点击下方关注我,然后右上角点击...“设为星标”,就能第一时间收到更新推送啦~~~
正则表达式(Regular Expression)在代码中常常简写为regex。正则表达式通常被用来检索、替换那些符合某个规则的文本,它是一种强大而灵活的文本处理工具。正则描述了一个规则,通过这个规则可以匹配一类字符串。
为了便于理解,所有示例的正则表达式用“regex=正则”表示,“=”号后面就是正则表达式,匹配到的字符会用颜色标注出来,连续匹配到的字符用一深一浅两种颜色区分。
比如:regex=\d+,其中\d+就是一个正则,它匹配任意多于1个的数字,如下:
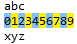
学习正则表达式语法,主要就是学习元字符以及它们在正则表达式上下文中的行为。元字符包括:普通字符、标准字符、特殊字符、限定字符(量词)、定位字符(边界字符)。
1、普通字符
字母[a-zA-Z]、数字[0-9]、下划线[-]、汉字,标点符号
匹配字母a可以regex=a
匹配字母b可以regex=b
匹配字母a或者b可以regex=a|b,这个正则引入一个特殊字符“|”,专业名称为“或”,你也可以叫它“竖线”,总之它表示“或”的意思。
匹配字母a或者b或者c可以regex=a|b|c
匹配字母a或者b或者c或者d可以regex=a|b|c|d
明显发现这么写有点傻了,如果匹配所有26个字母,这种写法就太二了。
这里引入两个特殊字符方括号“[ ]”和中划线“-”
“[ ]”,专业名称为“字符集合”,你也可以叫它“方括号”。
“-”,表示“范围”,你也可以叫它“到”,regex=[a-z]匹配从a到z26个字母的任意一个。
那么匹配字母a或者b或者c或者d可以regex=[abcd]
匹配数字1到8的任意数字可以regex=[1-8],这样就不会匹配到0与9这2个数字了,如下:
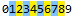
2、标准字符集合
标准字符集合是能够与“多种普通字符”匹配的简单表达式,比如:\d、\w、\s
匹配数字0到9的任意数字可以regex=[0-9]也可以regex=\d
标准字符集要注意区分大小写,大写是相反的意思
regex=\D,则匹配非数字字符,即不能匹配数字0到9,如下:
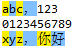
下面是一些常用的标准字符说明
| 标准字符 | 含义 |
| \d | 匹配0-9中的任意一个数字,等效于[0-9] |
| \D | 匹配非数字字符,等效于[^0-9] |
| \w | 匹配任意一个字母、数字或下划线,等效于[^A-Za-z0-9_] |
| \W | 与任何非字母、数字或下划线字符匹配,等效于[^A-Za-z0-9_] |
| \s | 匹配任何空白字符,包括空格、制表符、换页符,等效于 [\f\n\r\t\v] |
| \S | 匹配任何非空白字符,等效于[^\f\n\r\t\v] |
| \n | 匹配换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配制表符 |
| \v | 匹配垂直制表符 |
| \f | 匹配换页符 |
3、特殊字符
这些字符在正则表达式中表示特殊的含义,比如:*,+,?,\,等等
“\”是转义字符,用于匹配特殊字符
匹配反斜杠“\”可以regex=[\\],因为“\”是特殊字符,所以需要在它前边再加一个“\”进行转义
匹配星号“*”,可以regex=\*,因为“*”是特殊字符,所以需要在它前边再加一个“*”进行转义
下面是一些常用的特殊字符说明,后面都会讲到
| 特殊字符 | 含义 |
| \ | 转义字符,将下一个字符标记为一个特殊字符 |
| ^ | 匹配字符串开始的位置 |
| $ | 匹配字符串结尾的位置 |
| * | 零次或多次匹配前面的字符或子表达式 |
| + | 一次或多次匹配前面的字符或子表达式 |
| ? | 零次或一次匹配前面的字符或子表达式 |
| . | “点” 匹配除“\r\n”之外的任何单个字符 |
| | | 或 |
| [ ] | 字符集合 |
| ( ) | 分组,要匹配圆括号字符,请使用 “\(” 或 “\)” |
4、限定字符(量词)
限定字符又叫量词,是用于表示匹配的字符数量的。
匹配任意1位数字可以regex=\d
匹配任意2位数字可以regex=\d\d
匹配任意3位数字可以regex=\d\d\d
匹配任意16位数字,再这么写就有点傻了
这里引入用于表示数量限定字符“{n}”
“{n}”,n是一个非负整数,匹配确定的n次
注意:regex=\d\d{3}匹配任意4个数字不是6个,量词只对它前面的字符负责,regex=\d\d{3}匹配的内容如下:

匹配任意16位数字可以regex=\d{16}
匹配任意16位以上的数字可以regex=\d{16,}
匹配任意1到16位以上的数字可以regex=\d{1,16}
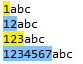
从上图,我们可以看到regex=\d{1,16},可以匹配到任意1-16个数字。
下面介绍一下匹配次数中的贪婪模式与非贪婪模式:
正则的匹配默认是贪婪模式,即匹配的字符越多越好,而非贪婪模式是匹配的字符越少越好,在修饰匹配字数的量词后再加上一个问号“?”即可。
那么同样是上面的字符串,regex=\d{1,16}?匹配到什么呢?
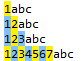
因为在{1,16}这个量词后面加上了问号“?”,表示非贪婪模式,所以只能匹配到1个数字,即匹配的字符越少越好。
下面是一些常用的限定字符说明
| 限定字符 | 含义 |
| * | 零次或多次匹配前面的字符或子表达式 |
| + | 一次或多次匹配前面的字符或子表达式 |
| ? | 零次或一次匹配前面的字符或子表达式 |
| {n} | n是一个非负整数,匹配确定的n次 |
| {n,} | n是非负整数,至少匹配n次 |
| {n,m} | n和m是非负整数,其中n<=m;匹配至少n次,至多m次 |
匹配0个或多个字母A可以regex=A*或者regex=A{0,}
匹配至少一个字母A可以regex=A+或者regex=A{1,}
匹配0个或1字母A可以regex=A?或者regex=A{0,1}
匹配至少一个LOVE可以regex=(LOVE)+
匹配的效果如下:

5、定位字符(字符边界)
定位字符也叫字符边界,标记匹配的不是字符而是符合某种条件的位置,所以定位字符是“零宽的”。
下面是一些常用的定位字符说明
| 定位字符 | 含义 |
| ^ | 匹配字符串开始的位置,表示开始 |
| $ | 匹配字符串结尾的位置,表示结尾 |
| \b | 匹配一个单词边界 |
匹配以Hello开头的字符串可以regex=^Hello
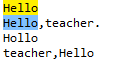
匹配以Hello结尾的字符串可以regex=Hello$,如下:

匹配以H开头以o结尾的任意长度字符串可以regex=^H.*o$,如下:

“\b”匹配这样一个位置:前面的字符和后面的字符不全是\w
如果在“hello,hello1 hello hello1 bhello”这个字符串里匹配regex=hello\b,
匹配到的结果如下:
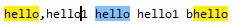
分析以下问题:为什么hello1匹配不了“hello\b”这个正则?
首先\b是一个定位字符,它是零宽的,标识一个位置,这个位置的前面和这个位置的后面不能全是\w,即不能全是字母数字和下划线[A-Za-z0-9_],而hello1的o与1之间的位置前面是o后面是1,前后全是\w,不符合\b匹配的含义,因此hello1不能匹配正则表达式“hello\b”。
但是bhello可以匹配“hello\b”这个正则,因为hello的结尾的位置,前面是o,后面是空白,所以符合\b匹配的含义,因此bhello可以匹配“hello\b”这个正则。
6、自定义字符集合
方括号[ ]表示字符集合,即[ ]表示自定义集合,用[ ]可以匹配方括号里的任意一个字符。
regex=[aeiou]匹配“a”,“e”,“i”,“o”,“u”任意一个字符,也就是可以匹配集合[aeiou]的任意一个字符。
需要注意,特殊字符(除了小尖角“^”和中划线“-”外)被包含到方括号中,就会失去特殊意义,只代表其字符本身。
regex=[abc+*?]匹配“a”,“b”,“c”任意一个字符或者“+”,“*”,“?”,即包含在自定义集合中的特殊字符“+”,“*”,“?”失去了特殊含义,只表示其字符本身的意思。
特殊字符小尖角“^”,原本含义是匹配字符串的开始位置,如果包含在自定义集合[ ]中,则表示取反的意思。
比如:regex=[^aeiou]匹配“a”,“e”,“i”,“o”,“u”之外的任意一个字符。
中划线“-”,在自定义集合[ ]中,表示“范围”,而不是字符“-”本身,regex=[a-z],匹配从a到z中26个字母的任意一个。
除小数点“.”外,标准字符集合包含在方括号中,仍然表示集合范围。
regex=[\d.+]匹配0-9的任意一个数字或者小数点“.”或者加号“+”
也就是说\d在自定义集合中仍然表示数字,但是小数点在字符集合中只表示小数点本身,而不是除“\r\n”之外的任何单个字符。
7、选择符和分组
| 表达式 | 作用 |
| pattern1|pattern2 | 或的关系,匹配左边的pattern1或右边的pattern2 |
| (pattern) | 匹配pattern并获取这一匹配,并存储 |
| (?:pattern) | 匹配pattern但不获取匹配结果,也就是不进行存储 |
regex=x|y,匹配字符x或y。
( )表示捕获组,( )的作用如下:
1、括号中的表达式可以作为整体被修饰,用来表示匹配括号中表达式的次数
regex=(abc){2,3},可以匹配连续的2个或3个abc,如下:

2、括号中的表达式匹配到的内容会存储起来,并可以获取到括号中表达式匹配到的内容
3、每一对括号会分配一个编号,使用( )的捕获根据左括号的顺序从1开始自动编号,编号为0的捕获是整个正则表达式匹配到的文本。
捕获组( )可以把匹配的内容存储起来,那么如何获取( )捕获到的内容呢,下面介绍反向引用。
8、反向引用“\number”
每一对括号会分配一个编号,使用( )的捕获根据左括号的顺序从1开始自动编号。通过反向引用,可以对分组已捕获的字符串进行引用。
“\number”中的number就是组号。
regex=(abc)d\1可以匹配字符串abcdabc,即\1表示把获取到的第一组再匹配一次,如下:

(?:pattern)表示非捕获组,匹配括号中表达式匹配到的内容,但是不进行存储匹配到的内容。这在使用 "或" 字符 (|) 来组合一个正则的各个部分是很有用的。
例如:匹配字符“story”或者“stories”,regex=stor(?:y|ies)就是一个比 regex=story|stories更简略的表达式。
9、预搜索(零宽断言)
预搜索,又叫零宽断言,又叫环视,它是对位置的匹配,与定位字符(边界字符)类似。
| 表达式 | 作用 |
| (?=pattern) | 断言此位置的后面能匹配表达式pattern |
| (?<=pattern) | 断言此位置的前面能匹配表达式pattern |
| (?!pattern) | 断言此位置的后面不能匹配表达式pattern |
| (?<!pattern) | 断言此位置的前面不能匹配表达式pattern |
regex=love (?=story)匹配的结果如下(匹配“love ”后面是story):

regex=love (?!story)匹配的结果如下(匹配“love ”后面不能是story):

10、运算符的优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
下表的优先级从高到低排序
| 运算符 | 描述 |
| \ | 转义字符 |
| (), (?:), (?=), [] | 圆括号和方括号,分组和自定义集合 |
| *, +, ?, {n}, {n,}, {n,m} | 限定字符(量词) |
| ^, $, 标准字符,字符 | 定位字符(边界字符)和字符 |
| | | 或 |
说明:“|”或操作是优先级最低的,它比普通字符的优先级低。
因此,regex=r|loom匹配“r”或“loom”,如下:
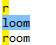
如果想匹配“room”或“loom”,请用括号创建子表达式,regex=(r|l)oom,如下:
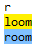
最后给大家介绍一下开发中使用正则表达式的流程:
1、分析所要匹配的数据特点,模拟各种测试数据;
2、利用正则工具,写正则表达式与测试数据进行匹配,从而验证你写的正则;
3、在程序里调用在正则工具中验证通过的正则表达式。
在这里给大家推荐一个正则工具“RegexBuddy”,你可以从网上下载,或者在后台回复关键词“正则表达式”获取。
至此,正则表达式的语法介绍完了,大家是不是已经掌握了呢,赶快去体验一下吧。

![[k8s] pod的创建过程](https://img-blog.csdnimg.cn/b8d3e1f217344535923aea80ca95e56e.png#pic_center)



![[自用]手推DDPM公式](https://img-blog.csdnimg.cn/3b6dbb7293bd4c4798747dec19c0f9e4.jpeg)