1.下载mnist.pkl.gz
网址:http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz
数据集文件夹路径是data2/mnist/mnist.pkl.gz
2.读取数据
from pathlib import Path
import matplotlib.pyplot as plt
DATA_PATH=Path("./data2")
PATH=DATA_PATH / "mnist"
FILENAME="mnist.pkl.gz"
import pickle
import gzip
with gzip.open((PATH/FILENAME).as_posix(),"rb") as f:
((x_train,y_train),(x_valid,y_valid),_)=pickle.load(f,encoding="latin-1")
#x_train(500,784),y_train(5000,) x_valid(10000, 784),y_valid(10000,)随机显示一个数字
#==========28*28=784========随机显示数字5
import matplotlib.pyplot as plt
import numpy as np
plt.imshow(x_train[50].reshape((28,28)),cmap="gray")
plt.show() 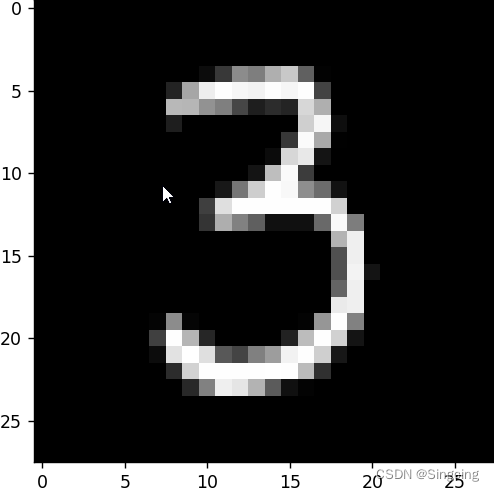
数据转为tensor
#=================数据转为tensor才能参与建模训练===
import torch
x_train,y_train,x_valid,y_valid=map(
torch.tensor, (x_train,y_train,x_valid,y_valid)
)
3.设置损失函数为交叉熵函数
#=====torch.nn.functional==========
import torch.nn.functional as F
loss_func=F.cross_entropy
4.创建Model类
from torch import nn
class Mnist_NN(nn.Module):
def __init__(self):
super().__init__()
self.hidden1=nn.Linear(784,128)
self.hidden2=nn.Linear(128,256)
self.out=nn.Linear(256,10)
self.dropout=nn.Dropout(0.5)
def forward(self,x):
x=F.relu(self.hidden1(x))
#全连接层+droput,防止过拟合
x=self.dropout(x)
x=F.relu(self.hidden2(x))
x=self.dropout(x)
x=self.out(x)
return x
# Mnist_NN(
# (hidden1): Linear(in_features=784, out_features=128, bias=True)
# (hidden2): Linear(in_features=128, out_features=256, bias=True)
# (out): Linear(in_features=256, out_features=10, bias=True)
# (dropout): Dropout(p=0.5, inplace=False)
# )
# net=Mnist_NN()
# print(net)
打印一下这网络长什么样
net=Mnist_NN()
print(net)
#打印定义好的名字和w和b
for name,parameter in net.named_parameters():
print(name,parameter,parameter.size())Mnist_NN(
(hidden1): Linear(in_features=784, out_features=128, bias=True)
(hidden2): Linear(in_features=128, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
)
hidden1.weight Parameter containing:
tensor([[-1.7000e-02, -7.5721e-03, -1.7358e-03, ..., 7.6538e-03,
7.2789e-03, -6.3162e-03],
[ 1.4825e-02, -2.8308e-02, 1.4613e-02, ..., 2.8675e-02,
-2.7759e-02, -3.0119e-03],
[ 3.0426e-02, 2.0748e-02, -3.4948e-03, ..., 3.0710e-02,
-4.2255e-03, -3.3025e-05],
...,
[-3.4821e-02, 2.9946e-02, -3.1861e-02, ..., 8.1853e-03,
-1.9938e-02, -3.3388e-02],
[-1.5154e-02, 1.3920e-02, -2.9203e-02, ..., -2.0026e-02,
-2.6470e-02, -9.5561e-03],
[-6.9892e-03, -3.8977e-03, -2.6180e-02, ..., -3.3327e-02,
-1.4922e-02, 2.6092e-02]], requires_grad=True) torch.Size([128, 784])
hidden1.bias Parameter containing:
tensor([ 2.5751e-02, -1.0377e-02, -1.3521e-02, -4.4816e-03, -2.6966e-02,
-3.4603e-02, 3.0604e-02, -3.3966e-02, 1.1005e-02, -3.7168e-03,
-1.4667e-02, -1.7566e-02, 8.6428e-03, 2.4892e-02, -6.2577e-03,
2.6498e-02, 1.8615e-02, 6.7457e-04, -2.4671e-02, 1.6848e-02,
6.7135e-03, 2.7673e-02, 3.1954e-02, 2.2302e-03, 2.4956e-02,
-2.1396e-02, 2.9394e-02, 2.7505e-02, -1.3726e-02, 2.5841e-02,
1.4209e-02, -3.2747e-02, -3.1744e-02, 2.6159e-05, 2.4203e-02,
-2.2114e-02, 1.3879e-02, 2.4030e-02, -7.9168e-03, -1.8550e-02,
9.8353e-03, -2.1257e-03, 1.7249e-02, 1.8158e-02, 1.5701e-02,
1.6851e-02, -2.2942e-02, 2.3169e-02, 9.7022e-03, -2.1426e-02,
2.8050e-02, 2.2969e-02, -2.0299e-04, -3.2873e-02, -2.4000e-02,
1.9591e-03, 1.9635e-02, 1.6035e-02, -2.4186e-02, -1.8391e-02,
1.3318e-02, -2.1707e-02, 2.6806e-02, -1.9598e-02, -2.2144e-03,
1.7189e-02, -1.2346e-02, 1.1579e-02, 2.4108e-02, -2.6332e-02,
2.8129e-02, -1.8886e-02, 2.9338e-02, -2.1488e-02, -8.8897e-03,
9.8325e-03, -1.8350e-02, -9.6284e-03, 2.0150e-03, 3.4695e-02,
1.9319e-02, -1.2755e-02, 1.7373e-02, -2.5692e-02, 1.8800e-02,
1.3602e-02, -2.5734e-02, -2.6812e-02, -2.8780e-02, -2.3088e-02,
-1.7497e-02, 1.5619e-02, -7.5968e-03, 4.3703e-03, -3.9508e-03,
-4.1538e-03, -2.2634e-02, 1.5959e-02, 2.6492e-02, -3.2042e-02,
2.9527e-02, 2.5412e-02, 2.3659e-02, 9.8108e-03, -2.7806e-02,
2.0003e-02, -1.2184e-02, -2.9596e-03, 8.7161e-03, -1.5629e-02,
1.2305e-03, 2.0794e-02, 2.7004e-03, 2.8585e-02, 2.5467e-02,
2.1072e-02, 7.3987e-03, 2.4267e-02, -2.6038e-03, 2.7078e-02,
1.9574e-02, -1.9452e-02, 2.6705e-02, -3.5053e-02, -2.1770e-02,
-1.0504e-02, -2.6949e-02, -1.3683e-02], requires_grad=True) torch.Size([128])
hidden2.weight Parameter containing:
tensor([[-0.0092, -0.0385, 0.0392, ..., 0.0202, -0.0780, -0.0181],
[-0.0694, 0.0047, -0.0097, ..., 0.0494, -0.0311, 0.0568],
[-0.0330, 0.0872, 0.0196, ..., 0.0530, -0.0158, -0.0122],
...,
[ 0.0671, -0.0538, -0.0228, ..., 0.0426, -0.0721, -0.0875],
[-0.0818, 0.0811, 0.0181, ..., -0.0633, 0.0213, 0.0622],
[ 0.0037, -0.0460, -0.0352, ..., 0.0280, 0.0473, -0.0177]],
requires_grad=True) torch.Size([256, 128])
hidden2.bias Parameter containing:
tensor([ 7.0455e-03, -8.5585e-02, -1.1738e-02, 5.0009e-02, 4.9168e-02,
1.2480e-02, -3.5337e-02, -7.6582e-02, -6.2093e-02, -8.1431e-02,
-8.3769e-02, -5.0416e-02, -4.2006e-03, -3.1598e-02, -2.1332e-02,
3.0044e-02, -5.9326e-02, -5.5279e-03, 1.4245e-02, 5.6438e-02,
4.9253e-02, 8.3465e-02, 5.6813e-02, -6.5503e-02, 3.8796e-02,
-2.2497e-02, 1.6275e-02, 1.7218e-02, -5.2700e-02, -5.5127e-03,
-7.7747e-02, 6.8675e-02, 1.2371e-02, 7.2901e-02, -3.3443e-02,
-8.3422e-02, 4.2207e-02, -6.0726e-03, -6.8885e-02, -2.3315e-02,
3.9463e-02, 8.1008e-02, 3.6421e-02, 1.2548e-02, 7.7355e-04,
-8.3500e-02, 8.4208e-02, 1.0381e-02, -8.2894e-02, 3.3573e-02,
7.9642e-02, 2.8607e-02, -1.0787e-02, 4.9583e-02, -5.1456e-02,
-1.9139e-02, -4.2526e-02, 9.3131e-03, 9.7653e-03, 7.5836e-02,
4.4982e-02, 3.6308e-02, -3.8912e-02, -1.0491e-02, -3.7225e-03,
1.8632e-02, -2.3825e-02, 8.6090e-02, 2.8692e-02, 6.0389e-02,
4.8401e-02, -8.3547e-02, 7.3226e-02, -8.6110e-02, -4.9497e-02,
6.2549e-02, 4.9156e-02, 8.1692e-02, 7.9723e-02, 8.1305e-02,
-3.7317e-02, -1.0242e-02, -5.4902e-03, -4.6117e-02, -5.9542e-02,
-5.7721e-04, 8.4372e-02, 5.5357e-02, -7.3170e-02, 4.5636e-02,
-1.2585e-02, 3.9466e-02, 3.7262e-02, 4.2761e-02, -4.0151e-02,
5.8672e-02, 1.3433e-02, 3.2238e-02, -2.7873e-02, 8.7917e-02,
-1.0597e-02, 2.2360e-02, 8.8234e-02, -2.3124e-02, -1.1411e-02,
-3.5525e-02, 5.5158e-02, -5.2876e-03, -6.4926e-02, 8.4380e-02,
4.8760e-02, 4.1597e-02, -4.3935e-02, -4.8510e-02, -1.8965e-02,
-3.9994e-02, 4.1508e-03, 5.2132e-02, 2.6399e-02, -6.4724e-02,
4.2482e-02, -3.6571e-03, -5.4799e-02, 6.1780e-02, -4.8077e-02,
-6.9937e-02, -8.5853e-02, 5.5176e-02, -7.5692e-02, 3.4551e-02,
3.7478e-02, -2.2803e-02, 5.2525e-02, 4.6488e-02, -7.9088e-02,
7.8011e-02, -7.3475e-02, -7.6256e-03, 4.8434e-02, 6.1110e-02,
2.1325e-03, 3.0351e-02, -5.0737e-02, 3.9619e-02, 5.5484e-02,
7.0710e-02, 1.0315e-02, 3.6087e-02, 7.9133e-02, 2.4239e-02,
1.8004e-02, 5.2432e-02, 5.0751e-02, -3.3260e-02, -8.2963e-02,
3.5039e-03, 7.0203e-02, -2.2949e-02, 1.1312e-02, 4.5111e-02,
-3.5280e-02, 3.2406e-02, -4.8534e-03, -3.3348e-02, 1.9767e-02,
-1.9143e-02, -8.5507e-02, -7.4808e-02, 2.2461e-03, -6.1984e-02,
1.0867e-02, 5.4872e-02, -1.4489e-02, -6.8439e-02, -6.5845e-02,
-3.7658e-02, -8.1783e-02, 6.3587e-02, 5.5441e-02, 3.4191e-02,
1.8248e-02, 5.9773e-02, 5.3208e-02, -5.2996e-02, -4.8426e-02,
8.0495e-02, -8.7603e-02, 5.8796e-02, -5.0811e-02, 3.3368e-02,
4.1760e-02, 3.3040e-02, -6.2694e-02, 2.6616e-02, 7.5526e-02,
2.3045e-02, 8.7650e-02, 3.3344e-02, -2.2611e-02, 1.6431e-03,
7.0857e-02, -4.5940e-02, -1.9087e-02, -4.0979e-02, -2.3439e-02,
4.7452e-02, -6.7687e-02, -6.6874e-02, -2.2108e-02, -7.4597e-02,
-8.4081e-02, -2.4046e-02, 5.2679e-02, 1.1143e-02, 5.7075e-02,
5.5594e-02, 4.9338e-02, 6.3005e-02, -7.7738e-03, -7.2735e-02,
1.9297e-06, -2.2267e-02, -5.2727e-02, -3.0659e-02, 6.5038e-02,
-6.3450e-02, -4.7696e-02, -6.8763e-02, 3.7123e-02, -3.9326e-02,
5.7811e-02, -7.1448e-02, -1.2273e-02, 1.9893e-02, 7.3995e-02,
-5.3996e-02, -3.6854e-02, 4.2341e-02, 8.7182e-02, -3.4325e-02,
3.2037e-02, -1.6926e-02, -1.9183e-02, -2.7851e-02, 1.4859e-02,
2.3929e-02, -2.0850e-02, -4.4323e-02, 3.0600e-02, 6.4798e-02,
-3.1656e-02, 2.6691e-02, -5.9549e-02, -5.6938e-02, -8.0130e-02,
-1.9742e-02], requires_grad=True) torch.Size([256])
out.weight Parameter containing:
tensor([[-0.0173, 0.0522, 0.0494, ..., -0.0579, -0.0439, -0.0522],
[-0.0426, 0.0072, -0.0055, ..., -0.0301, 0.0480, -0.0607],
[-0.0454, 0.0552, -0.0465, ..., -0.0398, -0.0137, -0.0034],
...,
[ 0.0118, -0.0355, 0.0059, ..., -0.0462, -0.0543, 0.0234],
[-0.0365, -0.0555, 0.0247, ..., 0.0361, 0.0263, 0.0357],
[-0.0340, 0.0300, 0.0400, ..., 0.0522, -0.0565, 0.0542]],
requires_grad=True) torch.Size([10, 256])
out.bias Parameter containing:
tensor([-0.0154, -0.0028, -0.0574, -0.0608, -0.0276, 0.0483, 0.0503, 0.0112,
-0.0352, -0.0498], requires_grad=True) torch.Size([10])
5.使用TensorDataset和DataLoader,封装成一个batch的数据集
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
bs=64
train_ds=TensorDataset(x_train,y_train)
# train_dl=DataLoader(train_ds,batch_size=bs,shuffle=True)
valid_ds=TensorDataset(x_valid,y_valid)
# valid_dl=DataLoader(valid_ds,batch_size=bs*2)
def get_data(train_ds,valid_ds,bs):
return (
DataLoader(train_ds,batch_size=bs,shuffle=True),
DataLoader(valid_ds,batch_size=bs*2)
)
6.定义训练步骤
import numpy as np
val_losses=[]
#steps:迭代次数,step相当于epoch
def fit(steps,model,loss_func,opt,train_dl,valid_dl):
for step in range(steps):
model.train() #更新w和b
#xb(64,784) yb(64),xb和yb都是tensor
for xb,yb in train_dl:
loss_batch(model,loss_func,xb,yb,opt)
#evaluate 模式,dropout和BatchNum不会工作
model.eval() #不更新w和b
with torch.no_grad():
#losses:nums=(loss,batch),(loss,batch)....
losses,nums =zip(
*[loss_batch(model,loss_func,xb,yb) for xb,yb in valid_dl]
)
#总的验证集的平均损失
val_loss=np.sum(np.multiply(losses,nums)) / np.sum(nums)
val_losses.append(val_loss)
print("当前step:"+str(step),"验证集损失"+str(val_loss))
from torch import optim
def get_model():
model=Mnist_NN()
#返回模型和优化器optim.SGD(model.parameters() , lr=0.001)
return model,optim.Adam(model.parameters() , lr=0.001)
def loss_batch(model, loss_func ,xb,yb, opt=None):
#根据预测值和真实值计算loss
loss=loss_func( model(xb) , yb )
if opt is not None:
loss.backward() #反向传播求梯度
opt.step() #更新参数
opt.zero_grad() #梯度清零,避免影响下一次的更新参数
return loss.item(), len(xb)
7.开始训练模型
train_dl,valid_dl=get_data(train_ds,valid_ds,bs)
model,opt=get_model()
fit(20,model ,loss_func,opt,train_dl,valid_dl)
correct=0
total=0
#xb(128,784) , yb(128)
for xb,yb in valid_dl:
#output(128,10),每一批128个样例,10个概率
output=(model(xb))
# print(output.shape)
# print(output)
#predicted==预测概率中最大的值的索引
_,predicted=torch.max(output.data,1) #最大的值和索引
# print(predicted)
#size(0)==64,item()脱离tensor
total+=yb.size(0)
correct+=(predicted==yb).sum().item()
print("Accuracy of network on the 10000 test image :%d %%" %(
100*correct / total
))
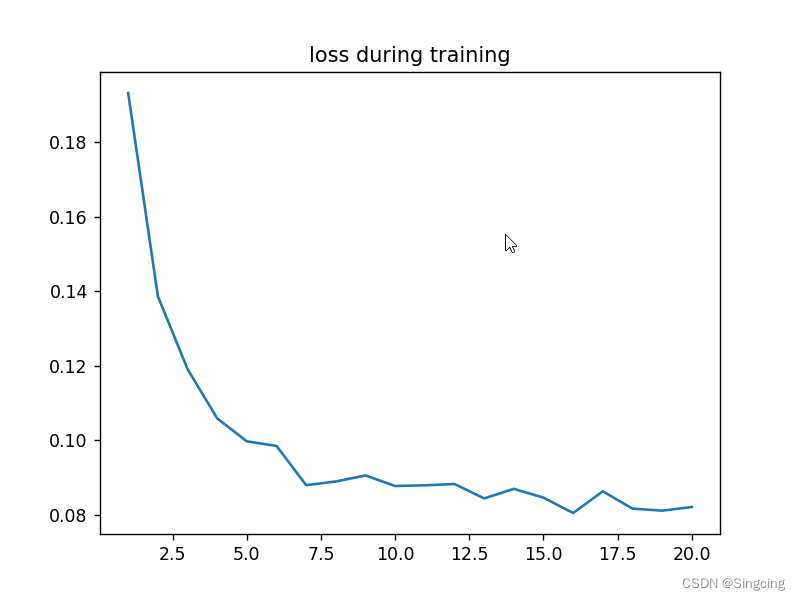
plt.figure()
plt.title("loss during training")
plt.plot(np.arange(1,21,1),val_losses)
plt.show()
当前step:0 验证集损失0.19325110550522803
当前step:1 验证集损失0.13869898459613322
当前step:2 验证集损失0.11913147141262889
当前step:3 验证集损失0.10589157585203647
当前step:4 验证集损失0.09970801477096974
当前step:5 验证集损失0.09848284918610006
当前step:6 验证集损失0.08794679024070501
当前step:7 验证集损失0.08894123120522127
当前step:8 验证集损失0.0905570782547351
当前step:9 验证集损失0.0877237871955149
当前step:10 验证集损失0.08790379901565612
当前step:11 验证集损失0.08826288345884532
当前step:12 验证集损失0.08438722904250026
当前step:13 验证集损失0.08695273711904883
当前step:14 验证集损失0.08459821079988032
当前step:15 验证集损失0.08047270769253373
当前step:16 验证集损失0.0862937849830836
当前step:17 验证集损失0.08164657156261383
当前step:18 验证集损失0.08109720230847597
当前step:19 验证集损失0.08208743708985858
Accuracy of network on the 10000 test image :97 %