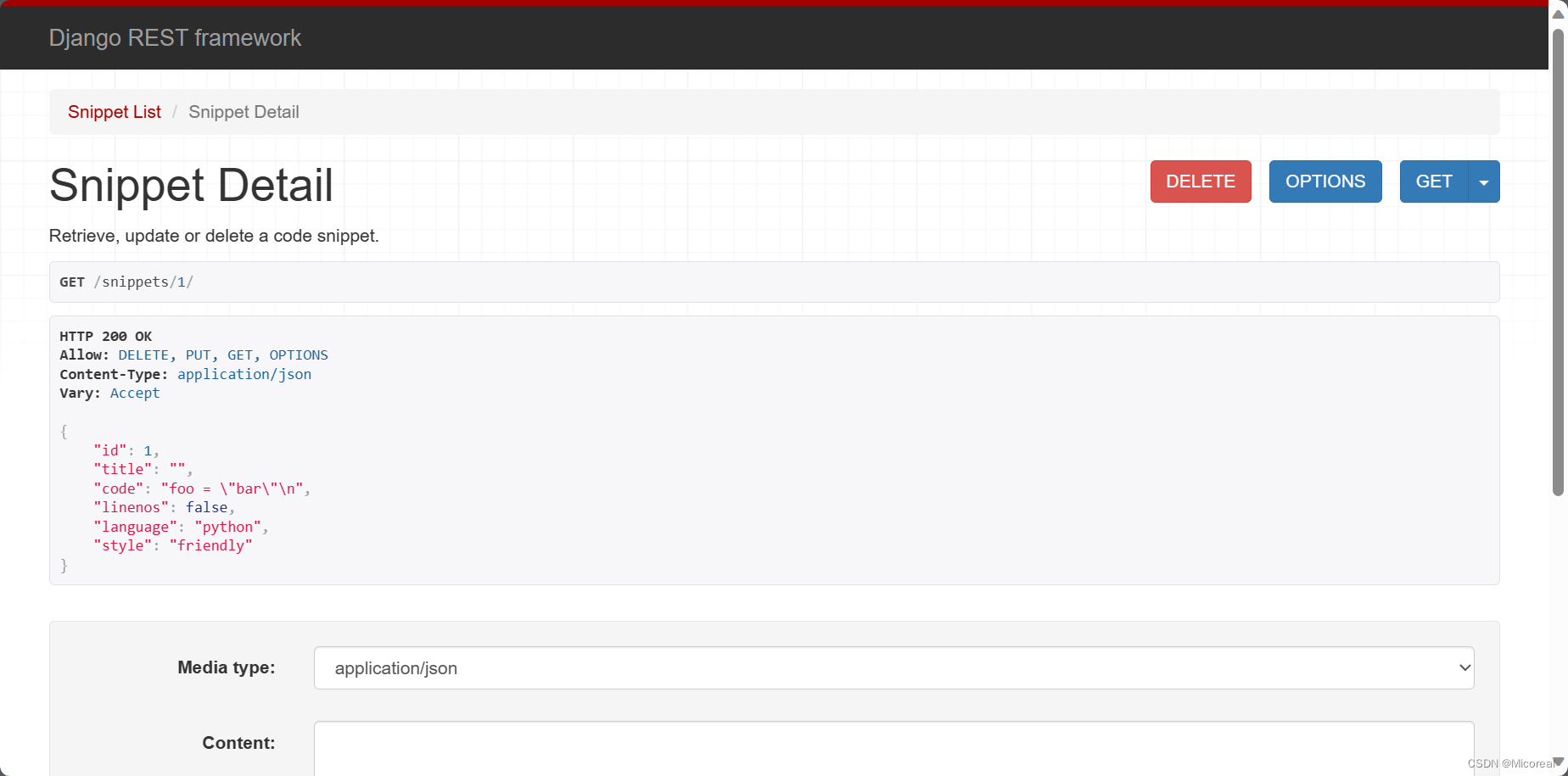
此时我们再输入网址进行查看,就能看到一个由drf提供的前端可视化的操作,可以模拟发送那些GET,POST,等等
为我们的 URL 添加可选的格式后缀
为 URL 添加可选的格式后缀有什么用?这样做可以让我们明确指定想要的响应数据的格式,例如 JSON 或 HTML。这样我们的 API 就可以处理不同格式的URL,而不再与单一内容类型绑定。
例如,如果我们想要获取一个项目的 JSON 格式的数据,我们可以使用这样的URL:http://example.com/api/items/4.json1。
具体的操作就是:
首先向两个视图添加一个 format 关键字参数,如下所示。
def snippet_list(request, format=None):
def snippet_detail(request, pk, format=None):
然后更新 snippets/urls.py 文件,以附加一组 除了 format_suffix_patterns 现有 URL。
from django.urls import path
from rest_framework.urlpatterns import format_suffix_patterns
from snippets import views
urlpatterns = [
path('snippets/', views.snippet_list),
path('snippets/<int:pk>/', views.snippet_detail),
]
urlpatterns = format_suffix_patterns(urlpatterns)
注意上面最后一句代码,它的意思是用来封装urlpatterns,这样每一个带有等后缀的url都能被正确解析。
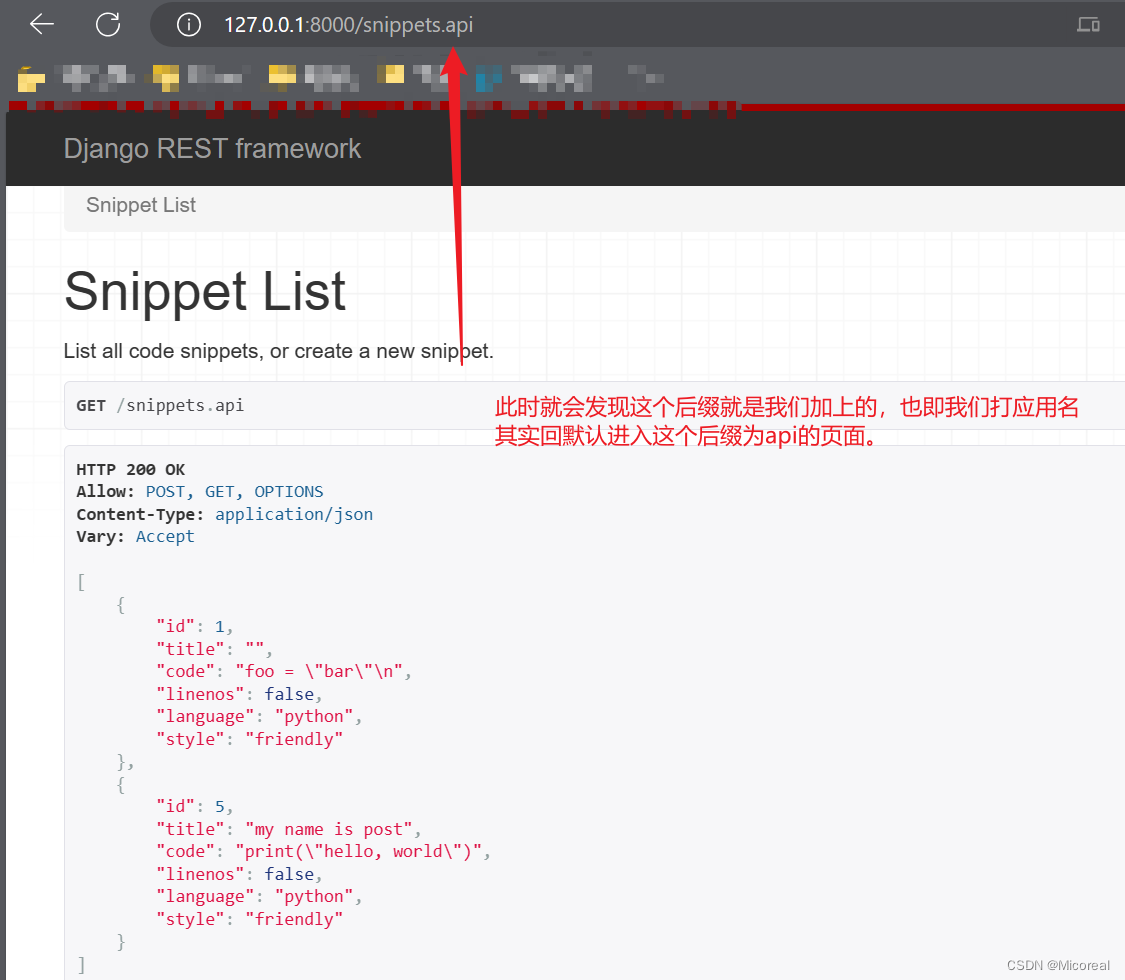
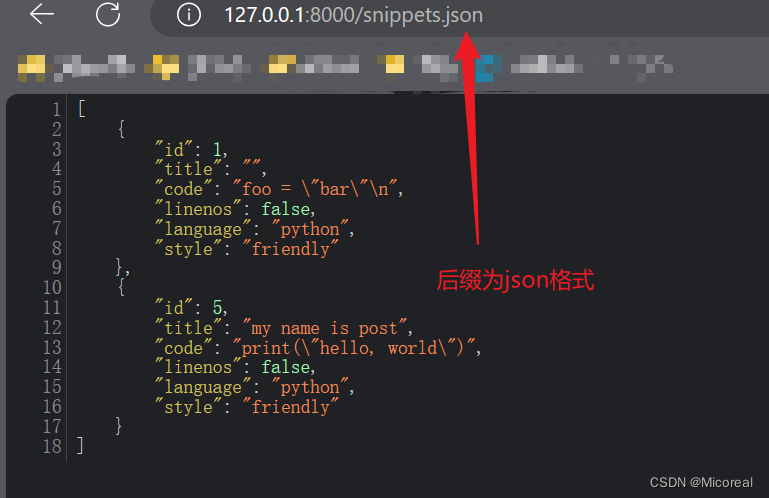
DRF的API视图会根据客户端请求的响应内容类型返回对应类型的数据,因此当Web浏览器请求snippets时,它实际请求的是HTML格式,而不是json等格式,API会按要求返回HTML格式的表示,这个过程是DRF早就写好了的,在源码中实现了的。DRF的这个功能,比较类似Django的admin后台的理念,大大降低了开发人员检查和使用API的障碍,可视化后更直接、更清晰、更便捷。
Class-based Views
我们会发现前面所使用的函数方法进行创建的视图函数,这虽然可以解决一些问题,但是我们想要让这个过程更加顺畅,更加节省代码,那我们该怎么做呢?答案就是利用切片编程的特性,做到节省代码的地步。我们一步一步节省,免得大家看不出来效果。
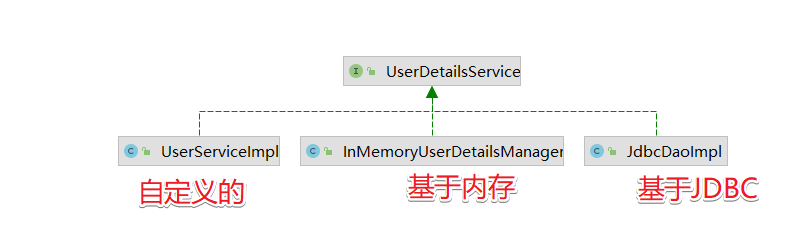
首先就是先使用类方式替代这些函数。先给大家一张图,就是类的关系继承图,给大家一个广域上的宏观的定义。

这些类都是一个一个的继承关系,在快速入门篇中先介绍其中几个,让大家了解一下基础功能,后面完整的篇章会再进行补充
先介绍这两个包:
最上面的View包,这个包是Django的view方法,原本是和form模块进行联合使用的,也就是drf框架写的基础,里面的dispatch()函数就是实现的基础(只是借鉴),实际上drf在APIView类当中进行重写了View方法(get/post识别的重点,这边先提一嘴,等等提到了,我们会截出源码进行讲解)
而APIView就是Drf的最基础的一个继承View的一个子类,Drf之后所有的类属性都是基于这一个类的,我们逐层进行剖析。
先更新一下view:
from django.http import Http404
from rest_framework import status
from rest_framework.response import Response
from rest_framework.views import APIView
from snippets.models import Snippet
from snippets.serializers import SnippetSerializer
# Create your views here.
class SnippetList(APIView):
"""
List all snippets, or create a new snippet.
"""
def get(self, request, format=None):
snippets = Snippet.objects.all()
serializer = SnippetSerializer(snippets, many=True)
return Response(serializer.data)
def post(self, request, format=None):
# 新增的话不需要传入实例
serializer = SnippetSerializer(data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
class SnippetDetail(APIView):
"""
Retrieve, update or delete a snippet instance.
"""
def get_object(self, pk):
try:
return Snippet.objects.get(pk=pk)
except Snippet.DoesNotExist:
raise Http404
def get(self, request, pk, format=None):
snippet = self.get_object(pk)
serializer = SnippetSerializer(snippet)
return Response(serializer.data)
def put(self, request, pk, format=None):
snippet = self.get_object(pk)
# 修改时需要传入实例 注意和上面的post的区别
serializer = SnippetSerializer(snippet, data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
def delete(self, request, pk, format=None):
snippet = self.get_object(pk)
snippet.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
跟之前的代码进行对比,大概有下面几种变化:
- 就是我们将原本的if method==''GET"等一系列判断变成了get这样子的一个函数,然后我们在外部调用网页的时候,传入了一个Get方法,就会自动跳入这个函数,那么至于怎么跳入的,就跟urls相关,等等下面介绍。
- 还有就是原本的 异常判断也被封装到了一个新的函数当中去了,def get_object(self, pk),这个方法也仅仅只是定义用的,不然都要复制粘贴四次,麻烦。
urls也需要进行更新,改成调用类对象的as_view()方法:
from django.urls import path
from rest_framework.urlpatterns import format_suffix_patterns
from snippets import views
urlpatterns = [
path('snippets/', views.SnippetList.as_view()),
path('snippets/<int:pk>/', views.SnippetDetail.as_view()),
]
urlpatterns = format_suffix_patterns(urlpatterns)
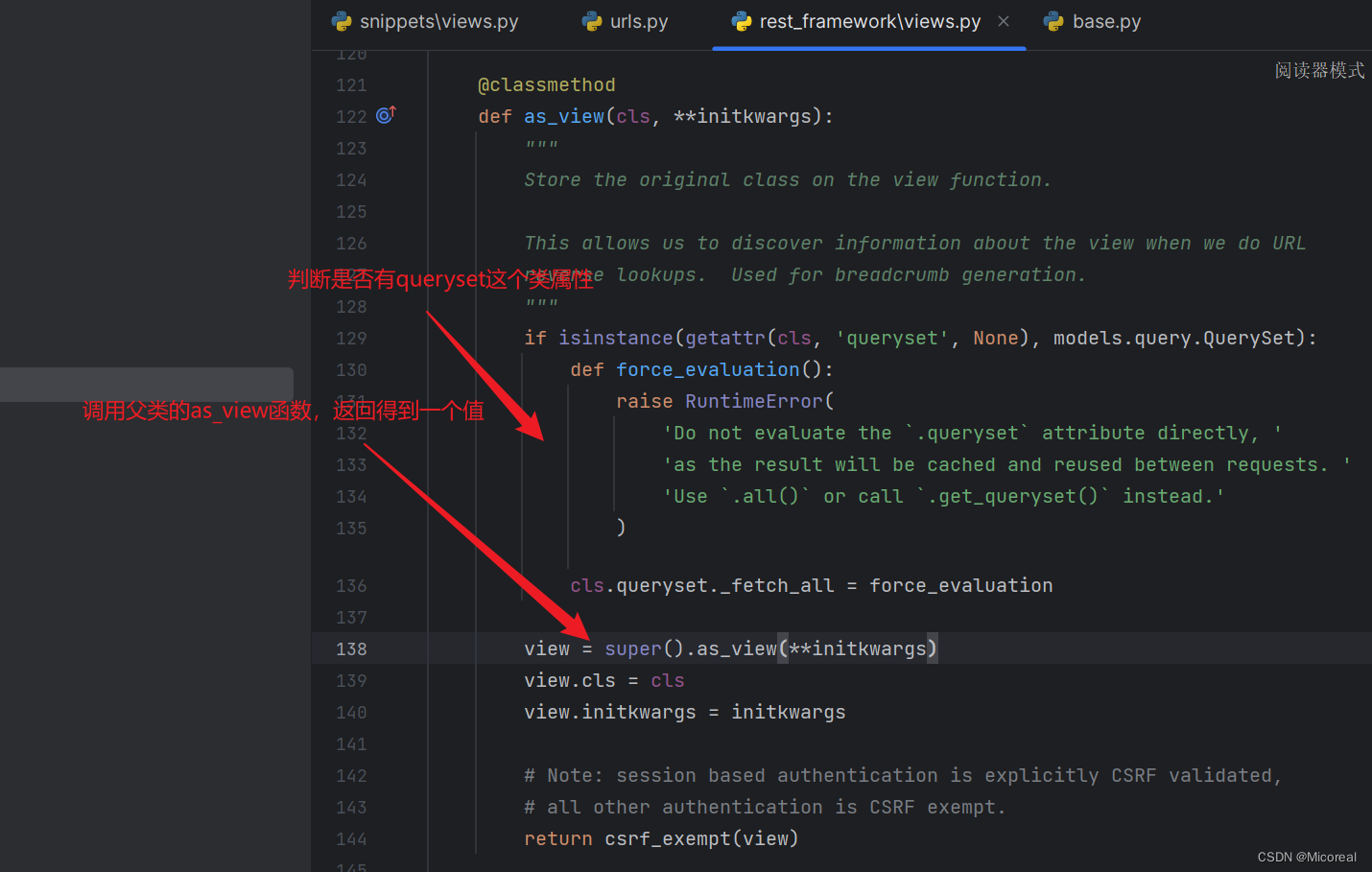
这边就需要重点注意as_view()函数了(注意这边是带逗号的,这边会将我们实际的url传回),这边就需要看下面的源码,不感兴趣的直接跳即可,我将相关的源码截出。
首先就是:我们的SnippetDetail自定义的函数明显是没有as_view属性的,所以就是父类所写的,我们就去父类APIView当中查看相关代码。
现在就需要进入View当中进行查看:
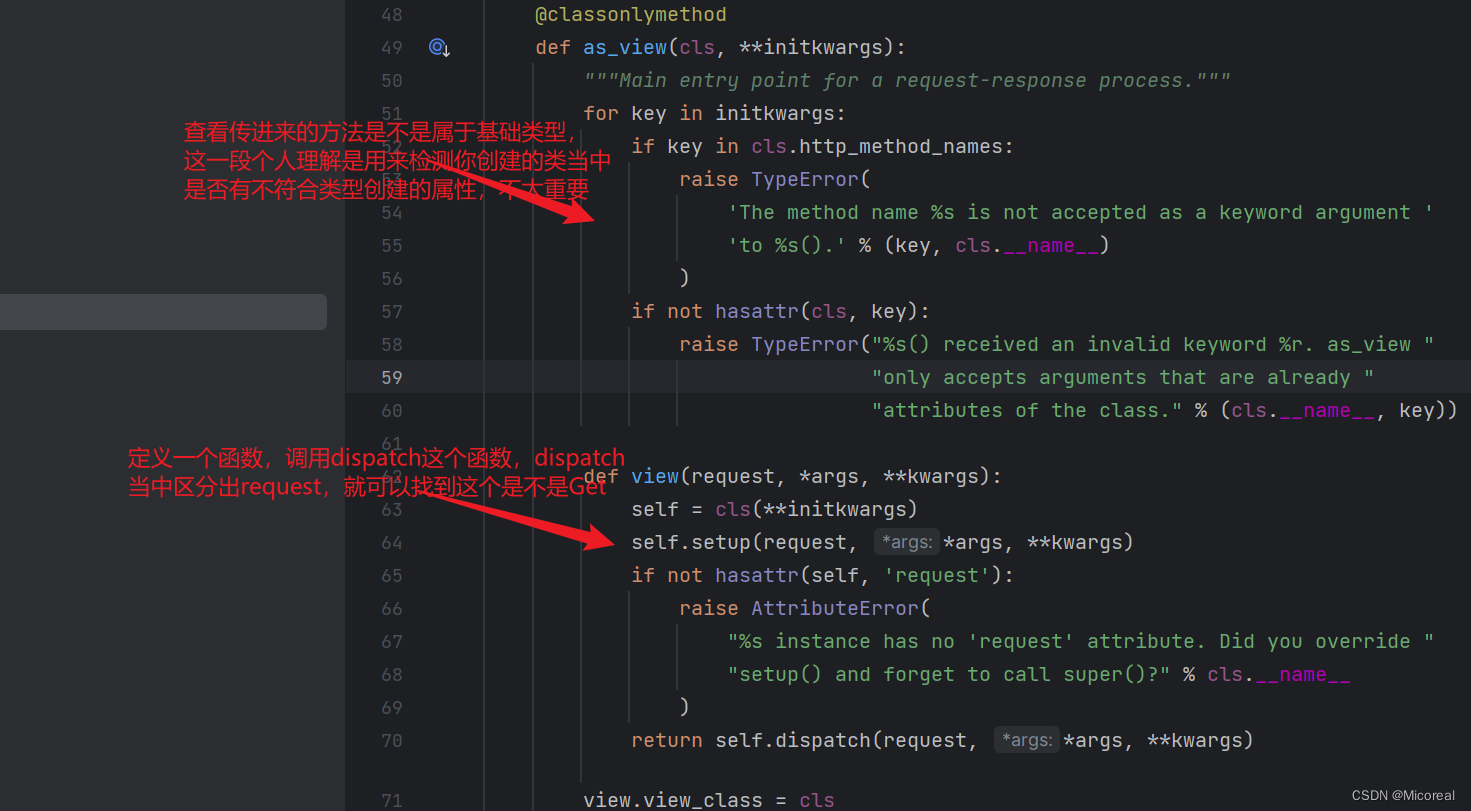
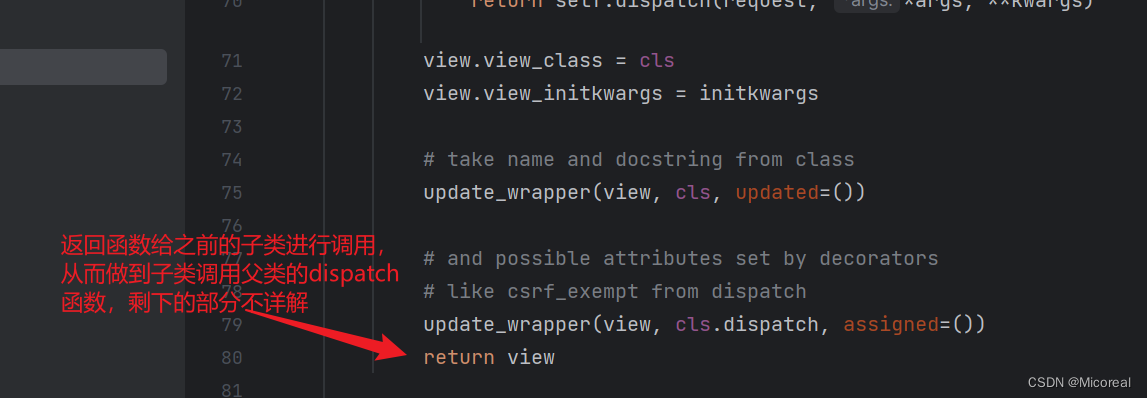
但是这边值得关注的是,调用的真实是父类的dispatch吗?不是的,是子类的dispatch,在类属性当中创建的时候已经做到了覆盖,这边实际上取到的知识一个dispatch名字,不然想象一个情况,当父类有一个类属性dispatch,子类也有一个类属性dispatch,两个不是明显重复了吗?明显会将子类的dispatch类属性对于父类的dispatch进行覆盖。
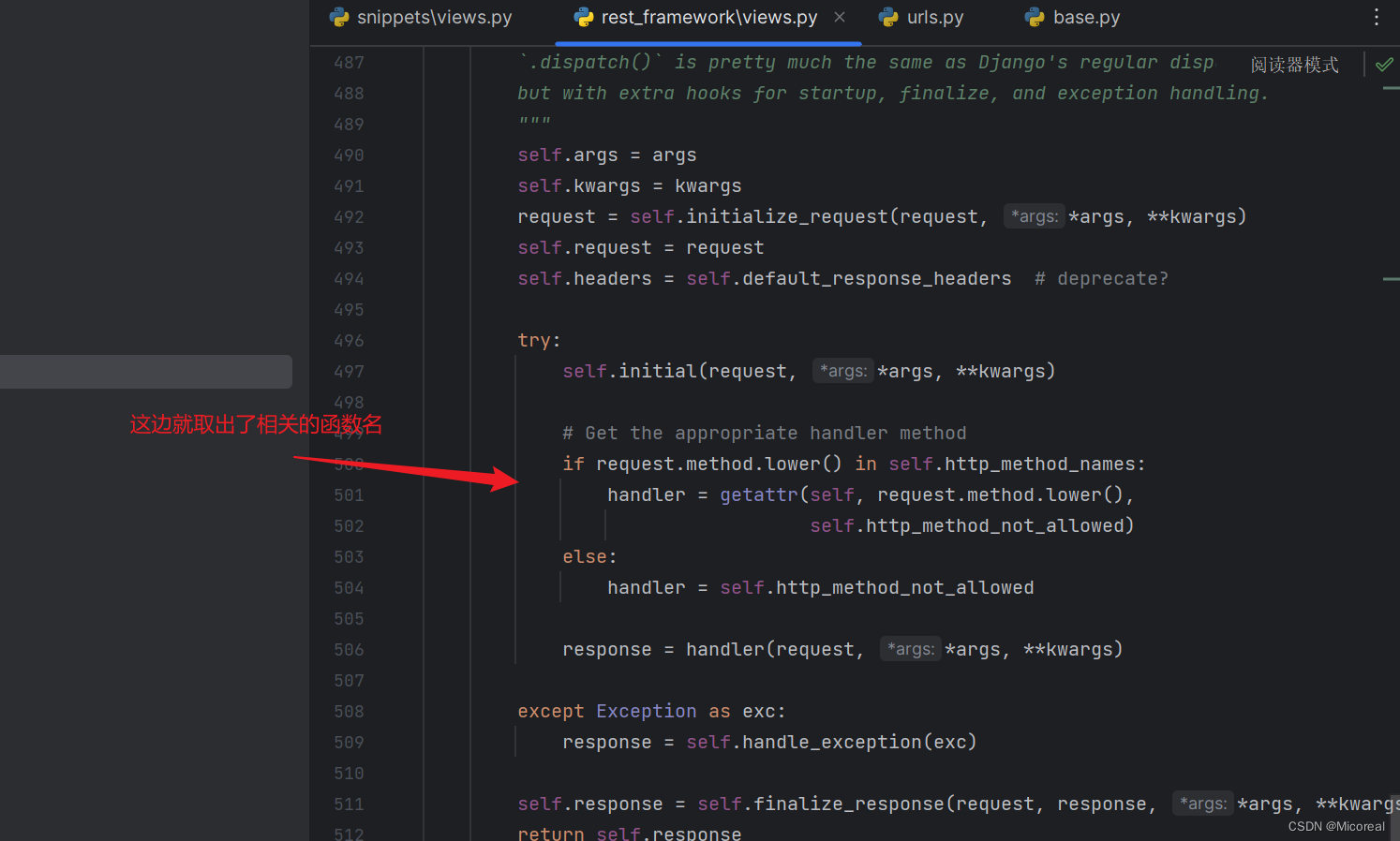
这边对于这些方法都进行了小写处理,也即我们的函数名称也需要写成小写的,才能进行匹配
总之,as_view做到的就是区分出到底是什么对应的函数进行调用的。
经过上面的操作之后,我们的视图还是原本的样子,这说明APIView没有任何的样式更新doge,QwQ,除非我没看出来
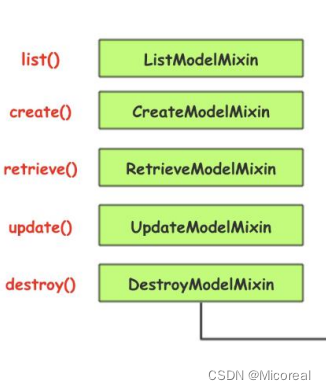
使用mixins
首先mixins类是什么,或者讲中文,混合类是什么?就是下面这五个
我们看看上面代码的场景:

所以如下应用混合类:
from snippets.models import Snippet
from snippets.serializers import SnippetSerializer
from rest_framework import mixins
from rest_framework import generics
class SnippetList(mixins.ListModelMixin,
mixins.CreateModelMixin,
generics.GenericAPIView):
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
class SnippetDetail(mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
mixins.DestroyModelMixin,
generics.GenericAPIView):
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
注意点:
- 现在开始使用GenericAPIView创建类了,GenericAPIView是APIView的直属子类,详细见上面的图。
- 此时我们在原本的函数中调用混合类当中的类函数,就可以得到相关的方法,这边简单介绍一下对照表:
| RESTful方法 | 对应 | mixins包名 |
|---|---|---|
| GET /Cars/ | list() | mixins.ListModelMixin |
| POST /Cars/ | create() | mixins.CreateModelMixin |
| GET /Cars/1/ | retrieve() | mixins.RetrieveModelMixin |
| PUT /Cars/1/ | update() | mixins.UpdateModelMixin |
| DELETE /Cars/1/ | destory() | mixins.DestroyModelMixin |
运行开:
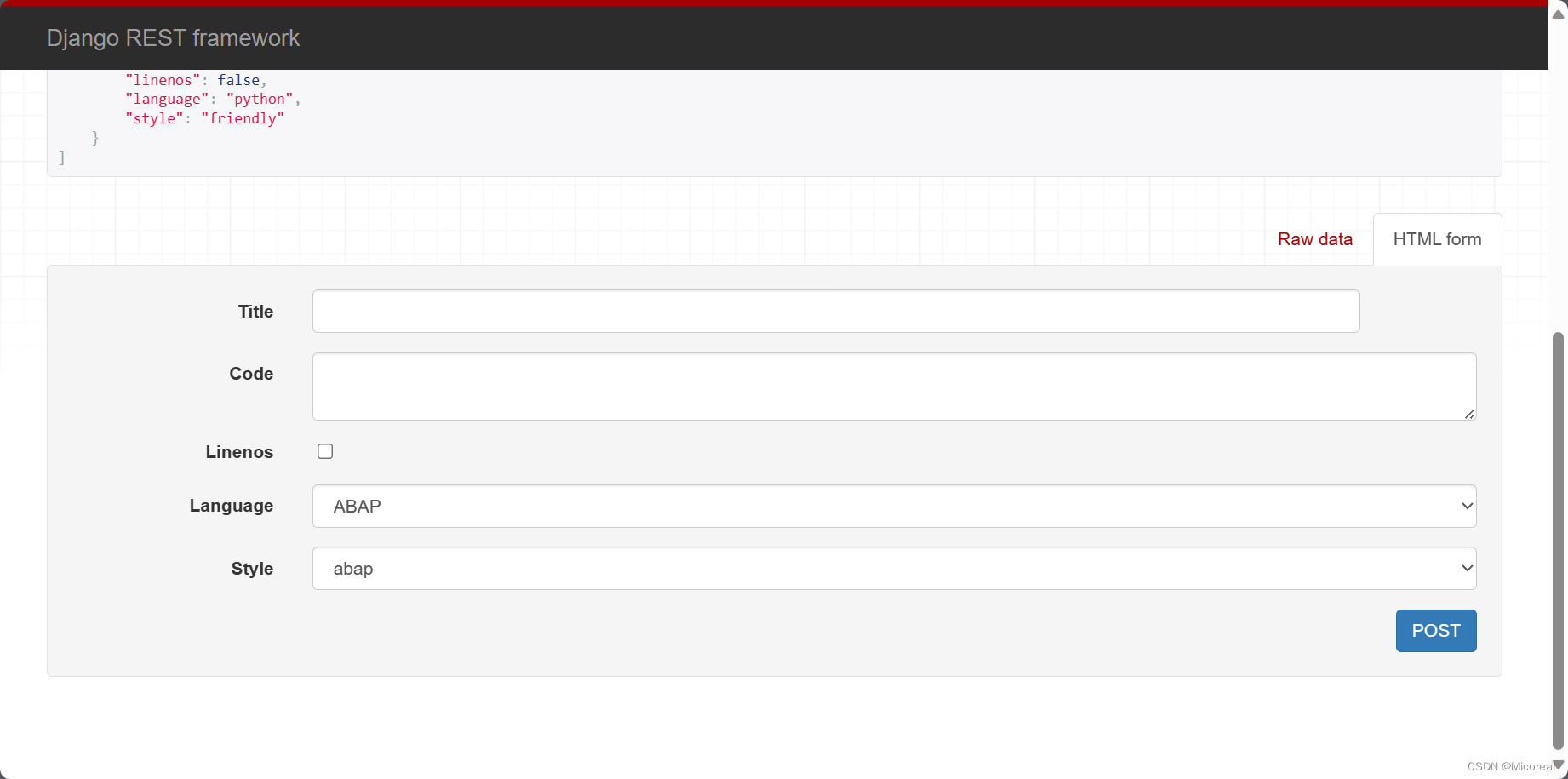
惊奇的发现前端页面发生了变化,可以得到GenericAPIView这个子类做到了这个功能,做到了不在只能原始数据输入的效果。
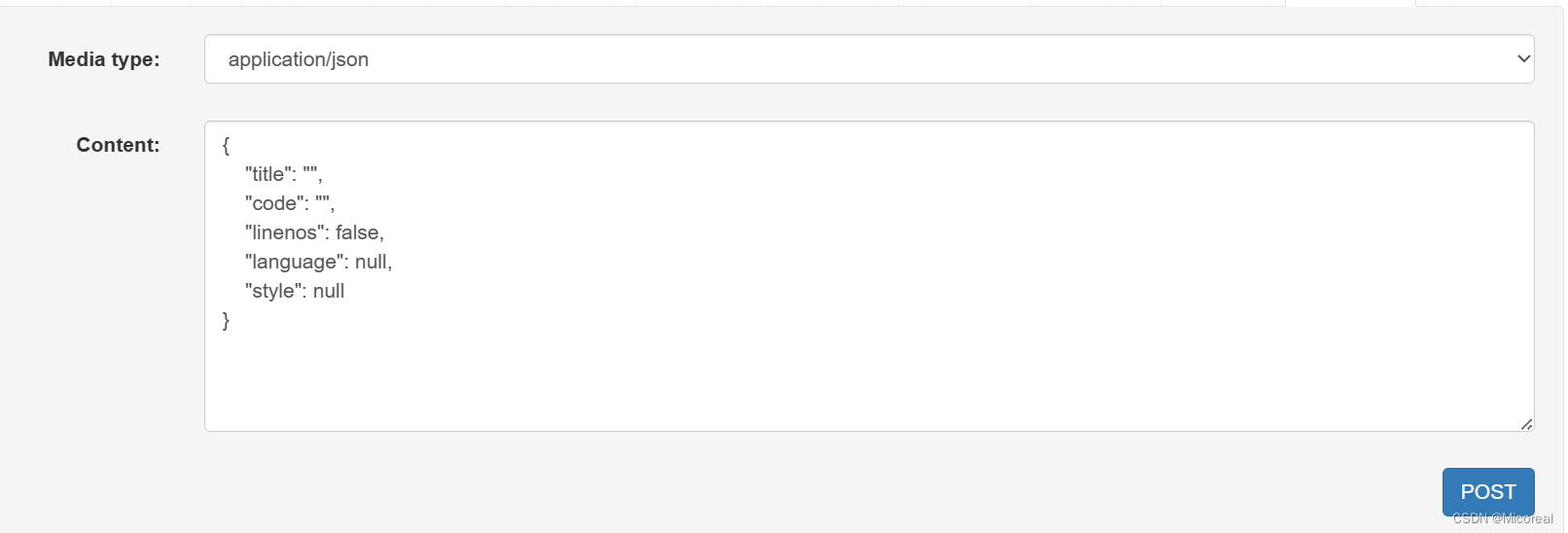
post,put,delete原理一致都留了perform的这个接口,留给我们自己进行重写。
小的总结:
- 混合类省去了我们自己编写从模型类中查询示例数据,并序列化。
- GenericAPIView相比于APIView额外做了get_querset 和 get_serializer ,然后这两个部分需要我们声明到我们自定义的view方法当中,在view当中先定义上querset,应当等于我们要查的那张表的全体内容,(也可以过滤掉一部分),然后再serializer应当声明成我们之前定义的类。
- 多了GenericAPIView之后,多了上面写的那个框,测试方便。
使用基于类的通用视图
但是有的时候,我们觉得这样也不行,天天都要写def get,def post,很麻烦,我还想省略,当然可以,这个时候轮到了:
from snippets.models import Snippet
from snippets.serializers import SnippetSerializer
from rest_framework import generics
# 因为这个类中用到了list 和 create 所以叫list create APIView
class SnippetList(generics.ListCreateAPIView):
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
# 和上面同理
class SnippetDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
我们可以看看这个类的设计:
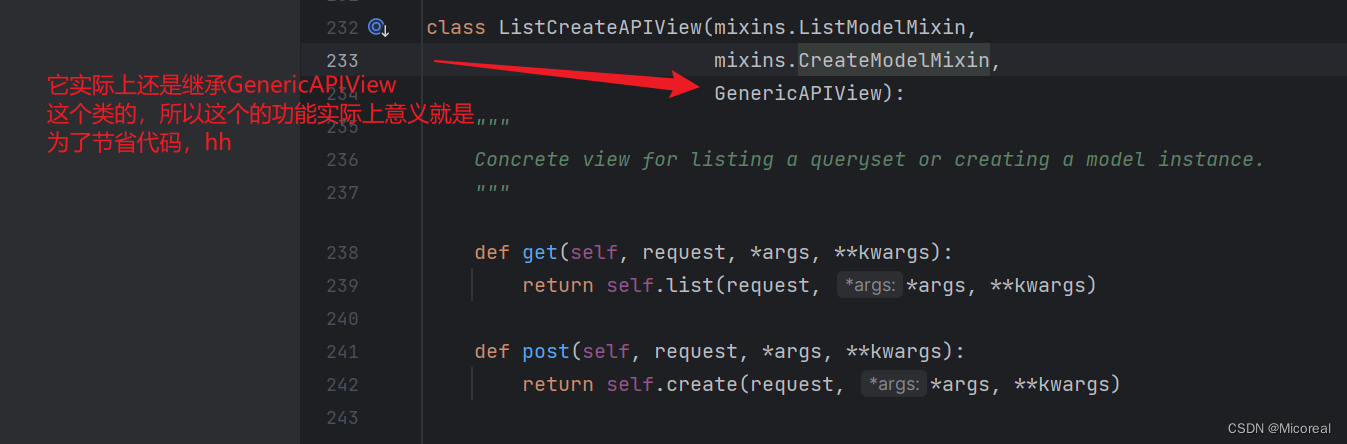
剩下部分其实和我们的那些都一样。
Authentication & Permissions
目前,我们的 API 对谁可以编辑或删除代码片段没有任何限制。我们希望有一些更高级的行为,以确保:
- 代码片段始终与创建者相关联。
- 只有经过身份验证的用户才能创建代码段。
- 只有代码段的创建者才能更新或删除它。
- 未经身份验证的请求应具有完全只读访问权限。
准备工作
首先就是对 Snippet 模型类进行一些更改。首先,让我们添加几个字段。其中一个字段将用于表示创建代码段的用户。另一个字段将用于存储代码的突出显示的 HTML 表示形式(也就是之前的那个高亮部分的使用,等之后看效果再进行理解吧)。
将以下两个字段添加到 中的 Snippet models.py 模型。
owner = models.ForeignKey('auth.User', related_name='snippets', on_delete=models.CASCADE)
highlighted = models.TextField()
这边有一个需要注意的就是auth.User实际上是Django框架自动生成的用于表示登录用户的表,他实际上也是一个应用,是auth应用下的User类。
然后就是跟着操作,也是几个跟高亮部分相关的操作,等后面进行理解:
需要补充额外的包:
from pygments.lexers import get_lexer_by_name
from pygments.formatters.html import HtmlFormatter
from pygments import highlight
我们还需要确保在保存模型时,使用 pygments 代码突出显示库填充突出显示的字段,原本如果没有定义save这个方法,调用的就是默认的save方法,这边采用了重写。
def save(self, *args, **kwargs):
"""
Use the `pygments` library to create a highlighted HTML
representation of the code snippet.
"""
lexer = get_lexer_by_name(self.language)
linenos = 'table' if self.linenos else False
options = {'title': self.title} if self.title else {}
formatter = HtmlFormatter(style=self.style, linenos=linenos,
full=True, **options)
self.highlighted = highlight(self.code, lexer, formatter)
super().save(*args, **kwargs)
完成所有这些操作后,我们需要更新数据库表。通常,我们会创建一个数据库迁移来执行此操作,但出于本教程的目的,让我们删除数据库并重新开始。
这边直接删库操作简便(开删跑路)
rm -f db.sqlite3
rm -r snippets/migrations
python manage.py makemigrations snippets
python manage.py migrate
然后就是创建相关的用户,和以前一样的操作:
python manage.py createsuperuser
我这边创建几个用户,仅供测试(admin,A,B):
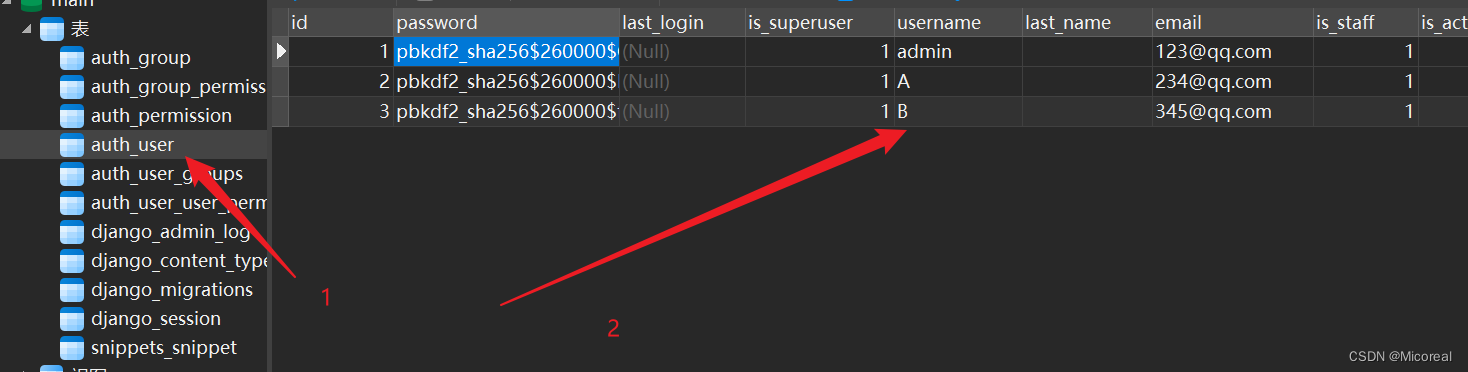
还记得我们之前的那个外键绑定的是auth.user吗?实际上绑定的就是这张表。
现在我们已经有一些用户可以使用,我们最好将这些用户的表示添加到我们的 API 中。创建新的序列化程序很容易。在 serializers.py 添加:
from django.contrib.auth.models import User
class UserSerializer(serializers.ModelSerializer):
snippets = serializers.PrimaryKeyRelatedField(many=True, queryset=Snippet.objects.all())
class Meta:
model = User
fields = ['id', 'username', 'snippets']
因为snippets字段在用户模型中是一个反向外键关系。什么意思呢?就是我们表只有在snippet那张表当中又user的id,但在snippets当中没有对应的snippets的字段,所以在使用该类时它默认不会被包含,所以我们需要为它添加一个显式字段。然后就可以使用serializers.PrimaryKeyRelatedField来指定获得关联自己主键的数据,然后内部需要指定相关的参数:many就是当引出来的值不止一个,queryset就是你需要去遍历查询的对象的user。
我们还将向 添加 views.py 几个视图。我们只想对用户表示使用只读视图,因此我们将使用 ListAPIView 和 RetrieveAPIView 类的通用视图。
from django.contrib.auth.models import User
from snippets.serializers import UserSerializer
class UserList(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
class UserDetail(generics.RetrieveAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
最后,我们需要通过从 URL conf 引用这些视图来将这些视图添加到 API 中。将以下内容添加到 中的 snippets/urls.py
path('users/', views.UserList.as_view()),
path('users/<int:pk>/', views.UserDetail.as_view()),
进行了上述的操作之后呢?我们想要新增Snippet的时候,已经不能新增了,为什么呢?原因就是:还记得我们再snippet当中绑定了一个外键,外键绑定的对象是user,但是我们原本的新增数据的时候没有填写user,导致新增有问题。
解决办法:
在视图类上 SnippetList ,添加以下方法(具体原理上文有源码剖析):
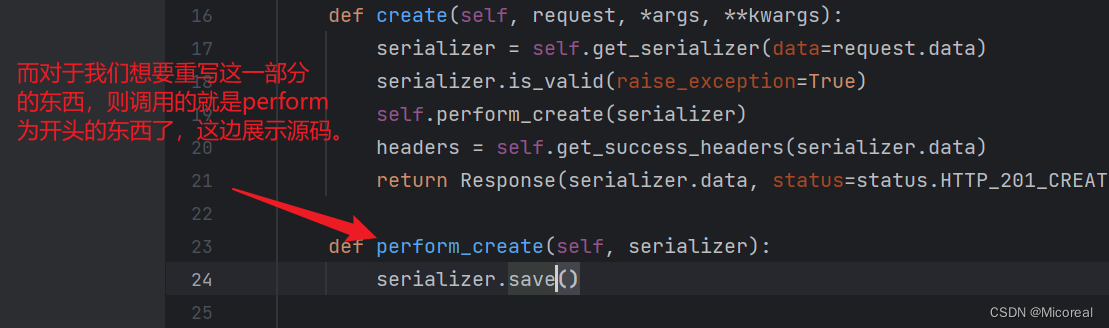
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
源码剖析:
然后我们继续看这一个字段是什么?为什么要这么写呢?原因就是我们SnippetSerializer中没有这个字段,我们SnippetSerializer当中放的数据实际上是会显示到前端页面上的,也就是新增需要填写的内容,但我们明显不希望编写人还要用户去写上自己的名字,那我们就需要通过重写perform_create方法,然后其中去调用对应的save,并传入需要增加的键值对,然后他的序列化就会通过字典解包拼接进行完成:
在Baseserializer 当中会出现那个对应的save,他通过这个方法进行拼接。

然后就是将我们的SnippetSerializer 这个类换成如下的代码:
class SnippetSerializer(serializers.Serializer):
"""
继承Serializer类的话,传送给前端的数据取决于下面的数据,至于参数后面再进行介绍。
"""
id = serializers.IntegerField(read_only=True)
title = serializers.CharField(required=False, allow_blank=True, max_length=100)
code = serializers.CharField(style={'base_template': 'textarea.html'})
linenos = serializers.BooleanField(required=False)
language = serializers.ChoiceField(choices=LANGUAGE_CHOICES, default='python')
style = serializers.ChoiceField(choices=STYLE_CHOICES, default='friendly')
# 只加上了这一句 实际上是为了在snippet当中显示其作者是谁
owner = serializers.ReadOnlyField(source='owner.username')
def create(self, validated_data):
"""
Create and return a new `Snippet` instance, given the validated data.
"""
return Snippet.objects.create(**validated_data)
def update(self, instance, validated_data):
"""
Update and return an existing `Snippet` instance, given the validated data.
"""
instance.title = validated_data.get('title', instance.title)
instance.code = validated_data.get('code', instance.code)
instance.linenos = validated_data.get('linenos', instance.linenos)
instance.language = validated_data.get('language', instance.language)
instance.style = validated_data.get('style', instance.style)
instance.save()
return instance
或者采用继承ModelSerialzer类
但是需要在Meta当中进行注明
# 只读,也就是在post请求中不需要进行提交的数据
owner = serializers.ReadOnlyField(source='owner.username')
class Meta:
model = Snippet
fields = ['id', 'username', 'owner']
views当中添加用户权限
经过上面代码的修改,我们已经实现了在snippet表内调用user表,做一个外键的功能,并且在Snippet当中显示所关联外键(只读)的username,采用的方法就是(source=‘owner.username’),来进行显示,然后在post 或者 put修改的时候,不需要我们填写谁写的,会自动通过读取登录的用户名进行上传。
但是现在我们想要做的是做一个权限,这个权限是这段代码的拥有者只有在是他的时候,才能进行修改,或者就是只有这个人登录了,才能进行post数据,现在就需要用到了权限。
REST 框架包括许多权限类,我们可以使用这些权限类来限制谁可以访问给定视图。在下面的例子中,我们用到的是 IsAuthenticatedOrReadOnly,他的功能是只有确保经过身份验证的请求获得读写访问权限 ,而未经身份验证的请求获得只读访问权限。
先导入包
from rest_framework import permissions
然后,将以下属性添加到 SnippetList 和 SnippetDetail 视图类中都加上:
permission_classes = [permissions.IsAuthenticatedOrReadOnly]
看看源码:

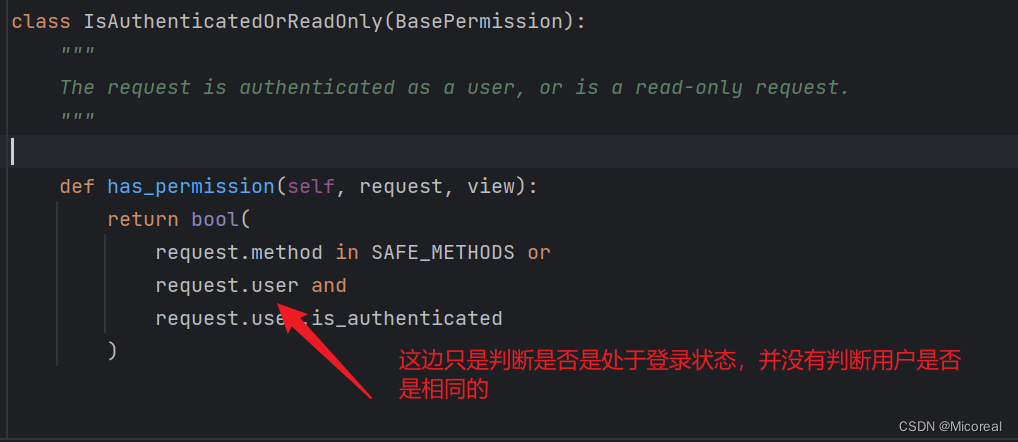
所以就有了如下图:
这个函数实际上做的事情就只是判断你是否进行登录,但是并没有进行账户检测,这就涉及到了,我们自定义的权限类。
自定义权限类-对象级权限
首先自然是:登录页面(drf的)
from django.urls import path, include
urlpatterns += [
path('api-auth/', include('rest_framework.urls')),
]
模式 ‘api-auth/’ 的一部分实际上可以是您想要使用的任何 URL。
这边就提一嘴过去了,毕竟上面讲解过了。
这边在进行重复一遍,我们上面做到了检测是否登录,登录了,才允许进行post或者put或者delete,所以这个IsAuthenticatedOrReadOnly加在两个地方。
但是我们还想要修改和delete只有本用户才能进行操作,那么我们就需要自定义权限类,流程见下:
- 在snippet(app)中,创建一个新文件, permissions.py
- 然后在这个文件中加上下面的代码:
from rest_framework import permissions
class IsOwnerOrReadOnly(permissions.BasePermission):
"""
Custom permission to only allow owners of an object to edit it.
"""
def has_object_permission(self, request, view, obj):
# Read permissions are allowed to any request,
# so we'll always allow GET, HEAD or OPTIONS requests.
if request.method in permissions.SAFE_METHODS:
return True
# Write permissions are only allowed to the owner of the snippet.
return obj.owner == request.user
这边需要进行补充一点,我们这边是自己写的权限类需要继承permissions.BasePermission这个父类权限,然后内部的方法的重写也具有一定的深意。 def has_object_permission(self, request, view, obj): 这个类主要用于detail的类的使用,因为他是有具体的obj的,就是我们/snippet/1/的那个id为1的obj,会传入进去。而相对之下的def has_permission(self, request, view):就是list的用法。
- 现在,我们可以通过编辑 SnippetDetail 视图类上的 permission_classes 属性将该自定义权限添加到代码段实例终结点:
permission_classes = [permissions.IsAuthenticatedOrReadOnly,IsOwnerOrReadOnly]
使用API进行身份验证
现在因为我们在API上设置了权限,如果我们要编辑某个代码片段,我们都需要验证请求是否认证了。我们还没有设置任何身份验证类,所以应用的是默认的SessionAuthentication和BasicAuthentication这两个认证类,这个我们现在比较有印象的肯定就是前者,一看就是Session,之后非快速入门处会在进行讲解,这边先有个印象。
当我们通过Web浏览器与API进行交互时,我们可以登录,然后浏览器会话将为请求提供所需的身份验证,也就是我们上面的操作过程。
如果我们在代码中与API交互,则需要在每次请求上显式地提供身份验证凭据。如果我们没有经过身份验证就尝试创建一个代码片段,就会像下面展示的那样收到错误提示:
http POST http://127.0.0.1:8000/snippets/ code="print(123)"
{
"detail": "Authentication credentials were not provided."
}
http -a admin:password123 POST http://127.0.0.1:8000/snippets/ code="print(789)"
{
"id": 1,
"owner": "admin",
"title": "foo",
"code": "print(789)",
"linenos": false,
"language": "python",
"style": "friendly"
}
Relationships & Hyperlinked APIs
对于这边的讲解:这边先抛出一个引子:
我们发现我们在访问最初始的页面的时候,竟然会是这样子的,那么我们怎么去将之修改呢?也就是我们访问比如www.qq.com的时候内部会有很多的超链接,指向其指定域名的子url当中,那么我们该怎么去进行相关的修改呢?
为我们的 API 根创建终端节点
现在我们有“代码段”和“用户”的端点,但我们没有一个 API 的入口点。为了创建一个,我们将使用基于函数的常规视图和我们之前介绍的 @api_view 装饰器。在您的 snippets/views.py 添加中:
from rest_framework.decorators import api_view
from rest_framework.response import Response
from rest_framework.reverse import reverse
@api_view(['GET'])
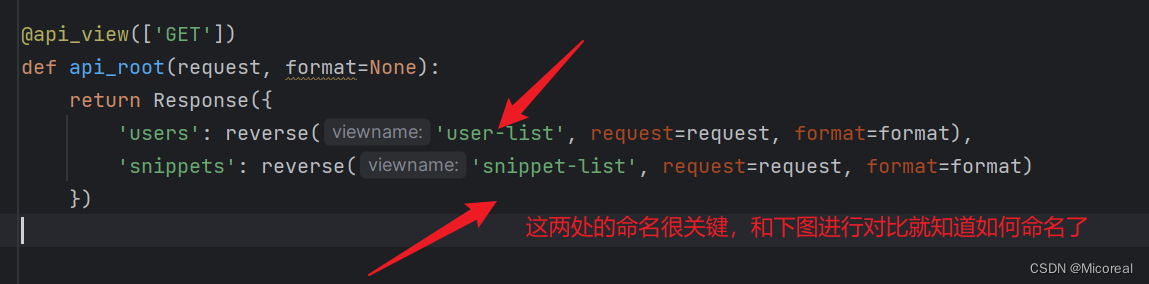
def api_root(request, format=None):
return Response({
'users': reverse('user-list', request=request, format=format),
'snippets': reverse('snippet-list', request=request, format=format)
})
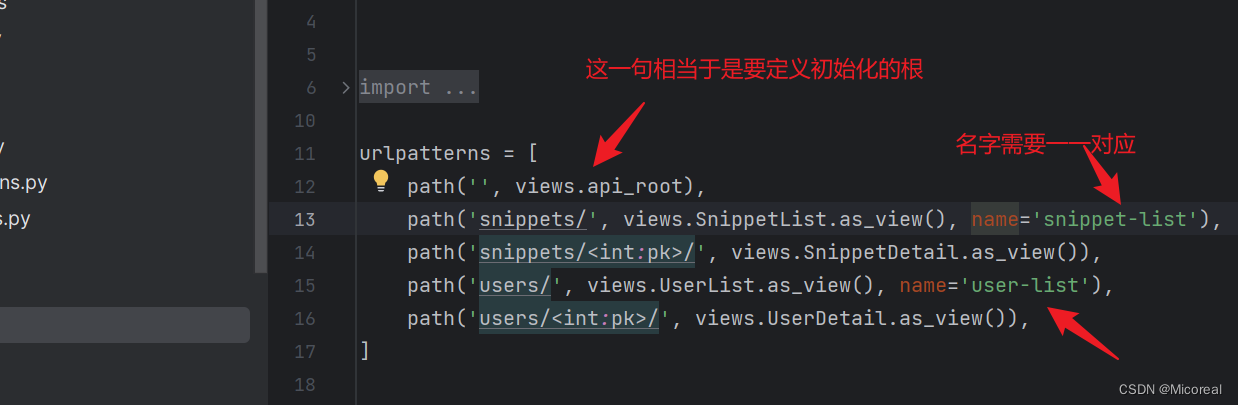
然后在snippets/urls中添加:
urlpatterns = [
path('', views.api_root),
path('snippets/', views.SnippetList.as_view(), name='snippet-list'),
path('snippets/<int:pk>/', views.SnippetDetail.as_view()),
path('users/', views.UserList.as_view(), name='user-list'),
path('users/<int:pk>/', views.UserDetail.as_view()),
]
然后这边实际上使用的就是后端的反向解析,不过reverse使用的是rest_framework的reverse 这是值得关注的东西。
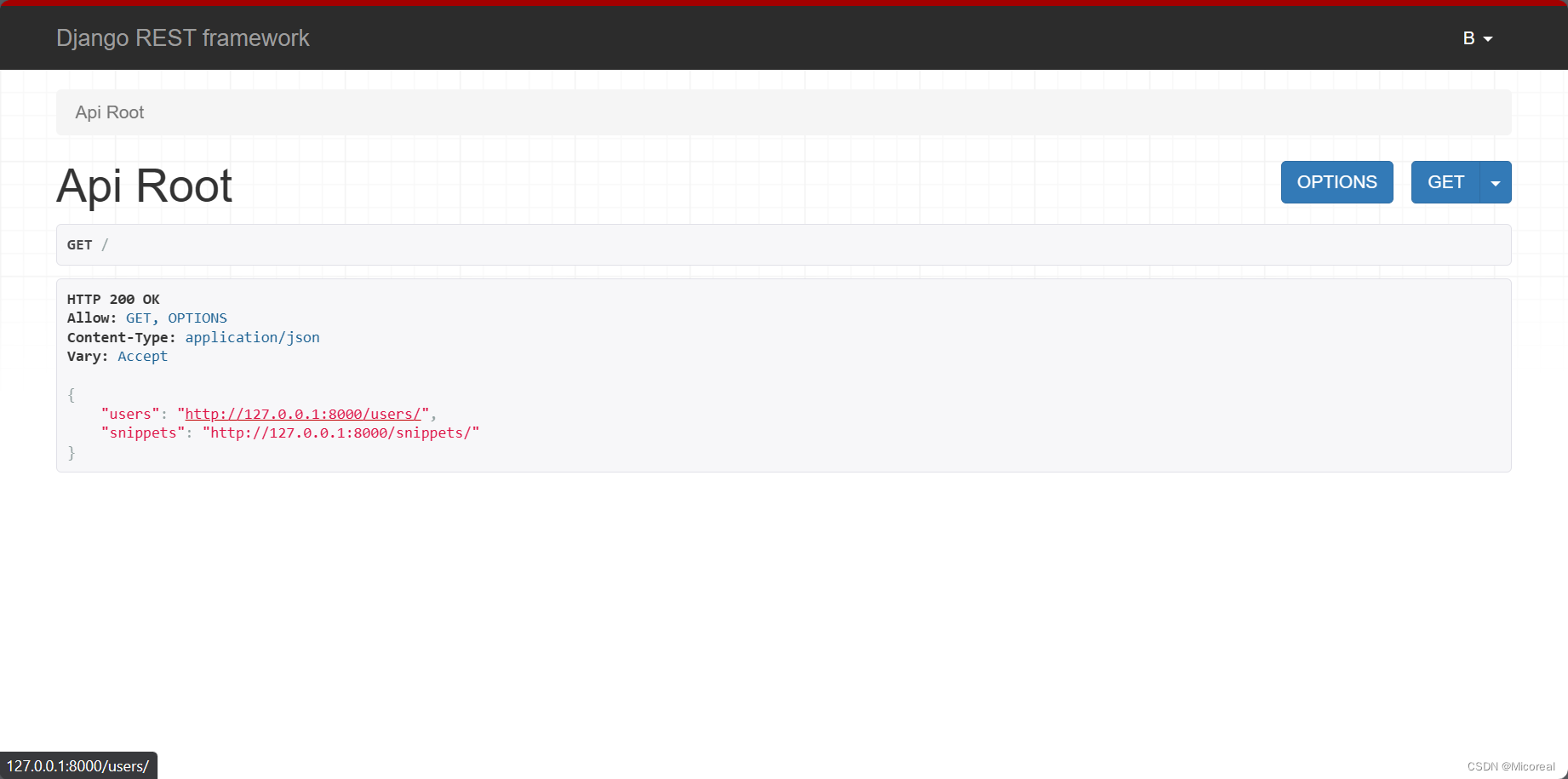
呈现的效果:
http://127.0.0.1:8000/
为突出显示的代码段创建终结点,只显示ORM对象的部分内容
创建代码突出显示视图时需要考虑的另一件事是,没有可以使用的现有具体通用视图。我们不返回对象实例,而是返回对象实例的属性。
我们将使用基类来表示实例,并创建自己的 .get() 方法,而不是使用具体的泛型视图。在您的 snippets/views.py 添加中:
from rest_framework import renderers
class SnippetHighlight(generics.GenericAPIView):
queryset = Snippet.objects.all()
renderer_classes = [renderers.StaticHTMLRenderer]
def get(self, request, *args, **kwargs):
snippet = self.get_object()
return Response(snippet.highlighted)
然后为代码段突出显示添加网址模式:
path('snippets/<int:pk>/highlight/', views.SnippetHighlight.as_view()),
超链接我们的 API
在本例中,我们希望在实体之间使用超链接样式。为此,我们将修改序列化程序以扩展 HyperlinkedModelSerializer 而不是现有的 ModelSerializer ,也即添加上超链接
我们可以轻松地重写现有的序列化程序以使用超链接。在您的snippets/serializers.py 添加中:
class SnippetSerializer(serializers.HyperlinkedModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
highlight = serializers.HyperlinkedIdentityField(view_name='snippet-highlight', format='html')
class Meta:
model = Snippet
fields = ['url', 'id', 'highlight', 'owner',
'title', 'code', 'linenos', 'language', 'style']
class UserSerializer(serializers.HyperlinkedModelSerializer):
snippets = serializers.HyperlinkedRelatedField(many=True, view_name='snippet-detail', read_only=True)
class Meta:
model = User
fields = ['url', 'id', 'username', 'snippets']
请注意,我们还添加了一个新 ‘highlight’ 字段。此字段与 url 字段的类型相同,只是它指向 url 模式,而不是 ‘snippet-highlight’ ‘snippet-detail’ url 模式
然后此时的url应该变成:
from django.urls import path
from rest_framework.urlpatterns import format_suffix_patterns
from snippets import views
# API endpoints
urlpatterns = format_suffix_patterns([
path('', views.api_root),
path('snippets/',
views.SnippetList.as_view(),
name='snippet-list'),
path('snippets/<int:pk>/',
views.SnippetDetail.as_view(),
name='snippet-detail'),
path('snippets/<int:pk>/highlight/',
views.SnippetHighlight.as_view(),
name='snippet-highlight'),
path('users/',
views.UserList.as_view(),
name='user-list'),
path('users/<int:pk>/',
views.UserDetail.as_view(),
name='user-detail')
])
效果图示:

小的总结:
- field当中的url,实际上是自动生成的,他是来源于HyperlinkedModelSerializer类当中的,点击他自动跳转到详情页。
- 而我们打算自定义超链接,则是需要定义如下的字段,并指向跳转的页面。
highlight = serializers.HyperlinkedIdentityField(view_name='snippet-highlight', format='html')
- 继承HyperlinkedModelSerializer,实际上唯一的作用就是多了一个url字段,可供我们进行添加,相反的如果想自定义超链接,就需要使用上文的手法。
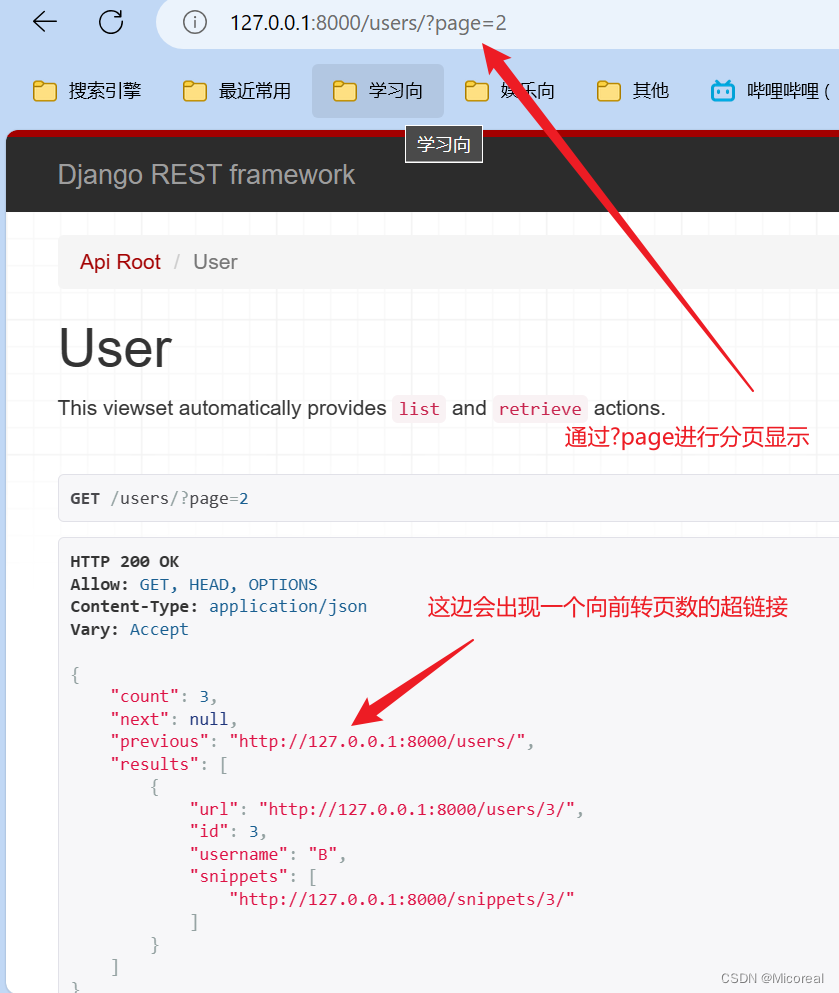
全局分页功能
我们可以通过稍微修改 tutorial/settings.py 文件来更改默认列表样式以使用分页。添加以下设置:
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 10
}
这个实际上也可以认为是一个setting,不过这边建议如果是涉及到drf的设置,都采用上面的形式,以做到区分。
效果:
ViewSets & Routers
再把图搬下来,这边终于到了要使用modelViewSet了,首先他继承了那五个混合类,以及新的没见过的GenericViewSet这个类,那这个类做了什么呢?这个类的继承顺序是(ViewSetMixin,GenericAPIView),而ViewSetMixin类当中重写了一个更为强大的as_view(),根据MRO原则,如果我们继承的是ModelViewSet,那么在使用as_view的时候,最后使用的就是ViewSetMixin这个类的as_view()。
使用视图集
现在有一个问题,就是我们在写一个页面的时候需要写至少两遍这个网页的view,也就是至少分为snippet_list 和 snippet_detail这两个class 是不是很烦,那么有没有一种办法可以直接综合起来呢?只写一个类就能做到最后的实现,这个问题就是最新的as_view发明的原因:
首先,让我们将我们的 UserList 和 UserDetail 视图重构为一个 UserViewSet .我们可以删除这两个视图,并用单个类替换它们:
from rest_framework import viewsets
class UserViewSet(viewsets.ReadOnlyModelViewSet):
"""
This viewset automatically provides `list` and `retrieve` actions.
"""
queryset = User.objects.all()
serializer_class = UserSerializer
直接拿一个类去替换两个类:
原本的:
class UserList(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
class UserDetail(generics.RetrieveAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
在这里,我们使用 ReadOnlyModelViewSet 类自动提供默认的“只读”操作。我们仍然像使用常规视图时一样设置 queryset and serializer_class 属性,但我们不再需要向两个单独的类提供相同的信息。
接下来,我们将替换 SnippetList 和 SnippetDetail SnippetHighlight 视图类。我们可以删除这三个视图,然后再次将它们替换为单个类
from rest_framework.decorators import action
from rest_framework.response import Response
from rest_framework import permissions
class SnippetViewSet(viewsets.ModelViewSet):
"""
This viewset automatically provides `list`, `create`, `retrieve`,
`update` and `destroy` actions.
Additionally we also provide an extra `highlight` action.
"""
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly,
IsOwnerOrReadOnly]
@action(detail=True, renderer_classes=[renderers.StaticHTMLRenderer])
def highlight(self, request, *args, **kwargs):
snippet = self.get_object()
return Response(snippet.highlighted)
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
原本的:
class SnippetList(generics.ListCreateAPIView):
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly]
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class SnippetDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly, IsOwnerOrReadOnly]
class SnippetHighlight(generics.GenericAPIView):
queryset = Snippet.objects.all()
# serializer_class 这边不指定序列化对象,如果制定了序列化对象,那么显示的就是序列化对象所写的数据了
renderer_classes = [renderers.StaticHTMLRenderer] # 渲染器,这边相当于讲输入的数据转化为html格式
def get(self, request, *args, **kwargs):
snippet = self.get_object()
return Response(snippet.highlighted)
是不是很清爽,相比之下:这次我们使用了该 ModelViewSet 类来获取完整的默认读写操作集。
请注意,我们还使用修饰器创建了一个 @action 名为 highlight .此装饰器可用于添加任何不适合标准 create / / update delete 样式的自定义终结点。默认情况下,使用 @action 修饰器的自定义操作将响应 GET 请求。如果我们想要响应 POST 请求的操作,我们可以使用该 methods 参数。
而在文件中, snippets/urls.py 我们将类 ViewSet 显示绑定到一组具体视图中,这边一看很麻烦,但是实际上这边只是为了让我们理解,实际的操作并不是如此,但是这边为了方便理解,就多这么一步。
然后就是进行显式的展示url当中映射关系:
from django.urls import path
from rest_framework import renderers
from rest_framework.urlpatterns import format_suffix_patterns
from snippets.views import SnippetViewSet, UserViewSet, api_root
snippet_list = SnippetViewSet.as_view({
'get': 'list',
'post': 'create'
})
snippet_detail = SnippetViewSet.as_view({
'get': 'retrieve',
'put': 'update',
'patch': 'partial_update',
'delete': 'destroy'
})
snippet_highlight = SnippetViewSet.as_view({
'get': 'highlight'
}, renderer_classes=[renderers.StaticHTMLRenderer])
user_list = UserViewSet.as_view({
'get': 'list'
})
user_detail = UserViewSet.as_view({
'get': 'retrieve'
})
urlpatterns = [
path('', api_root),
path('snippets/', snippet_list, name='snippet-list'),
path('snippets/<int:pk>/', snippet_detail, name='snippet-detail'),
path('snippets/<int:pk>/highlight/', snippet_highlight, name='snippet-highlight'),
path('users/', user_list, name='user-list'),
path('users/<int:pk>/', user_detail, name='user-detail')
]
urlpatterns = format_suffix_patterns(urlpatterns)
实际上就是自定义一个字典,字典当中存在着这些键值对,最后就会使用新式as_view进行转接。
使用路由器
但是这个时候还是很烦,虽然节省了view视图中只需要写一个类就可以执行一个相对应的页面,但是却增加了url的代码,这听起来只是拆东墙补西墙,但是明显框架不会那么呆,还可以进行省略,这就是路由的优势之处了。
因为我们使用的是 ViewSet 类而不是 View 类,所以我们实际上不需要自己设计 URL conf。将资源连接到视图和 url 的约定可以使用 Router 类自动处理。我们需要做的就是向路由器注册适当的视图集,然后让它完成剩下的工作。
from django.urls import path, include
from rest_framework.routers import DefaultRouter
from snippets import views
# Create a router and register our viewsets with it.
router = DefaultRouter()
router.register(r'snippets', views.SnippetViewSet,basename="snippet")
router.register(r'users', views.UserViewSet,basename="user")
# The API URLs are now determined automatically by the router.
urlpatterns = [
path('', include(router.urls)),
]
将视图集注册到路由器类似于提供 urlpattern。我们包括两个参数 - 视图的 URL 前缀和视图集本身。
我们使用的 DefaultRouter 类也会自动为我们创建 API 根视图,因此我们现在可以从模块 views 中删除该方法 api_root 。
视图与视图集之间的权衡
使用视图集可能是一个非常有用的抽象。它有助于确保 URL 约定在整个 API 中保持一致,最大限度地减少需要编写的代码量,并允许您专注于 API 提供的交互和表示形式,而不是 URL conf 的细节。
这并不意味着它总是正确的方法。与使用基于类的视图而不是基于函数的视图时,需要考虑一组类似的权衡。使用视图集不如单独构建视图那么明确。